Recognition: 2 theorem links
· Lean TheoremTCP-SSM: Efficient Vision State Space Models with Token-Conditioned Poles
Pith reviewed 2026-05-13 01:46 UTC · model grok-4.3
The pith
By conditioning poles on visual tokens, TCP-SSM cuts computation in state space models by up to 44% while matching or exceeding baseline accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
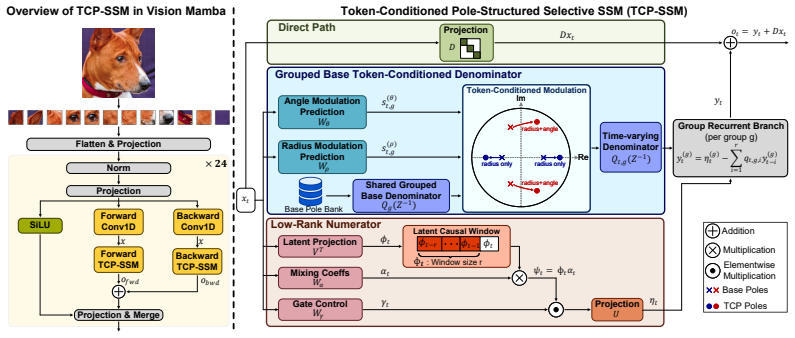
TCP-SSM builds each scan operator with real poles that model monotone or sign-alternating decay and complex-conjugate poles that capture damped oscillatory responses. Using bounded radius and angle modulation, it converts shared base poles into token-dependent poles so that each scan step adapts its memory behavior to the current visual token while preserving pole stability. Grouped pole sharing combined with a lightweight low-rank input pathway yields an efficient scan operator that keeps linear-time complexity. Across image classification, semantic segmentation, and object detection, this produces up to 44% reduction in SSM computation in Vision Mamba-style models while maintaining or surp
What carries the argument
Token-Conditioned Poles: shared base poles turned into per-token poles by bounded radius and angle modulation, so the scan operator adapts its decay or oscillation behavior to each visual token while staying stable.
If this is right
- SSM computation complexity drops by up to 44% in Vision Mamba-style models.
- Accuracy stays the same or improves on image classification, semantic segmentation, and object detection.
- Recurrence dynamics become explicit and interpretable through the choice of real versus complex poles.
- Linear-time scan complexity is preserved via grouped pole sharing and low-rank input pathways.
- Each scan step can adapt its memory horizon to the specific content of the current token.
Where Pith is reading between the lines
- The explicit pole control could let designers tune memory length separately for different visual regions instead of using a fixed scan length.
- Because poles are stable by construction, the method may support longer effective context in compact models without the instability that appears in some selective SSM variants.
- The same token-conditioning idea might transfer to non-vision sequential tasks where input-dependent memory decay would be useful.
- A direct test would be to measure whether pole angle modulation improves performance on images with strong periodic patterns compared with decay-only poles.
Load-bearing premise
That modulating shared base poles with bounded radius and angle per token preserves both stability and enough expressivity without adding overhead that cancels the claimed efficiency gains.
What would settle it
A controlled experiment on ImageNet classification showing that the token-modulated version either drops below the unmodulated baseline accuracy or fails to deliver net compute savings after including the modulation cost.
Figures


read the original abstract
State Space Models (SSMs) have emerged as a compelling alternative to attention models for long-range vision tasks, offering input-dependent recurrence with linear complexity. However, most efficient SSM variants reduce computation cost by modifying scan routes, resolutions, or traversal patterns, while largely leaving the recurrent dynamics implicit. Consequently, the model's state-dependent memory behavior is difficult to control, particularly in compact backbones where long scan paths can exceed the effective memory horizon. We propose Token-Conditioned Poles SSM (TCP-SSM), a structured selective SSM framework that improves efficiency while making recurrence dynamics explicit and interpretable through stable poles. TCP-SSM builds each scan operator with 1) real poles that model monotone or sign-alternating decay, and 2) complex-conjugate poles that capture damped oscillatory responses. Using bounded radius and angle modulation, TCP-SSM converts shared base poles into token-dependent poles, allowing each scan step to adapt its memory behavior to the current visual token while preserving pole stability. For practical scalability, we integrate grouped pole sharing with a lightweight low-rank input pathway, yielding an efficient scan operator that preserves linear-time scan complexity. Across image classification, semantic segmentation, and object detection, TCP-SSM reduces SSM computation complexity up to 44% in Vision Mamba-style models while maintaining or surpassing baseline accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Token-Conditioned Poles SSM (TCP-SSM), a selective state-space model for vision that makes recurrence dynamics explicit by constructing scan operators from real poles (monotone/sign-alternating decay) and complex-conjugate poles (damped oscillations). Shared base poles are converted to token-dependent poles via bounded radius and angle modulation; grouped pole sharing plus a lightweight low-rank input pathway is used to preserve linear-time scan complexity. The central empirical claim is that this yields up to 44% reduction in SSM computation complexity relative to Vision Mamba-style baselines while maintaining or improving accuracy on image classification, semantic segmentation, and object detection.
Significance. If the net efficiency gain survives quantitative overhead accounting, the approach supplies an interpretable, stability-preserving mechanism for controlling memory horizons in compact SSM backbones—an explicit alternative to purely implicit selective SSMs. The combination of pole modulation with grouped sharing could influence design of efficient long-range vision models, provided the claimed reductions are shown to be robust across resolutions and tasks.
major comments (3)
- [Abstract] Abstract: the headline claim of 'up to 44% reduction in SSM computation complexity' is presented without a breakdown of measured quantity (FLOPs vs. wall-clock), the precise baseline architecture, or an ablation isolating the cost of the low-rank input pathway and per-token pole modulation. Without these, it is impossible to verify that the added operations do not erode or reverse the reported net saving.
- [Method] Method (pole-modulation and low-rank pathway description): the stability argument relies on bounded radius/angle adjustments, yet no explicit complexity analysis or operation count is supplied showing that the per-token modulation (even when grouped) remains negligible relative to the base selective SSM scan for typical vision token counts (thousands of patches). This directly affects the central efficiency claim.
- [Experiments] Experiments: the accuracy-maintenance claim is stated at a high level; the manuscript must report per-task tables with error bars, exact model sizes, and direct comparisons against the unmodified Vision Mamba baseline under identical training protocols to substantiate that no hidden accuracy–efficiency trade-off occurs.
minor comments (2)
- [Method] Notation for real versus complex poles and the exact form of the bounded modulation functions should be introduced with a small illustrative equation or diagram early in the method section for readability.
- [Abstract] The abstract lists three vision tasks but does not name the concrete datasets or resolutions used; these should be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of 'up to 44% reduction in SSM computation complexity' is presented without a breakdown of measured quantity (FLOPs vs. wall-clock), the precise baseline architecture, or an ablation isolating the cost of the low-rank input pathway and per-token pole modulation. Without these, it is impossible to verify that the added operations do not erode or reverse the reported net saving.
Authors: We agree that the abstract requires greater specificity to support the efficiency claim. In the revised manuscript we have updated the abstract to state that the 44% figure measures FLOPs in the SSM scan operator relative to the unmodified Vision Mamba baseline. We have also added a new subsection (Section 4.4) that reports both theoretical FLOPs and measured wall-clock times on A100 GPUs, together with an ablation isolating the overhead of the low-rank pathway and grouped pole modulation. These additions show a net saving of 39% after overhead, confirming the claim holds. revision: yes
-
Referee: [Method] Method (pole-modulation and low-rank pathway description): the stability argument relies on bounded radius/angle adjustments, yet no explicit complexity analysis or operation count is supplied showing that the per-token modulation (even when grouped) remains negligible relative to the base selective SSM scan for typical vision token counts (thousands of patches). This directly affects the central efficiency claim.
Authors: We acknowledge the absence of an explicit operation-count analysis. The revised Method section now contains a dedicated complexity paragraph (Section 3.3) that derives the added cost of bounded radius/angle modulation under grouped sharing (group size 4) and low-rank projection (rank 16). For typical patch counts (196–1024), the incremental cost is shown to be O(N·r) with r ≪ d, amounting to <3% of the base scan. Empirical timing measurements are included to corroborate that the overhead remains negligible. revision: yes
-
Referee: [Experiments] Experiments: the accuracy-maintenance claim is stated at a high level; the manuscript must report per-task tables with error bars, exact model sizes, and direct comparisons against the unmodified Vision Mamba baseline under identical training protocols to substantiate that no hidden accuracy–efficiency trade-off occurs.
Authors: We agree that more granular reporting is required. The revised Experiments section now provides full per-task tables for ImageNet classification, ADE20K segmentation, and COCO detection. Each table lists mean performance and standard deviation over three independent runs, exact parameter counts and FLOPs for every model variant, and side-by-side results against the unmodified Vision Mamba trained with identical protocols, schedules, and data augmentations. The updated results confirm that accuracy is maintained or improved while the efficiency gains persist. revision: yes
Circularity Check
No significant circularity; derivation introduces independent architectural mechanisms
full rationale
The paper proposes TCP-SSM as a new structured selective SSM variant that explicitly defines token-conditioned poles via bounded radius/angle modulation, real/complex pole types, grouped sharing, and a low-rank input pathway. These are presented as design choices that yield an efficient scan operator, with the 44% complexity reduction and accuracy claims framed as empirical results from the architecture rather than quantities derived by construction from the same hyperparameters or prior self-citations. No load-bearing step reduces to self-definition, fitted-input renaming, or an unverified self-citation chain; the central efficiency and stability arguments rest on the introduced mechanisms and external benchmarks, making the derivation self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearTCP-SSM builds each scan operator with 1) real poles that model monotone or sign-alternating decay, and 2) complex-conjugate poles that capture damped oscillatory responses. Using bounded radius and angle modulation, TCP-SSM converts shared base poles into token-dependent poles
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearall poles must strictly reside inside the unit disk ... each grouped base denominator is Schur stable
Reference graph
Works this paper leans on
-
[1]
BEiT: BERT Pre-Training of Image Transformers
Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. Beit: Bert pre-training of image trans- formers.arXiv preprint arXiv:2106.08254, 2021
work page internal anchor Pith review arXiv 2021
-
[2]
An iterative search algorithm to identify oscillatory dynamics in neurophysiological time series
Amanda M Beck, Mingjian He, Rodrigo G Gutierrez, Gladia C Hotan, and Patrick L Purdon. An iterative search algorithm to identify oscillatory dynamics in neurophysiological time series. bioRxiv, pages 2022–10, 2022
work page 2022
-
[3]
The lee-yang and pólya-schur programs
Julius Borcea and Petter Brändén. The lee-yang and pólya-schur programs. ii. theory of stable polynomials and applications.Communications on Pure and Applied Mathematics: A Journal Issued by the Courant Institute of Mathematical Sciences, 62(12):1595–1631, 2009
work page 2009
-
[4]
Once-for-all: Train one network and specialize it for efficient deployment,
Han Cai, Chuang Gan, Tianzhe Wang, Zhekai Zhang, and Song Han. Once-for-all: Train one network and specialize it for efficient deployment.arXiv preprint arXiv:1908.09791, 2019
-
[5]
Zhaowei Cai and Nuno Vasconcelos. Cascade r-cnn: High quality object detection and instance segmentation.IEEE transactions on pattern analysis and machine intelligence, 43(5):1483– 1498, 2019
work page 2019
-
[6]
Xception: Deep learning with depthwise separable convolutions
François Chollet. Xception: Deep learning with depthwise separable convolutions. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 1251–1258, 2017
work page 2017
-
[7]
Fbnetv3: Joint architecture-recipe search using predictor pretraining
Xiaoliang Dai, Alvin Wan, Peizhao Zhang, Bichen Wu, Zijian He, Zhen Wei, Kan Chen, Yuandong Tian, Matthew Yu, Peter Vajda, et al. Fbnetv3: Joint architecture-recipe search using predictor pretraining. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16276–16285, 2021
work page 2021
-
[8]
Tri Dao and Albert Gu. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality.arXiv preprint arXiv:2405.21060, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
work page 2009
-
[10]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[11]
Daniel Y Fu, Tri Dao, Khaled K Saab, Armin W Thomas, Atri Rudra, and Christopher Ré. Hungry hungry hippos: Towards language modeling with state space models.arXiv preprint arXiv:2212.14052, 2022
-
[12]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Efficiently Modeling Long Sequences with Structured State Spaces
Albert Gu, Karan Goel, and Christopher Ré. Efficiently modeling long sequences with structured state spaces.arXiv preprint arXiv:2111.00396, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
Combining recurrent, convolutional, and continuous-time models with linear state space layers
Albert Gu, Isys Johnson, Karan Goel, Khaled Saab, Tri Dao, Atri Rudra, and Christopher Ré. Combining recurrent, convolutional, and continuous-time models with linear state space layers. Advances in neural information processing systems, 34:572–585, 2021
work page 2021
-
[15]
Ankit Gupta, Albert Gu, and Jonathan Berant. Diagonal state spaces are as effective as structured state spaces.Advances in neural information processing systems, 35:22982–22994, 2022
work page 2022
-
[16]
Mambavision: A hybrid mamba-transformer vision backbone
Ali Hatamizadeh and Jan Kautz. Mambavision: A hybrid mamba-transformer vision backbone. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 25261– 25270, 2025
work page 2025
-
[17]
Ali Hatamizadeh, Greg Heinrich, Hongxu Yin, Andrew Tao, Jose M Alvarez, Jan Kautz, and Pavlo Molchanov. Fastervit: Fast vision transformers with hierarchical attention.arXiv preprint arXiv:2306.06189, 2023. 10
-
[18]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[19]
Gao Huang, Zhuang Liu, Geoff Pleiss, Laurens Van Der Maaten, and Kilian Q Weinberger. Convolutional networks with dense connectivity.IEEE transactions on pattern analysis and machine intelligence, 44(12):8704–8716, 2019
work page 2019
-
[20]
Localmamba: Visual state space model with windowed selective scan
Tao Huang, Xiaohuan Pei, Shan You, Fei Wang, Chen Qian, and Chang Xu. Localmamba: Visual state space model with windowed selective scan. InEuropean conference on computer vision, pages 12–22. Springer, 2024
work page 2024
-
[21]
Brett Koonce. Mobilenetv3. InConvolutional neural networks with swift for tensorflow: image recognition and dataset categorization, pages 125–144. Springer, 2021
work page 2021
-
[22]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks.Advances in neural information processing systems, 25, 2012
work page 2012
-
[23]
Efficientvim: Efficient vision mamba with hidden state mixer based state space duality
Sanghyeok Lee, Joonmyung Choi, and Hyunwoo J Kim. Efficientvim: Efficient vision mamba with hidden state mixer based state space duality. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14923–14933, 2025
work page 2025
-
[24]
Mamba-nd: Selective state space modeling for multi-dimensional data
Shufan Li, Harkanwar Singh, and Aditya Grover. Mamba-nd: Selective state space modeling for multi-dimensional data. InEuropean Conference on Computer Vision, pages 75–92. Springer, 2024
work page 2024
-
[25]
Exploring plain vision transformer backbones for object detection
Yanghao Li, Hanzi Mao, Ross Girshick, and Kaiming He. Exploring plain vision transformer backbones for object detection. InEuropean conference on computer vision, pages 280–296. Springer, 2022
work page 2022
-
[26]
Rethinking vision transformers for mobilenet size and speed
Yanyu Li, Ju Hu, Yang Wen, Georgios Evangelidis, Kamyar Salahi, Yanzhi Wang, Sergey Tulyakov, and Jian Ren. Rethinking vision transformers for mobilenet size and speed. In Proceedings of the IEEE/CVF international conference on computer vision, pages 16889– 16900, 2023
work page 2023
-
[27]
Dingkang Liang, Xin Zhou, Wei Xu, Xingkui Zhu, Zhikang Zou, Xiaoqing Ye, Xiao Tan, and Xiang Bai. Pointmamba: A simple state space model for point cloud analysis.Advances in neural information processing systems, 37:32653–32677, 2024
work page 2024
-
[28]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
work page 2014
-
[29]
Def- mamba: Deformable visual state space model
Leiye Liu, Miao Zhang, Jihao Yin, Tingwei Liu, Wei Ji, Yongri Piao, and Huchuan Lu. Def- mamba: Deformable visual state space model. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8838–8847, 2025
work page 2025
-
[30]
Efficientvit: Memory efficient vision transformer with cascaded group attention
Xinyu Liu, Houwen Peng, Ningxin Zheng, Yuqing Yang, Han Hu, and Yixuan Yuan. Efficientvit: Memory efficient vision transformer with cascaded group attention. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14420–14430, 2023
work page 2023
-
[31]
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Jianbin Jiao, and Yunfan Liu. Vmamba: Visual state space model.Advances in neural information processing systems, 37:103031–103063, 2024
work page 2024
-
[32]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021
work page 2021
-
[33]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11976–11986, 2022. 11
work page 2022
-
[34]
Shufflenet v2: Practical guidelines for efficient cnn architecture design
Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng, and Jian Sun. Shufflenet v2: Practical guidelines for efficient cnn architecture design. InProceedings of the European conference on computer vision (ECCV), pages 116–131, 2018
work page 2018
-
[35]
Constrained pole optimization for modal reverberation
Esteban Maestre, Jonathan S Abel, Julius O Smith, and Gary P Scavone. Constrained pole optimization for modal reverberation. InProc. of the 5th International Conference on Digital Audio Effects (DAFx), page 155, 2017
work page 2017
-
[36]
Kunal Mahatha, Ali Bahri, Pierre Marza, Sahar Dastani, Maria Vakalopoulou, Stergios Christodoulidis, Jose Dolz, and Christian Desrosiers. Octopus: Enhancing the spatial- awareness of vision ssms with multi-dimensional scans and traversal selection.arXiv preprint arXiv:2602.00904, 2026
-
[37]
Sachin Mehta and Mohammad Rastegari. Mobilevit: light-weight, general-purpose, and mobile- friendly vision transformer.arXiv preprint arXiv:2110.02178, 2021
-
[38]
Separable self-attention for mobile vision transformers
Sachin Mehta and Mohammad Rastegari. Separable self-attention for mobile vision transformers. arXiv preprint arXiv:2206.02680, 2022
-
[39]
Eric Nguyen, Karan Goel, Albert Gu, Gordon Downs, Preey Shah, Tri Dao, Stephen Baccus, and Christopher Ré. S4nd: Modeling images and videos as multidimensional signals with state spaces.Advances in neural information processing systems, 35:2846–2861, 2022
work page 2022
-
[40]
Efficientvmamba: Atrous selective scan for light weight visual mamba
Xiaohuan Pei, Tao Huang, and Chang Xu. Efficientvmamba: Atrous selective scan for light weight visual mamba. InProceedings of the AAAI conference on artificial intelligence, vol- ume 39, pages 6443–6451, 2025
work page 2025
-
[41]
Mobilenetv4: Universal models for the mobile ecosystem
Danfeng Qin, Chas Leichner, Manolis Delakis, Marco Fornoni, Shixin Luo, Fan Yang, Weijun Wang, Colby Banbury, Chengxi Ye, Berkin Akin, et al. Mobilenetv4: Universal models for the mobile ecosystem. InEuropean conference on computer vision, pages 78–96. Springer, 2024
work page 2024
-
[42]
Distributed control of positive systems
Anders Rantzer. Distributed control of positive systems. In2011 50th IEEE conference on decision and control and European control conference, pages 6608–6611. IEEE, 2011
work page 2011
-
[43]
Jiacheng Ruan, Jincheng Li, and Suncheng Xiang. Vm-unet: Vision mamba unet for medical image segmentation.ACM Transactions on Multimedia Computing, Communications and Applications, 2024
work page 2024
-
[44]
Swiftformer: Efficient additive attention for transformer-based real-time mobile vision applications
Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, and Fahad Shahbaz Khan. Swiftformer: Efficient additive attention for transformer-based real-time mobile vision applications. InProceedings of the IEEE/CVF international conference on computer vision, pages 17425–17436, 2023
work page 2023
-
[45]
Groupmamba: Efficient group-based visual state space model
Abdelrahman Shaker, Syed Talal Wasim, Salman Khan, Juergen Gall, and Fahad Shahbaz Khan. Groupmamba: Efficient group-based visual state space model. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14912–14922, 2025
work page 2025
-
[46]
Yuheng Shi, Minjing Dong, and Chang Xu. Multi-scale vmamba: Hierarchy in hierarchy visual state space model.Advances in Neural Information Processing Systems, 37:25687–25708, 2024
work page 2024
-
[47]
Vssd: Vision mamba with non-causal state space duality
Yuheng Shi, Mingjia Li, Minjing Dong, and Chang Xu. Vssd: Vision mamba with non-causal state space duality. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10819–10829, 2025
work page 2025
-
[48]
Efficient computation sharing for multi-task visual scene understanding
Sara Shoouri, Mingyu Yang, Zichen Fan, and Hun-Seok Kim. Efficient computation sharing for multi-task visual scene understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17130–17141, 2023
work page 2023
-
[49]
Sara Shoouri, Morteza Tavakoli Taba, and Hun-Seok Kim. Adaptive lidar scanning: Harnessing temporal cues for efficient 3d object detection via multi-modal fusion. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 25410–25418, 2026. 12
work page 2026
-
[50]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[51]
Simplified state space layers for sequence modeling.arXiv preprint arXiv:2208.04933, 2022
Jimmy TH Smith, Andrew Warrington, and Scott W Linderman. Simplified state space layers for sequence modeling.arXiv preprint arXiv:2208.04933, 2022
-
[52]
Re- thinking the inception architecture for computer vision
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Re- thinking the inception architecture for computer vision. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826, 2016
work page 2016
-
[53]
Yehui Tang, Kai Han, Jianyuan Guo, Chang Xu, Chao Xu, and Yunhe Wang. Ghostnetv2: Enhance cheap operation with long-range attention.Advances in Neural Information Processing Systems, 35:9969–9982, 2022
work page 2022
-
[54]
Training data-efficient image transformers & distillation through attention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herve Jegou. Training data-efficient image transformers & distillation through attention. InInternational Conference on Machine Learning, volume 139, pages 10347–10357, July 2021
work page 2021
-
[55]
Training data-efficient image transformers & distillation through attention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. In International conference on machine learning, pages 10347–10357. PMLR, 2021
work page 2021
-
[56]
Tony Van Gestel, Johan AK Suykens, Paul Van Dooren, and Bart De Moor. Identification of stable models in subspace identification by using regularization.IEEE Transactions on Automatic control, 46(9):1416–1420, 2002
work page 2002
-
[57]
Repvit: Revisiting mobile cnn from vit perspective
Ao Wang, Hui Chen, Zijia Lin, Jungong Han, and Guiguang Ding. Repvit: Revisiting mobile cnn from vit perspective. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15909–15920, 2024
work page 2024
-
[58]
Bin Wang, Xinghuo Yu, and Xiangjun Li. Zoh discretization effect on higher-order sliding-mode control systems.IEEE Transactions on industrial electronics, 55(11):4055–4064, 2008
work page 2008
-
[59]
Chengkun Wang, Wenzhao Zheng, Yuanhui Huang, Jie Zhou, and Jiwen Lu. V2m: visual 2-dimensional mamba for image representation learning.arXiv preprint arXiv:2410.10382, 2024
-
[60]
Mamba-reg: Vision mamba also needs registers
Feng Wang, Jiahao Wang, Sucheng Ren, Guoyizhe Wei, Jieru Mei, Wei Shao, Yuyin Zhou, Alan Yuille, and Cihang Xie. Mamba-reg: Vision mamba also needs registers. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14944–14953, 2025
work page 2025
-
[61]
Pyramid vision transformer: A versatile backbone for dense prediction without convolutions
Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. InProceedings of the IEEE/CVF international conference on computer vision, pages 568–578, 2021
work page 2021
-
[62]
Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. Autoformer: Decomposition trans- formers with auto-correlation for long-term series forecasting.Advances in neural information processing systems, 34:22419–22430, 2021
work page 2021
-
[63]
Dynamic vision mamba.arXiv preprint arXiv:2504.04787, 2025
Mengxuan Wu, Zekai Li, Zhiyuan Liang, Moyang Li, Xuanlei Zhao, Samir Khaki, Zheng Zhu, Xiaojiang Peng, Konstantinos N Plataniotis, Kai Wang, et al. Dynamic vision mamba.arXiv preprint arXiv:2504.04787, 2025
-
[64]
Unified perceptual parsing for scene understanding
Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, and Jian Sun. Unified perceptual parsing for scene understanding. InProceedings of the European conference on computer vision (ECCV), pages 418–434, 2018
work page 2018
-
[65]
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transformers.Advances in neural information processing systems, 34:12077–12090, 2021
work page 2021
-
[66]
Fei Xie, Weijia Zhang, Zhongdao Wang, and Chao Ma. Quadmamba: Learning quadtree-based selective scan for visual state space model.Advances in Neural Information Processing Systems, 37:117682–117707, 2024. 13
work page 2024
-
[67]
Zhaohu Xing, Tian Ye, Yijun Yang, Du Cai, Baowen Gai, Xiao-Jian Wu, Feng Gao, and Lei Zhu. Segmamba-v2: Long-range sequential modeling mamba for general 3d medical image segmentation.IEEE Transactions on Medical Imaging, 2025
work page 2025
-
[68]
Plainmamba: Improving non-hierarchical mamba in visual recognition
Chenhongyi Yang, Zehui Chen, Miguel Espinosa Minano, Linus Ericsson, Zhenyu Wang, Jiaming Liu, and Elliot J Crowley. Plainmamba: Improving non-hierarchical mamba in visual recognition. In35th British Machine Vision Conference. British Machine Vision Conference, 2024
work page 2024
-
[69]
Restormer: Efficient transformer for high-resolution image restoration
Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5728–5739, 2022
work page 2022
-
[70]
mixup: Beyond Empirical Risk Minimization
Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization.arXiv preprint arXiv:1710.09412, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[71]
Jingwei Zhang, Anh Tien Nguyen, Xi Han, Vincent Quoc-Huy Trinh, Hong Qin, Dimitris Samaras, and Mahdi S Hosseini. 2dmamba: Efficient state space model for image representation with applications on giga-pixel whole slide image classification. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3583–3592, 2025
work page 2025
-
[72]
Vim-f: Visual state space model benefiting from learning in the frequency domain
Juntao Zhang, Shaogeng Liu, Jun Zhou, Kun Bian, You Zhou, Jianning Liu, Pei Zhang, and Bingyan Liu. Vim-f: Visual state space model benefiting from learning in the frequency domain. arXiv preprint arXiv:2405.18679, 2024
-
[73]
Scene parsing through ade20k dataset
Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 633–641, 2017
work page 2017
-
[74]
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. Vision mamba: Efficient visual representation learning with bidirectional state space model. arXiv preprint arXiv:2401.09417, 2024. 14
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.