Recognition: 3 theorem links
· Lean TheoremA Barrier-Metric First-Order Method for Linearly Constrained Bilevel Optimization
Pith reviewed 2026-05-13 02:11 UTC · model grok-4.3
The pith
Logarithmic barrier smoothing of the lower polyhedron lets a first-order proxy-gradient method reach stationarity rates of O(K to the -2/3) without Hessian inversions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For the barrier-smoothed bilevel objective the algorithm attains stationarity rates of O(K^{-2/3}) in the deterministic case and O(K^{-2/5}) when only the upper-level objective is corrupted by bounded stochastic noise, after K outer iterations, together with quantitative bounds showing that the bias introduced by the barrier parameter can be driven to zero at a controlled rate.
What carries the argument
The barrier metric (local Dikin geometry) that supplies an oracle-free, uniformly positive curvature scale near the moving lower-level centers and thereby justifies the barrier-aware step-size and barrier-parameter schedules.
If this is right
- Upper-level gradients can be computed without inverting the lower-level Hessian or solving auxiliary linear systems at each iteration.
- Active-set changes at the lower level no longer produce nondifferentiability in the upper objective because the barrier smoothing is maintained throughout.
- The same first-order framework extends immediately to the case of bounded stochastic noise only in the upper objective, albeit with a slower rate.
- Explicit, quantitative control on the approximation error is obtained simply by letting the barrier parameter decrease at a rate tied to the outer iteration count.
Where Pith is reading between the lines
- The Dikin-geometry argument may extend to other barrier or interior-point smoothings of nonsmooth bilevel or min-max problems.
- The explicit dependence of the schedules on problem constants suggests that an adaptive or line-search variant could be developed to remove the need for a priori knowledge of those constants.
- Because the lower-level set is required only to be polyhedral, the same smoothing-plus-metric idea might apply directly to other linearly constrained nonsmooth optimization tasks beyond bilevel settings.
Load-bearing premise
The lower-level feasible set is a fixed polyhedron and the prescribed step-size and barrier schedules keep every iterate inside a locally well-behaved region where the barrier metric supplies uniform curvature control.
What would settle it
A simple linearly constrained bilevel instance whose observed outer-iteration stationarity gap after K steps fails to improve at rate K^{-2/3} or better when the barrier parameter is decreased according to the paper's schedule.
Figures


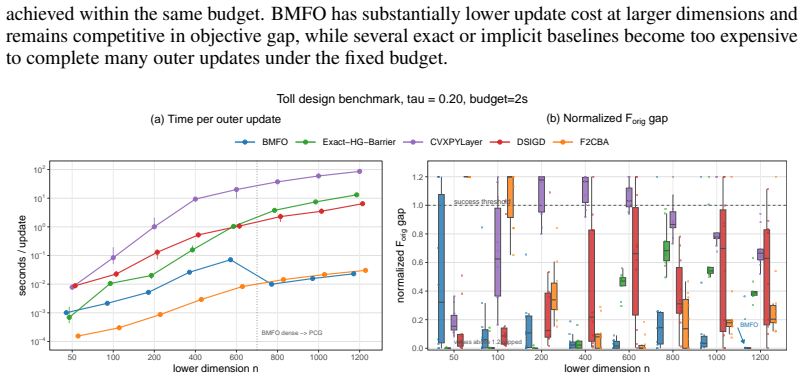
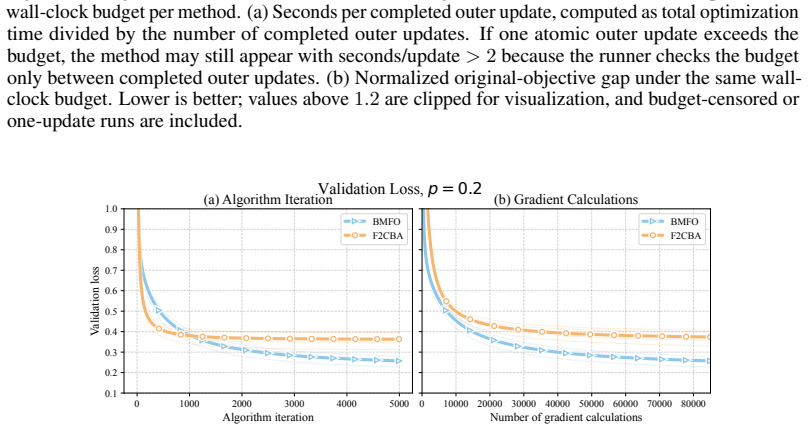
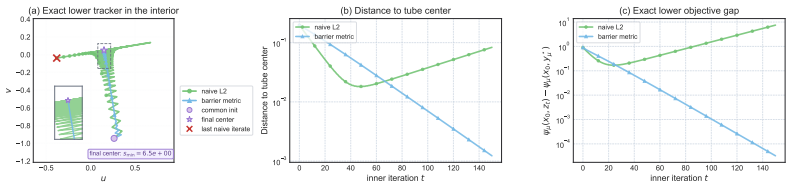


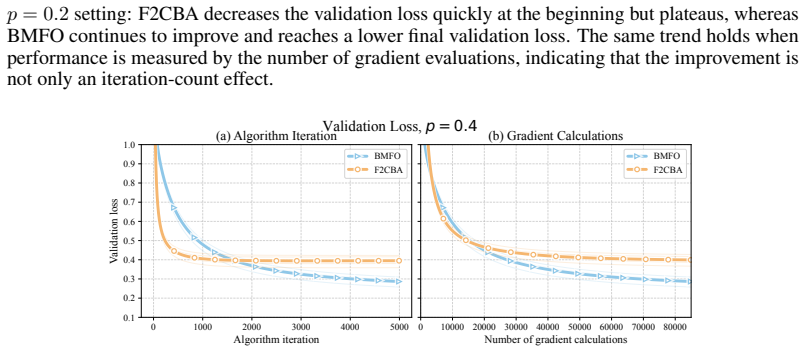
read the original abstract
We study bilevel optimization with a fixed polyhedral lower feasible set. Such problems are challenging for two reasons: active-set changes can make the upper objective nonsmooth, and existing hypergradient methods typically require lower-Hessian inversions or equivalent linear solves, which are computationally expensive. To address these issues, we adopt a logarithmic barrier smoothing of the lower problem to obtain a differentiable approximation of the constrained bilevel objective, and develop a proxy-gradient algorithm for the resulting barrier-smoothed surrogate. The algorithm uses only gradients of the upper and lower objectives; its only second-order object is the explicit logarithmic barrier Hessian determined by the fixed polyhedral constraints. Barrier smoothing restores differentiability, but Euclidean smoothness constants are not uniformly bounded near the boundary. We therefore develop a local Dikin-geometry analysis in which the barrier-metric provides an oracle-free curvature scale near the moving lower centers. This leads to barrier-aware schedules that keep the iterates inside locally well-behaved regions. For the barrier-smoothed objective, we prove stationarity rates of $\widetilde{O}(K^{-2/3})$ in the deterministic setting and $\widetilde{O}(K^{-2/5})$ under upper-level-only bounded stochastic noise after $K$ outer iterations, together with quantitative bias control as the barrier parameter decreases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a first-order proxy-gradient method for bilevel optimization problems where the lower-level feasible set is a fixed polyhedron. By applying logarithmic barrier smoothing to the lower-level problem, the upper-level objective becomes differentiable. The method uses only upper and lower gradients, with the barrier Hessian as the only second-order information. Using a local analysis in the Dikin geometry induced by the barrier metric, the authors derive step-size and barrier schedules that maintain iterates in regions with controlled curvature. They prove stationarity rates of O(K^{-2/3}) for the deterministic case and O(K^{-2/5}) under bounded stochastic noise in the upper level after K iterations, along with bounds on the bias introduced by the barrier smoothing as the parameter tends to zero.
Significance. If the convergence analysis holds, this provides a computationally attractive approach to bilevel optimization by avoiding lower-level Hessian inversions or solves, which are common bottlenecks in hypergradient methods. The barrier-metric analysis is a strength, allowing local control near the boundary without global Euclidean smoothness. The explicit rates and quantitative bias control as the barrier parameter decreases are valuable for understanding the approximation quality. This could be useful for applications with polyhedral constraints.
major comments (2)
- [§3 (Algorithm and Schedules)] The barrier-aware step-size and barrier-parameter schedules (defined via the problem constants in the algorithm description) are constructed from a priori Lipschitz constants, strong-convexity modulus, and a lower bound on distance to the polyhedral boundary. These are used to enforce that all outer iterates remain inside the region where the logarithmic barrier metric supplies uniform self-concordance and Hessian bounds relative to the moving lower centers. Since the algorithm provides no estimation or adaptive mechanism for these constants, the uniform curvature control required for the descent lemma is not guaranteed to hold in practice.
- [§4 (Convergence Analysis)] The proof of the deterministic stationarity rate O(K^{-2/3}) (and the stochastic O(K^{-2/5}) variant) relies on the descent inequality holding uniformly because the schedules keep iterates in the locally well-behaved Dikin region. If the actual distance to the boundary is smaller than the a priori lower bound used in the schedule, the Hessian bound relative to the barrier metric fails and the exponent derivation no longer applies.
minor comments (2)
- [§2 (Problem Formulation)] The notation for the proxy gradient and the explicit form of the barrier Hessian could be stated more explicitly in one location to improve readability.
- [Assumptions section] A single consolidated list of all assumptions (including noise bounds and geometry constants) would make cross-referencing with the rate proofs easier.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments on the algorithmic schedules and convergence analysis. We respond to each major comment below.
read point-by-point responses
-
Referee: [§3 (Algorithm and Schedules)] The barrier-aware step-size and barrier-parameter schedules (defined via the problem constants in the algorithm description) are constructed from a priori Lipschitz constants, strong-convexity modulus, and a lower bound on distance to the polyhedral boundary. These are used to enforce that all outer iterates remain inside the region where the logarithmic barrier metric supplies uniform self-concordance and Hessian bounds relative to the moving lower centers. Since the algorithm provides no estimation or adaptive mechanism for these constants, the uniform curvature control required for the descent lemma is not guaranteed to hold in practice.
Authors: We appreciate the referee's observation on the dependence on a priori constants. The analysis is non-adaptive and assumes these quantities (Lipschitz constants, strong-convexity modulus, and a positive lower bound δ on distance to the polyhedral boundary) are known or conservatively bounded, which is standard for deriving explicit rates in first-order methods. The schedules are constructed precisely from these constants to keep iterates inside the Dikin region with uniform curvature control relative to the barrier metric. In practice, a conservative (under)estimate of δ yields smaller steps that preserve the guarantees, though convergence may slow. We will add a remark in the revised Section 3 discussing conservative selection of these constants and noting that adaptive or line-search extensions could be considered in future work. revision: partial
-
Referee: [§4 (Convergence Analysis)] The proof of the deterministic stationarity rate O(K^{-2/3}) (and the stochastic O(K^{-2/5}) variant) relies on the descent inequality holding uniformly because the schedules keep iterates in the locally well-behaved Dikin region. If the actual distance to the boundary is smaller than the a priori lower bound used in the schedule, the Hessian bound relative to the barrier metric fails and the exponent derivation no longer applies.
Authors: The proof shows that when the a priori lower bound δ is chosen no larger than the true distance to the boundary, the barrier-aware schedules ensure all iterates remain inside a Dikin ball of controlled radius around the moving lower centers. This maintains the uniform Hessian bounds relative to the barrier metric, validating the descent inequality and the resulting rate exponents. Selecting δ larger than the actual distance would violate the curvature control, but the analysis treats δ as a valid lower bound that the user must supply (analogous to known smoothness parameters in standard first-order analyses). The local Dikin geometry is what permits handling non-uniform Euclidean smoothness without stronger global assumptions. revision: no
Circularity Check
No circularity: rates follow from standard analysis under explicit geometric assumptions
full rationale
The paper's central claims are stationarity rates for the barrier-smoothed bilevel objective, obtained by applying descent lemmas and noise bounds inside a local Dikin geometry induced by the logarithmic barrier. The step-size and barrier schedules are constructed explicitly from problem constants (Lipschitz moduli, strong-convexity parameters, distance to polyhedral boundary) that are treated as fixed inputs to the analysis; the rates are then derived as consequences of keeping iterates inside the region where those constants yield uniform self-concordance and Hessian bounds. No equation reduces a claimed prediction to a fitted quantity by construction, no uniqueness theorem is imported from the authors' prior work, and no ansatz is smuggled via self-citation. The derivation therefore remains self-contained against the stated assumptions rather than tautological.
Axiom & Free-Parameter Ledger
free parameters (1)
- barrier parameter
axioms (2)
- domain assumption Lower-level feasible set is a fixed polyhedron
- domain assumption Upper-level stochastic noise is bounded
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe adopt a logarithmic barrier smoothing... local Dikin-geometry analysis in which the barrier-metric provides an oracle-free curvature scale... barrier-aware schedules... rates of O(K^{-2/3})... O(K^{-2/5})
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclearDikin metric induced by the barrier Hessian... self-concordant metric change
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearfixed polyhedral lower feasible set... barrier parameter decreases
Reference graph
Works this paper leans on
-
[1]
International conference on machine learning , pages=
Model-agnostic meta-learning for fast adaptation of deep networks , author=. International conference on machine learning , pages=. 2017 , organization=
work page 2017
-
[2]
International conference on machine learning , pages=
Learning to reweight examples for robust deep learning , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[3]
International conference on machine learning , pages=
Bilevel programming for hyperparameter optimization and meta-learning , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[4]
Transportation science , volume=
A bilevel model for toll optimization on a multicommodity transportation network , author=. Transportation science , volume=. 2001 , publisher=
work page 2001
-
[5]
Advances in neural information processing systems , volume=
Task-based end-to-end model learning in stochastic optimization , author=. Advances in neural information processing systems , volume=
-
[6]
Smart “predict, then optimize” , author=. Management Science , volume=. 2022 , publisher=
work page 2022
-
[8]
International conference on machine learning , pages=
Bilevel optimization: Convergence analysis and enhanced design , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[9]
Annals of operations research , volume=
An overview of bilevel optimization , author=. Annals of operations research , volume=. 2007 , publisher=
work page 2007
-
[10]
SIAM Journal on Optimization , volume=
A two-timescale stochastic algorithm framework for bilevel optimization: Complexity analysis and application to actor-critic , author=. SIAM Journal on Optimization , volume=. 2023 , publisher=
work page 2023
-
[11]
Advances in Neural Information Processing Systems , volume=
Closing the gap: Tighter analysis of alternating stochastic gradient methods for bilevel problems , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
International Conference on Artificial Intelligence and Statistics , pages=
A single-timescale method for stochastic bilevel optimization , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2022 , organization=
work page 2022
-
[13]
Advances in Neural Information Processing Systems , volume=
A framework for bilevel optimization that enables stochastic and global variance reduction algorithms , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Advances in neural information processing systems , volume=
A near-optimal algorithm for stochastic bilevel optimization via double-momentum , author=. Advances in neural information processing systems , volume=
-
[15]
Advances in Neural Information Processing Systems , volume=
Provably faster algorithms for bilevel optimization , author=. Advances in Neural Information Processing Systems , volume=
- [16]
-
[17]
Liu, Bo and Ye, Mao and Wright, Stephen and Stone, Peter and Liu, Qiang , journal=
-
[18]
International Conference on Machine Learning , pages=
A fully first-order method for stochastic bilevel optimization , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[19]
International Conference on Machine Learning , pages=
Linearly constrained bilevel optimization: A smoothed implicit gradient approach , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[20]
Advances in neural information processing systems , volume=
First-order methods for linearly constrained bilevel optimization , author=. Advances in neural information processing systems , volume=
-
[22]
The Twelfth International Conference on Learning Representations , year=
Constrained Bi-Level Optimization: Proximal Lagrangian Value Function Approach and Hessian-free Algorithm , author=. The Twelfth International Conference on Learning Representations , year=
-
[23]
Advances in Neural Information Processing Systems , volume=
A Primal-Dual-Assisted Penalty Approach to Bilevel Optimization with Coupled Constraints , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
An implicit gradient method for constrained bilevel problems using barrier approximation , author=. ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2023 , organization=
work page 2023
-
[26]
Deng, Li , journal=. The. 2012 , publisher=
work page 2012
-
[27]
Some theoretical aspects of road traffic research
Road paper. Some theoretical aspects of road traffic research. , author=. Proceedings of the institution of civil engineers , volume=. 1952 , publisher=
work page 1952
-
[28]
Studies in the Economics of Transportation , author=
-
[29]
Mathematical programming , volume=
Analysis of the Frank--Wolfe method for convex composite optimization involving a logarithmically-homogeneous barrier , author=. Mathematical programming , volume=. 2023 , publisher=
work page 2023
-
[30]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
A Single-Loop First-Order Algorithm for Linearly Constrained Bilevel Optimization , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[31]
Advances in neural information processing systems , volume=
Differentiable convex optimization layers , author=. Advances in neural information processing systems , volume=
-
[32]
Differentiable convex optimization layers
Akshay Agrawal, Brandon Amos, Shane Barratt, Stephen Boyd, Steven Diamond, and J Zico Kolter. Differentiable convex optimization layers. Advances in neural information processing systems, 32, 2019
work page 2019
-
[33]
Studies in the economics of transportation
Martin Beckmann, Charles B McGuire, and Christopher B Winsten. Studies in the economics of transportation. Technical report, 1956
work page 1956
-
[34]
A bilevel model for toll optimization on a multicommodity transportation network
Luce Brotcorne, Martine Labb \'e , Patrice Marcotte, and Gilles Savard. A bilevel model for toll optimization on a multicommodity transportation network. Transportation science, 35 0 (4): 0 345--358, 2001
work page 2001
-
[35]
Closing the gap: Tighter analysis of alternating stochastic gradient methods for bilevel problems
Tianyi Chen, Yuejiao Sun, and Wotao Yin. Closing the gap: Tighter analysis of alternating stochastic gradient methods for bilevel problems. Advances in Neural Information Processing Systems, 34: 0 25294--25307, 2021
work page 2021
-
[36]
A single-timescale method for stochastic bilevel optimization
Tianyi Chen, Yuejiao Sun, Quan Xiao, and Wotao Yin. A single-timescale method for stochastic bilevel optimization. In International Conference on Artificial Intelligence and Statistics, pages 2466--2488. PMLR, 2022
work page 2022
-
[37]
An overview of bilevel optimization
Beno \^ t Colson, Patrice Marcotte, and Gilles Savard. An overview of bilevel optimization. Annals of operations research, 153 0 (1): 0 235--256, 2007
work page 2007
-
[38]
Mathieu Dagr \'e ou, Pierre Ablin, Samuel Vaiter, and Thomas Moreau. A framework for bilevel optimization that enables stochastic and global variance reduction algorithms. Advances in Neural Information Processing Systems, 35: 0 26698--26710, 2022
work page 2022
-
[39]
The MNIST database of handwritten digit images for machine learning research [best of the web]
Li Deng. The MNIST database of handwritten digit images for machine learning research [best of the web]. IEEE signal processing magazine, 29 0 (6): 0 141--142, 2012
work page 2012
-
[40]
Task-based end-to-end model learning in stochastic optimization
Priya Donti, Brandon Amos, and J Zico Kolter. Task-based end-to-end model learning in stochastic optimization. Advances in neural information processing systems, 30, 2017
work page 2017
-
[41]
Adam N Elmachtoub and Paul Grigas. Smart “predict, then optimize”. Management Science, 68 0 (1): 0 9--26, 2022
work page 2022
-
[42]
Model-agnostic meta-learning for fast adaptation of deep networks
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In International conference on machine learning, pages 1126--1135. PMLR, 2017
work page 2017
-
[43]
Bilevel programming for hyperparameter optimization and meta-learning
Luca Franceschi, Paolo Frasconi, Saverio Salzo, Riccardo Grazzi, and Massimiliano Pontil. Bilevel programming for hyperparameter optimization and meta-learning. In International conference on machine learning, pages 1568--1577. PMLR, 2018
work page 2018
-
[44]
Saeed Ghadimi and Mengdi Wang. Approximation methods for bilevel programming. arXiv preprint arXiv:1802.02246, 2018
-
[45]
Mingyi Hong, Hoi-To Wai, Zhaoran Wang, and Zhuoran Yang. A two-timescale stochastic algorithm framework for bilevel optimization: Complexity analysis and application to actor-critic. SIAM Journal on Optimization, 33 0 (1): 0 147--180, 2023
work page 2023
-
[46]
Bilevel optimization: Convergence analysis and enhanced design
Kaiyi Ji, Junjie Yang, and Yingbin Liang. Bilevel optimization: Convergence analysis and enhanced design. In International conference on machine learning, pages 4882--4892. PMLR, 2021
work page 2021
-
[47]
Tenorio, Fernando Real-Rojas, Antonio G
Liuyuan Jiang, Quan Xiao, Victor M. Tenorio, Fernando Real-Rojas, Antonio G. Marques, and Tianyi Chen. A primal-dual-assisted penalty approach to bilevel optimization with coupled constraints. In Advances in Neural Information Processing Systems, volume 37, pages 95026--95066, 2024 a
work page 2024
-
[48]
Xiaotian Jiang, Jiaxiang Li, Mingyi Hong, and Shuzhong Zhang. A barrier function approach for bilevel optimization with coupled lower-level constraints: Formulation, approximation and algorithms. arXiv preprint arXiv:2410.10670, 2024 b
-
[49]
A near-optimal algorithm for stochastic bilevel optimization via double-momentum
Prashant Khanduri, Siliang Zeng, Mingyi Hong, Hoi-To Wai, Zhaoran Wang, and Zhuoran Yang. A near-optimal algorithm for stochastic bilevel optimization via double-momentum. Advances in neural information processing systems, 34: 0 30271--30283, 2021
work page 2021
-
[50]
Linearly constrained bilevel optimization: A smoothed implicit gradient approach
Prashant Khanduri, Ioannis Tsaknakis, Yihua Zhang, Jia Liu, Sijia Liu, Jiawei Zhang, and Mingyi Hong. Linearly constrained bilevel optimization: A smoothed implicit gradient approach. In International Conference on Machine Learning, pages 16291--16325. PMLR, 2023
work page 2023
-
[51]
First-order methods for linearly constrained bilevel optimization
Guy Kornowski, Swati Padmanabhan, Kai Wang, Jimmy Zhang, and Suvrit Sra. First-order methods for linearly constrained bilevel optimization. Advances in neural information processing systems, 37: 0 141417--141460, 2024
work page 2024
-
[52]
A fully first-order method for stochastic bilevel optimization
Jeongyeol Kwon, Dohyun Kwon, Stephen Wright, and Robert D Nowak. A fully first-order method for stochastic bilevel optimization. In International Conference on Machine Learning, pages 18083--18113. PMLR, 2023
work page 2023
-
[53]
BOME! bilevel optimization made easy: A simple first-order approach
Bo Liu, Mao Ye, Stephen Wright, Peter Stone, and Qiang Liu. BOME! bilevel optimization made easy: A simple first-order approach. Advances in neural information processing systems, 35: 0 17248--17262, 2022
work page 2022
-
[54]
Cac Phan and Kai Wang. Bridging constraints and stochasticity: A fully first-order method for stochastic bilevel optimization with linear constraints. arXiv preprint arXiv:2511.09845, 2025
-
[55]
Learning to reweight examples for robust deep learning
Mengye Ren, Wenyuan Zeng, Bin Yang, and Raquel Urtasun. Learning to reweight examples for robust deep learning. In International conference on machine learning, pages 4334--4343. PMLR, 2018
work page 2018
-
[56]
A single-loop first-order algorithm for linearly constrained bilevel optimization
Wei Shen, Jiawei Zhang, Minhui Huang, and Cong Shen. A single-loop first-order algorithm for linearly constrained bilevel optimization. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[57]
An implicit gradient method for constrained bilevel problems using barrier approximation
Ioannis Tsaknakis, Prashant Khanduri, and Mingyi Hong. An implicit gradient method for constrained bilevel problems using barrier approximation. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1--5. IEEE, 2023
work page 2023
-
[58]
John Glen Wardrop. Road paper. some theoretical aspects of road traffic research. Proceedings of the institution of civil engineers, 1 0 (3): 0 325--362, 1952
work page 1952
-
[59]
Provably faster algorithms for bilevel optimization
Junjie Yang, Kaiyi Ji, and Yingbin Liang. Provably faster algorithms for bilevel optimization. Advances in Neural Information Processing Systems, 34: 0 13670--13682, 2021
work page 2021
-
[60]
Achieving O ( ^ -1.5 ) complexity in hessian/jacobian-free stochastic bilevel optimization
Yifan Yang, Peiyao Xiao, and Kaiyi Ji. Achieving O ( ^ -1.5 ) complexity in hessian/jacobian-free stochastic bilevel optimization. Advances in Neural Information Processing Systems, 36: 0 39491--39503, 2023
work page 2023
-
[61]
Wei Yao, Chengming Yu, Shangzhi Zeng, and Jin Zhang. Constrained bi-level optimization: Proximal lagrangian value function approach and hessian-free algorithm. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[62]
Renbo Zhao and Robert M Freund. Analysis of the frank--wolfe method for convex composite optimization involving a logarithmically-homogeneous barrier. Mathematical programming, 199 0 (1): 0 123--163, 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.