Recognition: 2 theorem links
· Lean TheoremBreaking textit{Winner-Takes-All}: Cooperative Policy Optimization Improves Diverse LLM Reasoning
Pith reviewed 2026-05-13 01:53 UTC · model grok-4.3
The pith
GCPO replaces individual rollout competition with team-level credit assignment based on contributions to collective solution coverage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
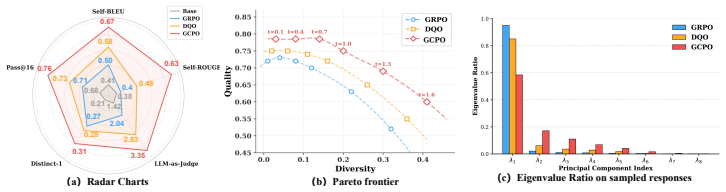
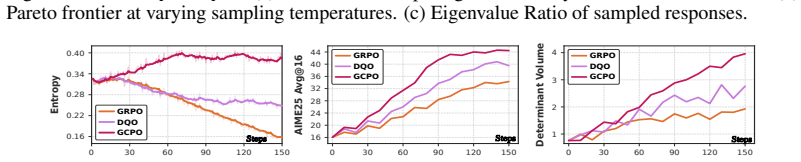
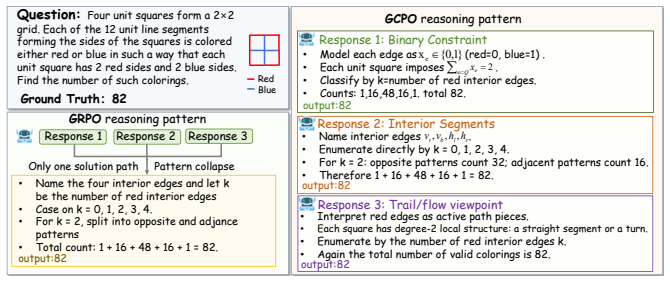
GCPO shifts the training paradigm from rollout competition to team cooperation by replacing independent rollout scoring with team-level credit assignment: a rollout is rewarded by how much it contributes to the team's valid solution coverage, described as a determinant volume over reward-weighted semantic embeddings where only correct and non-redundant rollouts contribute. During advantage estimation, GCPO redistributes the collective team reward to each single rollout according to its average marginal contribution to the team. This cooperative training paradigm routes optimization toward non-redundant correct reasoning paths.
What carries the argument
Determinant volume over reward-weighted semantic embeddings, which quantifies non-redundant team solution coverage and supports redistribution of collective reward via average marginal contributions.
If this is right
- GCPO improves both reasoning accuracy and solution diversity over GRPO and entropy-regularized methods across multiple benchmarks.
- The method prevents premature convergence on limited high-reward patterns by promoting global diversity through cooperation.
- Only correct and non-redundant rollouts contribute to the coverage volume used for credit assignment.
- Redistributing team reward according to average marginal contributions during advantage estimation directs updates toward diverse valid paths.
Where Pith is reading between the lines
- The geometric coverage measure could connect to diversity objectives in other RL domains such as code generation where multiple valid outputs are desirable.
- If the approach scales, it suggests that modifying credit assignment alone can substitute for explicit entropy bonuses in maintaining exploration.
- A testable extension is whether the same marginal-contribution logic applies when the verifier provides partial rather than binary correctness signals.
Load-bearing premise
The determinant volume over reward-weighted semantic embeddings provides a reliable, unbiased measure of non-redundant solution coverage whose marginal contributions can be computed and redistributed without introducing new optimization pathologies or sensitivity to embedding choice.
What would settle it
An experiment on a reasoning benchmark where GCPO-trained models produce no more distinct correct solutions than GRPO-trained models while showing equal or lower accuracy would falsify the claim that the cooperative paradigm improves both accuracy and diversity.
Figures



read the original abstract
Reinforcement learning with verifiers (RLVR) has become a central paradigm for improving LLM reasoning, yet popular group-based optimization algorithms like GRPO often suffer from exploration collapse, where the models prematurely converge on a narrow set of high-scoring patterns, lacking the ability to explore new solutions. Recent efforts attempt to alleviate this by adding entropy regularization or diversity bonus. However, these approaches do not change the \textit{winner-takes-all} nature, where rollouts still compete for individual advantage rather than cooperating for maximizing global diversity. In this work, we propose Group Cooperative Policy Optimization (GCPO), which shifts the training paradigm from rollout competition to team cooperation. Specifically, GCPO replaces independent rollout scoring with team-level credit assignment: a rollout is rewarded by how much it contributes to the team's valid solution coverage, rather than its individual accuracy. This coverage is described as a determinant volume over reward-weighted semantic embeddings, where only correct and non-redundant rollouts contribute to this volume. During advantage estimation, GCPO redistributes the collective team reward to each single rollout according to its average marginal contribution to the team. This cooperative training paradigm routes optimization toward non-redundant correct reasoning paths. Experiments across multiple reasoning benchmarks demonstrate that GCPO significantly improves both reasoning accuracy and solution diversity over existing approaches. Code will be released at $\href{https://github.com/bradybuddiemarch/gcpo}{this}$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Group Cooperative Policy Optimization (GCPO) to address exploration collapse in reinforcement learning with verifiers (RLVR) for LLMs. Unlike GRPO and similar group-based methods that rely on winner-takes-all individual advantages, GCPO treats rollouts as a cooperating team: coverage is quantified as the determinant volume of reward-weighted semantic embeddings (only correct, non-redundant rollouts contribute), and the team reward is redistributed to each rollout via its average marginal contribution. Experiments across reasoning benchmarks are reported to yield gains in both accuracy and solution diversity.
Significance. If the coverage metric and redistribution are shown to be robust, the work offers a substantive shift from competition-based to cooperation-based credit assignment in LLM RLVR. This could meaningfully improve diversity without sacrificing accuracy, addressing a recognized limitation of entropy or bonus-based regularizers. The approach is conceptually clean and directly targets the stated pathology.
major comments (3)
- [Method (coverage definition)] Method section (coverage definition): the determinant volume over reward-weighted semantic embeddings is asserted to measure non-redundant solution coverage, yet no analysis demonstrates that linear independence in the chosen embedding space corresponds to semantic distinctness of reasoning traces, nor that the volume is stable under embedding-model choice, dimensionality, or conditioning. This definition is load-bearing for both the coverage claim and the subsequent marginal-contribution redistribution.
- [Advantage estimation] Advantage estimation / redistribution: the paper states that the collective team reward is redistributed according to average marginal contributions, but supplies no derivation showing that the resulting per-rollout advantages remain unbiased estimators for the policy gradient. Without this, it is unclear whether the cooperative objective preserves the validity of the underlying RL update.
- [Experiments] Experiments: reported gains in accuracy and diversity rest on the coverage mechanism, yet the manuscript provides no ablations that isolate the marginal-contribution redistribution from standard diversity bonuses or entropy terms, nor sensitivity checks on embedding choice. This leaves the central empirical claim under-supported.
minor comments (2)
- [Abstract / Method] The abstract and method would benefit from explicit equations defining the coverage volume (det) and the marginal-contribution operator to improve readability and reproducibility.
- Minor notation inconsistencies appear in the description of 'reward-weighted' embeddings; a single consistent definition would aid clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important areas for strengthening the theoretical and empirical support of GCPO. We respond to each major comment below and will revise the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [Method (coverage definition)] Method section (coverage definition): the determinant volume over reward-weighted semantic embeddings is asserted to measure non-redundant solution coverage, yet no analysis demonstrates that linear independence in the chosen embedding space corresponds to semantic distinctness of reasoning traces, nor that the volume is stable under embedding-model choice, dimensionality, or conditioning. This definition is load-bearing for both the coverage claim and the subsequent marginal-contribution redistribution.
Authors: We acknowledge that additional analysis is warranted to substantiate the coverage metric. In the revised manuscript, we will include a dedicated subsection with illustrative examples of reasoning traces demonstrating the link between linear independence in the embedding space and semantic distinctness, along with empirical sensitivity checks across embedding models, dimensionalities, and conditioning to confirm robustness of the determinant volume. revision: yes
-
Referee: [Advantage estimation] Advantage estimation / redistribution: the paper states that the collective team reward is redistributed according to average marginal contributions, but supplies no derivation showing that the resulting per-rollout advantages remain unbiased estimators for the policy gradient. Without this, it is unclear whether the cooperative objective preserves the validity of the underlying RL update.
Authors: This concern is well-taken regarding the theoretical grounding. The redistribution follows from cooperative game-theoretic principles to allocate the team coverage reward. In the revision, we will add an appendix derivation establishing that the per-rollout advantages yield an unbiased estimator of the policy gradient with respect to the expected team coverage objective, thereby maintaining the validity of the RL update. revision: yes
-
Referee: [Experiments] Experiments: reported gains in accuracy and diversity rest on the coverage mechanism, yet the manuscript provides no ablations that isolate the marginal-contribution redistribution from standard diversity bonuses or entropy terms, nor sensitivity checks on embedding choice. This leaves the central empirical claim under-supported.
Authors: We agree that targeted ablations are needed to isolate the cooperative mechanism. The revised version will incorporate new ablation experiments comparing GCPO to variants augmented with standard diversity bonuses and entropy terms, as well as sensitivity analyses varying the embedding model for coverage computation. These will provide clearer empirical support for the reported gains. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines team coverage via determinant volume over reward-weighted semantic embeddings and redistributes collective reward using average marginal contributions. This constructs a specific objective and credit-assignment rule from standard linear-algebraic diversity measures and verifier rewards, without any equation reducing to its own inputs by construction. No self-citation chain, fitted parameter renamed as prediction, or ansatz smuggled via prior work is present. Experiments on external reasoning benchmarks supply independent evaluation, rendering the central claim self-contained rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic embeddings of reasoning paths can be meaningfully compared for redundancy via linear-algebraic volume (determinant).
invented entities (1)
-
determinant volume over reward-weighted semantic embeddings
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearThis coverage is described as a determinant volume over reward-weighted semantic embeddings, where only correct and non-redundant rollouts contribute to this volume.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearv(S) = log det(I_|S| + η L_S)
Reference graph
Works this paper leans on
-
[1]
The unreasonable effectiveness of entropy minimization in llm reasoning
Shivam Agarwal, Zimin Zhang, Lifan Yuan, Jiawei Han, and Hao Peng. The unreasonable effectiveness of entropy minimization in llm reasoning.arXiv preprint arXiv:2505.15134, 2025
-
[2]
EEPO: Exploration-Enhanced Policy Optimization via Sample-Then-Forget
Liang Chen, Xueting Han, Qizhou Wang, Bo Han, Jing Bai, Hinrich Schutze, and Kam-Fai Wong. Eepo: Exploration-enhanced policy optimization via sample-then-forget.arXiv preprint arXiv:2510.05837, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Yilei Chen, Souradip Chakraborty, Lorenz Wolf, Yannis Paschalidis, and Aldo Pacchiano. Post-training large language models for diverse high-quality responses.arXiv preprint arXiv:2509.04784, 2025
-
[4]
Zhipeng Chen, Xiaobo Qin, Youbin Wu, Yue Ling, Qinghao Ye, Wayne Xin Zhao, and Guang Shi. Pass@ k training for adaptively balancing exploration and exploitation of large reasoning models.arXiv preprint arXiv:2508.10751, 2025
-
[5]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Scaling laws for reward model overoptimization
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. InInternational Conference on Machine Learning, pages 10835–10866. PMLR, 2023
work page 2023
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems.arXiv preprint arXiv:2402.14008, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Zhenyu Hou, Xin Lv, Rui Lu, Jiajie Zhang, Yujiang Li, Zijun Yao, Juanzi Li, Jie Tang, and Yuxiao Dong. Advancing language model reasoning through reinforcement learning and inference scaling.arXiv preprint arXiv:2501.11651, 2025
-
[13]
Diversity-incentivized exploration for versatile reasoning
Zican Hu, Shilin Zhang, Yafu Li, Jianhao Yan, Xuyang Hu, Leyang Cui, Xiaoye Qu, Chunlin Chen, Yu Cheng, and Zhi Wang. Diversity-incentivized exploration for versatile reasoning. arXiv preprint arXiv:2509.26209, 2025
-
[14]
Open r1: A fully open reproduction of deepseek-r1, January 2025
Hugging Face. Open r1: A fully open reproduction of deepseek-r1, January 2025
work page 2025
-
[15]
Yuhua Jiang, Jiawei Huang, Yufeng Yuan, Xin Mao, Yu Yue, Qianchuan Zhao, and Lin Yan. Risk-sensitive rl for alleviating exploration dilemmas in large language models.arXiv preprint arXiv:2509.24261, 2025
-
[16]
Alex Kulesza and Ben Taskar. Determinantal point processes for machine learning.Foundations and Trends® in Machine Learning, 5(2-3):123–286, 2012. 10
work page 2012
-
[17]
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quan- titative reasoning problems with language models.Advances in neural information processing systems, 35:3843–3857, 2022
work page 2022
-
[18]
Tianjian Li, Yiming Zhang, Ping Yu, Swarnadeep Saha, Daniel Khashabi, Jason Weston, Jack Lanchantin, and Tianlu Wang. Jointly reinforcing diversity and quality in language model generations.arXiv preprint arXiv:2509.02534, 2025
-
[19]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Jia Liu, ChangYi He, YingQiao Lin, MingMin Yang, FeiYang Shen, and ShaoGuo Liu. Ettrl: Balancing exploration and exploitation in llm test-time reinforcement learning via entropy mechanism.arXiv preprint arXiv:2508.11356, 2025
-
[21]
Mingjie Liu, Shizhe Diao, Ximing Lu, Jian Hu, Xin Dong, Yejin Choi, Jan Kautz, and Yi Dong. Prorl: Prolonged reinforcement learning expands reasoning boundaries in large language models. arXiv preprint arXiv:2505.24864, 2025
-
[22]
Sentence-t5: Scalable sentence encoders from pre-trained text-to-text models
Jianmo Ni, Gustavo Hernandez Abrego, Noah Constant, Ji Ma, Keith Hall, Daniel Cer, and Yinfei Yang. Sentence-t5: Scalable sentence encoders from pre-trained text-to-text models. In Findings of the association for computational linguistics: ACL 2022, pages 1864–1874, 2022
work page 2022
-
[23]
OpenAI. Learning to reason with llms. https://openai.com/index/ learning-to-reason-with-llms, 2024
work page 2024
-
[24]
Sentence-bert: Sentence embeddings using siamese bert- networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert- networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP- IJCNLP), pages 3982–3992, 2019
work page 2019
-
[25]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Han Shen. On entropy control in llm-rl algorithms.arXiv preprint arXiv:2509.03493, 2025
-
[29]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025
work page 2025
-
[30]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
The many shapley values for model explanation
Mukund Sundararajan and Amir Najmi. The many shapley values for model explanation. In International conference on machine learning, pages 9269–9278. PMLR, 2020
work page 2020
-
[32]
Christian Walder and Deep Karkhanis. Pass@ k policy optimization: Solving harder reinforce- ment learning problems.arXiv preprint arXiv:2505.15201, 2025
-
[33]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022. 11
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024
work page 2024
-
[35]
The Invisible Leash: Why RLVR may or may not escape its origin.arXiv preprint arXiv:2507.14843, 2025
Fang Wu, Weihao Xuan, Ximing Lu, Mingjie Liu, Yi Dong, Zaid Harchaoui, and Yejin Choi. The invisible leash: Why rlvr may or may not escape its origin.arXiv preprint arXiv:2507.14843, 2025
-
[36]
Ting Wu, Xuefeng Li, and Pengfei Liu. Progress or regress? self-improvement reversal in post-training.arXiv preprint arXiv:2407.05013, 2024
-
[37]
C- pack: Packed resources for general chinese embeddings
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. C- pack: Packed resources for general chinese embeddings. InProceedings of the 47th international ACM SIGIR conference on research and development in information retrieval, pages 641–649, 2024
work page 2024
-
[38]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Jian Yao, Ran Cheng, Xingyu Wu, Jibin Wu, and Kay Chen Tan. Diversity-aware policy optimization for large language model reasoning.arXiv preprint arXiv:2505.23433, 2025
-
[40]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Right question is already half the answer: Fully unsupervised llm reasoning incentivization
Qingyang Zhang, Haitao Wu, Changqing Zhang, Peilin Zhao, and Yatao Bian. Right question is already half the answer: Fully unsupervised llm reasoning incentivization.arXiv preprint arXiv:2504.05812, 2025
-
[42]
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2024, 2024. 12 A Implementation Details A.1 Detailed Settings We provide additional experimental details in Section 4. All models are trained using theVERL framework [29] and deployed on 8 × NVIDIA 5880 Ada Generation GPUs. Table 4 and Table 5 summarize the training and eva...
work page 2024
-
[43]
How many ways to choose which interior edges are red
-
[44]
For each such choice, how many valid boundary colorings exist Step 3: Case analysis Casek= 0:All interior edges are blue. Each square has 0 red edges from interior, so both boundary edges of each square must be red. This uniquely determines all boundary edges. Count: 4 0 ×1 = 1. Casek= 4:All interior edges are red. Each square has 2 red edges from interio...
-
[45]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.