Recognition: no theorem link
PointGS: Semantic-Consistent Unsupervised 3D Point Cloud Segmentation with 3D Gaussian Splatting
Pith reviewed 2026-05-13 02:18 UTC · model grok-4.3
The pith
3D Gaussian Splatting bridges discrete point clouds and continuous 2D images to deliver consistent unsupervised segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PointGS reconstructs input sparse point clouds into dense 3D Gaussian spaces from multi-view observations, renders dense images from that space, extracts 2D semantic masks with SAM, distills the semantics to Gaussian primitives through contrastive learning to enforce cross-view consistency, aligns the labeled Gaussian space to the original point cloud by two-step registration, and assigns final point semantics by nearest-neighbor lookup.
What carries the argument
3D Gaussian Splatting as unified intermediate representation that fills spatial gaps, encodes occlusion relationships, and enables consistent 2D-to-3D semantic transfer.
If this is right
- Outperforms prior unsupervised methods by +0.9% mIoU on ScanNet-V2.
- Outperforms prior unsupervised methods by +2.8% mIoU on S3DIS.
- Eliminates projection overlap and modality alignment problems that compromise semantic consistency in direct 2D-3D transfers.
- Produces semantic assignments that remain consistent across different viewpoints through contrastive distillation.
- Operates without any point-level 3D annotations while still assigning coherent labels to the input cloud.
Where Pith is reading between the lines
- The same Gaussian intermediate could be swapped in for other 2D foundation models if they supply stronger masks than SAM.
- Adding temporal constraints inside the Gaussian optimization might extend the pipeline to dynamic or video point clouds.
- Gaussian spaces could replace direct projection in other 3D tasks such as object detection or instance segmentation where view consistency matters.
- The registration step suggests that explicit dense 3D representations may become a standard bridge for any multimodal semantic transfer.
Load-bearing premise
The two-step registration between Gaussian space and original point cloud preserves semantic accuracy without introducing mismatches or drift.
What would settle it
On a dataset with ground-truth point labels, the nearest-neighbor labels from the registered Gaussians show lower mIoU than a direct projection baseline or retain visible inconsistencies across rendered views after contrastive learning.
Figures




read the original abstract
Unsupervised point cloud segmentation is critical for embodied artificial intelligence and autonomous driving, as it mitigates the prohibitive cost of dense point-level annotations required by fully supervised methods. While integrating 2D pre-trained models such as the Segment Anything Model (SAM) to supplement semantic information is a natural choice, this approach faces a fundamental mismatch between discrete 3D points and continuous 2D images. This mismatch leads to inevitable projection overlap and complex modality alignment, resulting in compromised semantic consistency across 2D-3D transfer. To address these limitations, this paper proposes PointGS, a simple yet effective pipeline for unsupervised 3D point cloud segmentation. PointGS leverages 3D Gaussian Splatting as a unified intermediate representation to bridge the discrete-continuous domain gap. Input sparse point clouds are first reconstructed into dense 3D Gaussian spaces via multi-view observations, filling spatial gaps and encoding occlusion relationships to eliminate projection-induced semantic conflation. Multi-view dense images are rendered from the Gaussian space, with 2D semantic masks extracted via SAM, and semantics are distilled to 3D Gaussian primitives through contrastive learning to ensure consistent semantic assignments across different views. The Gaussian space is aligned with the original point cloud via two-step registration, and point semantics are assigned through nearest-neighbor search on labeled Gaussians. Experiments demonstrate that PointGS outperforms state-of-the-art unsupervised methods, achieving +0.9% mIoU on ScanNet-V2 and +2.8% mIoU on S3DIS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PointGS, a pipeline for unsupervised 3D point cloud segmentation that reconstructs sparse input points into dense 3D Gaussian spaces via multi-view observations, renders dense images, extracts 2D semantic masks with SAM, distills semantics into Gaussian primitives via contrastive learning for cross-view consistency, aligns the Gaussian space back to the original point cloud via two-step registration, and assigns point labels by nearest-neighbor lookup on the labeled Gaussians. It claims to outperform prior unsupervised methods, reporting +0.9% mIoU on ScanNet-V2 and +2.8% mIoU on S3DIS.
Significance. If the results hold after addressing the transfer step, the work would offer a practical way to leverage pre-trained 2D models like SAM for 3D tasks by using 3D Gaussian Splatting as a dense intermediate that fills spatial gaps and encodes occlusions. This could incrementally advance unsupervised segmentation in embodied AI and autonomous driving, where the contrastive distillation for semantic consistency is a promising component.
major comments (1)
- [Method pipeline (Abstract and §3)] The two-step registration followed by nearest-neighbor label transfer from the labeled Gaussian space to the original sparse point cloud is load-bearing for the reported mIoU gains. The manuscript provides no quantitative evaluation of alignment accuracy, sensitivity to Gaussian density variations, or ablation removing this step, so it remains possible that the modest improvements (+0.9% on ScanNet-V2, +2.8% on S3DIS) partly reflect optimistic NN assignment rather than genuine gains in 3D semantic consistency from the contrastive learning stage.
minor comments (1)
- The abstract and method description would benefit from explicit pseudocode or a diagram detailing the two-step registration procedure and the exact contrastive loss formulation to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of validating the two-step registration and label transfer components in our pipeline. We address this concern in detail below and commit to enhancing the manuscript with additional quantitative analyses and ablations in the revised version.
read point-by-point responses
-
Referee: The two-step registration followed by nearest-neighbor label transfer from the labeled Gaussian space to the original sparse point cloud is load-bearing for the reported mIoU gains. The manuscript provides no quantitative evaluation of alignment accuracy, sensitivity to Gaussian density variations, or ablation removing this step, so it remains possible that the modest improvements (+0.9% on ScanNet-V2, +2.8% on S3DIS) partly reflect optimistic NN assignment rather than genuine gains in 3D semantic consistency from the contrastive learning stage.
Authors: The referee is correct that the two-step registration and nearest-neighbor label transfer is a critical component for evaluating the method on the original point clouds. The manuscript outlines this process in Section 3 as part of the pipeline to assign semantics back to the input points after distilling into the Gaussian space. We acknowledge the absence of quantitative evaluations for alignment accuracy, sensitivity to variations in Gaussian density, and ablations that remove or isolate this transfer step. It is possible that some of the performance gains could be influenced by the transfer mechanism, and we agree that further analysis is needed to confirm the source of the improvements. In the revised manuscript, we will add quantitative metrics assessing the accuracy of the two-step registration, experiments showing sensitivity to Gaussian density, and an ablation study that compares the full pipeline against a variant without the contrastive learning to better isolate its contribution to semantic consistency. We will also consider an ablation that bypasses the Gaussian representation to directly transfer 2D semantics, if feasible. This will help demonstrate that the semantic consistency achieved through contrastive learning in the dense Gaussian space is the primary driver of the observed mIoU improvements on ScanNet-V2 and S3DIS. revision: yes
Circularity Check
No circularity in the derivation chain
full rationale
The paper describes a multi-stage engineering pipeline that first reconstructs sparse point clouds into 3D Gaussian space via multi-view observations, renders images for SAM-based 2D masking, distills semantics via contrastive learning, performs two-step registration to the original cloud, and assigns labels by nearest-neighbor lookup. None of these steps are shown by equations or self-citation to reduce to tautological definitions of their own outputs; each relies on external, independently grounded components (3D Gaussian Splatting, SAM) whose correctness is not presupposed by the target result. Reported gains are empirical benchmark comparisons rather than predictions forced by construction from fitted inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption 3D Gaussian Splatting can accurately reconstruct dense representations from sparse point clouds and multi-view observations to fill spatial gaps and encode occlusion relationships
- domain assumption Contrastive learning on rendered multi-view images can distill consistent semantic assignments to 3D Gaussian primitives
Reference graph
Works this paper leans on
-
[1]
Zamir, Helen Jiang, Ioan- nis Brilakis, Martin Fischer, and Silvio Savarese
Iro Armeni, Ozan Sener, Amir R. Zamir, Helen Jiang, Ioan- nis Brilakis, Martin Fischer, and Silvio Savarese. 3D seman- tic parsing of large-scale indoor spaces. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1534–1543, 2016. 2
work page 2016
-
[2]
Joint 2D-3D-Semantic Data for Indoor Scene Understanding
Iro Armeni, Sasha Sax, Amir R Zamir, and Silvio Savarese. Joint 2D-3D-semantic data for indoor scene understanding. arXiv preprint arXiv:1702.01105, 2017. 6, 7
work page Pith review arXiv 2017
-
[3]
Hafsa Benallal, Nadine Abdallah Saab, Hamid Tairi, Ayman Alfalou, and Jamal Riffi. Advancements in semantic seg- mentation of 3D point clouds for scene understanding using deep learning.Technologies, 13(8):322, 2025. 3
work page 2025
-
[4]
Paul J. Besl and Neil D. McKay. Method for registration of 3-D shapes. InSensor Fusion IV: Control Paradigms and Data Structures, pages 586–606, 1992. 5
work page 1992
-
[5]
Jiazhong Cen, Jiemin Fang, Chen Yang, Lingxi Xie, Xi- aopeng Zhang, Wei Shen, and Qi Tian. Segment any 3D Gaussians. InProceedings of the AAAI Conference on Arti- ficial Intelligence, pages 1971–1979, 2025. 4, 5
work page 1971
-
[6]
Zisheng Chen, Hongbin Xu, Weitao Chen, Zhipeng Zhou, Haihong Xiao, Baigui Sun, Xuansong Xie, et al. PointDC: Unsupervised semantic segmentation of 3D point clouds via cross-modal distillation and super-voxel clustering. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14290–14299, 2023. 3, 6, 7
work page 2023
-
[7]
PiCIE: Unsupervised semantic segmentation us- ing invariance and equivariance in clustering
Jang Hyun Cho, Utkarsh Mall, Kavita Bala, and Bharath Hariharan. PiCIE: Unsupervised semantic segmentation us- ing invariance and equivariance in clustering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 16794–16804, 2021. 6, 7
work page 2021
-
[8]
Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner
Angela Dai, Angel X. Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. ScanNet: Richly-annotated 3D reconstructions of indoor scenes. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 5828–5839, 2017. 2, 6
work page 2017
-
[9]
Antoine Gu ´edon and Vincent Lepetit. SuGaR: Surface- aligned Gaussian splatting for efficient 3D mesh reconstruc- tion and high-quality mesh rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5354–5363, 2024. 4
work page 2024
-
[10]
Point cloud based scene segmentation: A survey.arXiv preprint arXiv:2503.12595,
Dan Halperin and Niklas Eisl. Point cloud based scene segmentation: A survey.arXiv preprint arXiv:2503.12595,
-
[11]
Mamba3D: Enhancing local features for 3D point cloud anal- ysis via state space model
Xu Han, Yuan Tang, Zhaoxuan Wang, and Xianzhi Li. Mamba3D: Enhancing local features for 3D point cloud anal- ysis via state space model. InProceedings of the 32nd ACM International Conference on Multimedia, pages 4995–5004,
-
[12]
SegPoint: Segment any point cloud via large language model
Shuting He, Henghui Ding, Xudong Jiang, and Bihan Wen. SegPoint: Segment any point cloud via large language model. InProceedings of the European Conference on Com- puter Vision, pages 349–367, 2024. 1
work page 2024
-
[13]
Exploring data-efficient 3D scene understanding with contrastive scene contexts
Ji Hou, Benjamin Graham, Matthias Nießner, and Saining Xie. Exploring data-efficient 3D scene understanding with contrastive scene contexts. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15587–15597, 2021. 6, 7
work page 2021
-
[14]
RandLA-Net: Efficient semantic segmentation of large-scale point clouds
Qingyong Hu, Bo Yang, Linhai Xie, Stefano Rosa, Yulan Guo, Zhihua Wang, Niki Trigoni, and Andrew Markham. RandLA-Net: Efficient semantic segmentation of large-scale point clouds. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11108– 11117, 2020. 2
work page 2020
-
[15]
Segment3D: Learning fine-grained class-agnostic 3D segmentation without manual labels
Rui Huang, Songyou Peng, Ayca Takmaz, Federico Tombari, Marc Pollefeys, Shiji Song, Gao Huang, and Francis Engel- mann. Segment3D: Learning fine-grained class-agnostic 3D segmentation without manual labels. InProceedings of the European Conference on Computer Vision, pages 278–295,
-
[16]
3D Gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3D Gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139:1– 139:14, 2023. 2, 3
work page 2023
-
[17]
GARField: Group anything with radiance fields
Chung Min Kim, Mingxuan Wu, Justin Kerr, Ken Gold- berg, Matthew Tancik, and Angjoo Kanazawa. GARField: Group anything with radiance fields. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21530–21539, 2024. 3
work page 2024
-
[18]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C. Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 4015–4026, 2023. 2, 3
work page 2023
-
[19]
Stratified trans- former for 3D point cloud segmentation
Xin Lai, Jianhui Liu, Li Jiang, Liwei Wang, Hengshuang Zhao, Shu Liu, Xiaojuan Qi, and Jiaya Jia. Stratified trans- former for 3D point cloud segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8500–8509, 2022. 2
work page 2022
-
[20]
Jiaxu Liu, Zhengdi Yu, Toby P. Breckon, and Hubert P.H. Shum. U3DS3: Unsupervised 3D semantic scene segmenta- tion. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 3759–3768, 2024. 2, 3, 6, 7
work page 2024
-
[21]
Guofeng Mei, Cristiano Saltori, Elisa Ricci, Nicu Sebe, Qiang Wu, Jian Zhang, and Fabio Poiesi. Unsupervised point cloud representation learning by clustering and neural ren- dering.International Journal of Computer Vision, 132(8): 3251–3269, 2024. 3
work page 2024
-
[22]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. DINOv2: Learning robust visual features without supervi- sion.arXiv preprint arXiv:2304.07193, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Jinyoung Park, Sanghyeok Lee, Sihyeon Kim, Yunyang Xiong, and Hyunwoo J. Kim. Self-positioning point-based transformer for point cloud understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21814–21823, 2023. 1
work page 2023
-
[24]
OA-CNNs: Omni-adaptive sparse CNNs for 3D semantic segmentation
Bohao Peng, Xiaoyang Wu, Li Jiang, Yukang Chen, Heng- shuang Zhao, Zhuotao Tian, and Jiaya Jia. OA-CNNs: Omni-adaptive sparse CNNs for 3D semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21305–21315, 2024. 2
work page 2024
-
[25]
Qi, Hao Su, Kaichun Mo, and Leonidas J
Charles R. Qi, Hao Su, Kaichun Mo, and Leonidas J. Guibas. PointNet: Deep learning on point sets for 3D classification and segmentation. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 652–660, 2017. 1, 2
work page 2017
-
[26]
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J. Guibas. PointNet++: Deep hierarchical feature learning on point sets in a metric space. InAdvances in Neural Informa- tion Processing Systems, pages 5099–5108, 2017. 1, 2
work page 2017
-
[27]
PointNeXt: Revisiting PointNet++ with improved training and scaling strategies
Guocheng Qian, Yuchen Li, Houwen Peng, Jinjie Mai, Hasan Hammoud, Mohamed Elhoseiny, and Bernard Ghanem. PointNeXt: Revisiting PointNet++ with improved training and scaling strategies. InAdvances in Neural Infor- mation Processing Systems, pages 23192–23204, 2022. 2
work page 2022
-
[28]
3D spatial recognition without spatially la- beled 3D
Zhongzheng Ren, Ishan Misra, Alexander G Schwing, and Rohit Girdhar. 3D spatial recognition without spatially la- beled 3D. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13204– 13213, 2021. 6, 7
work page 2021
-
[29]
Un- Scene3D: Unsupervised 3D instance segmentation for in- door scenes
David Rozenberszki, Or Litany, and Angela Dai. Un- Scene3D: Unsupervised 3D instance segmentation for in- door scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19957– 19967, 2024. 2, 3
work page 2024
-
[30]
Sushmita Sarker, Prithul Sarker, Gunner Stone, Ryan Gor- man, Alireza Tavakkoli, George Bebis, and Javad Sattarvand. A comprehensive overview of deep learning techniques for 3D point cloud classification and semantic segmentation. Machine Vision and Applications, 35(4):67, 2024. 2
work page 2024
-
[31]
Flash- Splat: 2D-to-3D Gaussian splatting segmentation solved op- timally
Qiuhong Shen, Xingyi Yang, and Xinchao Wang. Flash- Splat: 2D-to-3D Gaussian splatting segmentation solved op- timally. InProceedings of the European Conference on Com- puter Vision, pages 456–472, 2024. 5
work page 2024
-
[32]
ProtoTransfer: Cross-modal prototype transfer for point cloud segmenta- tion
Pin Tang, Hai-Ming Xu, and Chao Ma. ProtoTransfer: Cross-modal prototype transfer for point cloud segmenta- tion. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 3337–3347, 2023. 1
work page 2023
-
[33]
Qi, Jean-Emmanuel Deschaud, Beatriz Marcotegui, Franc ¸ois Goulette, and Leonidas J
Hugues Thomas, Charles R. Qi, Jean-Emmanuel Deschaud, Beatriz Marcotegui, Franc ¸ois Goulette, and Leonidas J. Guibas. KPConv: Flexible and deformable convolution for point clouds. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6411–6420, 2019. 2
work page 2019
-
[34]
Jingyi Wang, Yu Liu, Hanlin Tan, and Maojun Zhang. A survey on weakly supervised 3D point cloud semantic seg- mentation.IET Computer Vision, 18(3):329–342, 2024. 3
work page 2024
-
[35]
P2P: Tuning pre-trained image models for point cloud analysis with point-to-pixel prompting
Ziyi Wang, Xumin Yu, Yongming Rao, Jie Zhou, and Ji- wen Lu. P2P: Tuning pre-trained image models for point cloud analysis with point-to-pixel prompting. InAdvances in Neural Information Processing Systems, pages 14388– 14402, 2022. 2, 3
work page 2022
-
[36]
Point Transformer V2: Grouped vector at- tention and partition-based pooling
Xiaoyang Wu, Yixing Lao, Li Jiang, Xihui Liu, and Heng- shuang Zhao. Point Transformer V2: Grouped vector at- tention and partition-based pooling. InAdvances in Neural Information Processing Systems, pages 33330–33342, 2022. 2
work page 2022
-
[37]
Point Transformer V3: Simpler, faster, stronger
Xiaoyang Wu, Li Jiang, Peng-Shuai Wang, Zhijian Liu, Xi- hui Liu, Yu Qiao, Wanli Ouyang, Tong He, and Hengshuang Zhao. Point Transformer V3: Simpler, faster, stronger. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 4840–4851, 2024. 1, 2
work page 2024
-
[38]
Yuanchen Wu, Xiaoqiang Li, Jide Li, Kequan Yang, Pinpin Zhu, and Shaohua Zhang. DINO is also a semantic guider: Exploiting class-aware affinity for weakly supervised seman- tic segmentation. InProceedings of the 32nd ACM Interna- tional Conference on Multimedia, pages 1389–1397, 2024. 1
work page 2024
-
[39]
GSV A: Generalized segmentation via multimodal large language models
Zhuofan Xia, Dongchen Han, Yizeng Han, Xuran Pan, Shiji Song, and Gao Huang. GSV A: Generalized segmentation via multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3858–3869, 2024. 1
work page 2024
-
[40]
Unsupervised point cloud rep- resentation learning with deep neural networks: A survey
Aoran Xiao, Jiaxing Huang, Dayan Guan, Xiaoqin Zhang, Shijian Lu, and Ling Shao. Unsupervised point cloud rep- resentation learning with deep neural networks: A survey. IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 45(9):11321–11339, 2023. 3
work page 2023
-
[41]
Gaussian Grouping: Segment and edit anything in 3D scenes
Mingqiao Ye, Martin Danelljan, Fisher Yu, and Lei Ke. Gaussian Grouping: Segment and edit anything in 3D scenes. InProceedings of the European Conference on Com- puter Vision, pages 162–179, 2024. 5
work page 2024
-
[42]
SAI3D: Segment any instance in 3D scenes
Yingda Yin, Yuzheng Liu, Yang Xiao, Daniel Cohen-Or, Jingwei Huang, and Baoquan Chen. SAI3D: Segment any instance in 3D scenes. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 3292–3302, 2024. 2
work page 2024
-
[43]
Point-BERT: Pre-training 3D point cloud transformers with masked point modeling
Xumin Yu, Lulu Tang, Yongming Rao, Tiejun Huang, Jie Zhou, and Jiwen Lu. Point-BERT: Pre-training 3D point cloud transformers with masked point modeling. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19313–19322, 2022. 1, 2
work page 2022
-
[44]
COB-GS: Clear object boundaries in 3DGS seg- mentation based on boundary-adaptive Gaussian splitting
Jiaxin Zhang, Junjun Jiang, Youyu Chen, Kui Jiang, and Xi- anming Liu. COB-GS: Clear object boundaries in 3DGS seg- mentation based on boundary-adaptive Gaussian splitting. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 19335–19344, 2025. 5
work page 2025
-
[45]
GrowSP: Unsupervised semantic segmentation of 3D point clouds
Zihui Zhang, Bo Yang, Bing Wang, and Bo Li. GrowSP: Unsupervised semantic segmentation of 3D point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 17619–17629, 2023. 2, 3, 7
work page 2023
-
[46]
Zihui Zhang, Weisheng Dai, Hongtao Wen, and Bo Yang. LogoSP: Local-global grouping of superpoints for unsuper- vised semantic segmentation of 3D point clouds. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1374–1384, 2025. 2, 3, 6, 7
work page 2025
-
[47]
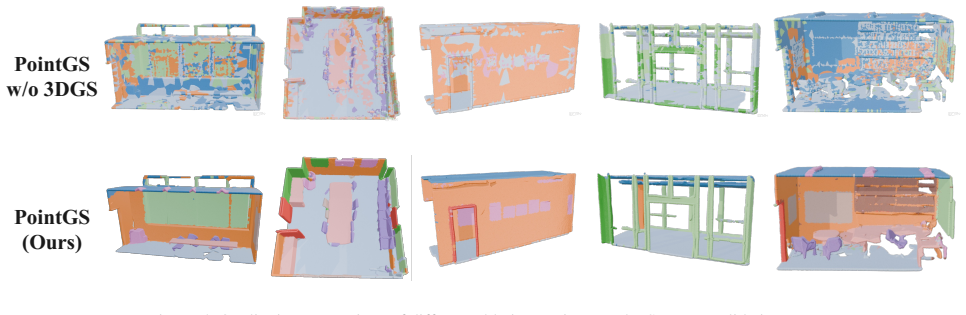
Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip H. S. Torr, and Vladlen Koltun. Point Transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16259–16268, 2021. 2 PointGS: Semantic-Consistent Unsupervised 3D Point Cloud Segmentation with 3D Gaussian Splatting Supplementary Material Input Ours GT Figure 4. Qualitative com...
work page 2021
-
[48]
Additional Experiments Due to space constraints in the main text, some of the ex- periments are placed in this supplementary material. 7.1. Qualitative Experiment on ScanNet-v2 To verify the performance on the ScanNet-v2 dataset, we conduct additional visual experiments on this dataset. As shown in Fig. 4, the performance of our method on the ScanNet data...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.