Recognition: no theorem link
UNIPO: Unified Interactive Visual Explanation for RL Fine-Tuning Policy Optimization
Pith reviewed 2026-05-13 01:35 UTC · model grok-4.3
The pith
UNIPO supplies the first interactive visualization that unifies token-level training dynamics across RL fine-tuning algorithms for language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
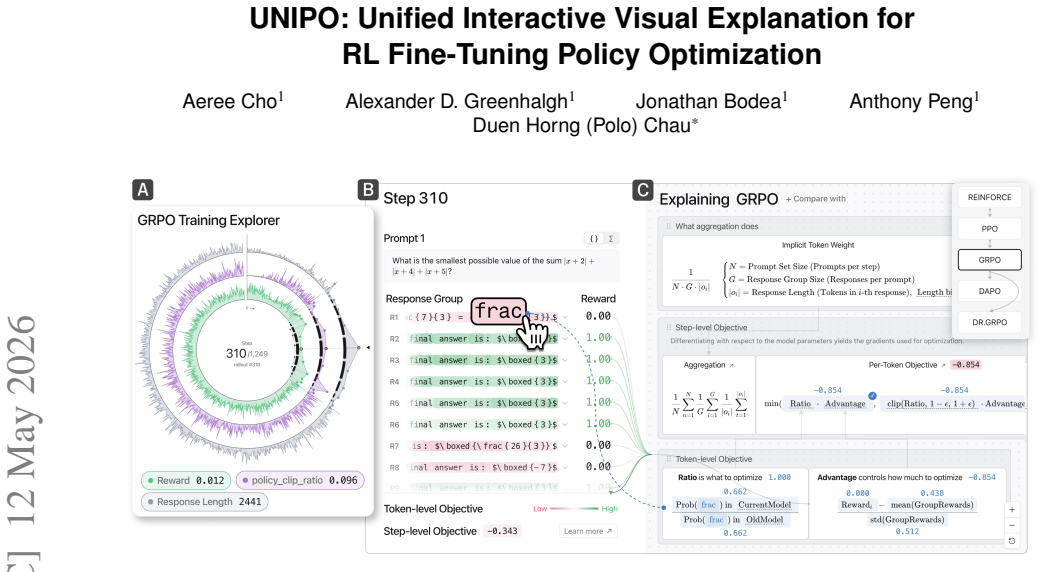
UNIPO is presented as the first interactive visualization tool that exposes the token-level training dynamics of RL fine-tuning algorithms through a unified design. It integrates a high-level training overview, a step-level prompt and response inspector, and a side-by-side algorithm comparison to let users trace how modular differences in clipping, advantage estimation, and reward aggregation propagate through training.
What carries the argument
The unified design that connects three complementary interactive views exposing token-level training dynamics.
Load-bearing premise
That inconsistent notation across papers creates a meaningful barrier and that an interactive visualization will help non-experts and practitioners compare and select algorithms more effectively.
What would settle it
A controlled study in which participants shown the original papers identify differences in clipping or advantage estimation as accurately and quickly as participants using UNIPO.
Figures


read the original abstract
Reinforcement learning has emerged as a dominant technique for fine-tuning the behavior of large language models, with policy optimization (PO) algorithms such as GRPO, DAPO, and Dr. GRPO emerging in rapid succession to advance state-of-the-art reasoning and alignment performance. However, the modular differences between these algorithms, including targeted improvements to clipping, advantage estimation, and reward aggregation, are introduced across separate papers with inconsistent notation, making them difficult to compare and intimidating to the non-expert community. We present UNIPO, the first interactive visualization tool that exposes the token-level training dynamics of RL fine-tuning algorithms through a unified design. UNIPO connects three complementary views, a high-level training overview, a step-level prompt and response inspector, and a side-by-side algorithm comparison, allowing learners to observe how individual design decisions propagate through training. Through two usage scenarios, we demonstrate how UNIPO supports both classroom instruction for non-experts and algorithm selection for AI practitioners. Our tool is open-source and publicly available at https://poloclub.github.io/unipo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UNIPO, an open-source interactive visualization tool for unifying the explanation of token-level training dynamics in RL fine-tuning algorithms such as GRPO, DAPO, and Dr. GRPO. It integrates three complementary views—a high-level training overview, a step-level prompt and response inspector, and a side-by-side algorithm comparison—to allow observation of how design decisions propagate through training. The authors claim it is the first such tool and demonstrate its utility for classroom instruction to non-experts and algorithm selection by practitioners through two usage scenarios.
Significance. If the tool's unified views prove effective at exposing token-level dynamics and aiding comparison despite inconsistent notations across papers, it could meaningfully lower barriers for non-experts learning RL fine-tuning and support practitioners in evaluating algorithmic variants, contributing to education and informed development in LLM alignment.
major comments (2)
- [Abstract] Abstract: the claim that UNIPO is 'the first interactive visualization tool that exposes the token-level training dynamics of RL fine-tuning algorithms through a unified design' is presented without any systematic comparison to prior visualization tools or literature on RL/LLM explanation interfaces, which is load-bearing for the novelty positioning.
- [Abstract] Abstract (usage scenarios): the central claims that the tool 'supports both classroom instruction for non-experts and algorithm selection for AI practitioners' rest solely on two narrative usage scenarios with no accompanying user studies, learning metrics, task performance data, or controlled comparisons to baseline resources such as papers or other tools.
minor comments (1)
- The manuscript would benefit from explicit discussion of how the three views handle specific modular differences (e.g., clipping, advantage estimation) in a way that resolves notation inconsistencies, with concrete examples tied to the views.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, indicating where we agree and the specific revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that UNIPO is 'the first interactive visualization tool that exposes the token-level training dynamics of RL fine-tuning algorithms through a unified design' is presented without any systematic comparison to prior visualization tools or literature on RL/LLM explanation interfaces, which is load-bearing for the novelty positioning.
Authors: We agree that the novelty positioning would be strengthened by a more systematic comparison. While the manuscript contains a Related Work section discussing prior RL visualization efforts, it does not include an exhaustive survey or explicit feature comparison. In the revised manuscript we will expand Related Work with a dedicated subsection surveying existing visualization tools for RL training dynamics and LLM explanation interfaces. We will add a comparison table contrasting UNIPO's unified token-level views, multi-algorithm support, and interactive design against prior single-algorithm or non-token-level tools, thereby providing the requested grounding for the 'first' claim. revision: yes
-
Referee: [Abstract] Abstract (usage scenarios): the central claims that the tool 'supports both classroom instruction for non-experts and algorithm selection for AI practitioners' rest solely on two narrative usage scenarios with no accompanying user studies, learning metrics, task performance data, or controlled comparisons to baseline resources such as papers or other tools.
Authors: The referee is correct that the claims rest on narrative scenarios without formal user studies or quantitative metrics. For an initial tool-introduction paper, narrative scenarios are a conventional method to illustrate potential use cases. However, to avoid overstatement we will revise the abstract and introduction to present the scenarios explicitly as 'illustrative usage scenarios' rather than as demonstrated support. We will also add a Limitations section that acknowledges the lack of controlled user studies, learning metrics, or comparisons to baselines and outlines plans for such evaluations as future work. revision: partial
Circularity Check
No circularity: tool description paper with no derivations or fitted predictions
full rationale
The paper presents UNIPO, an interactive visualization tool for comparing RL fine-tuning algorithms like GRPO and DAPO. It contains no mathematical derivation chain, equations, predictions, or first-principles results. Claims about supporting instruction and algorithm selection rest on two narrative usage scenarios rather than any self-referential definitions, fitted parameters renamed as outputs, or load-bearing self-citations. The design is self-contained as a software artifact description with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
E. Aflalo, M. Du, S.-Y . Tseng, Y . Liu, C. Wu, N. Duan, et al. VL- InterpreT: An Interactive Visualization Tool for Interpreting Vision- Language Transformers . In2022 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pp. 21374–21383. IEEE Computer Society, Los Alamitos, CA, USA, June 2022. doi: 10.1109/CVPR52688.2022.020722
-
[2]
Y . Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, et al. Training a helpful and harmless assistant with reinforcement learn- ing from human feedback, 2022. URL:https://arxiv.org/abs/ 2204.05862. 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
L. Biewald. Experiment tracking with weights and biases, 2020. URL: https://www.wandb.com/. 1, 2, 4
work page 2020
-
[4]
A. Cho, G. C. Kim, A. Karpekov, S. Lee, A. Helbling, B. Hoover, et al. Transformer explainer: Learning llm transformers with interactive vi- sual explanation and experimentation. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems, CHI ’26. As- sociation for Computing Machinery, New York, NY , USA, 2026. doi: 10.1145/3772318.37917252
-
[5]
P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences. In I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vish- wanathan, et al., eds.,Advances in Neural Information Processing Sys- tems, vol. 30. Curran Associates, Inc., 2017. 1
work page 2017
-
[6]
G. M. Draper, Y . Livnat, and R. F. Riesenfeld. A survey of radial meth- ods for information visualization.IEEE Transactions on Visualization & Computer Graphics, 15(05):759–776, 2009. 3
work page 2009
- [7]
-
[8]
doi:10.1111/cgf.130922
-
[9]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, et al. Deepseek- r1 incentivizes reasoning in llms through reinforcement learning.Na- ture, 645(8081):633–638, 2025. doi:10.1038/s41586-025-09422-z1, 2
- [10]
- [11]
- [12]
-
[13]
Y . Kilcher. [GRPO Explained] DeepSeekMath: Pushing the limits of mathematical reasoning in open language models. YouTube video, Jan. 2025.https://www.youtube.com/watch?v=bAWV_yrqx4w, URL:https://www.youtube.com/watch?v=bAWV_yrqx4w. 1
work page 2025
-
[14]
I. Lakatos, J. Worrall, and E. Zahar, eds.Proofs and Refutations: The Logic of Mathematical Discovery. Cambridge University Press, Cambridge and London, 1976. 2
work page 1976
-
[15]
N. Lambert. Reinforcement learning from human feedback, 2026. URL:https://arxiv.org/abs/2504.12501. 1
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
N. Lambert, L. Castricato, L. von Werra, and A. Havrilla. Illustrating reinforcement learning from human feedback (rlhf).Hugging Face Blog, 2022. https://huggingface.co/blog/rlhf. 1
work page 2022
-
[17]
N. Lambert, J. Morrison, V . Pyatkin, S. Huang, H. Ivison, F. Brahman, et al. Tulu 3: Pushing frontiers in open language model post-training. InSecond Conference on Language Modeling, 2025. 2
work page 2025
- [18]
-
[19]
Z. Liu, C. Chen, W. Li, P. Qi, T. Pang, C. Du, et al. Understanding r1-zero-like training: A critical perspective, 2025. URL:https:// arxiv.org/abs/2503.20783. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [20]
-
[21]
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, et al. Training language models to follow instructions with human feedback. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, eds.,Advances in Neural Information Process- ing Systems, vol. 35, pp. 27730–27744. Curran Associates, Inc., 2022. 1, 2
work page 2022
-
[22]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms, 2017. URL:https:// arxiv.org/abs/1707.06347. 2
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, et al. Deepseek- math: Pushing the limits of mathematical reasoning in open language models, 2024. URL:https://arxiv.org/abs/2402.03300. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
B. Shneiderman. The Eyes Have It: A Task by Data Type Taxonomy for Information Visualizations . InVisual Languages, IEEE Sympo- sium on, p. 336. IEEE Computer Society, Los Alamitos, CA, USA, Sept. 1996. doi:10.1109/VL.1996.5453072
-
[25]
D. Smilkov, S. Carter, D. Sculley, F. B. Vi ´egas, and M. Wattenberg. Direct-manipulation visualization of deep networks, 2017. URL: https://arxiv.org/abs/1708.03788. 2
-
[26]
T. Spinner, U. Schlegel, H. Sch ¨afer, and M. El-Assady. explainer: A visual analytics framework for interactive and explainable machine learning.IEEE Transactions on Visualization and Computer Graph- ics, 26(1):1064–1074, 2020. doi:10.1109/TVCG.2019.29346292
-
[27]
Steinarsson.Downsampling time series for visual representation
S. Steinarsson.Downsampling time series for visual representation. PhD thesis, 2013. 3
work page 2013
-
[28]
R. S. Sutton and A. G. Barto.Reinforcement learning - an introduc- tion, 2nd Edition. MIT Press, 2018. 1
work page 2018
-
[29]
J. Vig. A multiscale visualization of attention in the transformer model. In M. R. Costa-juss `a and E. Alfonseca, eds.,Proceedings of the 57th Annual Meeting of the Association for Computational Lin- guistics: System Demonstrations, pp. 37–42. Association for Compu- tational Linguistics, Florence, Italy, July 2019. doi:10.18653/v1/P19 -30072
- [30]
-
[31]
Z. Wang, K. Ramnath, B. Bi, S. K. Pentyala, S. Chaudhuri, S. Mehro- tra, et al. Reinforcement learning for llm post-training: A survey,
-
[32]
URL:https://arxiv.org/abs/2407.16216. 2
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Z. J. Wang, R. Turko, O. Shaikh, H. Park, N. Das, F. Hohman, et al. Cnn explainer: Learning convolutional neural networks with interac- tive visualization.IEEE Transactions on Visualization and Computer Graphics, 27(2):1396–1406, Feb. 2021. doi:10.1109/tvcg.2020.3030418 2
-
[34]
R. J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning.Mach. Learn., 8(3–4):229–256, May 1992. doi:10.1007/BF009926962
-
[35]
C. Yeh, Y . Chen, A. Wu, C. Chen, F. Vi´egas, and M. Wattenberg. At- tentionviz: A global view of transformer attention.IEEE Transactions on Visualization and Computer Graphics, 30(1):262–272, Jan. 2024. doi:10.1109/TVCG.2023.33271632
-
[36]
Q. Yu, Z. Zhang, R. Zhu, Y . Yuan, X. Zuo, Y . Yue, et al. Dapo: An open-source llm reinforcement learning system at scale, 2025. URL: https://arxiv.org/abs/2503.14476. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
M. A. Zaharia, A. Chen, A. Davidson, A. Ghodsi, S. A. Hong, A. Kon- winski, et al. Accelerating the machine learning lifecycle with mlflow. IEEE Data Eng. Bull., 41:39–45, 2018. 2
work page 2018
-
[38]
Y . Zhang. From GRPO to DAPO and GSPO: What, why, and how. Hugging Face Blog, Aug. 2025.https://huggingface.co/ blog/NormalUhr/grpo-to-dapo-and-gspo, URL:https:// huggingface.co/blog/NormalUhr/grpo-to-dapo-and-gspo. 1, 2
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.