Recognition: 3 theorem links
· Lean TheoremEngagement Process: Rethinking the Temporal Interface of Action and Observation
Pith reviewed 2026-05-13 01:34 UTC · model grok-4.3
The pith
The Engagement Process decouples actions and observations into independent time streams to handle real-world timing mismatches in agent-environment interactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Engagement Process (EP) represents actions and observations as decoupled event streams along time instead of paired updates at fixed decision steps, inheriting the decision-theoretic structure of POMDPs while capturing timing issues such as deliberation latency, delayed feedback, and persistent actions, and enabling multi-rate coordination and compositional subsystem interactions.
What carries the argument
The decoupled event streams for actions and observations in the Engagement Process interface, which makes time explicit in the action-observation coupling.
If this is right
- Policies can explicitly adapt to time costs in decision making.
- Agents can manage persistent actions without forcing synchronization.
- Multi-rate coordination becomes possible between different agent subsystems.
- Compositional interactions are supported among agent components.
- Temporal behaviors hidden in step-based models become visible and actionable.
Where Pith is reading between the lines
- This interface might simplify integration with asynchronous real-world sensors and actuators.
- It could enable more natural modeling of human-like deliberation in AI agents.
- Extending to multi-agent scenarios might allow truly asynchronous interactions without global clocks.
Load-bearing premise
That managing the decoupled time streams adds complexity that can be practically handled and optimized in learning algorithms without the overhead negating the gains shown in the experiments.
What would settle it
A learning experiment on a task with significant timing mismatches where the EP-based agent fails to outperform or match the performance of a standard POMDP agent due to implementation or optimization issues.
Figures


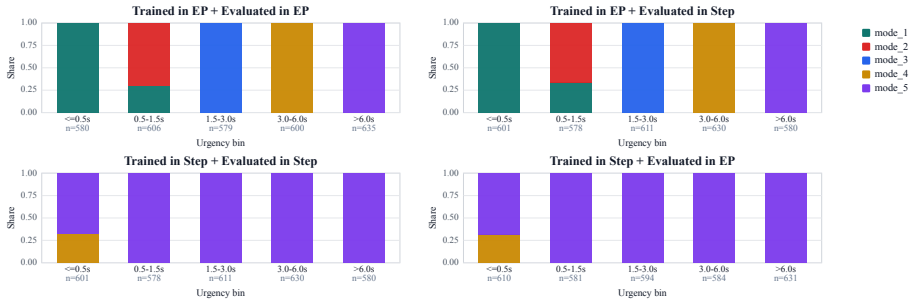



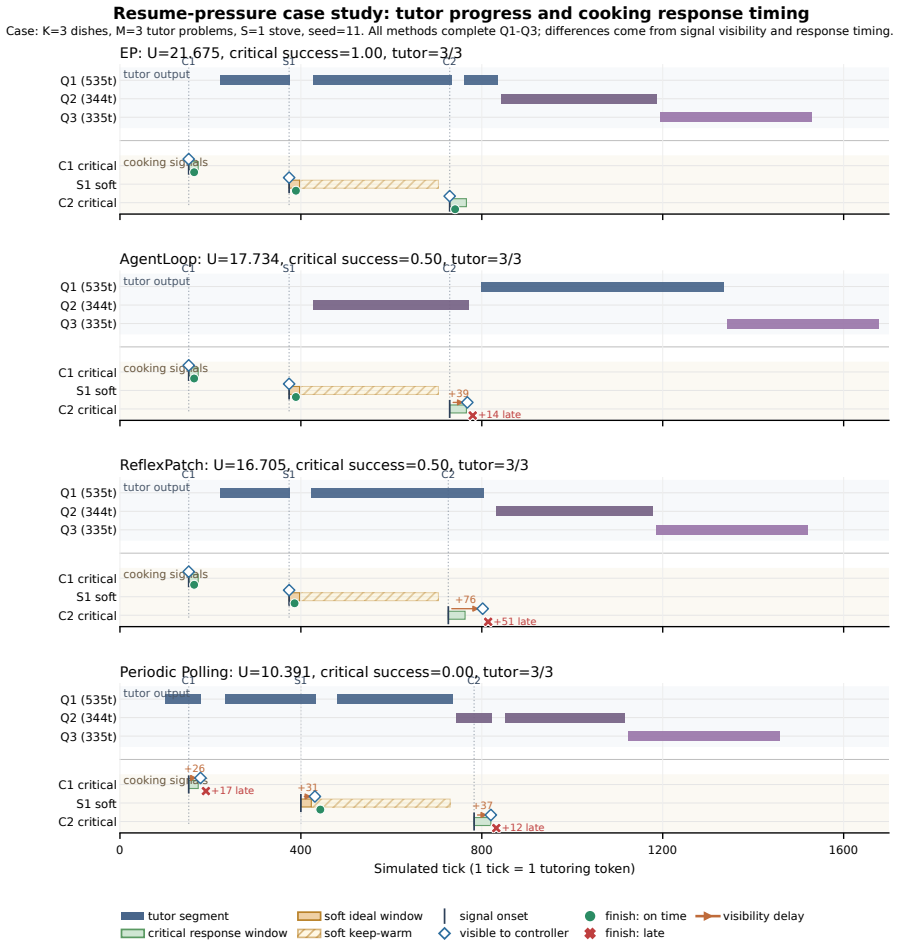
read the original abstract
Task completion in digital and physical environments increasingly involves complex temporal interaction, where actions and observations unfold over different time scales rather than align with fixed observation--action steps. To model such interactions, we propose \emph{Engagement Process} (EP), an interaction formalism that inherits the decision-theoretic structure of POMDPs while making time explicit in the action--observation interface. EP represents actions and observations as decoupled event streams along time, rather than updates paired at fixed decision steps. This interface captures single-agent timing issues such as deliberation latency, delayed feedback, and persistent actions, while supporting richer agent-side organization, multi-rate coordination, and compositional interaction among subsystems. Across toy, LLM-agent, and learning experiments, EP exposes temporal behaviors hidden by step-based interfaces and enables policies to adapt under explicit time costs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Engagement Process (EP) as a POMDP-compatible formalism that decouples actions and observations into independent event streams over explicit time, rather than pairing them at fixed decision steps. This is intended to capture timing phenomena such as deliberation latency, delayed feedback, and persistent actions, while enabling multi-rate coordination and compositional agent organization. The authors report that EP reveals temporal behaviors obscured by step-based interfaces and supports policy adaptation under explicit time costs, demonstrated via toy examples, LLM-agent scenarios, and learning experiments.
Significance. If the claimed practical advantages hold, EP could provide a more faithful interface for real-world agents operating under asynchronous or multi-scale temporal dynamics, potentially improving sample efficiency and policy quality in domains where standard POMDP step assumptions break down. The work supplies a clean conceptual separation and initial empirical illustrations, which are strengths if the formalism is shown to be trainable without prohibitive overhead.
major comments (2)
- [Learning experiments section] The central claim that EP yields usable policies adapting under explicit time costs (abstract) rests on the unverified assumption that the decoupled streams can be discretized and optimized without the expanded state space destroying convergence or sample efficiency. No section details the reduction to a trainable MDP/POMDP, the handling of asynchronous events, or the specific RL updates employed.
- [Learning experiments section] The experiments are asserted to isolate the benefit of decoupling from mere increases in model expressivity, yet the manuscript provides no controls (e.g., comparison to time-augmented but still paired POMDPs or ablations on event-rate handling) that would substantiate this isolation.
minor comments (2)
- [Introduction] Notation for event streams and time indexing should be introduced with a small formal example early in the paper to aid readability before the experimental sections.
- [Experimental sections] The abstract mentions 'toy, LLM-agent, and learning experiments' but does not indicate the number of runs, statistical significance, or exact baselines used; these details belong in the main text or appendix.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting the need for greater rigor in the learning experiments section. We agree that additional implementation details and controls are required to substantiate the claims regarding policy adaptation under explicit time costs. We will revise the manuscript to address both major comments as detailed below.
read point-by-point responses
-
Referee: [Learning experiments section] The central claim that EP yields usable policies adapting under explicit time costs (abstract) rests on the unverified assumption that the decoupled streams can be discretized and optimized without the expanded state space destroying convergence or sample efficiency. No section details the reduction to a trainable MDP/POMDP, the handling of asynchronous events, or the specific RL updates employed.
Authors: We accept this point. The current manuscript describes the outcomes of the learning experiments at a high level but does not specify the discretization procedure, state-space construction, or RL algorithm. In the revised version we will add a new subsection titled 'Training Procedure' that (1) explains the reduction of EP event streams to a finite POMDP via fixed-duration time bins and event queues, (2) describes how asynchronous events are buffered without exploding the state space by retaining only the most recent relevant history and explicit elapsed-time features, and (3) states that we employ a standard off-policy RL method (PPO with a recurrent critic) whose updates are applied at the end of each time bin. Preliminary runs confirm that convergence remains stable for the problem sizes reported; the added text will make this explicit. revision: yes
-
Referee: [Learning experiments section] The experiments are asserted to isolate the benefit of decoupling from mere increases in model expressivity, yet the manuscript provides no controls (e.g., comparison to time-augmented but still paired POMDPs or ablations on event-rate handling) that would substantiate this isolation.
Authors: We agree that the isolation claim requires stronger empirical support. The original experiments compared EP only against conventional step-based POMDPs. In the revision we will augment the experimental suite with two controls: (i) a time-augmented but still paired POMDP baseline in which actions and observations remain synchronized at each decision step while time is explicitly encoded, and (ii) rate-ablation variants that vary observation and action event frequencies independently while keeping the interface paired. Performance differences between these baselines and full EP will be reported to demonstrate that the observed advantages stem from the decoupled streams rather than from added temporal expressivity alone. revision: yes
Circularity Check
No circularity: Engagement Process is a definitional extension of POMDP structure
full rationale
The paper introduces Engagement Process as an explicit-time interface that inherits POMDP decision theory while decoupling actions and observations into independent event streams. All core claims are presented as modeling choices and descriptive extensions rather than derivations, predictions, or fitted quantities. No equations reduce by construction to their inputs, no self-citation chains bear the central argument, and no uniqueness theorems or ansatzes are smuggled in. The formalism is self-contained as a proposal for richer temporal modeling, with experiments serving only to illustrate exposed behaviors rather than validate forced predictions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The decision-theoretic structure of POMDPs can be preserved while redefining the action-observation interface to use decoupled time-based event streams.
invented entities (1)
-
Engagement Process (EP)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat inductive structure; embed into positive reals via generator orbit echoesWe define an Engagement Process (EP) over a discrete sequence of ticks T={0,1,2,…}. … actions and observations as decoupled event streams … Yt and At need not be paired.
-
IndisputableMonolith/CostJ(x)=½(x+x⁻¹)−1; J-cost forcing echoesutility ut ∼ U(·|st,At) … can represent … deliberation-time costs … cumulative utility J
-
IndisputableMonolith/Foundation/ArrowOfTime.leanTemporalSequence; zAtStep monotonicity; 8-tick periodicity echoesEP … inherits the decision-theoretic structure of POMDPs while making time explicit … 8-tick micro-structure implied by period-8 neutrality
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
${\pi}_{0.7}$: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities
Physical Intelligence, Bo Ai, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Greg Balke, Kevin Black, George Bokinsky, Shihao Cao, Thomas Charbonnier, et al. pi0.7: a steerable generalist robotic foundation model with emergent capabilities.arXiv preprint arXiv:2604.15483, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Openclaw: Personal ai assistant
OpenClaw. Openclaw: Personal ai assistant. https://github.com/openclaw/openclaw, 2026. Open-source agent framework
work page 2026
-
[6]
Claude code: Anthropic’s agentic coding system
Anthropic. Claude code: Anthropic’s agentic coding system. https://www.anthropic.com/ product/claude-code, 2025. Product page
work page 2025
-
[7]
Principles of metareasoning.Artificial intelligence, 49(1-3):361–395, 1991
Stuart Russell and Eric Wefald. Principles of metareasoning.Artificial intelligence, 49(1-3):361–395, 1991
work page 1991
-
[8]
Using anytime algorithms in intelligent systems.AI magazine, 17(3):73–73, 1996
Shlomo Zilberstein. Using anytime algorithms in intelligent systems.AI magazine, 17(3):73–73, 1996
work page 1996
-
[9]
Metareasoning: Theoretical and methodological developments, 2025
Linden J Ball and Beth H Richardson. Metareasoning: Theoretical and methodological developments, 2025
work page 2025
-
[10]
Sutton and Doina Precup and Satinder Singh , keywords =
Richard S. Sutton, Doina Precup, and Satinder Singh. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning.Artificial Intelligence, 112(1–2):181–211, 1999. doi: 10.1016/S0004-3702(99)00052-1
-
[11]
Matthias Hutsebaut-Buysse, Kevin Mets, and Steven Latré. Hierarchical reinforcement learning: A survey and open research challenges.Machine Learning and Knowledge Extraction, 4(1):172–221, 2022
work page 2022
-
[12]
Steven Bradtke and Michael Duff. Reinforcement learning methods for continuous-time markov decision problems.Advances in neural information processing systems, 7, 1994
work page 1994
-
[13]
An introduction to event- triggered and self-triggered control
Wilhelmus PMH Heemels, Karl Henrik Johansson, and Paulo Tabuada. An introduction to event- triggered and self-triggered control. In2012 ieee 51st ieee conference on decision and control (cdc), pages 3270–3285. IEEE, 2012
work page 2012
-
[14]
Xian-Ming Zhang, Qing-Long Han, Xiaohua Ge, Derui Ding, Boda Ning, and Bao-Lin Zhang. An overview of recent advances in event-triggered control.Science China Information Sciences, 68(6): 161201, 2025. 11
work page 2025
-
[15]
Revisiting active perception.Autonomous Robots, 42(2):177–196, 2018
Ruzena Bajcsy, Yiannis Aloimonos, and John K Tsotsos. Revisiting active perception.Autonomous Robots, 42(2):177–196, 2018
work page 2018
-
[16]
Julio A Placed, Jared Strader, Henry Carrillo, Nikolay Atanasov, Vadim Indelman, Luca Carlone, and José A Castellanos. A survey on active simultaneous localization and mapping: State of the art and new frontiers.IEEE Transactions on Robotics, 39(3):1686–1705, 2023
work page 2023
-
[17]
Handling delay in real-time reinforcement learning
Ivan Anokin, Rishav Rishav, Matthew Riemer, Stephen Chung, Irina Rish, and Samira Ebrahimi Kahou. Handling delay in real-time reinforcement learning. InInternational Conference on Learning Representations, 2025
work page 2025
-
[18]
Asynchronous tool usage for real-time agents.arXiv preprint arXiv:2410.21620, 2024
Antonio A Ginart, Naveen Kodali, Jason Lee, Caiming Xiong, Silvio Savarese, and John Emmons. Asynchronous tool usage for real-time agents.arXiv preprint arXiv:2410.21620, 2024
-
[19]
Puterman.Markov Decision Processes: Discrete Stochastic Dynamic Programming
Martin L. Puterman.Markov Decision Processes: Discrete Stochastic Dynamic Programming. Wiley, New York, 1994. ISBN 9780471619772
work page 1994
-
[20]
Leslie Pack Kaelbling, Michael L. Littman, and Anthony R. Cassandra. Planning and acting in partially observable stochastic domains.Artificial Intelligence, 101(1–2):99–134, 1998. doi: 10.1016/S0004-3702(98)00023-X
-
[21]
Howard.Dynamic Probabilistic Systems, Volume II: Semi-Markov and Decision Processes
Ronald A. Howard.Dynamic Probabilistic Systems, Volume II: Semi-Markov and Decision Processes. Wiley, New York, 1971
work page 1971
-
[22]
Thomas G Dietterich. Hierarchical reinforcement learning with the maxq value function decomposi- tion.Journal of artificial intelligence research, 13:227–303, 2000
work page 2000
-
[23]
Steven J. Bradtke and Michael O. Duff. Reinforcement learning methods for continuous- time markov decision problems. In G. Tesauro, D. Touretzky, and T. Leen, editors, Advances in Neural Information Processing Systems, volume 7, pages 393–400. MIT Press, 1994. URL https://proceedings.neurips.cc/paper_files/paper/1994/file/ 07871915a8107172b3b5dc15a6574ad3...
work page 1994
-
[24]
POMDPs in continuous time and dis- crete spaces
Bastian Alt, Matthias Schultheis, and Heinz Koeppl. POMDPs in continuous time and dis- crete spaces. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 13151–13162. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper_files/paper/2020/ file/992...
work page 2020
-
[25]
Paulo Tabuada. Event-triggered real-time scheduling of stabilizing control tasks.IEEE Transactions on Automatic Control, 52(9):1680–1685, 2007. doi: 10.1109/TAC.2007.904277
-
[26]
Rafal Goebel, Ricardo G. Sanfelice, and Andrew R. Teel.Hybrid Dynamical Systems: Modeling, Stability, and Robustness. Princeton University Press, Princeton, 2012. doi: 10.23943/princeton/ 9780691153896.001.0001
-
[27]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=WE_ vluYUL-X
work page 2023
-
[28]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 6...
work page 2023
-
[29]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. In A. Oh, T. Nau- mann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neu- ral Information Processing Systems, volume 36, pages 8634–8652. Curran Associates, Inc., 2023. URL https://proce...
work page 2023
-
[30]
A full-duplex speech dialogue scheme based on large language model
Peng Wang, Songshuo Lu, Yaohua Tang, Sijie Yan, Wei Xia, and Yuanjun Xiong. A full-duplex speech dialogue scheme based on large language model. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 13372–13403. Curran Asso- ciates, Inc., 2024. URL h...
work page 2024
-
[31]
Language model can listen while speaking
Ziyang Ma, Yakun Song, Chenpeng Du, Jian Cong, Zhuo Chen, Yuping Wang, Yuxuan Wang, and Xie Chen. Language model can listen while speaking. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 24831–24839, 2025
work page 2025
-
[32]
Guan-Ting Lin, Jiachen Lian, Tingle Li, Qirui Wang, Gopala Anumanchipalli, Alexander H. Liu, and Hung yi Lee. Full-duplex-bench: A benchmark to evaluate full-duplex spoken dialogue models on turn-taking capabilities.arXiv preprint arXiv:2503.04721, 2025
-
[33]
Gengyuan Zhang, Tanveer Hannan, Hermine Kleiner, Beste Aydemir, Xinyu Xie, Jian Lan, Thomas Seidl, V olker Tresp, and Jindong Gu. A ViLA: Asynchronous vision-language agent for streaming multimodal data interaction.arXiv preprint arXiv:2506.18472, 2025. doi: 10.48550/arXiv.2506. 18472
-
[34]
Robotouille: An asynchronous planning benchmark for LLM agents.arXiv preprint arXiv:2502.05227, 2025
Gonzalo Gonzalez-Pumariega, Leong Su Yean, Neha Sunkara, and Sanjiban Choudhury. Robotouille: An asynchronous planning benchmark for LLM agents.arXiv preprint arXiv:2502.05227, 2025. ReAct (GPT-4o): 47% sync, 11% async
-
[35]
From Static Inference to Dynamic Interaction: A Survey of Streaming Large Language Models
Junlong Tong, Zilong Wang, YuJie Ren, Peiran Yin, Hao Wu, Wei Zhang, and Xiaoyu Shen. From static inference to dynamic interaction: A survey of streaming large language models.arXiv preprint arXiv:2603.04592, 2026. Taxonomy: output-streaming, sequential-streaming, concurrent-streaming
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 24824–24837. Curran Assoc...
work page 2022
-
[37]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Le, Christopher Ré, and Azalia Mirhoseini
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V . Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling,
-
[39]
URLhttps://arxiv.org/abs/2407.21787
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Zhangwei He. Deepmath-103k. https://huggingface.co/datasets/zwhe99/ DeepMath-103K, 2025. Hugging Face dataset. 13
work page 2025
-
[42]
Real-time reasoning agents in evolving environ- ments.arXiv preprint arXiv:2511.04898, 2025
Yule Wen, Yixin Ye, Yanzhe Zhang, Diyi Yang, and Hao Zhu. Real-time reasoning agents in evolving environments.arXiv preprint arXiv:2511.04898, 2025. Introduces Real-Time Reasoning Gym and AgileThinker
-
[43]
Yangqing Zheng, Shunqi Mao, Dingxin Zhang, and Weidong Cai. LLM-enhanced rapid-reflex async-reflect embodied agent for real-time decision-making in dynamically changing environments. arXiv preprint arXiv:2506.07223, 2025. Proposes TCM and RRARA; evaluated on HAZARD benchmark
-
[44]
Tiago Veiga and Jennifer Renoux. From reactive to active sensing: A survey on information gathering in decision-theoretic planning.ACM Computing Surveys, 55(13s):280:1–280:22, 2023. doi: 10.1145/3583068
-
[45]
OpenThoughts: Data Recipes for Reasoning Models
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, et al. Openthoughts: Data recipes for reasoning models.arXiv preprint arXiv:2506.04178, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. InProceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025. 14 A Extended Related Work Streaming, full-duplex, and asynchronous agent systems.Recent agent...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.