Recognition: 2 theorem links
· Lean TheoremMaskTab: Scalable Masked Tabular Pretraining with Scaling Laws and Distillation for Industrial Classification
Pith reviewed 2026-05-13 02:32 UTC · model grok-4.3
The pith
A masked pretraining framework for tabular data with dedicated missing-value tokens and twin-path supervision delivers over 5% AUC gains on industrial tasks and distills to efficient models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
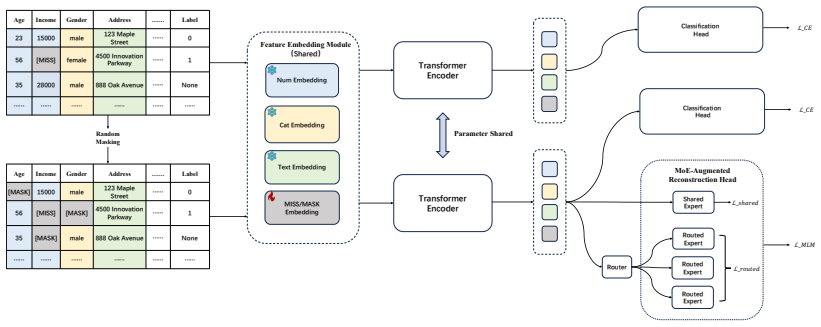
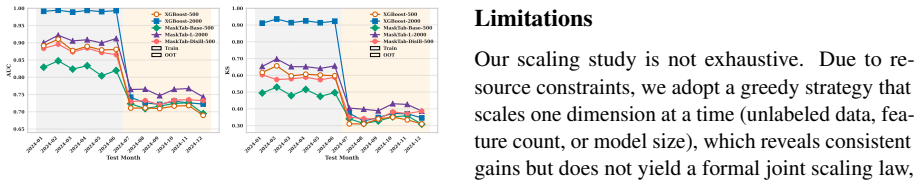
MaskTab encodes missing values via dedicated learnable tokens, jointly optimizes a hybrid supervised pre-training scheme utilizing a twin-path architecture to reconcile masked reconstruction with task-specific supervision, and employs an MoE-augmented loss that adaptively routes features through specialized subnetworks; on industrial-scale benchmarks it achieves +5.04% AUC and +8.28% KS over prior art under rigorous scaling, while its representations distill into lightweight models yielding +2.55% AUC and +4.85% KS under strict latency and interpretability constraints while improving robustness to distribution shifts.
What carries the argument
Twin-path architecture that reconciles masked reconstruction with task-specific supervision, augmented by learnable missing-value tokens and an MoE-augmented loss.
If this is right
- Performance lifts of +5.04% AUC and +8.28% KS on industrial benchmarks under rigorous scaling.
- Distilled lightweight models retain +2.55% AUC and +4.85% KS gains while meeting latency and interpretability limits.
- Improved robustness to distribution shifts in deployed tabular systems.
- Tabular data supports foundation-model pretraining once missingness and high dimensionality are modeled explicitly.
Where Pith is reading between the lines
- The approach could reduce dependence on hand-engineered features by letting large-scale pretraining discover useful representations from raw tables.
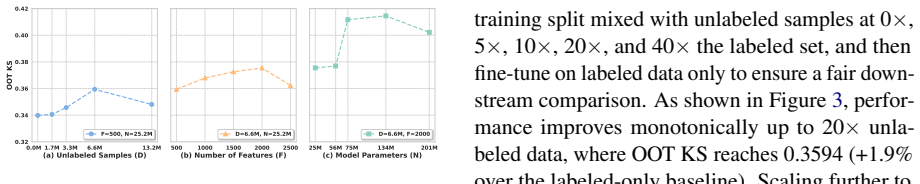
- Observed scaling behavior suggests further gains from larger pretraining compute or data volume without redesigning the core components.
- The missing-value token mechanism may transfer to other structured data with systematic absences such as time-series sensor logs or electronic health records.
Load-bearing premise
The twin-path architecture reconciling masked reconstruction with task-specific supervision combined with the MoE-augmented loss and learnable missing-value tokens will produce generalizable improvements on high-dimensional industrial tabular data without post-hoc tuning or dataset-specific biases.
What would settle it
Training MaskTab on a fresh industrial tabular dataset with previously unseen missing-value patterns and measuring whether AUC improvement falls below 1% relative to strong supervised baselines.
Figures


read the original abstract
Tabular data forms the backbone of high-stakes decision systems in finance, healthcare, and beyond. Yet industrial tabular datasets are inherently difficult: high-dimensional, riddled with missing entries, and rarely labeled at scale. While foundation models have revolutionized vision and language, tabular learning still leans on handcrafted features and lacks a general self-supervised framework. We present MaskTab, a unified pre-training framework designed specifically for industrial-scale tabular data. MaskTab encodes missing values via dedicated learnable tokens, enabling the model to distinguish structural absence from random dropout. It jointly optimizes a hybrid supervised pre-training scheme--utilizing a twin-path architecture to reconcile masked reconstruction with task-specific supervision--and an MoE-augmented loss that adaptively routes features through specialized subnetworks. On industrial-scale benchmarks, it achieves +5.04% AUC and +8.28% KS over prior art under rigorous scaling. Moreover, its representations distill effectively into lightweight models, yielding +2.55% AUC and +4.85% KS under strict latency and interpretability constraints, while improving robustness to distribution shifts. Our work demonstrates that tabular data admits a foundation-model treatment--when its structural idiosyncrasies are respected.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MaskTab, a unified pre-training framework for industrial-scale tabular data. It features learnable tokens for missing values, a twin-path architecture that combines masked reconstruction with task-specific supervision, and an MoE-augmented loss. The paper reports empirical gains of +5.04% in AUC and +8.28% in KS over prior art on industrial benchmarks under scaling, along with successful distillation to lightweight models achieving +2.55% AUC and +4.85% KS improvements, enhanced robustness to distribution shifts, and adherence to latency and interpretability constraints.
Significance. Should the empirical results prove robust and reproducible, this work would be significant as it provides a foundation-model style approach tailored to tabular data's unique challenges, potentially influencing practices in finance, healthcare, and other domains reliant on tabular data. The integration of scaling laws and distillation further enhances its applicability in resource-constrained industrial settings.
major comments (2)
- [Abstract] Abstract: The abstract states precise percentage gains (+5.04% AUC and +8.28% KS) but supplies no experimental protocol, baseline definitions, statistical tests, or ablation results; without these details the numerical claims cannot be evaluated against the paper's own data or equations. This is load-bearing for the central empirical claim.
- [Methods] The twin-path architecture is described as reconciling masked reconstruction with task-specific supervision, but without a formal loss equation or ablation isolating the contribution of each path, it is unclear whether the hybrid scheme is necessary for the reported gains.
minor comments (1)
- [Abstract] The phrase 'prior art' in the abstract is imprecise; naming the specific competing methods and their configurations would aid readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below, clarifying points where the manuscript already provides supporting material and outlining revisions to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states precise percentage gains (+5.04% AUC and +8.28% KS) but supplies no experimental protocol, baseline definitions, statistical tests, or ablation results; without these details the numerical claims cannot be evaluated against the paper's own data or equations. This is load-bearing for the central empirical claim.
Authors: We agree that the abstract would benefit from additional context. In the revised manuscript we will expand the abstract to briefly reference the industrial-scale benchmarks, the prior-art baselines, and the use of statistical testing, while directing readers to Sections 4 and 5 for the full experimental protocol, ablation studies, and significance results. This change will make the numerical claims more immediately evaluable without exceeding typical abstract length limits. revision: yes
-
Referee: [Methods] The twin-path architecture is described as reconciling masked reconstruction with task-specific supervision, but without a formal loss equation or ablation isolating the contribution of each path, it is unclear whether the hybrid scheme is necessary for the reported gains.
Authors: Equation (2) in Section 3.2 already defines the hybrid loss as L = L_recon + λ L_task, with the twin-path architecture and MoE routing shown in Figure 2. To directly address the request for isolating each path's contribution, we will add an ablation study in the revised experiments section that compares the full hybrid model against single-path variants (reconstruction-only and supervision-only). This will quantify the incremental benefit of the combined scheme. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical pre-training framework for tabular data, with all reported gains (+5.04% AUC, etc.) presented as measured outcomes on industrial benchmarks rather than as outputs of any derivation or first-principles chain. No equations, scaling-law derivations, or uniqueness theorems appear; architectural elements (learnable tokens, twin-path, MoE loss) are introduced as design choices validated by experiment. Because the central claims rest on external data rather than reducing to fitted parameters or self-citation chains, the work is self-contained against benchmarks and carries no circularity.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearMaskTab encodes missing values via dedicated learnable tokens... twin-path architecture to reconcile masked reconstruction with task-specific supervision... MoE-augmented loss that adaptively routes features through specialized subnetworks.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearperformance improves predictably as we scale unlabeled data, feature dimension, and model capacity
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
- [3]
-
[4]
Deep Residual Learning for Image Recognition , author=. 2015 , eprint=
work page 2015
-
[5]
TabReD: A Benchmark of Tabular Machine Learning in-the-Wild , author=. 2024 , journal=
work page 2024
-
[6]
Revisiting Deep Learning Models for Tabular Data , author=. NeurIPS , year=
- [7]
-
[8]
Advances in neural information processing systems , volume=
Lightgbm: A highly efficient gradient boosting decision tree , author=. Advances in neural information processing systems , volume=
-
[9]
CatBoost: unbiased boosting with categorical features , author=. NeurIPS , year=
-
[10]
DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems , author=. arXiv , volume=
- [11]
-
[12]
On Embeddings for Numerical Features in Tabular Deep Learning , author=. NeurIPS , year=
-
[13]
Trompt: Towards a Better Deep Neural Network for Tabular Data , booktitle =
Kuan. Trompt: Towards a Better Deep Neural Network for Tabular Data , booktitle =
-
[14]
TABR: TABULAR DEEP LEARNING MEETS NEAREST NEIGHBORS IN 2023 , author=. ICLR , year=
work page 2023
-
[15]
Towards Cross-Table Masked Pretraining for Web Data Mining , author=. WWW , year=
-
[16]
Zhu, Bingzhao and Shi, Xingjian and Erickson, Nick and Li, Mu and Karypis, George and Shoaran, Mahsa , booktitle=
-
[17]
Wang, Zifeng and Sun, Jimeng , booktitle=
-
[18]
Manbir S Gulati and Paul F Roysdon , booktitle=. Tab
-
[19]
ReMasker: Imputing Tabular Data with Masked Autoencoding , author=. ICLR , year=
-
[20]
Hangbo Bao and Li Dong and Songhao Piao and Furu Wei , booktitle=
-
[21]
A machine learning approach for prediction of pregnancy outcome following
Hassan, Md Rafiul and Al-Insaif, Sadiq and others , journal=. A machine learning approach for prediction of pregnancy outcome following
-
[22]
European Financial Management , year=
Machine learning in finance: A topic modeling approach , author=. European Financial Management , year=
-
[23]
HyperImpute: Generalized Iterative Imputation with Automatic Model Selection , author=. ICML , year=
-
[24]
Why do tree-based models still outperform deep learning on typical tabular data? , author=. NeurIPS , year=
-
[25]
Dara Bahri and Heinrich Jiang and Yi Tay and Donald Metzler , title =. ICLR , year =
- [26]
- [27]
-
[28]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second , author=. ICLR , year=
-
[29]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , booktitle=
-
[30]
GAIN: Missing Data Imputation using Generative Adversarial Nets , author=. NeurIPS , year=
-
[31]
Bayan Bruss and Tom Goldstein , booktitle=
Gowthami Somepalli and Avi Schwarzschild and Micah Goldblum and C. Bayan Bruss and Tom Goldstein , booktitle=
-
[32]
Language Models are Realistic Tabular Data Generators , author=. ICLR , year=
-
[33]
Training Compute-Optimal Large Language Models
Training compute-optimal large language models , author=. arXiv preprint arXiv:2203.15556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Scaling Laws for Neural Language Models
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[35]
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Scaling language models: Methods, analysis & insights from training gopher , author=. arXiv preprint arXiv:2112.11446 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Tab- DPT: Scaling tabular foundation models.arXiv preprint arXiv:2410.18164, 2024
Tabdpt: Scaling tabular foundation models , author=. arXiv preprint arXiv:2410.18164 , year=
-
[37]
Proceedings of the Nineteenth ACM Conference on Recommender Systems , pages=
Exploring Scaling Laws of CTR Model for Online Performance Improvement , author=. Proceedings of the Nineteenth ACM Conference on Recommender Systems , pages=
-
[38]
arXiv preprint arXiv:2410.12360 , year=
Towards neural scaling laws for time series foundation models , author=. arXiv preprint arXiv:2410.12360 , year=
-
[39]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Scaling vision transformers , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[40]
Distilling the Knowledge in a Neural Network
Distilling the knowledge in a neural network , author=. arXiv preprint arXiv:1503.02531 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
DeepGBM: A deep learning framework distilled by GBDT for online prediction tasks , author=. Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[42]
GLU Variants Improve Transformer
Glu variants improve transformer , author=. arXiv preprint arXiv:2002.05202 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[43]
Advances in neural information processing systems , volume=
Flashattention: Fast and memory-efficient exact attention with io-awareness , author=. Advances in neural information processing systems , volume=
-
[44]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[45]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
work page 2019
-
[46]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models , author=. arXiv preprint arXiv:2401.06066 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models , author=. 2026 , eprint=
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.