Recognition: 1 theorem link
· Lean TheoremA Study on Hidden Layer Distillation for Large Language Model Pre-Training
Pith reviewed 2026-05-13 02:11 UTC · model grok-4.3
The pith
Hidden layer distillation yields systematic perplexity gains over logit-based knowledge distillation in decoder-only LLM pre-training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our experiments show that HLD does not consistently outperform standard KD on downstream evaluation tasks. Nevertheless, we show that HLD can yield a systematic perplexity gain over KD across all shared-hyperparameter configurations, suggesting that a latent signal can be extracted, but a breakthrough may be needed for it to play a more significant role in LLM pre-training.
What carries the argument
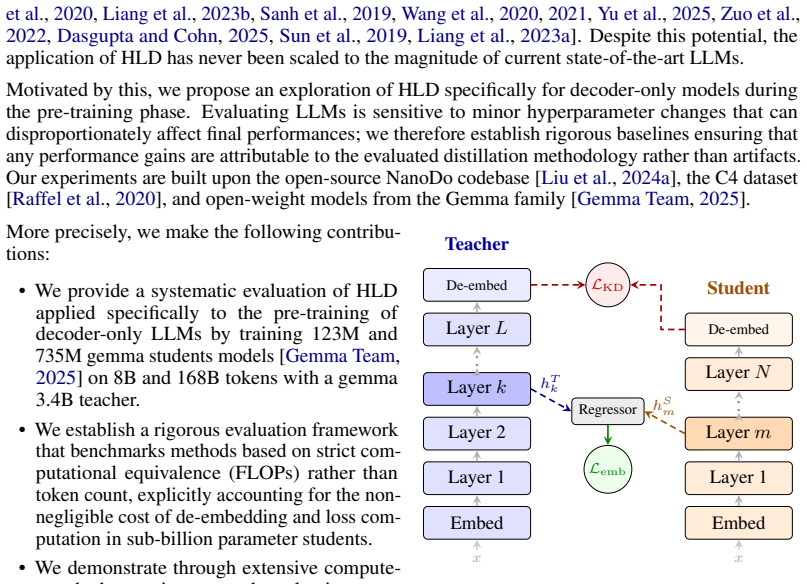
Hidden Layer Distillation (HLD), which aligns intermediate hidden representations of the teacher and student models during pre-training in addition to output logits.
If this is right
- A latent signal in teacher hidden layers can be extracted to improve language modeling quality measured by perplexity.
- The signal improves perplexity under every tested hyperparameter configuration when training decoder-only models.
- Current hidden layer distillation methods do not translate the signal into reliable downstream task gains.
- Further technique development is required before hidden layer information plays a significant role in large language model pre-training.
Where Pith is reading between the lines
- The gap between perplexity gains and downstream results suggests that pre-training objectives and task evaluations may be misaligned in how they use hidden signals.
- Architectural differences between encoder and decoder models may explain why hidden layer distillation has shown stronger results in prior encoder work.
- Selective layer matching or dynamic loss weighting could be tested to better exploit the extractable signal without increasing compute.
- Combining hidden layer distillation with other compression methods might produce additive efficiency benefits in resource-limited settings.
Load-bearing premise
The chosen student model sizes, training token counts, and downstream evaluation suite are sufficient to reveal whether hidden-layer information can be productively used in decoder-only pre-training.
What would settle it
A new experiment with different student sizes or token budgets in which hidden layer distillation shows no perplexity improvement over standard distillation would falsify the claim of systematic gains.
Figures






read the original abstract
Knowledge Distillation (KD) is a critical tool for training Large Language Models (LLMs), yet the majority of research focuses on approaches that rely solely on output logits, neglecting semantic information in the teacher's intermediate representations. While Hidden Layer Distillation (HLD) showed potential for encoder architectures, its application to decoder-only pre-training at scale remains largely unexplored. Through compute-controlled experiments, we benchmark HLD against logit-based KD and self-supervised baselines with Gemma3 3.4B as teacher and 123M and 735M students trained on up to 168B tokens from the C4 dataset. Our experiments show that HLD does not consistently outperform standard KD on downstream evaluation tasks. Nevertheless, we show that HLD can yield a systematic perplexity gain over KD across all shared-hyperparameter configurations, suggesting that a latent signal can be extracted, but a breakthrough may be needed for it to play a more significant role in LLM pre-training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically compares Hidden Layer Distillation (HLD) against logit-based Knowledge Distillation (KD) and self-supervised baselines for decoder-only LLM pre-training. Using Gemma3 3.4B as teacher and 123M/735M students trained on up to 168B C4 tokens under compute-controlled conditions with matched hyperparameters, it reports that HLD produces consistent perplexity reductions versus KD across all tested configurations, indicating an extractable latent signal from intermediate representations, while downstream task performance shows no consistent gains and concludes that further methodological advances are required for HLD to play a major role.
Significance. If the perplexity gains are shown to arise solely from the hidden-layer term under identical search budgets, the work would provide concrete evidence that teacher hidden states contain usable semantic information beyond logits in decoder-only pre-training, complementing existing KD literature. The compute-matched protocol and public dataset are positive features that aid reproducibility. However, the absence of consistent downstream improvements limits immediate practical impact, and the paper itself notes that a breakthrough is still needed.
major comments (3)
- [Abstract] Abstract: The central claim that HLD yields a 'systematic perplexity gain over KD across all shared-hyperparameter configurations' is load-bearing for the latent-signal conclusion, yet the manuscript supplies no explicit protocol (e.g., in the methods section) confirming that HLD-specific choices—teacher-layer indices, hidden-state similarity metric (MSE vs. cosine), and auxiliary-loss scalar—were drawn from the identical discrete/continuous search space used for KD rather than tuned after observing validation perplexity.
- [Results] Results section (perplexity and downstream tables): No error bars, multiple random seeds, or statistical significance tests are reported for the claimed perplexity reductions or the downstream-task comparisons; without these, it is impossible to assess whether the observed differences exceed run-to-run variance and therefore whether the distinction between perplexity gains and downstream neutrality is robust.
- [Experimental setup] Experimental setup: The weakest assumption—that the chosen student sizes (123M, 735M), token counts (up to 168B), and downstream suite are sufficient to reveal productive use of hidden-layer information—remains untested; the paper does not include scaling curves or ablation on larger students or longer training that would strengthen the generality of the 'latent signal' interpretation.
minor comments (2)
- [Methods] Notation for loss weighting and layer mapping should be defined once in a dedicated subsection rather than scattered across text and tables.
- [Abstract] The abstract states HLD 'does not consistently outperform' on downstream tasks; a table or figure explicitly listing per-task deltas with confidence intervals would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the insightful and constructive comments on our manuscript. We address each of the major comments in detail below and outline the revisions we plan to make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] The central claim that HLD yields a 'systematic perplexity gain over KD across all shared-hyperparameter configurations' is load-bearing for the latent-signal conclusion, yet the manuscript supplies no explicit protocol (e.g., in the methods section) confirming that HLD-specific choices—teacher-layer indices, hidden-state similarity metric (MSE vs. cosine), and auxiliary-loss scalar—were drawn from the identical discrete/continuous search space used for KD rather than tuned after observing validation perplexity.
Authors: We appreciate the referee pointing out the need for greater transparency in our hyperparameter selection process. The HLD-specific parameters, including teacher layer indices, similarity metrics, and loss scalars, were explored using the same systematic grid search over discrete and continuous spaces as the logit KD baselines, with all searches conducted under identical compute constraints and without reference to final validation perplexity after initial runs. To clarify this, we will add an explicit subsection to the Methods section detailing the full hyperparameter search protocol for both approaches. revision: yes
-
Referee: [Results] No error bars, multiple random seeds, or statistical significance tests are reported for the claimed perplexity reductions or the downstream-task comparisons; without these, it is impossible to assess whether the observed differences exceed run-to-run variance and therefore whether the distinction between perplexity gains and downstream neutrality is robust.
Authors: We agree that including measures of statistical robustness would enhance the reliability of our findings. Due to the extreme computational demands of these large-scale pre-training runs, our primary results are based on single executions with carefully matched conditions. In the revision, we will conduct and report results from multiple random seeds (at least three) for a subset of key configurations to provide error bars, and we will include statistical significance testing for the downstream task comparisons. revision: yes
-
Referee: [Experimental setup] The weakest assumption—that the chosen student sizes (123M, 735M), token counts (up to 168B), and downstream suite are sufficient to reveal productive use of hidden-layer information—remains untested; the paper does not include scaling curves or ablation on larger students or longer training that would strengthen the generality of the 'latent signal' interpretation.
Authors: We recognize the value of scaling analyses for broader generalization. Our experimental design prioritized compute-matched comparisons at practical scales to isolate the contribution of hidden layer information. The observed consistent perplexity improvements across the tested student sizes provide supporting evidence for the latent signal within these regimes. We will revise the paper to include additional discussion in the Limitations section on the scale-specific nature of our results and suggest directions for future scaling studies. revision: partial
Circularity Check
No circularity: purely empirical benchmark with no derivations or fitted predictions
full rationale
The paper is an empirical comparison of Hidden Layer Distillation versus logit-based KD on decoder-only pre-training. It reports measured perplexity and downstream-task results from controlled experiments (Gemma3 teacher, fixed student sizes, token counts, C4 data) without any claimed mathematical derivation, uniqueness theorem, or prediction that reduces to its own inputs by construction. No self-citations are invoked to justify a load-bearing premise, no ansatz is smuggled, and no parameter is fitted then relabeled as a prediction. The central claim rests on external benchmarks and baselines, making the work self-contained against the patterns that would trigger circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Matching teacher hidden states or logits transfers useful knowledge to the student
- domain assumption Perplexity and standard downstream benchmarks are appropriate measures of distillation success
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearLHLD = β L_data + α L_logits + γ L_emb with L_emb = MSE(normalized teacher/student hidden states at median layer)
Reference graph
Works this paper leans on
-
[1]
Hinton and Oriol Vinyals and Jeffrey Dean , title =
Geoffrey E. Hinton and Oriol Vinyals and Jeffrey Dean , title =. CoRR , volume =. 2015 , url =
work page 2015
-
[2]
FitNets: Hints for Thin Deep Nets , booktitle =
Adriana Romero and Nicolas Ballas and Samira Ebrahimi Kahou and Antoine Chassang and Carlo Gatta and Yoshua Bengio , editor =. FitNets: Hints for Thin Deep Nets , booktitle =. 2015 , url =
work page 2015
-
[3]
Zechun Liu and Changsheng Zhao and Forrest N. Iandola and Chen Lai and Yuandong Tian and Igor Fedorov and Yunyang Xiong and Ernie Chang and Yangyang Shi and Raghuraman Krishnamoorthi and Liangzhen Lai and Vikas Chandra , title =. Forty-first International Conference on Machine Learning,. 2024 , url =
work page 2024
-
[4]
Hao Peng and Xin Lv and Yushi Bai and Zijun Yao and Jiajie Zhang and Lei Hou and Juanzi Li , title =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. 2025 , url =
work page 2025
-
[5]
Forty-second International Conference on Machine Learning,
Dan Busbridge and Amitis Shidani and Floris Weers and Jason Ramapuram and Etai Littwin and Russell Webb , title =. Forty-second International Conference on Machine Learning,. 2025 , url =
work page 2025
-
[6]
Findings of the Association for Computational Linguistics:
Xiaoqi Jiao and Yichun Yin and Lifeng Shang and Xin Jiang and Xiao Chen and Linlin Li and Fang Wang and Qun Liu , title =. Findings of the Association for Computational Linguistics:. 2020 , url =
work page 2020
-
[7]
International Conference on Machine Learning,
Chen Liang and Simiao Zuo and Qingru Zhang and Pengcheng He and Weizhu Chen and Tuo Zhao , title =. International Conference on Machine Learning,. 2023 , url =
work page 2023
-
[8]
Victor Sanh and Lysandre Debut and Julien Chaumond and Thomas Wolf , title =. CoRR , volume =. 2019 , url =
work page 2019
-
[9]
Wenhui Wang and Furu Wei and Li Dong and Hangbo Bao and Nan Yang and Ming Zhou , title =. Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020 , year =
work page 2020
-
[10]
Findings of the Association for Computational Linguistics:
Wenhui Wang and Hangbo Bao and Shaohan Huang and Li Dong and Furu Wei , title =. Findings of the Association for Computational Linguistics:. 2021 , url =
work page 2021
-
[11]
Revisiting Intermediate-Layer Matching in Knowledge Distillation: Layer-Selection Strategy Doesn't Matter (Much) , author =. 2025 , eprint =
work page 2025
-
[12]
Simiao Zuo and Qingru Zhang and Chen Liang and Pengcheng He and Tuo Zhao and Weizhu Chen , title =. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,. 2022 , url =
work page 2022
-
[13]
The Thirteenth International Conference on Learning Representations,
Sayantan Dasgupta and Trevor Cohn , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
work page 2025
-
[14]
Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing,
Siqi Sun and Yu Cheng and Zhe Gan and Jingjing Liu , title =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing,. 2019 , url =
work page 2019
-
[15]
The Eleventh International Conference on Learning Representations,
Chen Liang and Haoming Jiang and Zheng Li and Xianfeng Tang and Bing Yin and Tuo Zhao , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
work page 2023
-
[16]
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , journal =. 2025 , url =
work page 2025
-
[17]
An Yang and Anfeng Li and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Gao and Chengen Huang and Chenxu Lv and Chujie Zheng and Dayiheng Liu and Fan Zhou and Fei Huang and Feng Hu and Hao Ge and Haoran Wei and Huan Lin and Jialong Tang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jian Yang and Jiaxi Yang and Ji...
work page 2025
- [18]
- [19]
-
[20]
Training Compute-Optimal Large Language Models , author =. 2022 , eprint =
work page 2022
-
[21]
Rosenfeld and Amir Rosenfeld and Yonatan Belinkov and Nir Shavit , title =
Jonathan S. Rosenfeld and Amir Rosenfeld and Yonatan Belinkov and Nir Shavit , title =. 8th International Conference on Learning Representations,. 2020 , url =
work page 2020
-
[22]
Diamos and Heewoo Jun and Hassan Kianinejad and Md
Joel Hestness and Sharan Narang and Newsha Ardalani and Gregory F. Diamos and Heewoo Jun and Hassan Kianinejad and Md. Mostofa Ali Patwary and Yang Yang and Yanqi Zhou , title =. CoRR , volume =. 2017 , url =
work page 2017
-
[23]
Sungsoo Ahn and Shell Xu Hu and Andreas C. Damianou and Neil D. Lawrence and Zhenwen Dai , title =. 2019 , url =
work page 2019
- [24]
-
[25]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing,
Nadir Durrani and Hassan Sajjad and Fahim Dalvi and Yonatan Belinkov , title =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing,. 2020 , url =
work page 2020
-
[26]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing,
Fahim Dalvi and Hassan Sajjad and Nadir Durrani and Yonatan Belinkov , title =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing,. 2020 , url =
work page 2020
-
[27]
Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu , title =. J. Mach. Learn. Res. , volume =. 2020 , url =
work page 2020
-
[28]
5th International Conference on Learning Representations,
Stephen Merity and Caiming Xiong and James Bradbury and Richard Socher , title =. 5th International Conference on Learning Representations,. 2017 , url =
work page 2017
-
[29]
Denis Paperno and Germ. The. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics,. 2016 , url =
work page 2016
-
[30]
Proceedings of the 57th Conference of the Association for Computational Linguistics,
Rowan Zellers and Ari Holtzman and Yonatan Bisk and Ali Farhadi and Yejin Choi , title =. Proceedings of the 57th Conference of the Association for Computational Linguistics,. 2019 , url =
work page 2019
-
[31]
WinoGrande: An Adversarial Winograd Schema Challenge at Scale , author =. 2019 , eprint =
work page 2019
-
[32]
Thirty-Fourth AAAI Conference on Artificial Intelligence , year =
Yonatan Bisk and Rowan Zellers and Ronan Le Bras and Jianfeng Gao and Yejin Choi , title =. Thirty-Fourth AAAI Conference on Artificial Intelligence , year =
- [33]
-
[34]
Elad Hoffer and Itay Hubara and Daniel Soudry , title =. Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017 , pages =. 2017 , url =
work page 2017
-
[35]
Diego Granziol and Stefan Zohren and Stephen Roberts , title =. J. Mach. Learn. Res. , volume =. 2022 , url =
work page 2022
-
[36]
Xian Shuai and Yiding Wang and Yimeng Wu and Xin Jiang and Xiaozhe Ren , title =. CoRR , volume =. 2024 , url =
work page 2024
-
[37]
Gomez and Lukasz Kaiser and Illia Polosukhin , title =
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , title =. Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017 , pages =. 2017 , url =
work page 2017
-
[38]
Language Models are Unsupervised Multitask Learners , author =. 2019 , url =
work page 2019
-
[39]
Peter J. Liu and Roman Novak and Jaehoon Lee and Mitchell Wortsman and Lechao Xiao and Katie Everett and Alexander A. Alemi and Mark Kurzeja and Pierre Marcenac and Izzeddin Gur and Simon Kornblith and Kelvin Xu and Gamaleldin Elsayed and Ian Fischer and Jeffrey Pennington and Ben Adlam and Jascha-Sohl Dickstein , title =
-
[40]
7th International Conference on Learning Representations,
Ilya Loshchilov and Frank Hutter , title =. 7th International Conference on Learning Representations,. 2019 , url =
work page 2019
-
[41]
Mathieu Blondel and Vincent Roulet , title =. CoRR , volume =. 2024 , url =
work page 2024
-
[42]
The Thirteenth International Conference on Learning Representations,
Samir Yitzhak Gadre and Georgios Smyrnis and Vaishaal Shankar and Suchin Gururangan and Mitchell Wortsman and Rulin Shao and Jean Mercat and Alex Fang and Jeffrey Li and Sedrick Keh and Rui Xin and Marianna Nezhurina and Igor Vasiljevic and Luca Soldaini and Jenia Jitsev and Alex Dimakis and Gabriel Ilharco and Pang Wei Koh and Shuran Song and Thomas Koll...
work page 2025
-
[43]
How to Scale Your Model , author =
- [44]
-
[45]
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies , author =. 2024 , eprint =
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.