Recognition: no theorem link
RIO: Flexible Real-Time Robot I/O for Cross-Embodiment Robot Learning
Pith reviewed 2026-05-13 01:38 UTC · model grok-4.3
The pith
RIO is a Python framework that supplies lightweight abstractions for robot control, teleoperation, and data handling so users can switch between different robot bodies and hardware setups with minimal code changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RIO supplies a set of flexible, lightweight Python abstractions for robot I/O that let users select and interchange choices for hardware, morphology, sensors, and control without large reconfiguration, demonstrated by collecting teleoperated data and fine-tuning VLAs on household tasks across three morphologies and four platforms.
What carries the argument
RIO's collection of lightweight Python abstractions for real-time robot I/O, covering control loops, teleoperation interfaces, data formatting, sensor configuration, and policy deployment.
If this is right
- Teleoperated data collected once with RIO can be reused to fine-tune models such as π0.5 and GR00T on tasks including pick-and-place, folding, and bowl scrubbing.
- Switching between single-arm, bimanual, and humanoid setups or between different grippers and cameras requires only small adjustments rather than full rewrites.
- Policy deployment workflows remain compatible with the same code base when moving from data collection to inference on varied robot hardware.
- Open release of the framework and collected datasets lowers the barrier for other groups to run cross-embodiment experiments.
Where Pith is reading between the lines
- If the abstractions prove durable, the main bottleneck in multi-embodiment robot learning could shift from infrastructure to model architecture and data scale.
- Standardized I/O layers like this might make it practical to maintain one dataset that supports training policies for many different physical robots at once.
- Future extensions could test whether the same components support simulation-to-real transfer or multi-robot coordination without new abstractions.
Load-bearing premise
The Python abstractions stay lightweight enough to preserve real-time performance and full compatibility across the tested range of platforms and morphologies without requiring hidden platform-specific workarounds or large extra engineering effort.
What would settle it
Trying to port an existing RIO-based VLA deployment to a fifth hardware platform or new morphology and measuring whether the required code changes stay minimal and real-time constraints are still met.
Figures










read the original abstract
Despite recent efforts to collect multi-task, multi-embodiment datasets, to design recipes for training Vision-Language-Action models (VLAs), and to showcase these models on different robot platforms, generalist cross-embodiment robot capabilities remains a largely elusive ideal. Progress is limited by fragmented infrastructure: most robot code is highly specific to the exact setup the user decided on, which adds major overhead when attempting to reuse, recycle, or share artifacts between users. We present RIO (Robot I/O), an open source Python framework that provides flexible, lightweight components for robot control, teleoperation, data formatting, sensor configuration, and policy deployment across diverse hardware platforms and morphologies. RIO provides abstractions that enable users to make any choice and to switch between them, with minimal reconfiguration effort. We validate RIO on VLA deployment workflows across three morphologies (single-arm, bimanual, humanoid) and four hardware platforms with varying grippers and cameras. Using teleoperated data collected with RIO, we fine-tune state-of-the-art VLAs including $\pi_{0.5}$ and GR00T on household tasks such as pick-and-place, folding, and bowl scrubbing. By open sourcing all our efforts, we hope the community can accelerate their pace of robot learning on real-world robot hardware. Additional details at: https://robot-i-o.github.io
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RIO, an open-source Python framework offering lightweight abstractions for robot control, teleoperation, data formatting, sensor configuration, and policy deployment. It claims these abstractions allow arbitrary choices in setup with minimal reconfiguration effort when switching across hardware platforms and robot morphologies. Validation consists of using RIO to collect teleoperated data and fine-tune VLAs (π_{0.5} and GR00T) on household tasks such as pick-and-place, folding, and bowl scrubbing, demonstrated across three morphologies (single-arm, bimanual, humanoid) and four hardware platforms with varying grippers and cameras.
Significance. If the flexibility and real-time performance claims hold, RIO could meaningfully reduce infrastructure fragmentation in robot learning, enabling faster reuse of datasets, policies, and code across embodiments. The open-source release together with concrete demonstrations of VLA fine-tuning on real hardware for multiple morphologies is a practical strength that could accelerate community progress in cross-embodiment generalist policies.
major comments (2)
- [Validation / Experiments] Validation section: the description of experiments across morphologies and platforms supplies no quantitative metrics (latency, throughput, success rates, or timing for real-time control), no baseline comparisons to existing I/O frameworks, and no error or limitation analysis. This leaves the central claim that the lightweight Python abstractions deliver flexibility with minimal effort and maintained real-time performance only moderately supported.
- [Abstract and §3] Abstract and §3 (framework description): the claim that users can 'make any choice and switch between them with minimal reconfiguration effort' is not accompanied by concrete examples of code changes required when altering grippers, cameras, or control modes, nor by discussion of any hidden platform-specific costs. This detail is load-bearing for assessing whether the abstractions truly achieve the advertised cross-embodiment generality.
minor comments (1)
- [Abstract] The project URL is referenced but the manuscript would benefit from including a short table or figure summarizing the four platforms, grippers, cameras, and tasks to make the validation scope immediately clear without external lookup.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We have carefully considered the major comments and provide point-by-point responses below, along with plans for revisions to address the concerns raised.
read point-by-point responses
-
Referee: [Validation / Experiments] Validation section: the description of experiments across morphologies and platforms supplies no quantitative metrics (latency, throughput, success rates, or timing for real-time control), no baseline comparisons to existing I/O frameworks, and no error or limitation analysis. This leaves the central claim that the lightweight Python abstractions deliver flexibility with minimal effort and maintained real-time performance only moderately supported.
Authors: We agree that the validation section would benefit from more quantitative support. The current experiments demonstrate successful teleoperated data collection and VLA fine-tuning/deployment across morphologies and platforms, but do not report explicit latency, throughput, or success-rate numbers. In the revised manuscript we will add measured control timings and throughput values from our setups, a brief comparison to related I/O approaches, and a dedicated limitations subsection. This will provide stronger evidence for the real-time and flexibility claims. revision: yes
-
Referee: [Abstract and §3] Abstract and §3 (framework description): the claim that users can 'make any choice and switch between them with minimal reconfiguration effort' is not accompanied by concrete examples of code changes required when altering grippers, cameras, or control modes, nor by discussion of any hidden platform-specific costs. This detail is load-bearing for assessing whether the abstractions truly achieve the advertised cross-embodiment generality.
Authors: We recognize that concrete examples are needed to substantiate the generality claim. Section 3 currently describes the abstractions at a conceptual level. In the revision we will insert specific code snippets showing configuration for different grippers, cameras, and control modes, highlighting the minimal (or zero) code changes required. We will also add a short discussion of platform-specific considerations such as driver requirements to give a balanced view of reconfiguration effort. revision: yes
Circularity Check
No significant circularity; software framework validated externally
full rationale
The paper describes an open-source Python framework (RIO) for robot control, teleoperation, and VLA deployment. It contains no mathematical derivations, equations, fitted parameters, or predictive claims that could reduce to self-definition or fitted inputs. All validation rests on external hardware experiments across three morphologies and four platforms, with no self-citation chains or ansatzes invoked as load-bearing premises. The central claim of flexible abstractions enabling minimal-reconfiguration switching is demonstrated through practical implementation and task execution rather than internal logical reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Python-based abstractions can deliver real-time robot I/O performance across diverse hardware platforms without unacceptable latency or compatibility issues
Reference graph
Works this paper leans on
-
[1]
Amazon FAR, Pieter Abbeel, Juyue Chen, Rocky Duan, Alejandro Escontrela, Manan Gandhi, Samuel Gundry, Xiaoyu Huang, Angjoo Kanazawa, Tomasz Lewicki, Jiaman Li, Karen Liu, Clay Rosenthal, Younggyo Seo, Carlo Sferrazza, Guanya Shi, Linda Shih, Jonathan Tseng, Zhen Wu, Lujie Yang, Brent Yi, and Yuanhang Zhang. Holosoma. URL https://github.com/amazon-far/ holosoma
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wen- bin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, Andr ´e Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Casta ˜neda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Kevin Black, Noah Brown, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π 0: A Vision-Language-Action Flow Model for General Robot Control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Kevin Black, Manuel Y Galliker, and Sergey Levine. Real-Time Execution of Action Chunking Flow Policies. arXiv preprint arXiv:2506.07339, 2025
-
[7]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yev- gen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Open robot control software: the OROCOS project
Herman Bruyninckx. Open robot control software: the OROCOS project. InProceedings 2001 ICRA. IEEE in- ternational conference on robotics and automation (Cat. No. 01CH37164), volume 3, pages 2523–2528. IEEE, 2001
work page 2001
-
[9]
Lerobot: State-of-the-art machine learning for real- world robotics in pytorch, 2024
Remi Cadene, Simon Alibert, Alexander Soare, Quentin Gallouedec, Adil Zouitine, Steven Palma, Pepijn Kooijmans, Michel Aractingi, Mustafa Shukor, Dana Aubakirova, Martino Russi, Francesco Capuano, Car- oline Pascal, Jade Choghari, Jess Moss, and Thomas Wolf. Lerobot: State-of-the-art machine learning for real- world robotics in pytorch, 2024. URL https://...
work page 2024
-
[10]
Robo-DM: Data Management For Large Robot Datasets.arXiv preprint arXiv:2505.15558, 2025
Kaiyuan Chen, Letian Fu, David Huang, Yanxiang Zhang, Lawrence Yunliang Chen, Huang Huang, Kush Hari, Ashwin Balakrishna, Ted Xiao, Pannag R Sanketi, et al. Robo-DM: Data Management For Large Robot Datasets.arXiv preprint arXiv:2505.15558, 2025
-
[11]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yi- heng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain random- ization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Universal Manipulation Interface: In-The- Wild Robot Teaching Without In-The-Wild Robots
Cheng Chi, Zhenjia Xu, Chuer Pan, Eric Cousineau, Benjamin Burchfiel, Siyuan Feng, Russ Tedrake, and Shuran Song. Universal Manipulation Interface: In-The- Wild Robot Teaching Without In-The-Wild Robots. In Robotics: Science and Systems, 2024
work page 2024
-
[13]
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
work page 2025
-
[14]
RoboNet: Large-Scale Multi-Robot Learning
Sudeep Dasari, Frederik Ebert, Stephen Tian, Suraj Nair, Bernadette Bucher, Karl Schmeckpeper, Siddharth Singh, Sergey Levine, and Chelsea Finn. RoboNet: Large-Scale Multi-Robot Learning. InConference on Robot Learning, pages 885–897. PMLR, 2020
work page 2020
-
[15]
Molmo and pixmo: Open weights and open data for state- of-the-art vision-language models
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tri- pathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, et al. Molmo and pixmo: Open weights and open data for state- of-the-art vision-language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 91–104, 2025
work page 2025
-
[16]
Ark: An Open-source Python-based Framework for Robot Learning.arXiv preprint arXiv:2506.21628, 2025
Magnus Dierking, Christopher E Mower, Sarthak Das, Huang Helong, Jiacheng Qiu, Cody Reading, Wei Chen, Huidong Liang, Huang Guowei, Jan Peters, et al. Ark: An Open-source Python-based Framework for Robot Learning.arXiv preprint arXiv:2506.21628, 2025
-
[17]
Scaling Cross-Embodied Learning: One Policy for Manipulation, Navigation, Lo- comotion and Aviation
Ria Doshi, Homer Rich Walke, Oier Mees, Sudeep Dasari, and Sergey Levine. Scaling Cross-Embodied Learning: One Policy for Manipulation, Navigation, Lo- comotion and Aviation. InConference on Robot Learn- ing, pages 496–512. PMLR, 2025
work page 2025
-
[18]
PaLM-E: an embodied multimodal language model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. PaLM-E: an embodied multimodal language model. In Proceedings of the 40th International Conference on Machine Learning, pages 8469–8488, 2023
work page 2023
-
[19]
Octo: An Open- Source Generalist Robot Policy
Dibya Ghosh, Homer Rich Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, et al. Octo: An Open- Source Generalist Robot Policy. InRobotics: Science and Systems, 2024
work page 2024
-
[20]
Markus Grotz, Mohit Shridhar, Tamim Asfour, and Di- eter Fox. PerAct2: Benchmarking and Learning for Robotic Bimanual Manipulation Tasks.arXiv preprint arXiv:2407.00278, 2024
-
[21]
Learning human- to-humanoid real-time whole-body teleoperation
Tairan He, Zhengyi Luo, Wenli Xiao, Chong Zhang, Kris Kitani, Changliu Liu, and Guanya Shi. Learning human- to-humanoid real-time whole-body teleoperation. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 8944–8951. IEEE, 2024
work page 2024
-
[22]
OmniH2O: Universal and Dexter- ous Human-to-Humanoid Whole-Body Teleoperation and Learning
Tairan He, Zhengyi Luo, Xialin He, Wenli Xiao, Chong Zhang, Weinan Zhang, Kris M Kitani, Changliu Liu, and Guanya Shi. OmniH2O: Universal and Dexter- ous Human-to-Humanoid Whole-Body Teleoperation and Learning. InConference on Robot Learning, pages 1516–
-
[23]
ReMix: Optimizing Data Mixtures for Large Scale Imitation Learning
Joey Hejna, Chethan Anand Bhateja, Yichen Jiang, Karl Pertsch, and Dorsa Sadigh. ReMix: Optimizing Data Mixtures for Large Scale Imitation Learning. InConfer- ence on Robot Learning, pages 145–164. PMLR, 2025
work page 2025
-
[24]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5:a Vision-Language-Action Model with Open-World Generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Tobias J ¨ulg, Pierre Krack, Seongjin Bien, Yannik Blei, Khaled Gamal, Ken Nakahara, Johannes Hechtl, Roberto Calandra, Wolfram Burgard, and Florian Walter. Robot Control Stack: A Lean Ecosystem for Robot Learning at Scale.arXiv preprint arXiv:2509.14932, 2025
-
[26]
arXiv preprint arXiv:2512.22414 (2025)
Simar Kareer, Karl Pertsch, James Darpinian, Judy Hoff- man, Danfei Xu, Sergey Levine, Chelsea Finn, and Suraj Nair. Emergence of Human to Robot Trans- fer in Vision-Language-Action Models.arXiv preprint arXiv:2512.22414, 2025
-
[27]
DROID: A large-scale in-the-wild robot manipulation dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ash- win Balakrishna, Sudeep Dasari, Siddharth Karam- cheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. DROID: A large-scale in-the-wild robot manipulation dataset. In Robotics: Science and Systems, 2024
work page 2024
-
[28]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, et al. OpenVLA: An Open-Source Vision-Language-Action Model. InConference on Robot Learning, pages 2679–
-
[29]
Vikash Kumar, Rutav Shah, Gaoyue Zhou, Vincent Moens, Vittorio Caggiano, Abhishek Gupta, and Aravind Rajeswaran. Robohive: A unified framework for robot learning.Advances in Neural Information Processing Systems, 36:44323–44340, 2023
work page 2023
-
[30]
Obin Kwon, Sankalp Yamsani, Noboru Myers, Sean Taylor, Jooyoung Hong, Kyungseo Park, Alex Alspach, and Joohyung Kim. PAPRLE (Plug-And-Play Robotic Limb Environment): A Modular Ecosystem for Robotic Limbs.arXiv preprint arXiv:2507.05555, 2025
-
[31]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[32]
arXiv preprint arXiv:2510.26742 (2025)
Yunchao Ma, Yizhuang Zhou, Yunhuan Yang, Tiancai Wang, and Haoqiang Fan. Running vlas at real-time speed.arXiv preprint arXiv:2510.26742, 2025
-
[33]
Steven Macenski, Tully Foote, Brian Gerkey, Chris Lalancette, and William Woodall. Robot operating sys- tem 2: Design, architecture, and uses in the wild.Science robotics, 7(66):eabm6074, 2022
work page 2022
-
[34]
Y ARP: yet another robot platform.International Journal of Advanced Robotic Systems, 3(1):8, 2006
Giorgio Metta, Paul Fitzpatrick, and Lorenzo Natale. Y ARP: yet another robot platform.International Journal of Advanced Robotic Systems, 3(1):8, 2006
work page 2006
-
[35]
Adithyavairavan Murali, Tao Chen, Kalyan Vasudev Al- wala, Dhiraj Gandhi, Lerrel Pinto, Saurabh Gupta, and Abhinav Gupta. Pyrobot: An open-source robotics frame- work for research and benchmarking.arXiv preprint arXiv:1906.08236, 2019
-
[36]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Ab- hishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
work page 2024
-
[37]
Using apple vision pro to train and control robots, 2024
Younghyo Park and Pulkit Agrawal. Using apple vision pro to train and control robots, 2024. URL https://github. com/Improbable-AI/VisionProTeleop
work page 2024
-
[38]
Sabela Ramos, Sertan Girgin, L ´eonard Hussenot, Damien Vincent, Hanna Yakubovich, Daniel Toyama, Anita Gergely, Piotr Stanczyk, Raphael Marinier, Jeremiah Harmsen, et al. Rlds: an ecosystem to generate, share and use datasets in reinforcement learning.arXiv preprint arXiv:2111.02767, 2021
-
[39]
StarVLA: A Lego-like Codebase for Vision-Language-Action Model Developing, January
starVLA Community. StarVLA: A Lego-like Codebase for Vision-Language-Action Model Developing, January
-
[40]
URL https://github.com/starVLA/starVLA
-
[41]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gonzalez Arenas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Rdt2: Enabling zero-shot cross-embodiment generalization by scaling up umi data, September 2025
RDT Team. Rdt2: Enabling zero-shot cross-embodiment generalization by scaling up umi data, September 2025. URL https://github.com/thu-ml/RDT2
work page 2025
-
[43]
Bridgedata v2: A dataset for robot learning at scale
Homer Rich Walke, Kevin Black, Tony Z Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen-Estruch, An- dre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning, pages 1723–
-
[44]
Evaluating pi0 in the wild: Strengths, problems, and the future of generalist robot policies, 2025
J Wang, M Leonard, K Daniilidis, D Jayaraman, and ES Hu. Evaluating pi0 in the wild: Strengths, problems, and the future of generalist robot policies, 2025. URL https://penn-pal-lab.github.io/ Pi0-Experiment-in-the-Wild/
work page 2025
-
[45]
Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation
Junjie Wen, Yichen Zhu, Jinming Li, Minjie Zhu, Zhibin Tang, Kun Wu, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, et al. Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation. IEEE Robotics and Automation Letters, 2025
work page 2025
-
[46]
arXiv preprint arXiv:2412.13877 (2024) 14
Kun Wu, Chengkai Hou, Jiaming Liu, Zhengping Che, Xiaozhu Ju, Zhuqin Yang, Meng Li, Yinuo Zhao, Zhiyuan Xu, Guang Yang, et al. Robomind: Benchmark on multi-embodiment intelligence normative data for robot manipulation.arXiv preprint arXiv:2412.13877, 2024
-
[47]
Gello: A general, low-cost, and intuitive teleoperation framework for robot manipulators
Philipp Wu, Yide Shentu, Zhongke Yi, Xingyu Lin, and Pieter Abbeel. Gello: A general, low-cost, and intuitive teleoperation framework for robot manipulators. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 12156–12163. IEEE, 2024
work page 2024
-
[48]
arXiv preprint arXiv:2601.18692 (2026)
Wei Wu, Fan Lu, Yunnan Wang, Shuai Yang, Shi Liu, Fangjing Wang, Qian Zhu, He Sun, Yong Wang, Shuailei Ma, et al. A Pragmatic VLA Foundation Model.arXiv preprint arXiv:2601.18692, 2026
-
[49]
Dexbotic: Open-source vision-language-action toolbox,
Bin Xie, Erjin Zhou, Fan Jia, Hao Shi, Haoqiang Fan, Haowei Zhang, Hebei Li, Jianjian Sun, Jie Bin, Jun- wen Huang, Kai Liu, Kaixin Liu, Kefan Gu, Lin Sun, Meng Zhang, Peilong Han, Ruitao Hao, Ruitao Zhang, Saike Huang, Songhan Xie, Tiancai Wang, Tianle Liu, Wenbin Tang, Wenqi Zhu, Yang Chen, Yingfei Liu, Yizhuang Zhou, Yu Liu, Yucheng Zhao, Yunchao Ma, Y...
-
[50]
Dexumi: Using human hand as the universal manipulation interface for dexterous manipulation, 2025
Mengda Xu, Han Zhang, Yifan Hou, Zhenjia Xu, Linxi Fan, Manuela Veloso, and Shuran Song. DexUMI: Using Human Hand as the Universal Manipulation In- terface for Dexterous Manipulation.arXiv preprint arXiv:2505.21864, 2025
-
[51]
Sigmoid loss for language image pre- training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre- training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
work page 2023
-
[52]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware. InRobotics: Science and Systems XIX, 2023
work page 2023
-
[53]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, et al. X-vla: Soft-prompted trans- former as scalable cross-embodiment vision-language- action model.arXiv preprint arXiv:2510.10274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
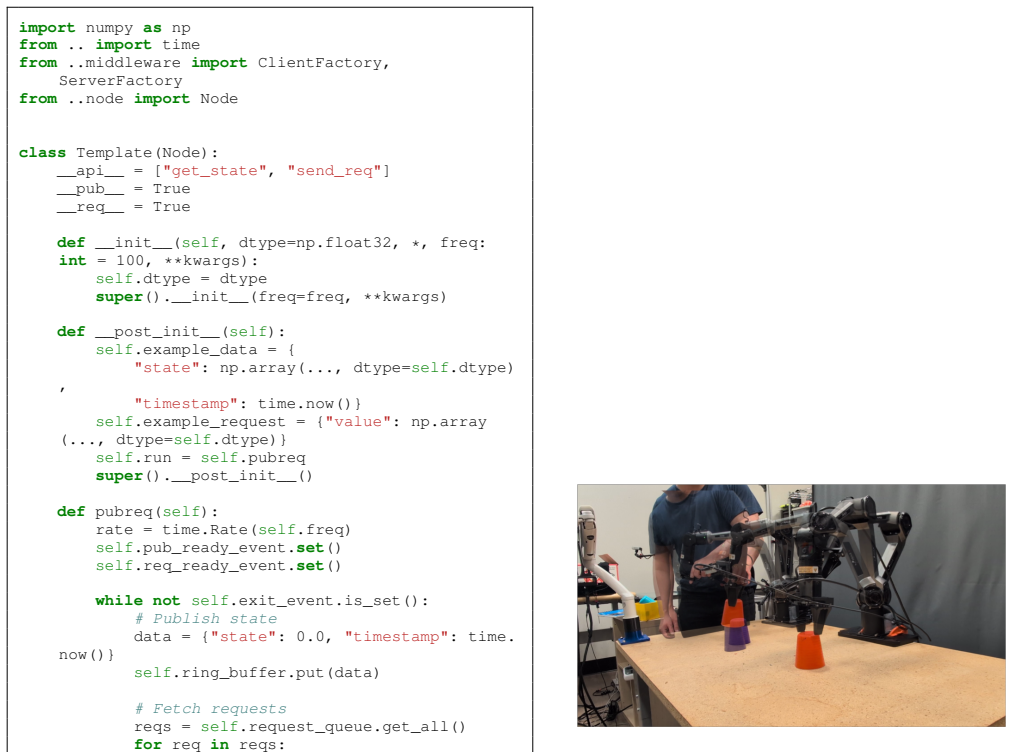
Zhengbang Zhu, Minghuan Liu, Xiaoshen Han, and Zhengshen Zhang. Maniunicon: A unified control in- terface for robotic manipulation, 2025. URL https: //github.com/Universal-Control/ManiUniCon. APPENDIX A. Code specifics Template Node.Our Node implementation is inspired by Diffusion Policy [13] and UMI [12], with a main loop that publishes state through ari...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.