Recognition: 2 theorem links
· Lean TheoremCoordinated Diffusion: Generating Multi-Agent Behavior Without Multi-Agent Demonstrations
Pith reviewed 2026-05-13 02:04 UTC · model grok-4.3
The pith
Coordinated Diffusion couples single-agent diffusion policies with a cost function to produce joint multi-agent behavior without any coordinated training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CoDi decomposes the diffusion sampling score into the sum of independent single-agent base policies plus a cost-driven guidance term; the guidance steers the product of the base policies toward desired joint outcomes and can be estimated in a gradient-free way for black-box costs. The method succeeds when single-agent data covers the support of the target multi-agent distribution and the cost selects the right combinations from that product.
What carries the argument
The cost-driven guidance term added to the decomposed diffusion score, which coordinates independent single-agent policies into joint behavior during sampling.
If this is right
- Multi-agent policies can be learned from single-agent demonstrations plus a cost function rather than joint data.
- The guidance term works with non-differentiable black-box costs without requiring additional training.
- Data efficiency improves because exponential growth in joint state-action space is avoided.
- The composition faithfully approximates target behavior only when base-policy support is sufficient and the cost is well-designed.
Where Pith is reading between the lines
- The same decomposition might allow cost-guided coordination in other generative models besides diffusion.
- For more than two agents, the approach would require costs that remain tractable as the product space grows.
- Hardware validation beyond two-arm tasks could test whether real-world dynamics preserve the theoretical coverage condition.
Load-bearing premise
Single-agent demonstrations must contain every behavior needed for the target joint distribution, and the cost function must be able to promote the desired combinations from the product of those independent policies.
What would settle it
Train single-agent policies on data that deliberately omits key coordinated configurations required by the target task, then run sampling with the cost function; the generated joint trajectories will fail to satisfy the coordination objective.
Figures

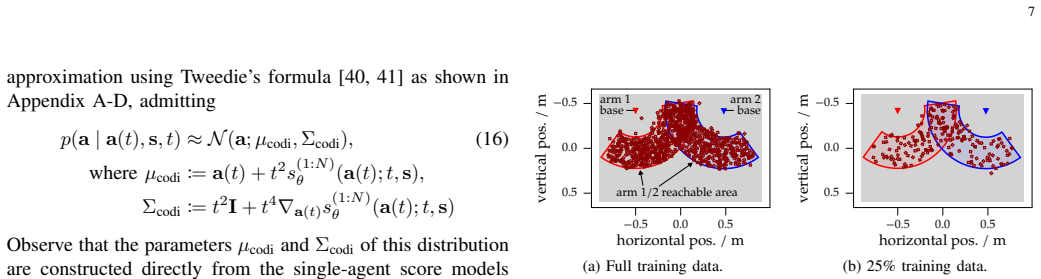

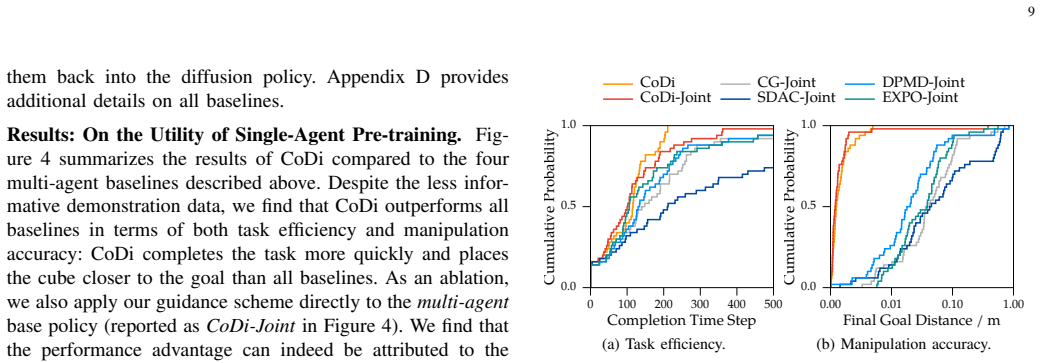
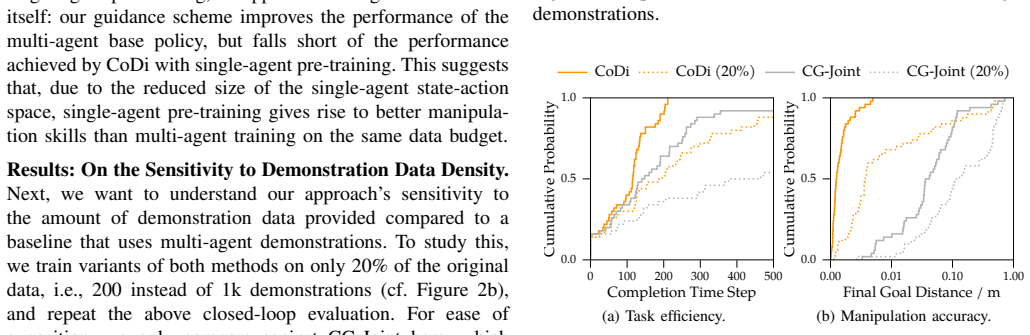



read the original abstract
Imitation learning powered by generative models has proven effective for modeling complex single-agent behaviors. However, teaching multi-agent systems, like multiple arms or vehicles, to coordinate through imitation learning is hindered by a fundamental data bottleneck: as the joint state-action space grows exponentially with the number of agents, collecting a sufficient amount of coordinated multi-agent demonstrations becomes extremely costly. In this work, we ask: how can we leverage single-agent demonstration data to learn multi-agent policies? We present Coordinated Diffusion (CoDi), a framework that couples independently trained single-agent diffusion policies through a user-defined multi-agent cost function, without requiring any coordinated demonstrations. We derive a new diffusion-based sampling scheme wherein the diffusion score function decomposes into independent, single-agent pre-trained base policies plus a cost-driven guidance term that coordinates these base policies into cohesive multi-agent behavior. We show that this guidance term can be estimated in a gradient-free manner, making CoDi applicable to black-box, non-differentiable cost functions without additional training. Theoretically and empirically, we analyze the conditions under which this composition can faithfully approximate a target multi-agent behavior. We find a complementary role for demonstration data versus the cost function: single-agent demonstrations must cover the support of the desired multi-agent behavior, while the cost function must promote desired behavior from this product of single-agent policies. Our results in simulation and hardware experiments of a two-arm manipulation task show that CoDi discovers robust coordinated behavior from single-agent data, is more data-efficient than multi-agent baselines, and highlights the importance of joint guidance, base policy support, and cost design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Coordinated Diffusion (CoDi), a framework that generates multi-agent coordinated behaviors by coupling independently trained single-agent diffusion policies via a user-defined multi-agent cost function, without any multi-agent demonstrations. It derives a diffusion sampling scheme in which the joint score decomposes into the sum of the pre-trained single-agent scores plus a cost-driven guidance term, shows that the guidance can be estimated gradient-free, and analyzes (theoretically and empirically) the conditions under which the composition approximates a target joint distribution. The key condition identified is that single-agent data must cover the support of the desired multi-agent behavior while the cost shapes the product distribution; results are shown on two-arm manipulation in simulation and hardware, claiming greater data efficiency than multi-agent baselines.
Significance. If the decomposition and support conditions hold as analyzed, the work would meaningfully advance imitation learning for multi-agent robotics by removing the exponential cost of collecting joint demonstrations. The gradient-free guidance for black-box costs and the explicit complementary roles of data support versus cost are useful contributions. The approach is falsifiable via the stated support-coverage requirement and could be extended to other generative models, though its practical scope is bounded by the need for single-agent data to already include the relevant coordinated states.
major comments (2)
- [Experiments] The central claim that the composition faithfully approximates the target multi-agent distribution rests on the support-coverage condition (single-agent demonstrations must cover the support of desired joint behavior). The abstract states this condition is analyzed theoretically and empirically, yet the two-arm experiments do not include controlled ablations that deliberately shrink base-policy support (e.g., by removing demonstrations of specific relative poses while holding the cost fixed) to test the boundary case where guidance cannot recover missing probability mass. This omission weakens the empirical validation of the load-bearing theoretical condition.
- [Method] The derived sampling scheme equates the joint score to the sum of independent single-agent scores plus the guidance term derived from the cost. This identity is exact if and only if the target joint is proportional to the product of the marginals times the cost factor. The manuscript should provide the explicit derivation (including any regularity assumptions on the diffusion process) in the methods section, as any unstated approximation in the score decomposition directly affects whether the guidance term can coordinate the policies as claimed.
minor comments (1)
- [Abstract] Notation for the guidance term and the product distribution could be introduced earlier and used consistently to improve readability of the decomposition.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We appreciate the identification of areas where the manuscript can be strengthened and address each major comment below.
read point-by-point responses
-
Referee: [Experiments] The central claim that the composition faithfully approximates the target multi-agent distribution rests on the support-coverage condition (single-agent demonstrations must cover the support of desired joint behavior). The abstract states this condition is analyzed theoretically and empirically, yet the two-arm experiments do not include controlled ablations that deliberately shrink base-policy support (e.g., by removing demonstrations of specific relative poses while holding the cost fixed) to test the boundary case where guidance cannot recover missing probability mass. This omission weakens the empirical validation of the load-bearing theoretical condition.
Authors: We agree that the current experiments primarily demonstrate success under sufficient support coverage and do not include explicit negative ablations testing the boundary where support is deliberately reduced. While our theoretical analysis and existing results (showing coordination only when relevant states are present in single-agent data) support the condition, adding controlled ablations would provide stronger empirical validation. In the revised manuscript, we will include new experiments that systematically remove demonstrations of specific relative poses from the single-agent datasets (while keeping the cost fixed) and demonstrate that the guidance term fails to recover the missing coordinated behaviors, directly testing the support-coverage requirement. revision: yes
-
Referee: [Method] The derived sampling scheme equates the joint score to the sum of independent single-agent scores plus the guidance term derived from the cost. This identity is exact if and only if the target joint is proportional to the product of the marginals times the cost factor. The manuscript should provide the explicit derivation (including any regularity assumptions on the diffusion process) in the methods section, as any unstated approximation in the score decomposition directly affects whether the guidance term can coordinate the policies as claimed.
Authors: We thank the referee for this clarification request. The explicit derivation of the score decomposition (showing that the joint score equals the sum of single-agent scores plus the cost-derived guidance term exactly when the target joint distribution is proportional to the product of the single-agent marginals modulated by the cost) is provided in the appendix, along with the regularity assumptions (standard Gaussian diffusion forward process with known score function and the target being defined via the product measure times the cost factor). We will move this full derivation, including the stated assumptions, into the main Methods section of the revised manuscript to make the exactness of the identity and its implications for coordination explicit. revision: yes
Circularity Check
No circularity: derivation is a standard score decomposition under explicitly stated support assumption
full rationale
The central derivation applies the known log-gradient identity to a product distribution (joint score = sum of marginal scores + cost gradient), which is a mathematical fact independent of the paper's data or claims. The paper explicitly flags the support-coverage requirement as a necessary condition rather than deriving it from the method itself, and the cost function is user-defined and external rather than fitted to multi-agent targets. No self-citations are invoked to justify uniqueness or load-bearing premises, and no fitted parameters are relabeled as predictions. The result is therefore self-contained against external diffusion-model theory.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The diffusion score function for the joint multi-agent process can be expressed as the sum of independent single-agent scores plus a cost-driven guidance term.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
the diffusion score function decomposes into independent, single-agent pre-trained base policies plus a cost-driven guidance term... π(a|s) := 1/Z(s) exp(−J(s,a)/λ) p1:N_θ(a|s)
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
single-agent demonstrations must cover the support of the desired multi-agent behavior, while the cost function must promote desired behavior from this product of single-agent policies
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Diffusion policy: Vi- suomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burch- fiel, R. Tedrake, and S. Song, “Diffusion policy: Vi- suomotor policy learning via action diffusion,”Proc. of Robotics: Science and Systems (RSS), 2023
work page 2023
-
[2]
Diffusion policy: Visuomotor policy learning via action diffusion,
——, “Diffusion policy: Visuomotor policy learning via action diffusion,”Intl. Journal of Robotics Research (IJRR), vol. 44, no. 10-11, pp. 1684–1704, 2025
work page 2025
-
[3]
Planning with Diffusion for Flexible Behavior Synthesis
M. Janner, Y . Du, J. B. Tenenbaum, and S. Levine, “Planning with diffusion for flexible behavior synthesis,” arXiv preprint, 2022, arXiv:2205.09991
work page internal anchor Pith review arXiv 2022
-
[4]
Goal- conditioned imitation learning using score-based diffu- sion policies,
M. Reuss, M. Li, X. Jia, and R. Lioutikov, “Goal- conditioned imitation learning using score-based diffu- sion policies,”Proc. of Robotics: Science and Systems (RSS), 2023
work page 2023
-
[5]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collab- oration 0,
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jainet al., “Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collab- oration 0,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 6892–6903
work page 2024
-
[6]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Elliset al., “Droid: A large-scale in-the-wild robot manipulation dataset,”arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Opti- mal and approximate q-value functions for decentralized pomdps,
F. A. Oliehoek, M. T. Spaan, and N. Vlassis, “Opti- mal and approximate q-value functions for decentralized pomdps,”Journal of Artificial Intelligence Research, vol. 32, pp. 289–353, 2008
work page 2008
-
[8]
Deep unsupervised learning using nonequi- librium thermodynamics,
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequi- librium thermodynamics,” inProc. of the Int. Conf. on Machine Learning (ICML). Proceedings of Machine Learning Research, 2015, pp. 2256–2265
work page 2015
-
[9]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,”Advances in Neural Information Processing Systems (NeurIPS), vol. 33, pp. 6840–6851, 2020
work page 2020
-
[10]
Generative modeling by es- timating gradients of the data distribution,
Y . Song and S. Ermon, “Generative modeling by es- timating gradients of the data distribution,”Advances in Neural Information Processing Systems (NeurIPS), vol. 32, 2019
work page 2019
-
[11]
Score-based generative mod- eling through stochastic differential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative mod- eling through stochastic differential equations,”Proc. of the Int. Conf. on Learning Representations (ICLR), 2021
work page 2021
-
[12]
Elucidating the design space of diffusion-based generative models,
T. Karras, M. Aittala, T. Aila, and S. Laine, “Elucidating the design space of diffusion-based generative models,” Advances in Neural Information Processing Systems (NeurIPS), vol. 35, pp. 26 565–26 577, 2022
work page 2022
-
[13]
Stochastic interpolants: A unifying framework for flows and diffusions,
M. Albergo, N. M. Boffi, and E. Vanden-Eijnden, “Stochastic interpolants: A unifying framework for flows and diffusions,”Journal of Machine Learning Research, vol. 26, no. 209, pp. 1–80, 2025
work page 2025
-
[14]
Diffusion meets flow matching: Two sides of the same coin,
R. Gao, E. Hoogeboom, J. Heek, V . D. Bortoli, K. P. Murphy, and T. Salimans, “Diffusion meets flow matching: Two sides of the same coin,” 2024. [Online]. Available: https://diffusionflow.github.io/
work page 2024
-
[15]
Flow matching for generative modeling,
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” inProc. of the Int. Conf. on Learning Representations (ICLR), 2023
work page 2023
-
[16]
Diffusion models beat gans on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat gans on image synthesis,”Advances in Neural Information 12 Processing Systems (NeurIPS), vol. 34, pp. 8780–8794, 2021
work page 2021
-
[17]
Diffwave: A versatile diffusion model for audio synthesis,
Z. Kong, W. Ping, J. Huang, K. Zhao, and B. Catanzaro, “Diffwave: A versatile diffusion model for audio synthesis,” inInternational Conference on Learning Representations (ICLR), 2021. [Online]. Available: https://openreview.net/forum?id=a-xFK8Ymz5J
work page 2021
-
[18]
J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. Fleet, “Video diffusion models,” inAdvances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds., vol. 35. Curran Associates, Inc., 2022, pp. 8633–8646. [Online]. Available: https: //proceedings.neurips.cc/paper files/paper/2022/file/...
work page 2022
-
[19]
Diffusion probabilistic models for 3d point cloud generation,
S. Luo and W. Hu, “Diffusion probabilistic models for 3d point cloud generation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2021, pp. 2837–2845
work page 2021
-
[20]
MIMIC- D: Multi-modal imitation for MultI-agent coordination with decentralized diffusion policies,
D. Dong, M. Bhatt, S. Choi, and N. Mehr, “MIMIC- D: Multi-modal imitation for MultI-agent coordination with decentralized diffusion policies,”arXiv preprint arXiv:2509.14159, 2025
work page internal anchor Pith review arXiv 2025
-
[21]
Latent theory of mind: A decentralized diffusion architecture for cooperative manipulation,
C. He, G. S. Camps, X. Liu, M. Schwager, and G. Sar- toretti, “Latent theory of mind: A decentralized diffusion architecture for cooperative manipulation,”arXiv preprint arXiv:2505.09144, 2025
-
[22]
Compositional visual generation with composable diffu- sion models,
N. Liu, S. Li, Y . Du, A. Torralba, and J. B. Tenenbaum, “Compositional visual generation with composable diffu- sion models,” inProceedings of the European Conference on Computer Vision (ECCV). Springer, 2022, pp. 423– 439
work page 2022
-
[23]
Reduce, reuse, recycle: Compositional gen- eration with energy-based diffusion models and MCMC,
Y . Du, C. Durkan, R. Strudel, J. B. Tenenbaum, S. Diele- man, R. Fergus, J. Sohl-Dickstein, A. Doucet, and W. S. Grathwohl, “Reduce, reuse, recycle: Compositional gen- eration with energy-based diffusion models and MCMC,” inProceedings of the International Conference on Ma- chine Learning (ICML). PMLR, 2023, pp. 8489–8510
work page 2023
-
[24]
PoCo: Policy composition from and for heterogeneous robot learning,
L. Wang, J. Zhao, Y . Du, E. H. Adelson, and R. Tedrake, “PoCo: Policy composition from and for heterogeneous robot learning,” inRobotics: Science and Systems (RSS), 2024
work page 2024
-
[25]
Multi-robot motion planning with diffusion models,
Y . Shaoul, I. Mishani, S. Vats, J. Li, and M. Likhachev, “Multi-robot motion planning with diffusion models,” in International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[26]
Efficient online reinforcement learning for diffusion policy,
H. Ma, T. Chen, K. Wang, N. Li, and B. Dai, “Efficient online reinforcement learning for diffusion policy,” in International Conference on Machine Learning. PMLR, 2025, pp. 41 837–41 853
work page 2025
-
[27]
EXPO: Stable Reinforcement Learning with Expressive Policies
P. Dong, Q. Li, D. Sadigh, and C. Finn, “Expo: Stable reinforcement learning with expressive policies,”arXiv preprint arXiv:2507.07986, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Diffusion policy policy optimization,
A. Z. Ren, J. Lidard, L. L. Ankile, A. Simeonov, P. Agrawal, A. Majumdar, B. Burchfiel, H. Dai, and M. Simchowitz, “Diffusion policy policy optimization,” inInternational Conference on Learning Representations (ICLR), 2025
work page 2025
-
[29]
Diffusing to coordinate: Efficient online multi-agent diffusion policies,
Z. Li, H. Zhong, X. Wang, Q. Xia, L. Zhang, and L. Huang, “Diffusing to coordinate: Efficient online multi-agent diffusion policies,”arXiv preprint arXiv:2602.18291, 2026
-
[30]
MADiff: Offline multi-agent learning with diffusion models,
Z. Zhu, M. Liu, L. Mao, B. Kang, M. Xu, Y . Yu, S. Ermon, and W. Zhang, “MADiff: Offline multi-agent learning with diffusion models,” inAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[31]
Classifier-Free Diffusion Guidance
J. Ho and T. Salimans, “Classifier-free diffusion guid- ance,”arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Hierarchical Text-Conditional Image Generation with CLIP Latents
A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical text-conditional image genera- tion with clip latents,”arXiv preprint arXiv:2204.06125, vol. 1, no. 2, p. 3, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
The Principles of Diffusion Models,
C.-H. Lai, Y . Song, D. Kim, Y . Mitsufuji, and S. Ermon, “The principles of diffusion models,”arXiv preprint, 2025, arXiv:2510.21890
-
[34]
Reverse-time diffusion equation mod- els,
B. D. Anderson, “Reverse-time diffusion equation mod- els,”Stochastic Processes and their Applications, vol. 12, no. 3, pp. 313–326, 1982
work page 1982
-
[35]
A connection between score matching and denoising autoencoders,
P. Vincent, “A connection between score matching and denoising autoencoders,”Neural computation, vol. 23, no. 7, pp. 1661–1674, 2011
work page 2011
-
[36]
Asymptotic eval- uation of certain markov process expectations for large time, i,
M. D. Donsker and S. S. Varadhan, “Asymptotic eval- uation of certain markov process expectations for large time, i,”Communications on pure and applied mathe- matics, vol. 28, no. 1, pp. 1–47, 1975
work page 1975
-
[37]
R. B. Nelsen,An introduction to copulas. Springer, 2006
work page 2006
-
[38]
Fonctions de r ´epartition `a n dimensions et leurs marges,
M. Sklar, “Fonctions de r ´epartition `a n dimensions et leurs marges,” inAnnales de l’ISUP, vol. 8, no. 3, 1959, pp. 229–231
work page 1959
-
[39]
Y . Fan and M. Henry, “Vector copulas,”Journal of Econometrics, vol. 234, no. 1, pp. 128–150, 2023
work page 2023
-
[40]
An empirical bayes approach to statis- tics,
H. E. Robbins, “An empirical bayes approach to statis- tics,” inBreakthroughs in Statistics: Foundations and basic theory. Springer Verlag, 1992, pp. 388–394
work page 1992
-
[41]
Tweedie’s formula and selection bias,
B. Efron, “Tweedie’s formula and selection bias,”Journal of the American Statistical Association, vol. 106, no. 496, pp. 1602–1614, 2011
work page 2011
-
[42]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. All- shire, A. Handaet al., “Isaac gym: High performance gpu-based physics simulation for robot learning,”arXiv preprint, 2021, arXiv:2108.10470. 13 APPENDIXA DERIVATIONS A. Optimally Compensating Multi-Agent Cost Function For completeness, we begin by repeatin...
work page internal anchor Pith review Pith/arXiv arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.