Recognition: no theorem link
Efficient and provably convergent end-to-end training of deep neural networks with linear constraints
Pith reviewed 2026-05-13 01:49 UTC · model grok-4.3
The pith
An HS-Jacobian serves as a conservative mapping for polyhedral projections, enabling efficient end-to-end training of linearly constrained deep neural networks with convergence guarantees for algorithms like Adam.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the HS-Jacobian of the projection operator onto any polyhedral set is a conservative mapping. Because it can be computed efficiently, it integrates without modification into the nonsmooth automatic differentiation pipeline used for backpropagation. Consequently, standard first-order methods such as Adam become applicable to end-to-end training of deep networks whose layer outputs satisfy linear constraints, and the resulting training algorithm is provably convergent.
What carries the argument
The HS-Jacobian of the projection operator onto a polyhedral set, shown to be a conservative mapping that supports direct use inside nonsmooth automatic differentiation.
If this is right
- Standard optimizers such as Adam can be used without alteration for the full end-to-end training.
- Convergence of the training procedure is guaranteed when the HS-Jacobian is employed.
- The same layer can be dropped into networks for finance, computer vision, and architecture-search tasks.
- Performance exceeds that of earlier projection-based or penalty-based methods on the reported benchmarks.
Where Pith is reading between the lines
- Frameworks that already implement nonsmooth automatic differentiation can adopt the layer with only a local change to the projection routine.
- The same conservative-mapping idea may apply to other common nonsmooth layers such as ReLU or max-pooling when linear side constraints are present.
- If the polyhedral set changes during training, recomputing the HS-Jacobian at each step remains cheap enough to keep the overall procedure practical.
Load-bearing premise
That the HS-Jacobian is a conservative mapping for the projection onto every polyhedral set and that this single property is enough to guarantee correct behavior inside any nonsmooth automatic differentiation framework.
What would settle it
A concrete polyhedral set for which the HS-Jacobian fails to satisfy the conservative mapping definition, or a linearly constrained network where Adam training using the HS-Jacobian diverges.
Figures


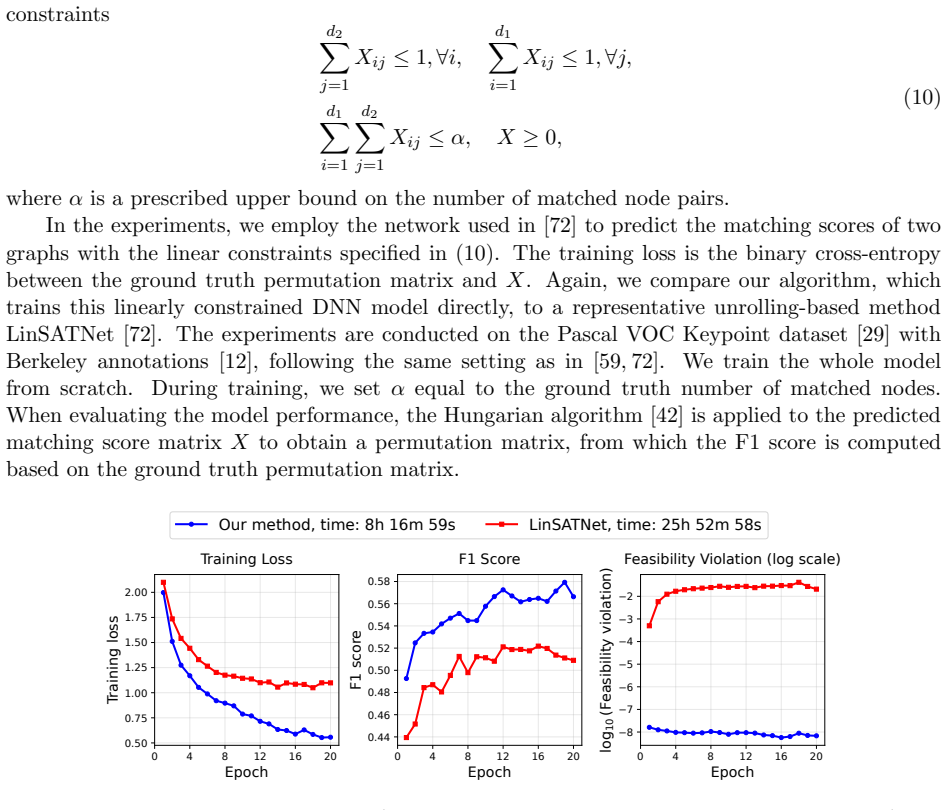

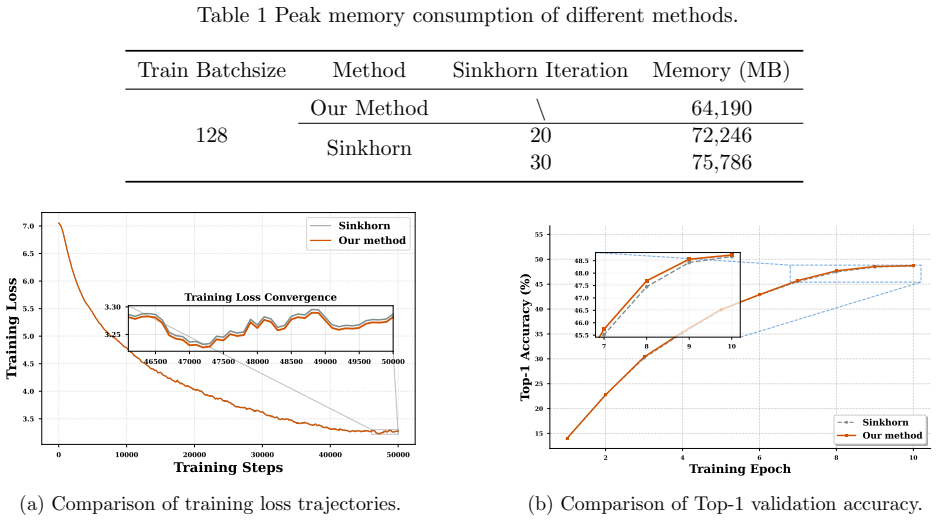

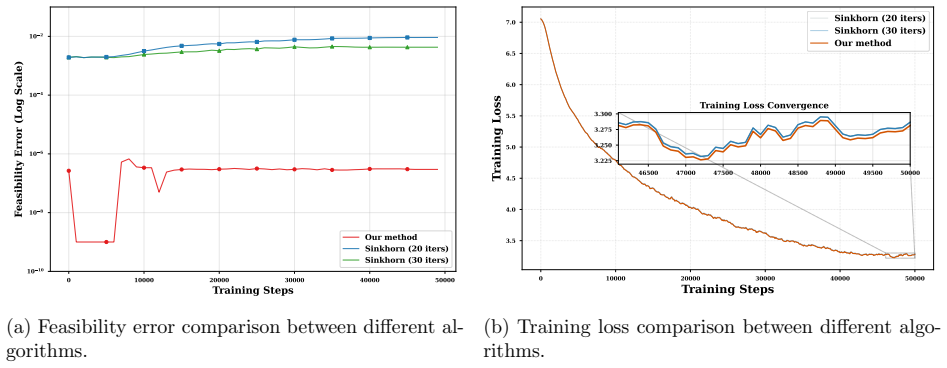
read the original abstract
Training a deep neural network with the outputs of selected layers satisfying linear constraints is required in many contemporary data-driven applications. While this can be achieved by incorporating projection layers into the neural network, its end-to-end training remains challenging due to the lack of rigorous theory and efficient algorithms for backpropagation. A key difficulty in developing the theory and efficient algorithms for backpropagation arose from the nonsmoothness of the solution mapping of the projection layer. To address this bottleneck, we introduce an efficiently computable HS-Jacobian to the projection layer. Importantly, we prove that the HS-Jacobian is a conservative mapping for the projection operator onto the polyhedral set, enabling its seamless integration into the nonsmooth automatic differentiation framework for backpropagation. Therefore, many efficient algorithms, such as Adam, can be applied for end-to-end training of deep neural networks with linear constraints. Particularly, we establish convergence guarantees of the HS-Jacobian based Adam algorithm for training linearly constrained deep neural networks. Extensive experiment results on several important applications, including finance, computer vision, and network architecture design, demonstrate the superior performance of our method compared to other existing popular methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an efficiently computable HS-Jacobian for the Euclidean projection layer onto polyhedral sets, proves that this Jacobian is a conservative mapping, and shows that it integrates with nonsmooth automatic differentiation to permit end-to-end training of DNNs with linear constraints via standard first-order methods such as Adam. Convergence of the resulting Adam iteration is established, and experiments on finance, computer-vision, and architecture-design tasks report improved performance over existing projection-based baselines.
Significance. If the conservative-mapping claim holds for arbitrary polyhedra without hidden restrictions on active-set geometry or constraint qualification, the work would remove a long-standing obstacle to reliable back-propagation through projection layers, allowing provably convergent training with off-the-shelf optimizers. The explicit convergence analysis and the provision of reproducible code would constitute a concrete advance over prior heuristic treatments of constrained DNNs.
major comments (2)
- [§4.2, Theorem 3] §4.2, Theorem 3 and the surrounding proof of the conservative property: the argument that the HS-Jacobian belongs to the conservative field of the projection operator relies on a specific selection rule within the normal cone; it is not shown that this selection remains valid for degenerate active sets or when strict complementarity fails at some iterates. A counter-example or an explicit statement of the required constraint qualification is needed, because the chain-rule property used by nonsmooth AD frameworks and the subsequent Lyapunov argument for Adam convergence both depend on the conservative property holding without qualification.
- [§5, Theorem 4] §5, Algorithm 1 and Theorem 4: the convergence guarantee for HS-Jacobian-based Adam is derived under the assumption that the conservative mapping property established in §4 holds at every training iterate. If the proof in §4.2 admits restrictions on polyhedral geometry, the convergence statement does not automatically extend to the general linear constraints appearing in the cited applications (e.g., portfolio constraints or simplex constraints with equality).
minor comments (2)
- [Definition 2] Notation for the HS-Jacobian (Definition 2) is introduced without an explicit comparison to the classical Clarke Jacobian or to the limiting Jacobian; a short remark clarifying the relationship would help readers situate the contribution.
- [Experiments] Figure 2 and the experimental tables report mean and standard deviation over 5 runs, but do not state whether the same random seeds or data splits were used across all compared methods; this detail affects reproducibility claims.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review of our manuscript. The two major comments raise important questions about the scope of the conservative-mapping result and its consequences for the convergence analysis. We address each point below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [§4.2, Theorem 3] §4.2, Theorem 3 and the surrounding proof of the conservative property: the argument that the HS-Jacobian belongs to the conservative field of the projection operator relies on a specific selection rule within the normal cone; it is not shown that this selection remains valid for degenerate active sets or when strict complementarity fails at some iterates. A counter-example or an explicit statement of the required constraint qualification is needed, because the chain-rule property used by nonsmooth AD frameworks and the subsequent Lyapunov argument for Adam convergence both depend on the conservative property holding without qualification.
Authors: We appreciate the referee drawing attention to this aspect of the proof. The HS-Jacobian is obtained by solving a linear system whose right-hand side is a particular selection from the normal cone to the active constraints at the projected point. Because the feasible set is polyhedral, the projection operator is piecewise affine and the normal cone is itself polyhedral; the selected vector is always an extreme ray of the normal cone generated by the active constraints and therefore lies in the Clarke subdifferential (hence in the conservative field) irrespective of degeneracy or the failure of strict complementarity. The argument never invokes strict complementarity or any other CQ beyond polyhedrality. To make this explicit we will (i) insert a short paragraph immediately after the proof of Theorem 3 stating that the result holds for arbitrary polyhedra without additional qualifications, and (ii) add a brief numerical illustration of a degenerate active-set case in the revised appendix. revision: partial
-
Referee: [§5, Theorem 4] §5, Algorithm 1 and Theorem 4: the convergence guarantee for HS-Jacobian-based Adam is derived under the assumption that the conservative mapping property established in §4 holds at every training iterate. If the proof in §4.2 admits restrictions on polyhedral geometry, the convergence statement does not automatically extend to the general linear constraints appearing in the cited applications (e.g., portfolio constraints or simplex constraints with equality).
Authors: Theorem 4 is stated for any polyhedral constraint set precisely because Theorem 3 establishes the conservative property for arbitrary polyhedra. The portfolio and simplex examples used in the experiments are polyhedral, so the convergence guarantee applies directly. We will revise the statement of Theorem 4 and the paragraph preceding Algorithm 1 to emphasize that the result requires only that the constraint set be polyhedral, thereby covering all applications mentioned in the paper. revision: partial
Circularity Check
No circularity: HS-Jacobian and convergence proofs are self-contained mathematical constructions
full rationale
The paper introduces the HS-Jacobian as a new, efficiently computable object for the projection layer onto polyhedra, then proves it belongs to the conservative field of the Euclidean projection operator. Convergence of the resulting Adam variant is established via a separate Lyapunov argument that does not rely on re-using fitted parameters or prior self-citations as load-bearing premises. No equation reduces by definition to its own input, no prediction is a renamed fit, and the central claims rest on explicit proofs rather than ansatz smuggling or uniqueness theorems imported from the authors' earlier work. The derivation chain is therefore independent of the target results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The projection operator onto a polyhedral set admits an efficiently computable HS-Jacobian that is a conservative mapping.
invented entities (1)
-
HS-Jacobian
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A. Agrawal, B. Amos, S. Barratt, S. Boyd, S. Diamond, and J. Z. Kolter , Differentiable Convex Optimization Layers , Advances in Neural Information Processing Systems, 32 (2019)
work page 2019
-
[2]
A. Agrawal, S. Barratt, S. Boyd, E. Busseti, and W. M. Moursi , Differentiating Through a Cone Program , Journal of Applied and Numerical Optimization, 1 (2019), pp. 107--115
work page 2019
-
[3]
C. D. Aliprantis and K. C. Border , Infinite Dimensional Analysis: A Hitchhiker’s Guide , Springer, 2006
work page 2006
-
[4]
B. Amos , Differentiable Optimization-Based Modeling for Machine Learning , PhD thesis, Carnegie Mellon University, Pittsburgh, PA, 2019
work page 2019
-
[5]
B. Amos and J. Z. Kolter , OptNet: Differentiable Optimization as a Layer in Neural Networks , in International Conference on Machine Learning, PMLR, 2017, pp. 136--145
work page 2017
-
[6]
S. Barratt , On the Differentiability of the Solution to Convex Optimization Problems , arXiv preprint arXiv:1804.05098, (2018)
-
[7]
A. G. Baydin, B. A. Pearlmutter, A. A. Radul, and J. M. Siskind , Automatic Differentiation in Machine Learning: a Survey , Journal of Machine Learning Research, 18 (2018), pp. 1--43
work page 2018
-
[8]
E. Bierstone and P. D. Milman , Semianalytic and subanalytic sets , Publications Math \'e matiques de l'IH \'E S, 67 (1988), pp. 5--42
work page 1988
- [9]
- [10]
-
[11]
J. Bolte and E. Pauwels , Conservative set valued fields, automatic differentiation, stochastic gradient methods and deep learning , Mathematical Programming, 188 (2021), pp. 19--51
work page 2021
-
[12]
L. Bourdev and J. Malik , Poselets: Body Part Detectors Trained Using 3D Human Pose Annotations , in 2009 IEEE 12th International Conference on Computer Vision, IEEE, 2009, pp. 1365--1372
work page 2009
-
[13]
D. Cao, Y. Wang, J. Duan, C. Zhang, X. Zhu, C. Huang, Y. Tong, B. Xu, J. Bai, J. Tong, et al. , Spectral Temporal Graph Neural Network for Multivariate Time-series Forecasting , Advances in Neural Information Processing Systems, 33 (2020), pp. 17766--17778
work page 2020
- [14]
-
[15]
T. Chen, B. Xu, C. Zhang, and C. Guestrin , Training Deep Nets with Sublinear Memory Cost , arXiv preprint arXiv:1604.06174, (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[16]
M. Cho, J. Lee, and K. M. Lee , Reweighted Random Walks for Graph Matching , in European Conference on Computer vision, Springer, 2010, pp. 492--505
work page 2010
-
[17]
F. H. Clarke , Generalized gradients and applications , Transactions of the American Mathematical Society, 205 (1975), pp. 247--262
work page 1975
-
[18]
F. H. Clarke , Optimization and Nonsmooth Analysis , Society for Industrial and Applied Mathematics, 1983
work page 1983
-
[19]
Coste , An Introduction to O-minimal Geometry , 1999
M. Coste , An Introduction to O-minimal Geometry , 1999
work page 1999
-
[20]
height 2pt depth -1.6pt width 23pt, An Introduction to Semialgebraic Geometry , 2002
work page 2002
-
[21]
M. Cuturi , Sinkhorn Distances: Lightspeed Computation of Optimal Transport , Advances in Neural Information Processing Systems, 26 (2013)
work page 2013
-
[22]
D. Davis and D. Drusvyatskiy , Conservative and Semismooth Derivatives are Equivalent for Semialgebraic Maps , Set-Valued and Variational Analysis, 30 (2022), pp. 453--463
work page 2022
- [23]
-
[24]
DeepSeek-AI , Deepseek-v4: Towards highly efficient million-token context intelligence , 2026
work page 2026
-
[25]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei , Imagenet: A Large-Scale Hierarchical Image Database , in 2009 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, 2009, pp. 248--255
work page 2009
-
[26]
M. P. Denkowski and P. Pe szy \'n ska , On definable multifunctions and ojasiewicz inequalities , Journal of Mathematical Analysis and Applications, 456 (2017), pp. 1101--1122
work page 2017
-
[27]
A. L. Dontchev and R. T. Rockafellar , Implicit Functions and Solution Mappings , vol. 543, Springer, 2009
work page 2009
-
[28]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby , An image is worth 16x16 words: Transformers for image recognition at scale , in International Conference on Learning Representations, 2021
work page 2021
-
[29]
M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman , The Pascal Visual Object Classes (VOC) Challenge , International Journal of Computer Vision, 88 (2010), pp. 303--338
work page 2010
-
[30]
F. Facchinei and J.-S. Pang , Finite-Dimensional Variational Inequalities and Complementarity Problems , Springer Science & Business Media, 2003
work page 2003
-
[31]
M. Fey, J. E. Lenssen, F. Weichert, and H. M \"u ller , SplineCNN: Fast Geometric Deep Learning with Continuous B-Spline Kernels , in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 869--877
work page 2018
-
[32]
A. V. Fiacco , Sensitivity analysis for nonlinear programming using penalty methods , Mathematical Programming, 10 (1976), pp. 287--311
work page 1976
-
[33]
A. V. Fiacco and G. P. McCormick , Nonlinear Programming: Sequential Unconstrained Minimization Techniques , SIAM, 1990
work page 1990
-
[34]
A. Griewank and A. Walther , Evaluating Derivatives: Principles and Techniques of Algorithmic Differentiation , SIAM, 2008
work page 2008
-
[35]
Gurobi Optimization, LLC , Gurobi Optimizer Reference Manual , 2026
work page 2026
- [36]
-
[37]
Haraux , How to differentiate the projection on a convex set in Hilbert space
A. Haraux , How to differentiate the projection on a convex set in Hilbert space. Some applications to variational inequalities , Journal of the Mathematical Society of Japan, 29 (1977), pp. 615--631
work page 1977
-
[38]
K. He, X. Zhang, S. Ren, and J. Sun , Deep Residual Learning for Image Recognition , in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770--778
work page 2016
-
[39]
R. Jagannathan and T. Ma , Risk Reduction in Large Portfolios: Why Imposing the Wrong Constraints Helps , The Journal of Finance, 58 (2003), pp. 1651--1683
work page 2003
-
[40]
A. G. Khovanskii , A class of systems of transcendental equations , in Doklady akademii nauk, vol. 255, Russian Academy of Sciences, 1980, pp. 804--807
work page 1980
-
[41]
D. P. Kingma and J. Ba , Adam: A Method for Stochastic Optimization , in International Conference on Learning Representations (ICLR), 2015
work page 2015
-
[42]
H. Kuhn , The Hungarian method for the assignment problem , Naval Research Logistics Quarterly, 2 (1955), pp. 83--97
work page 1955
- [43]
-
[44]
M. Leordeanu and M. Hebert , A Spectral Technique for Correspondence Problems Using Pairwise Constraints , in Tenth IEEE International Conference on Computer Vision (ICCV'05) Volume 1, IEEE, 2005, pp. 1482--1489
work page 2005
-
[45]
X. Li, D. Sun, and K.-C. Toh , On the efficient computation of a generalized Jacobian of the projector over the Birkhoff polytope , Mathematical Programming, 179 (2020), pp. 419--446
work page 2020
- [46]
- [47]
-
[48]
A. L. Maas, A. Y. Hannun, A. Y. Ng, et al. , Rectifier Nonlinearities Improve Neural Network Acoustic Models , in Proc. ICML, vol. 30, Atlanta, GA, 2013, p. 3
work page 2013
-
[49]
C. W. Magoon, F. Yang, N. Aigerman, and S. Z. Kovalsky , Differentiation Through Black-Box Quadratic Programming Solvers , in The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[50]
Marker , Model Theory and Exponentiation , Notices of the AMS, 43 (1996), pp
D. Marker , Model Theory and Exponentiation , Notices of the AMS, 43 (1996), pp. 753--759
work page 1996
-
[51]
height 2pt depth -1.6pt width 23pt, Model Theory: An Introduction , Springer, 2002
work page 2002
-
[52]
B. Mordukhovich , Variational Analysis and Generalized Differentiation I: Basic Theory , Grundlehren der mathematischen Wissenschaften, Springer Berlin Heidelberg, 2012
work page 2012
-
[53]
V. Nair and G. E. Hinton , Rectified Linear Units Improve Restricted Boltzmann Machines , in Proceedings of the 27th International Conference on Machine Learning (ICML-10), 2010, pp. 807--814
work page 2010
-
[54]
A. Pillay and C. Steinhorn , Definable sets in ordered structures , Bulletin of the American Mathematical Society, 11 (1984), pp. 159--162
work page 1984
-
[55]
U ber partielle und totale differenzierbarkeit von funktionen mehrerer variabeln und \
H. Rademacher , \"U ber partielle und totale differenzierbarkeit von funktionen mehrerer variabeln und \"u ber die transformation der doppelintegrale , Mathematische Annalen, 79 (1919), pp. 340--359
work page 1919
-
[56]
S. M. Robinson , Local structure of feasible sets in nonlinear programming, part iii: stability and sensitivity , Mathematical Programming Study, 30 (1987), pp. 45--66
work page 1987
-
[57]
Rockafellar , Convex Analysis , Princeton Math
R. Rockafellar , Convex Analysis , Princeton Math. Series, 28 (1970)
work page 1970
-
[58]
R. T. Rockafellar and R. J. Wets , Variational Analysis , Springer, 1998
work page 1998
-
[59]
M. Rol \' nek, P. Swoboda, D. Zietlow, A. Paulus, V. Musil, and G. Martius , Deep Graph Matching via Blackbox Differentiation of Combinatorial Solvers , in European Conference on Computer Vision, Springer, 2020, pp. 407--424
work page 2020
-
[60]
D. E. Rumelhart, G. E. Hinton, and R. J. Williams , Learning representations by back-propagating errors , Nature, 323 (1986), pp. 533--536
work page 1986
-
[61]
Seidenberg , A new decision method for elementary algebra , Annals of Mathematics, 60 (1954), pp
A. Seidenberg , A new decision method for elementary algebra , Annals of Mathematics, 60 (1954), pp. 365--374
work page 1954
-
[62]
W. F. Sharpe , Mutual fund performance , The Journal of Business, 39 (1966), pp. 119--138
work page 1966
-
[63]
height 2pt depth -1.6pt width 23pt, The Sharpe ratio , Journal of Portfolio Management, 21 (1994), pp. 49--58
work page 1994
-
[64]
K. Simonyan and A. Zisserman , Very Deep Convolutional Networks for Large-Scale Image Recognition , in 3rd International Conference on Learning Representations (ICLR 2015), Computational and Biological Learning Society, 2015
work page 2015
-
[65]
R. Sinkhorn and P. Knopp , Concerning nonnegative matrices and doubly stochastic matrices , Pacific Journal of Mathematics, 21 (1967), pp. 343--348
work page 1967
-
[66]
B. Stellato, G. Banjac, P. Goulart, A. Bemporad, and S. Boyd , OSQP: An operator splitting solver for quadratic programs , in 2018 UKACC 12th International Conference on Control (CONTROL), IEEE, 2018, pp. 339--339
work page 2018
-
[67]
D. Sun , A further result on an implicit function theorem for locally lipschitz functions , Operations Research Letters, 28 (2001), pp. 193--198
work page 2001
-
[68]
J. Tan, B. Li, X. Lu, Y. Yao, F. Yu, T. He, and W. Ouyang , The Equalization Losses: Gradient-Driven Training for Long-Tailed Object Recognition , IEEE Transactions on Pattern Analysis and Machine Intelligence, 45 (2023), pp. 13876--13892
work page 2023
-
[69]
A. Tarski , A Decision Method for Elementary Algebra and Geometry , Journal of Symbolic Logic, 17 (1952)
work page 1952
-
[70]
L. van den Dries and C. Miller , Geometric categories and O-minimal structures , Duke Mathematical Journal, 84 (1996), pp. 497--540
work page 1996
-
[71]
R. Wang, J. Yan, and X. Yang , Neural Graph Matching Network: Learning Lawler’s Quadratic Assignment Problem With Extension to Hypergraph and Multiple-Graph Matching , IEEE Transactions on Pattern Analysis and Machine Intelligence, 44 (2021), pp. 5261--5279
work page 2021
-
[72]
R. Wang, Y. Zhang, Z. Guo, T. Chen, X. Yang, and J. Yan , LinSATNet: The Positive Linear Satisfiability Neural Networks , in International Conference on Machine Learning, PMLR, 2023, pp. 36605--36625
work page 2023
-
[73]
A. J. Wilkie , Model completeness results for expansions of the ordered field of real numbers by restricted Pfaffian functions and the exponential function , Journal of the American Mathematical Society, 9 (1996), pp. 1051--1094
work page 1996
-
[74]
N. Xiao, X. Hu, X. Liu, and K.-C. Toh , Adam-family Methods for Nonsmooth Optimization with Convergence Guarantees , Journal of Machine Learning Research, 25 (2024), pp. 1--53
work page 2024
- [75]
-
[76]
mixup: Beyond Empirical Risk Minimization
H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz , mixup: Beyond Empirical Risk Minimization , arXiv preprint arXiv:1710.09412, (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [77]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.