Recognition: 2 theorem links
· Lean TheoremKeep What Audio Cannot Say: Context-Preserving Token Pruning for Omni-LLMs
Pith reviewed 2026-05-13 01:56 UTC · model grok-4.3
The pith
ContextGuard lets omni-LLMs drop more than half their video tokens at inference without losing accuracy by keeping only what audio cannot convey.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ContextGuard predicts coarse visual semantics from audio and prunes video tokens whose coarse semantics are likely recoverable from audio, while retaining additional video tokens to preserve localized visual details that audio alone cannot specify and merging temporally similar video tokens. The framework requires no downstream LLM fine-tuning and uses only an independently trained lightweight predictor.
What carries the argument
ContextGuard, an inference-time pruning method that identifies prunable video tokens by checking if their coarse semantics can be recovered from the audio input.
If this is right
- Substantial reduction in computational cost for processing multimodal inputs.
- No need for model retraining or fine-tuning to apply the pruning.
- Better performance than previous inference-time pruning approaches at higher compression rates.
- Applicable across different omni-LLM scales without task-specific adjustments.
Where Pith is reading between the lines
- The method highlights how audio can serve as a reliable signal for much of the visual context in videos.
- It could inspire similar pruning techniques for other multimodal combinations like text-image or audio-text.
- Testing on more diverse question types might reveal limits where visual details are crucial beyond coarse semantics.
Load-bearing premise
That the independently trained lightweight predictor can correctly identify video tokens whose information is redundant with the audio for any potential question the model might be asked later.
What would settle it
A benchmark question that requires distinguishing fine visual details in the video that are not predictable from the accompanying audio; if the pruned version performs worse than the full-token version on such questions, the approach would be falsified.
Figures






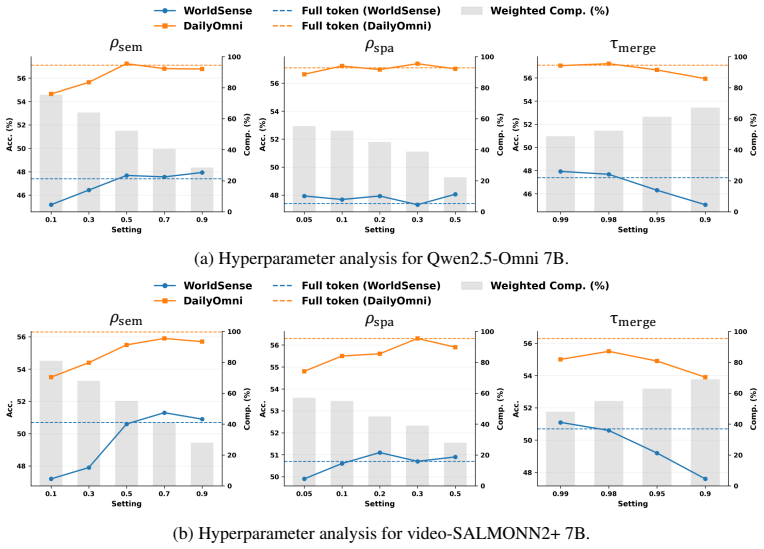







read the original abstract
Omnimodal Large Language Models (Omni-LLMs) incur substantial computational overhead due to the large number of multimodal input tokens they process, making token reduction essential for real-world deployment. Existing Omni-LLM pruning methods typically reduce this cost by selecting tokens that are important for the current query or strongly aligned with cross-modal cues. However, such strategies can discard evidence that falls outside these criteria, even when needed for different questions or for understanding context beyond aligned audio-visual cues. To address this limitation, we reframe Omni-LLM token reduction as preserving broad audio-visual context while removing cross-modal redundancy. We propose ContextGuard, an inference-time token pruning framework built on this principle. ContextGuard predicts coarse visual semantics from audio and prunes video tokens whose coarse semantics are likely recoverable from audio, while retaining additional video tokens to preserve localized visual details that audio alone cannot specify. For further compression, our method merges temporally similar video tokens. The framework requires no downstream LLM fine-tuning and uses only an independently trained lightweight predictor. On Qwen2.5-Omni and Video-SALMONN2+ at 3B and 7B scales across six audio-visual benchmarks, ContextGuard outperforms prior inference-time pruning methods while pruning more tokens. Notably, on Qwen2.5-Omni 7B, ContextGuard achieves full-token-level performance on five of six benchmarks while pruning 55% of input tokens.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ContextGuard, an inference-time token pruning framework for Omni-LLMs. It reframes pruning as preserving broad audio-visual context by using a lightweight predictor to identify and remove video tokens whose coarse semantics are recoverable from audio, while retaining additional tokens for localized visual details and merging temporally similar tokens. The method requires no LLM fine-tuning. Experiments on Qwen2.5-Omni and Video-SALMONN2+ (3B/7B scales) across six audio-visual benchmarks claim that ContextGuard outperforms prior inference-time pruning methods, with the 7B Qwen2.5-Omni model achieving full-token performance on five of six benchmarks at 55% pruning.
Significance. If the empirical claims hold under rigorous controls, the work could meaningfully advance efficient inference for omnimodal models by exploiting cross-modal redundancy without query-specific selection or retraining. The emphasis on context preservation for arbitrary downstream questions addresses a clear limitation of existing pruning strategies and could support longer-context deployments.
major comments (3)
- [Method and Experiments] The central performance claims (full-token equivalence at 55% pruning on five of six benchmarks) rest on the unverified assumption that the independently trained predictor plus retained localized tokens suffice for arbitrary queries. No quantitative evaluation of predictor error rates on query-specific visual details (e.g., text, object attributes, or spatial relations misaligned with audio) is reported, leaving the weakest assumption untested.
- [Experiments] The manuscript provides no experimental details on baselines, number of runs, statistical significance, or controls for the pruning ratio and retention heuristic. This prevents verification of the reported outperformance and near-full performance claims.
- [Experiments] The six benchmarks may not contain sufficient cases exposing the failure mode where fine-grained visual information required by future questions is pruned; the paper should include targeted stress tests or additional datasets with non-audio-aligned details.
minor comments (1)
- [Method] Notation for the predictor output and retention threshold should be defined more explicitly with equations to clarify the inference-time operations.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major comment below and describe the revisions we will incorporate to improve the manuscript.
read point-by-point responses
-
Referee: [Method and Experiments] The central performance claims (full-token equivalence at 55% pruning on five of six benchmarks) rest on the unverified assumption that the independently trained predictor plus retained localized tokens suffice for arbitrary queries. No quantitative evaluation of predictor error rates on query-specific visual details (e.g., text, object attributes, or spatial relations misaligned with audio) is reported, leaving the weakest assumption untested.
Authors: We thank the referee for highlighting this point. The method retains extra tokens precisely to safeguard localized visual details that audio cannot recover, and the reported benchmark results provide indirect support for handling arbitrary queries. To strengthen the evidence, we will add a quantitative analysis of predictor error rates on query-specific details (such as text, object attributes, and spatial relations) in the revised manuscript. revision: yes
-
Referee: [Experiments] The manuscript provides no experimental details on baselines, number of runs, statistical significance, or controls for the pruning ratio and retention heuristic. This prevents verification of the reported outperformance and near-full performance claims.
Authors: We agree that these details are required for full reproducibility and verification of the claims. The revised manuscript will include complete experimental information: the specific baselines, number of runs, statistical significance (means and standard deviations), and controls for pruning ratios and the retention heuristic. revision: yes
-
Referee: [Experiments] The six benchmarks may not contain sufficient cases exposing the failure mode where fine-grained visual information required by future questions is pruned; the paper should include targeted stress tests or additional datasets with non-audio-aligned details.
Authors: We acknowledge that the existing benchmarks may not fully expose failure cases involving fine-grained, non-audio-aligned visual information. We will add targeted stress tests and/or supplementary datasets focused on such details (e.g., text reading or precise object attributes) in the revised version. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes ContextGuard as an inference-time pruning method that relies on an independently trained lightweight predictor to decide which video tokens have coarse semantics recoverable from audio, while retaining additional tokens for localized details and merging temporally similar ones. All reported results are empirical performance measurements on external benchmarks (Qwen2.5-Omni, Video-SALMONN2+, six audio-visual tasks) with no equations, fitted parameters, or self-citations presented as load-bearing derivations. The method is explicitly stated to require no downstream LLM fine-tuning, making the performance claims independent of any internal redefinition or tautological prediction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Flamingo: a Visual Language Model for Few-Shot Learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a Visual Language Model for Few-Shot Learning. InProc. NeurIPS, 2022
work page 2022
-
[2]
Qwen2.5-VL Technical Report.arXiv, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-VL Technical Report.arXiv, 2025
work page 2025
-
[3]
VGGSound: A Large-scale Audio-Visual Dataset
Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zisserman. VGGSound: A Large-scale Audio-Visual Dataset. InProc. ICASSP, 2020
work page 2020
-
[4]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing Multimodal LLM’s Referential Dialogue Magic.arXiv:2306.15195, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An Image is Worth 1/2 Tokens After Layer 2: Plug-and-Play Inference Acceleration for Large Vision-Language Models. InProc. ECCV, 2024
work page 2024
-
[6]
BEATs: Audio Pre-Training with Acoustic Tokenizers
Sanyuan Chen, Yu Wu, Chengyi Wang, Shujie Liu, Daniel Tompkins, Zhuo Chen, Wanxiang Che, Xiangzhan Yu, and Furu Wei. BEATs: Audio Pre-Training with Acoustic Tokenizers. In Proc. ICML, 2023
work page 2023
-
[7]
V AST: A Vision-Audio-Subtitle-Text Omni-Modality Foundation Model and Dataset
Sihan Chen, Handong Li, Qunbo Wang, Zijia Zhao, Mingzhen Sun, Xinxin Zhu, and Jing Liu. V AST: A Vision-Audio-Subtitle-Text Omni-Modality Foundation Model and Dataset. InProc. NeurIPS, 2023
work page 2023
-
[8]
StreamingTOM: Streaming Token Compression for Efficient Video Understanding
Xueyi Chen, Keda Tao, Kele Shao, and Huan Wang. StreamingTOM: Streaming Token Compression for Efficient Video Understanding. InProc. CVPR, 2026
work page 2026
-
[9]
InternVL: Scaling Up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. InternVL: Scaling Up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks. InProc. CVPR, 2024
work page 2024
-
[10]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs.arXiv:2406.07476, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Meerkat: Audio-Visual Large Language Model for Grounding in Space and Time
Sanjoy Chowdhury, Sayan Nag, Subhrajyoti Dasgupta, Jun Chen, Mohamed Elhoseiny, Ruohan Gao, and Dinesh Manocha. Meerkat: Audio-Visual Large Language Model for Grounding in Space and Time. InProc. ECCV, 2024
work page 2024
-
[12]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities.arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Yue Ding, Yiyan Ji, Jungang Li, Xuyang Liu, Xinlong Chen, Junfei Wu, Bozhou Li, Bohan Zeng, Yang Shi, Yushuo Guan, et al. OmniSIFT: Modality-Asymmetric Token Compression for Efficient Omni-modal Large Language Models.arXiv:2602.04804, 2026
work page internal anchor Pith review arXiv 2026
-
[14]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InProc. ICLR, 2021
work page 2021
-
[15]
Video-MME: The First-Ever Compre- hensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-MME: The First-Ever Compre- hensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis. InProc. CVPR, 2025
work page 2025
-
[16]
Jort F. Gemmeke, Daniel P. W. Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Chan- ning Moore, Manoj Plakal, and Marvin Ritter. Audio Set: An ontology and human-labeled dataset for audio events. InProc. ICASSP, 2017. 10
work page 2017
-
[17]
Chao Gong, Depeng Wang, Zhipeng Wei, Ya Guo, Huijia Zhu, and Jingjing Chen. Echo- ingPixels: Cross-Modal Adaptive Token Reduction for Efficient Audio-Visual LLMs. arXiv:2512.10324, 2025
-
[18]
AST: Audio Spectrogram Transformer
Yuan Gong, Yu-An Chung, and James Glass. AST: Audio Spectrogram Transformer. InProc. Interspeech, 2021
work page 2021
-
[19]
OneLLM: One Framework to Align All Modalities with Language
Jiaming Han, Kaixiong Gong, Yiyuan Zhang, Jiaqi Wang, Kaipeng Zhang, Dahua Lin, Yu Qiao, Peng Gao, and Xiangyu Yue. OneLLM: One Framework to Align All Modalities with Language. InProc. CVPR, 2024
work page 2024
-
[20]
WorldSense: Evaluating Real-world Omnimodal Understanding for Multimodal LLMs
Jack Hong, Shilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, and Weidi Xie. WorldSense: Evaluating Real-world Omnimodal Understanding for Multimodal LLMs. InProc. ICLR, 2026
work page 2026
-
[21]
Language is Not All You Need: Aligning Perception with Language Models
Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais Khan Mohammed, Barun Patra, et al. Language is Not All You Need: Aligning Perception with Language Models. InProc. NeurIPS, 2023
work page 2023
-
[22]
Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. GPT-4o System Card. arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Multi-Granular Spatio-Temporal Token Merging for Training-Free Acceleration of Video LLMs
Jeongseok Hyun, Sukjun Hwang, Su Ho Han, Taeoh Kim, Inwoong Lee, Dongyoon Wee, Joon-Young Lee, Seon Joo Kim, and Minho Shim. Multi-Granular Spatio-Temporal Token Merging for Training-Free Acceleration of Video LLMs. InProc. ICCV, 2025
work page 2025
-
[24]
STORM: Token-Efficient Long Video Understanding for Multimodal LLMs
Jindong Jiang, Xiuyu Li, Zhijian Liu, Muyang Li, Guo Chen, Zhiqi Li, De-An Huang, Guilin Liu, Zhiding Yu, Kurt Keutzer, Sungjin Ahn, Jan Kautz, Hongxu Yin, Yao Lu, Song Han, and Wonmin Byeon. STORM: Token-Efficient Long Video Understanding for Multimodal LLMs. InProc. ICCV Workshop, 2025
work page 2025
-
[25]
LLaV A-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. LLaV A-OneVision: Easy Visual Task Transfer. Transactions on Machine Learning Research, 2024
work page 2024
-
[26]
Omnivideobench: Towards audio-visual understanding evaluation for omni mllms, 2025
Caorui Li, Yu Chen, Yiyan Ji, Jin Xu, Zhenyu Cui, Shihao Li, Yuanxing Zhang, Wentao Wang, Zhenghao Song, Dingling Zhang, et al. OmniVideoBench: Towards Audio-Visual Understanding Evaluation for Omni MLLMs.arXiv:2510.10689, 2025
-
[27]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping Language- Image Pre-training with Frozen Image Encoders and Large Language Models. InProc. ICML, 2023
work page 2023
-
[28]
VideoChat- Flash: Hierarchical Compression for Long-Context Video Modeling
Xinhao Li, Yi Wang, Jiashuo Yu, Xiangyu Zeng, Yuhan Zhu, Haian Huang, Jianfei Gao, Kunchang Li, Yinan He, Chenting Wang, Yu Qiao, Yali Wang, and Limin Wang. VideoChat- Flash: Hierarchical Compression for Long-Context Video Modeling. InProc. ICLR, 2026
work page 2026
-
[29]
Video-LLaV A: Learning United Visual Representation by Alignment Before Projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-LLaV A: Learning United Visual Representation by Alignment Before Projection. InProc. EMNLP, 2024
work page 2024
-
[30]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual Instruction Tuning. In Proc. NeurIPS, 2023
work page 2023
-
[31]
Xuyang Liu, Xiyan Gui, Yuchao Zhang, and Linfeng Zhang. Mixing Importance with Diversity: Joint Optimization for KV Cache Compression in Large Vision-Language Models. InProc. ICLR, 2026
work page 2026
-
[32]
arXiv preprint arXiv:2306.09093 , year=
Chenyang Lyu, Minghao Wu, Longyue Wang, Xinting Huang, Bingshuai Liu, Zefeng Du, Shuming Shi, and Zhaopeng Tu. Macaw-LLM: Multi-Modal Language Modeling with Image, Audio, Video, and Text Integration.arXiv:2306.09093, 2023
-
[33]
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models. InProc. ACL, 2024. 11
work page 2024
-
[34]
Artemis Panagopoulou, Le Xue, Ning Yu, Junnan Li, Dongxu Li, Shafiq Joty, Ran Xu, Silvio Savarese, Caiming Xiong, and Juan Carlos Niebles. X-InstructBLIP: A Framework for Aligning X-Modal Instruction-Aware Representations to LLMs and Emergent Cross-modal Reasoning. arXiv:2311.18799, 2023
-
[35]
Adapt- Token: Entropy-based Adaptive Token Selection for MLLM Long Video Understanding
Haozhe Qi, Kevin Qu, Mahdi Rad, Rui Wang, Alexander Mathis, and Marc Pollefeys. Adapt- Token: Entropy-based Adaptive Token Selection for MLLM Long Video Understanding. arXiv:2603.28696, 2026
-
[36]
Quicksviewer: An LMM for Efficient Video Understanding via Reinforced Compression of Video Cubes
Ji Qi, Yuan Yao, Yushi Bai, Bin Xu, Juanzi Li, Zhiyuan Liu, and Tat-Seng Chua. Quicksviewer: An LMM for Efficient Video Understanding via Reinforced Compression of Video Cubes. arXiv:2504.15270, 2025
-
[37]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning Transferable Visual Models From Natural Language Supervision. InProc. ICML, 2021
work page 2021
-
[38]
Robust Speech Recognition via Large-Scale Weak Supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust Speech Recognition via Large-Scale Weak Supervision. InProc. ICML, 2023
work page 2023
-
[39]
LLaV A-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. LLaV A-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models. InProc. ICCV, 2025
work page 2025
-
[40]
C. E. Shannon. A mathematical theory of communication.The Bell System Technical Journal, 27(3):379–423, 1948
work page 1948
-
[41]
HoliTom: Holistic Token Merging for Fast Video Large Language Models
Kele Shao, Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. HoliTom: Holistic Token Merging for Fast Video Large Language Models. InProc. NeurIPS, 2025
work page 2025
-
[42]
Video-XL: Extra-Long Vision Language Model for Hour-Scale Video Understanding
Yan Shu, Zheng Liu, Peitian Zhang, Minghao Qin, Junjie Zhou, Zhengyang Liang, Tiejun Huang, and Bo Zhao. Video-XL: Extra-Long Vision Language Model for Hour-Scale Video Understanding. InProc. CVPR, 2025
work page 2025
-
[43]
video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models
Guangzhi Sun, Wenyi Yu, Changli Tang, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Yuxuan Wang, and Chao Zhang. video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models. InProc. ICML, 2024
work page 2024
-
[44]
Xudong Tan, Peng Ye, Chongjun Tu, Jianjian Cao, Yaoxin Yang, Lin Zhang, Dongzhan Zhou, and Tao Chen. TokenCarve: Information-Preserving Visual Token Compression in Multimodal Large Language Models.arXiv:2503.10501, 2025
-
[45]
Changli Tang, Yixuan Li, Yudong Yang, Jimin Zhuang, Guangzhi Sun, Wei Li, Zejun Ma, and Chao Zhang. video-SALMONN 2: Caption-Enhanced Audio-Visual Large Language Models. arXiv:2506.15220, 2025
-
[46]
DyCoke: Dynamic Compression of Tokens for Fast Video Large Language Models
Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. DyCoke: Dynamic Compression of Tokens for Fast Video Large Language Models. InProc. CVPR, 2025
work page 2025
-
[47]
OmniZip: Audio- Guided Dynamic Token Compression for Fast Omnimodal Large Language Models
Keda Tao, Kele Shao, Bohan Yu, Weiqiang Wang, Jian Liu, and Huan Wang. OmniZip: Audio- Guided Dynamic Token Compression for Fast Omnimodal Large Language Models. InProc. CVPR, 2026
work page 2026
-
[48]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, Soroosh Mariooryad, Yifan Ding, Xinyang Geng, Fred Alcober, Roy Frostig, Mark Omernick, Lexi Walker, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. LLaMA: Open and Efficient Foundation Language Models.arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction
Long Xing, Qidong Huang, Xiaoyi Dong, Jiajie Lu, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang, Feng Wu, and Dahua Lin. PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction. InProc. CVPR, 2025. 12
work page 2025
-
[51]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, et al. Qwen2.5-Omni Technical Report.arXiv:2503.20215, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Chenyu Yang, Xuan Dong, Xizhou Zhu, Weijie Su, Jiahao Wang, Hao Tian, Zhe Chen, Wenhai Wang, Lewei Lu, and Jifeng Dai. PVC: Progressive Visual Token Compression for Unified Image and Video Processing in Large Vision-Language Models. InProc. CVPR, 2025
work page 2025
-
[53]
A VQA: A Dataset for Audio-Visual Question Answering on Videos
Pinci Yang, Xin Wang, Xuguang Duan, Hong Chen, Runze Hou, Cong Jin, and Wenwu Zhu. A VQA: A Dataset for Audio-Visual Question Answering on Videos. InProc. ACM MM, 2022
work page 2022
-
[54]
VisionZip: Longer is Better but Not Necessary in Vision Language Models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. VisionZip: Longer is Better but Not Necessary in Vision Language Models. InProc. CVPR, 2025
work page 2025
-
[55]
TimeChat-Online: 80% Visual Tokens are Naturally Redundant in Streaming Videos
Linli Yao, Yicheng Li, Yuancheng Wei, Lei Li, Shuhuai Ren, Yuanxin Liu, Kun Ouyang, Lean Wang, Shicheng Li, Sida Li, et al. TimeChat-Online: 80% Visual Tokens are Naturally Redundant in Streaming Videos. InProc. ACM MM, 2025
work page 2025
-
[56]
CAT: Enhancing Multimodal Large Language Model to Answer Questions in Dynamic Audio-Visual Scenarios
Qilang Ye, Zitong Yu, Rui Shao, Xinyu Xie, Philip Torr, and Xiaochun Cao. CAT: Enhancing Multimodal Large Language Model to Answer Questions in Dynamic Audio-Visual Scenarios. InProc. ECCV, 2024
work page 2024
-
[57]
Fit and Prune: Fast and Training-free Visual Token Pruning for Multi-modal Large Language Models
Weihao Ye, Qiong Wu, Wenhao Lin, and Yiyi Zhou. Fit and Prune: Fast and Training-free Visual Token Pruning for Multi-modal Large Language Models. InProc. AAAI, 2025
work page 2025
-
[58]
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, et al. RLHF-V: Towards Trustworthy MLLMs via Behavior Alignment from Fine-grained Correctional Human Feedback. InProc. CVPR, 2024
work page 2024
-
[59]
AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling.arXiv:2402.12226, 2024
Jun Zhan, Junqi Dai, Jiasheng Ye, Yunhua Zhou, Dong Zhang, Zhigeng Liu, Xin Zhang, Ruibin Yuan, Ge Zhang, Linyang Li, et al. AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling.arXiv:2402.12226, 2024
-
[60]
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding. InProc. EMNLP, 2023
work page 2023
-
[61]
p-MoD: Building Mixture-of-Depths MLLMs via Progressive Ratio Decay
Jun Zhang, Desen Meng, Ji Qi, Zhenpeng Huang, Tao Wu, and Limin Wang. p-MoD: Building Mixture-of-Depths MLLMs via Progressive Ratio Decay. InProc. ICCV, 2025
work page 2025
-
[62]
LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
Renrui Zhang, Jiaming Han, Chris Liu, Peng Gao, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, and Yu Qiao. LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention. InProc. ICLR, 2024
work page 2024
-
[63]
Zijia Zhao, Longteng Guo, Tongtian Yue, Sihan Chen, Shuai Shao, Xinxin Zhu, Zehuan Yuan, and Jing Liu. ChatBridge: Bridging Modalities with Large Language Model as a Language Catalyst.arXiv:2305.16103, 2023
-
[64]
Daily-omni: Towards audio-visual reasoning with temporal alignment across modalities, 2025
Ziwei Zhou, Rui Wang, Zuxuan Wu, and Yu-Gang Jiang. Daily-Omni: Towards Audio-Visual Reasoning with Temporal Alignment across Modalities.arXiv:2505.17862, 2025
-
[65]
plucked string instrument music
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models. InProc. ICLR, 2024. 13 Appendix A Audio-to-Video Semantic Predictor A.1 Architecture and Training Details Predictor architecture and training objective.We implement the audio-to-video semantic pre- di...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.