Recognition: no theorem link
The Midas Touch for Metric Depth
Pith reviewed 2026-05-13 01:33 UTC · model grok-4.3
The pith
MTD turns relative depth estimates into accurate metric depth using only a few 3D points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MTD is a mathematically interpretable approach that converts relative depth into metric depth using only extremely sparse 3D data. To eliminate local scale inconsistencies, it applies a segment-wise recovery strategy via sparse graph optimization, followed by a pixel-wise refinement strategy using a discontinuity-aware geodesic cost. MTD exhibits strong generalization and achieves substantial accuracy improvements over previous depth completion and depth estimation methods. Moreover, its lightweight, plug-and-play design facilitates deployment and integration on diverse downstream 3D tasks.
What carries the argument
Segment-wise scale recovery via sparse graph optimization followed by pixel-wise refinement with a discontinuity-aware geodesic cost.
If this is right
- Metric depth becomes available from relative estimators with minimal additional input.
- Local scale inconsistencies are removed, leading to more consistent 3D models.
- Accuracy surpasses previous depth completion and estimation techniques.
- The lightweight design allows easy integration into other 3D vision pipelines.
Where Pith is reading between the lines
- The approach could support real-time metric scaling in robotics by fusing relative depth with occasional sparse measurements.
- Testing with varying numbers and placements of sparse points would reveal the minimum data needed for reliable segment scales.
- The two-stage process might extend to video by adding temporal links between segments across frames.
Load-bearing premise
Extremely sparse 3D data points are sufficient and accurate enough to recover consistent metric scales across segments without introducing new errors, and the discontinuity-aware geodesic cost correctly handles all local inconsistencies.
What would settle it
Applying MTD to a relative depth map with known ground-truth metric depth and clustered sparse points, then measuring scale errors in distant segments without nearby points; large errors would show the recovery fails.
Figures


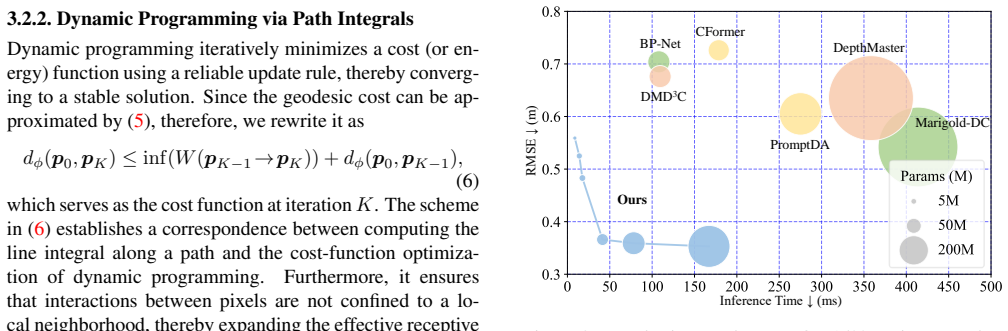












read the original abstract
Recent advances have markedly improved the cross-scene generalization of relative depth estimation, yet its practical applicability remains limited by the absence of metric scale, local inconsistencies, and low computational efficiency. To address these issues, we present \emph{\textbf{M}idas \textbf{T}ouch for \textbf{D}epth} (MTD), a mathematically interpretable approach that converts relative depth into metric depth using only extremely sparse 3D data. To eliminate local scale inconsistencies, it applies a segment-wise recovery strategy via sparse graph optimization, followed by a pixel-wise refinement strategy using a discontinuity-aware geodesic cost. MTD exhibits strong generalization and achieves substantial accuracy improvements over previous depth completion and depth estimation methods. Moreover, its lightweight, plug-and-play design facilitates deployment and integration on diverse downstream 3D tasks. Project page is available at https://mias.group/MTD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MTD (Midas Touch for Depth), a plug-and-play method that converts relative depth estimates into metric depth using only extremely sparse 3D data. It applies a segment-wise recovery strategy via sparse graph optimization to eliminate local scale inconsistencies, followed by pixel-wise refinement using a discontinuity-aware geodesic cost. The authors claim strong cross-scene generalization and substantial accuracy improvements over prior depth completion and depth estimation methods, along with lightweight design for downstream 3D tasks.
Significance. If the central claims hold with rigorous validation, the approach could meaningfully improve the practical utility of relative depth models by enabling metric-scale output with minimal additional 3D input, facilitating integration into robotics, AR, and other applications where full metric depth is required but dense sensors are unavailable.
major comments (2)
- Abstract: the claim of 'substantial accuracy improvements' and 'strong generalization' is asserted without any quantitative results, error bars, ablation studies, or details on sparse-point selection and optimization formulation, leaving the central claim without visible supporting evidence.
- Method description (segment-wise recovery): the graph optimization for per-segment scale recovery is described as relying on 'extremely sparse' points, yet no analysis is provided of the minimum point density required per segment, behavior when points lie near discontinuities, or robustness to noise in the sparse input; this directly bears on whether the method eliminates inconsistencies or merely substitutes new artifacts.
minor comments (2)
- Abstract: the parenthetical expansion of MTD is given as 'Midas Touch for Depth' but the bolding and spacing in the title rendering are inconsistent with standard LaTeX conventions.
- Project page link is provided but no supplementary material or code repository is referenced, which would aid reproducibility of the claimed lightweight design.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for strengthening the presentation of our claims and the analysis of the method's robustness. We address each major comment below and have made revisions to the manuscript where appropriate to improve clarity and provide additional supporting evidence.
read point-by-point responses
-
Referee: Abstract: the claim of 'substantial accuracy improvements' and 'strong generalization' is asserted without any quantitative results, error bars, ablation studies, or details on sparse-point selection and optimization formulation, leaving the central claim without visible supporting evidence.
Authors: We agree that the abstract, due to its brevity, does not include quantitative details or explicit references to supporting experiments. The full manuscript contains extensive quantitative results, ablation studies, and method details in Sections 3 and 4. To address this directly, we have revised the abstract to include key quantitative highlights (e.g., specific accuracy gains on standard benchmarks) and added cross-references to the experimental validation. We have also expanded the method section with more explicit descriptions of sparse-point selection criteria and the graph optimization formulation, ensuring these are tied to the reported results. revision: yes
-
Referee: Method description (segment-wise recovery): the graph optimization for per-segment scale recovery is described as relying on 'extremely sparse' points, yet no analysis is provided of the minimum point density required per segment, behavior when points lie near discontinuities, or robustness to noise in the sparse input; this directly bears on whether the method eliminates inconsistencies or merely substitutes new artifacts.
Authors: We appreciate this observation on the need for robustness analysis. The original manuscript includes experimental results with varying levels of sparsity and qualitative examples near discontinuities. However, we acknowledge that a dedicated sensitivity analysis was not sufficiently detailed. We have added a new subsection to the experiments section that analyzes minimum point density per segment, performance when points are near discontinuities, and robustness under input noise. These results confirm that the segment-wise optimization eliminates local inconsistencies without introducing new artifacts, supported by both quantitative metrics and visual comparisons. revision: yes
Circularity Check
No circularity: method applies standard optimization and geodesic costs to external inputs
full rationale
The paper presents MTD as a plug-and-play conversion pipeline that takes relative depth plus extremely sparse 3D points as inputs, applies segment-wise sparse graph optimization for scale recovery, then pixel-wise refinement via a discontinuity-aware geodesic cost. These operations are described as standard techniques (graph optimization, geodesic distances) whose outputs are not shown to be mathematically identical to any fitted parameter or quantity defined inside the paper itself. No equations equate a 'prediction' to its own fitting objective by construction, no uniqueness theorem is imported from the authors' prior work, and no self-citation chain is load-bearing for the central claim. The derivation chain therefore remains self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Radhakrishna Achanta et al. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods.IEEE Transactions on Pattern Analysis and Machine Intelligence, 34(11):2274– 2282, 2012. 3, 15, 17
work page 2012
-
[2]
1–a model zoo for robust monocular relative depth estimation
Reiner Birkl et al. MiDaS v3.1 – A Model Zoo for Ro- bust Monocular Relative Depth Estimation.arXiv preprint arXiv:2307.14460, 2023. 2, 6, 14
-
[3]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Aleksei Bochkovskii et al. Depth pro: Sharp monocu- lar metric depth in less than a second.arXiv preprint arXiv:2410.02073, 2024. 6, 14
work page internal anchor Pith review arXiv 2024
-
[4]
Yohann Cabon et al. Virtual kitti 2.arXiv preprint arXiv:2001.10773, 2020. 5, 12
work page internal anchor Pith review arXiv 2001
-
[5]
nuScenes: A Multimodal Dataset for Autonomous Driving
Holger Caesar et al. nuScenes: A Multimodal Dataset for Autonomous Driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 5, 9, 12
work page 2020
-
[6]
Domain Generalized Stereo Matching via Hierarchical Visual Transformation
Tianyu Chang et al. Domain Generalized Stereo Matching via Hierarchical Visual Transformation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9559–9568, 2023. 15
work page 2023
-
[7]
Depth Estimation via Affinity Learned with Convolutional Spatial Propagation Network
Xinjing Cheng et al. Depth Estimation via Affinity Learned with Convolutional Spatial Propagation Network. InPro- ceedings of the European Conference on Computer Vision (ECCV), pages 103–119, 2018. 14
work page 2018
-
[8]
ScanNet: Richly-Annotated 3D Recon- structions of Indoor Scenes
Angela Dai et al. ScanNet: Richly-Annotated 3D Recon- structions of Indoor Scenes. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. 5, 9, 12
work page 2017
-
[9]
Omnidata: A scalable pipeline for mak- ing multi-task mid-level vision datasets from 3d scans
Ainaz Eftekhar et al. Omnidata: A scalable pipeline for mak- ing multi-task mid-level vision datasets from 3d scans. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10786–10796, 2021. 14
work page 2021
-
[10]
David Eigen et al. Depth map prediction from a single im- age using a multi-scale deep network.Advances in neural information processing systems (NeurIPS), 27, 2014. 12
work page 2014
-
[11]
Pedro F Felzenszwalb and Daniel P Huttenlocher. Efficient graph-based image segmentation.International Journal of Computer Vision, 59(2):167–181, 2004. 3, 15, 17
work page 2004
-
[12]
Yi Feng et al. ViPOcc: leveraging visual priors from vision foundation models for single-view 3d occupancy prediction. InProceedings of the AAAI Conference on Artificial Intelli- gence (AAAI), pages 3004–3012, 2025. 8
work page 2025
-
[13]
Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a single image
Xiao Fu et al. Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a single image. InProceedings of the European Conference on Computer Vision (ECCV), pages 241–258. Springer, 2024. 2, 6, 14
work page 2024
-
[14]
Yongtao Ge et al. GeoBench: Benchmarking and Analyz- ing Monocular Geometry Estimation Models.arXiv preprint arXiv:2406.12671, 2024. 1, 2, 5, 12
-
[15]
Are we ready for autonomous driv- ing? the KITTI vision benchmark suite
Andreas Geiger et al. Are we ready for autonomous driv- ing? the KITTI vision benchmark suite. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3354–3361. IEEE, 2012. 5, 9, 12
work page 2012
-
[16]
Unsupervised Monocular Depth Esti- mation With Left-Right Consistency
Clement Godard et al. Unsupervised Monocular Depth Esti- mation With Left-Right Consistency. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2017. 7
work page 2017
-
[17]
Digging Into Self-Supervised Monoc- ular Depth Estimation
Clement Godard et al. Digging Into Self-Supervised Monoc- ular Depth Estimation. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), 2019. 7, 8
work page 2019
-
[18]
Neural Markov Random Field for Stereo Matching
Tongfan Guan et al. Neural Markov Random Field for Stereo Matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5459–5469, 2024. 15
work page 2024
-
[19]
3D Packing for Self-Supervised Monoc- ular Depth Estimation
Vitor Guizilini et al. 3D Packing for Self-Supervised Monoc- ular Depth Estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 5, 9, 12
work page 2020
-
[20]
Lotus: Diffusion-based visual foundation model for high-quality dense prediction
Jing He et al. Lotus: Diffusion-based visual foundation model for high-quality dense prediction.arXiv preprint arXiv:2409.18124, 2024. 2, 6, 14
-
[21]
Mu Hu et al. Metric3d v2: A versatile monocular geomet- ric foundation model for zero-shot metric depth and surface normal estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 2, 6
work page 2024
-
[22]
MVSAnywhere: Zero-Shot Multi- View Stereo
Sergio Izquierdo et al. MVSAnywhere: Zero-Shot Multi- View Stereo. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11493–11504, 2025. 8
work page 2025
-
[23]
Uncertainty Guided Adaptive Warping for Robust and Efficient Stereo Matching
Junpeng Jing et al. Uncertainty Guided Adaptive Warping for Robust and Efficient Stereo Matching. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3318–3327, 2023. 15
work page 2023
-
[24]
HyunJun Jung et al. Is my Depth Ground-Truth Good Enough? HAMMER–Highly Accurate Multi-Modal Dataset for DEnse 3D Scene Regression.arXiv preprint arXiv:2205.04565, 2022. 5, 9, 12
-
[25]
Repurposing diffusion-based image gen- erators for monocular depth estimation
Bingxin Ke et al. Repurposing diffusion-based image gen- erators for monocular depth estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9492–9502, 2024. 2, 5, 6, 7, 12, 14
work page 2024
-
[26]
Alexander Kirillov et al. Segment Anything. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion (ICCV), pages 4015–4026, 2023. 5, 12
work page 2023
-
[27]
Tobias Koch et al. Comparison of monocular depth esti- mation methods using geometrically relevant metrics on the IBims-1 dataset.Computer Vision and Image Understand- ing, 191:102877, 2020. 5, 9, 12
work page 2020
-
[28]
Know Your Neighbors: Improving Single- View Reconstruction via Spatial Vision-Language Reason- ing
Rui Li et al. Know Your Neighbors: Improving Single- View Reconstruction via Spatial Vision-Language Reason- ing. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 9848– 9858, 2024. 8
work page 2024
-
[29]
Superpixel Segmenta- tion Using Linear Spectral Clustering
Zhengqin Li and Jiansheng Chen. Superpixel Segmenta- tion Using Linear Spectral Clustering. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2015. 15, 17
work page 2015
-
[30]
Distilling Monocular Foundation Model for Fine-grained Depth Completion
Yingping Liang et al. Distilling Monocular Foundation Model for Fine-grained Depth Completion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 22254–22265, 2025. 2, 3, 6, 12, 13, 14
work page 2025
-
[31]
Prompting Depth Anything for 4K Reso- lution Accurate Metric Depth Estimation
Haotong Lin et al. Prompting Depth Anything for 4K Reso- lution Accurate Metric Depth Estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17070–17080, 2025. 2, 6, 13
work page 2025
-
[32]
Dynamic spatial propagation network for depth completion
Yuankai Lin et al. Dynamic spatial propagation network for depth completion. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), pages 1638–1646, 2022. 2
work page 2022
-
[33]
RAFT-Stereo: Multilevel Recurrent Field Transforms for Stereo Matching
Lahav Lipson et al. RAFT-Stereo: Multilevel Recurrent Field Transforms for Stereo Matching. In2021 International Conference on 3D Vision (3DV), pages 218–227, 2021. 15
work page 2021
-
[34]
EfficientViT: Memory Efficient Vision Transformer With Cascaded Group Attention
Xinyu Liu et al. EfficientViT: Memory Efficient Vision Transformer With Cascaded Group Attention. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14420–14430, 2023. 5
work page 2023
-
[35]
Non-local spatial propagation network for depth completion
Jinsun Park et al. Non-local spatial propagation network for depth completion. InProceedings of the European Confer- ence on Computer Vision (ECCV), pages 120–136. Springer,
-
[36]
Depth prompting for sensor-agnostic depth estimation
Jin-Hwi Park et al. Depth prompting for sensor-agnostic depth estimation. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 9859–9869, 2024. 14
work page 2024
-
[37]
Unidepth: Universal monocular metric depth estimation
Luigi Piccinelli et al. Unidepth: Universal monocular metric depth estimation. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 10106–10116, 2024. 2, 12, 14
work page 2024
-
[38]
Unidepthv2: Universal monocular metric depth estimation made simpler
Luigi Piccinelli et al. UniDepthV2: Universal Monocu- lar Metric Depth Estimation Made Simpler.arXiv preprint arXiv:2502.20110, 2025. 2, 6
-
[39]
Towards robust monocular depth esti- mation: Mixing datasets for zero-shot cross-dataset transfer
Ren ´e Ranftl et al. Towards robust monocular depth esti- mation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 44(3):1623–1637, 2020. 2
work page 2020
-
[40]
Vision Transformers for Dense Prediction
Ren ´e Ranftl et al. Vision Transformers for Dense Prediction. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 12179–12188, 2021. 6, 12, 14
work page 2021
-
[41]
Masked Representation Learning for Domain Generalized Stereo Matching
Zhibo Rao et al. Masked Representation Learning for Domain Generalized Stereo Matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5435–5444, 2023. 15
work page 2023
-
[42]
Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding
Mike Roberts et al. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 10912–10922, 2021. 5, 12
work page 2021
-
[43]
Ashutosh Saxena et al. Make3D: Learning 3D Scene Struc- ture from a Single Still Image.IEEE Transactions on Pattern Analysis and Machine Intelligence, 31(5):824–840, 2009. 5, 9, 12
work page 2009
-
[44]
A Multi-View Stereo Benchmark With High-Resolution Images and Multi-Camera Videos
Thomas Schops et al. A Multi-View Stereo Benchmark With High-Resolution Images and Multi-Camera Videos. InPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. 5, 9, 12
work page 2017
-
[45]
Indoor segmentation and support inference from rgbd images
Nathan Silberman et al. Indoor segmentation and support inference from rgbd images. InProceedings of the Euro- pean Conference on Computer Vision (ECCV), pages 746–
- [46]
-
[47]
Depth Estimation From Camera Image and mmWave Radar Point Cloud
Akash Deep Singh et al. Depth Estimation From Camera Image and mmWave Radar Point Cloud. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9275–9285, 2023. 12
work page 2023
-
[48]
SUN RGB-D: A RGB-D Scene Un- derstanding Benchmark Suite
Shuran Song et al. SUN RGB-D: A RGB-D Scene Un- derstanding Benchmark Suite. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015. 5, 9, 12
work page 2015
-
[49]
DepthMaster: Taming Diffusion Models for Monocular Depth Estimation
Ziyang Song, Zerong Wang, Bo Li, Hao Zhang, Ruijie Zhu, Li Liu, Peng-Tao Jiang, and Tianzhu Zhang. Depthmaster: Taming diffusion models for monocular depth estimation. arXiv preprint arXiv:2501.02576, 2025. 2, 6, 12, 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
LoFTR: Detector-Free Local Fea- ture Matching With Transformers
Jiaming Sun et al. LoFTR: Detector-Free Local Fea- ture Matching With Transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8922–8931, 2021. 17
work page 2021
-
[51]
Bilateral propagation network for depth com- pletion
Jie Tang et al. Bilateral propagation network for depth com- pletion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9763–9772, 2024. 2, 3, 6, 12, 13, 14
work page 2024
-
[52]
Zachary Teed and Jia Deng. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.Advances in neu- ral information processing systems (NeurIPS), 34:16558– 16569, 2021. 8, 17
work page 2021
-
[53]
Igor Vasiljevic et al. Diode: A dense indoor and outdoor depth dataset.arXiv preprint arXiv:1908.00463, 2019. 5, 9, 12
-
[54]
Marigold-DC: Zero-Shot Monoc- ular Depth Completion with Guided Diffusion
Massimiliano Viola et al. Marigold-DC: Zero-Shot Monoc- ular Depth Completion with Guided Diffusion. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 5359–5370, 2025. 2, 3, 5, 6, 12, 14
work page 2025
-
[55]
Haotian Wang et al. G2-MonoDepth: A General Framework of Generalized Depth Inference From Monocular RGB+X Data.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(5):3753–3771, 2024. 14
work page 2024
-
[56]
VGGT: Visual Geometry Grounded Transformer
Jianyuan Wang et al. VGGT: Visual Geometry Grounded Transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5294–5306, 2025. 8
work page 2025
-
[57]
TartanAir: A Dataset to Push the Limits of Visual SLAM
Wenshan Wang et al. TartanAir: A Dataset to Push the Limits of Visual SLAM. In2020 IEEE/RSJ International Confer- ence on Intelligent Robots and Systems (IROS), pages 4909– 4916, 2020. 5, 12
work page 2020
-
[58]
Selective-Stereo: Adaptive Frequency In- formation Selection for Stereo Matching
Xianqi Wang et al. Selective-Stereo: Adaptive Frequency In- formation Selection for Stereo Matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19701–19710, 2024. 15
work page 2024
-
[59]
LRRU: Long-short Range Recurrent Up- dating Networks for Depth Completion
Yufei Wang et al. LRRU: Long-short Range Recurrent Up- dating Networks for Depth Completion. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9422–9432, 2023. 2, 6, 12
work page 2023
-
[60]
Behind the scenes: Density fields for single view reconstruction
Felix Wimbauer et al. Behind the scenes: Density fields for single view reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9076–9086, 2023. 8
work page 2023
-
[61]
Alex Wong et al. Unsupervised depth completion from visual inertial odometry.IEEE Robotics and Automation Letters, 5 (2):1899–1906, 2020. 5, 9, 12
work page 1906
-
[62]
Tinyvit: Fast pretraining distillation for small vision transformers
Kan Wu et al. Tinyvit: Fast pretraining distillation for small vision transformers. InProceedings of the European Con- ference on Computer Vision (ECCV), pages 68–85. Springer,
-
[63]
EfficientSAM: Leveraged Masked Im- age Pretraining for Efficient Segment Anything
Yunyang Xiong et al. EfficientSAM: Leveraged Masked Im- age Pretraining for Efficient Segment Anything. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16111–16121, 2024. 5
work page 2024
-
[64]
Iterative Geometry Encoding V olume for Stereo Matching
Gangwei Xu et al. Iterative Geometry Encoding V olume for Stereo Matching. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 21919–21928, 2023. 15
work page 2023
-
[65]
Gangwei Xu et al. IGEV++: Iterative Multi-Range Geome- try Encoding V olumes for Stereo Matching.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 47(8): 7108–7122, 2025. 15
work page 2025
-
[66]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang et al. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10371–10381, 2024. 2, 7
work page 2024
-
[67]
Depth anything v2.Advances in Neural In- formation Processing Systems (NeurIPS), 37:21875–21911,
Lihe Yang et al. Depth anything v2.Advances in Neural In- formation Processing Systems (NeurIPS), 37:21875–21911,
-
[68]
Wei Yin et al. Diversedepth: Affine-invariant depth predic- tion using diverse data.arXiv preprint arXiv:2002.00569,
-
[69]
Learning To Recover 3D Scene Shape From a Single Image
Wei Yin et al. Learning To Recover 3D Scene Shape From a Single Image. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 204–213, 2021. 6, 14
work page 2021
-
[70]
Metric3d: Towards zero-shot metric 3d predic- tion from a single image
Wei Yin et al. Metric3d: Towards zero-shot metric 3d predic- tion from a single image. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9043–9053, 2023. 2
work page 2023
-
[71]
pixelNeRF: Neural Radiance Fields From One or Few Images
Yu, Alex and others. pixelNeRF: Neural Radiance Fields From One or Few Images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4578–4587, 2021. 8
work page 2021
-
[72]
Chi Zhang et al. Hierarchical normalization for robust monocular depth estimation.Advances in neural informa- tion processing systems (NeurIPS), 35:14128–14139, 2022. 14
work page 2022
-
[73]
Faster segment anything: Towards lightweight sam for mobile applications,
Chaoning Zhang et al. Faster segment anything: Towards lightweight sam for mobile applications.arXiv preprint arXiv:2306.14289, 2023. 3, 5
-
[74]
Domain-invariant stereo matching net- works
Feihu Zhang et al. Domain-invariant stereo matching net- works. InProceedings of the European Conference on Com- puter Vision (ECCV), pages 420–439. Springer, 2020. 15
work page 2020
-
[75]
Mengtan Zhang et al. DCPI-Depth: Explicitly Infusing Dense Correspondence Prior to Unsupervised Monocular Depth Estimation.IEEE Transactions on Image Processing, 34:4258–4272, 2025. 7
work page 2025
-
[76]
Ning Zhang et al. Lite-Mono: A Lightweight CNN and Transformer Architecture for Self-Supervised Monocular Depth Estimation. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 18537–18546, 2023. 12
work page 2023
-
[77]
CompletionFormer: Depth Completion With Convolutions and Vision Transformers
Youmin Zhang et al. CompletionFormer: Depth Completion With Convolutions and Vision Transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 18527–18536, 2023. 2, 6, 12
work page 2023
-
[78]
Learning representations from foun- dation models for domain generalized stereo matching
Yongjian Zhang et al. Learning representations from foun- dation models for domain generalized stereo matching. In Proceedings of the European Conference on Computer Vi- sion (ECCV), pages 146–162. Springer, 2024. 15
work page 2024
-
[79]
OGNI-DC: Robust depth com- pletion with optimization-guided neural iterations
Yiming Zuo and Jia Deng. OGNI-DC: Robust depth com- pletion with optimization-guided neural iterations. InPro- ceedings of the European Conference on Computer Vision (ECCV), pages 78–95. Springer, 2024. 2, 12
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.