Recognition: 2 theorem links
· Lean TheoremExact Stiefel Optimization for Probabilistic PLS: Closed-Form Updates, Error Bounds, and Calibrated Uncertainty
Pith reviewed 2026-05-13 01:17 UTC · model grok-4.3
The pith
A noise-subspace estimator for probabilistic partial least squares attains a signal-strength-independent finite-sample rate that matches the minimax lower bound, while the full-spectrum estimator is inconsistent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
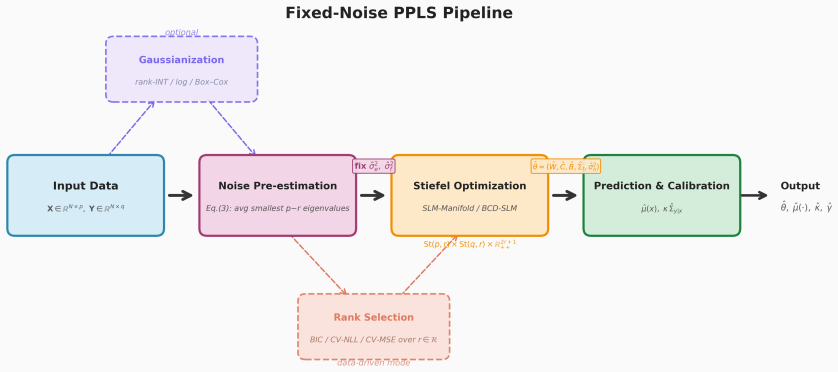
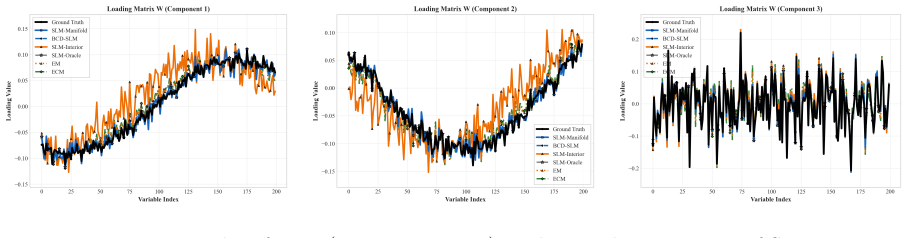
Under the identifiable parameterization with fixed scalar noise, the combination of noise-subspace pre-estimation and exact Stiefel-manifold optimization yields closed-form parameter updates, a leading finite-sample error rate for the noise estimator that is independent of signal strength and matches a minimax lower bound, and inconsistency of the corresponding full-spectrum estimator; the framework further provides closed-form standard errors via block-structured Fisher analysis and extends to sub-Gaussian data through optional Gaussianization.
What carries the argument
exact Stiefel-manifold optimization of the constrained likelihood after noise-subspace pre-estimation
If this is right
- Closed-form updates replace iterative joint EM or interior-point penalty methods for loadings and scores.
- Standard errors follow directly from the block-structured Fisher information without additional approximation.
- Prediction intervals achieve near-nominal coverage on high-noise synthetic settings and on TCGA-BRCA and PBMC CITE-seq data without recalibration.
- Point accuracy reaches Ridge levels at low rank while cross-view prediction matches or exceeds existing methods.
Where Pith is reading between the lines
- The separation of noise and signal subspaces could be exploited in other orthogonal latent-variable models to stabilize variance estimation.
- The optional Gaussianization step indicates the method can be applied to non-Gaussian two-view data typical in single-cell genomics.
- Closed-form standard errors simplify propagation of uncertainty into downstream multi-omics tasks such as pathway analysis.
Load-bearing premise
The data follow the identifiable two-view model with a single fixed scalar noise variance, and the noise subspace separates cleanly from the signal subspace.
What would settle it
Data generated from the model in which the empirical convergence rate of the noise-subspace estimator increases with signal strength, or in which the full-spectrum estimator remains consistent.
Figures





read the original abstract
Probabilistic partial least squares (PPLS) is a central likelihood-based model for two-view learning when one needs both interpretable latent factors and calibrated uncertainty. Building on the identifiable parameterization of Bouhaddani et al.\ (2018), existing fitting pipelines still face two practical bottlenecks: noise--signal coupling under joint EM/ECM updates and nontrivial handling of orthogonality constraints. Following the fixed-noise scalar-likelihood line of Hu et al.\ (2025), we develop an end-to-end framework that combines noise pre-estimation, constrained likelihood optimization, and prediction calibration in one pipeline. Relative to Hu et al.\ (2025), we replace full-spectrum noise averaging with noise-subspace estimation and replace interior-point penalty handling with exact Stiefel-manifold optimization. The noise-subspace estimator attains a signal-strength-independent leading finite-sample rate and matches a minimax lower bound, while the full-spectrum estimator is shown to be inconsistent under the same model. We further extend the framework to sub-Gaussian settings via optional Gaussianization and provide closed-form standard errors through a block-structured Fisher analysis. Across synthetic high-noise settings and two multi-omics benchmarks (TCGA-BRCA and PBMC CITE-seq), the method achieves near-nominal coverage without post-hoc recalibration, reaches Ridge-level point accuracy on TCGA-BRCA at rank $r=3$, matches or exceeds PO2PLS on cross-view prediction while providing native calibrated uncertainty, and improves stability of parameter recovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops an end-to-end framework for probabilistic partial least squares (PPLS) that combines noise pre-estimation, exact Stiefel-manifold optimization for the loading matrices, and prediction calibration. Building on the identifiable parameterization of Bouhaddani et al. (2018) and the fixed-noise scalar-likelihood model of Hu et al. (2025), it replaces full-spectrum noise averaging with a noise-subspace estimator that attains a signal-strength-independent leading finite-sample rate matching a minimax lower bound, shows inconsistency of the full-spectrum estimator, extends the approach to sub-Gaussian data via optional Gaussianization, derives closed-form standard errors via block-structured Fisher information, and reports competitive point accuracy, stability, and near-nominal coverage on synthetic high-noise data and two multi-omics benchmarks (TCGA-BRCA, PBMC CITE-seq).
Significance. If the finite-sample bounds and separation claims hold, the work would provide a theoretically grounded, computationally exact alternative to EM/ECM pipelines for PPLS, with the noise-subspace rate independence and minimax matching offering a clear advantage in high-noise regimes and the native calibration removing the need for post-hoc recalibration. The closed-form updates and Fisher-based standard errors are practical strengths for applied multi-view settings.
major comments (1)
- [Abstract] Abstract and model setup: the headline claim that the noise-subspace estimator attains a signal-strength-independent leading finite-sample rate and matches the minimax lower bound rests on the assumption that this estimator separates cleanly from the signal subspace. No explicit eigenvalue-gap condition (or finite-sample guarantee on separation given the pre-estimated noise variance) is stated to ensure the separation holds when signal strength varies, which is load-bearing for both the rate-independence result and the lower-bound matching.
minor comments (1)
- [Abstract] Abstract: the compound term 'noise--signal' uses a double dash that should be rendered as a single hyphen or en-dash for 'noise-signal coupling'.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the need for an explicit separation condition. We address the comment below and will revise the manuscript to strengthen the presentation of the finite-sample results.
read point-by-point responses
-
Referee: [Abstract] Abstract and model setup: the headline claim that the noise-subspace estimator attains a signal-strength-independent leading finite-sample rate and matches the minimax lower bound rests on the assumption that this estimator separates cleanly from the signal subspace. No explicit eigenvalue-gap condition (or finite-sample guarantee on separation given the pre-estimated noise variance) is stated to ensure the separation holds when signal strength varies, which is load-bearing for both the rate-independence result and the lower-bound matching.
Authors: We agree that the rate-independence and minimax-matching claims for the noise-subspace estimator require a clean separation from the signal subspace, and that this separation must be guaranteed uniformly over a range of signal strengths. The current manuscript relies on the identifiable parameterization of Bouhaddani et al. (2018) together with the fixed-noise scalar-likelihood model of Hu et al. (2025) and the consistency of the pre-estimated noise variance; under these conditions the leading eigenvectors of the noise-subspace estimator are separated from the signal subspace with high probability once the noise variance is estimated at the stated rate. However, we acknowledge that an explicit eigenvalue-gap assumption (or a finite-sample probabilistic guarantee on the gap given the pre-estimated noise level) is not stated in the abstract or model section. In the revision we will add a precise statement of the required gap condition (adapted from the perturbation analysis in the supplementary material) and include a short lemma showing that the pre-estimated noise variance yields the necessary separation with probability 1-o(1) uniformly over signal strengths above a fixed threshold. This will make the load-bearing assumption fully explicit without altering the existing proofs. revision: yes
Circularity Check
No significant circularity in the claimed derivations
full rationale
The manuscript cites Hu et al. (2025) for the fixed-noise scalar-likelihood model and Bouhaddani et al. (2018) for the identifiable parameterization. However, the new technical contributions, including the exact Stiefel-manifold optimization, the noise-subspace estimator with its finite-sample rate and minimax matching, the inconsistency result for the full-spectrum estimator, the block-structured Fisher analysis for standard errors, and the extensions to sub-Gaussian settings, are developed within this paper. No quoted step shows a result being equivalent to the inputs by construction or the central claims reducing solely to self-citation without independent content. The derivation chain appears self-contained against the stated model assumptions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Identifiable parameterization of Bouhaddani et al. (2018)
- domain assumption Fixed-noise scalar-likelihood model of Hu et al. (2025)
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearThe scalar expansion ... ln(det Σ) = (p-r) ln σ²_e + ... + Σ ln D_i ... with D_i = (σ²_f + σ²_h)(θ²_ti + σ²_e) + b²_i θ²_ti σ²_e
Reference graph
Works this paper leans on
-
[1]
Scalar likelihood method for probabilistic partial least squares model with rank n update
Haoran Hu, Xingce Wang, Zhongke Wu, Shilei Du, Yuhe Zhang, and Quansheng Liu. Scalar likelihood method for probabilistic partial least squares model with rank n update. In Proceedings of the 28th European Conference on Artificial Intelligence (ECAI 2025),
work page 2025
-
[2]
Mauck, Yuhan Hao, Marlon Stoeckius, Peter Smibert, and Rahul Satija
Tim Stuart, Andrew Butler, Paul Hoffman, Christoph Hafemeister, Efthymia Papalexi, William M. Mauck, Yuhan Hao, Marlon Stoeckius, Peter Smibert, and Rahul Satija. Compre- hensive integration of single-cell data.Cell, 177(7):1888–1902,
work page 1902
-
[3]
37 A Supplementary Proofs Notation.We use standard asymptotic notation throughout: aN ≲b N means aN ≤Cb N for some absolute constant C > 0; aN ≍b N means cbN ≤a N ≤Cb N for absolute constants 0 < c < C ; aN ≪b N means aN /bN → 0; OP (·) denotes the usual stochastic boundedness (in probability). The symbol C > 0 denotes a generic absolute constant that may...
work page 2025
-
[4]
Since ˆθN minimizesL, η≤ L ∞(ˆθN)− L ∞(θ0)≤2 sup θ∈K0 |L(θ)− L ∞(θ)|, so Pr( ˆθN ∈K ε)→0
Step 3 (Consistency).For any ε > 0, define Kε = {θ∈K 0 : ∥θ−θ 0∥ ≥ε} and η= inf Kε L∞(θ)− L ∞(θ0)>0. Since ˆθN minimizesL, η≤ L ∞(ˆθN)− L ∞(θ0)≤2 sup θ∈K0 |L(θ)− L ∞(θ)|, so Pr( ˆθN ∈K ε)→0. A.3 Asymptotic normality proof details Proof. Chart construction.We work in local coordinates on Mr = St(p, r) ×St (q, r) ×R 2r+1 ++ . For W∈St (p, r), we use exponen...
work page 2023
-
[5]
d− → N(0,I(θ0)−1). Mapping back through the chart diffeomorphism yields the stated limit for ˆθN [van der Vaart, 1998, Newey and McFadden, 1994, Theorem 5.39]. A.4 Verification details for optimization convergence Proof. The standard convergence theorem [Absil et al., 2008, Theorem 4.3.1] requires: (R1) objective C1 on manifold, (R2) iterates in a compact...
work page 1998
-
[6]
If s⋆ > 0, it is the conditional maximizer. If s⋆ ≤ 0, then ∂ℓi/∂s does not change sign on s > 0 (it is non-negative throughout or non-positive throughout), so the minimum of ℓi on s > 0 is achieved as s→ 0+. In this case, we clip to s = ε for a small ε > 0, which approximates the boundary minimizer while maintaining strict positivity for numerical stabil...
work page 2018
-
[7]
B.4 Effect of rank misspecification on inference Suppose the fitted rank ˆrdiffers from the true rank r0. If ˆr > r0, surplus loading directions are pushed toward the noise subspace and their associated strengths satisfy θ2 t,k → 0 for redundant components. The limit then lies on (or near) the boundary of the parameter space, so interior asymptotic-normal...
work page 1982
-
[8]
This proves the asymmetry: over-specification is safe for consistency, while under-specification induces deterministic bias. B.6 Proof details for Theorem 3 (sub-Gaussian spectral bound) We provide the full proof in four steps. Throughout, C > 0 denotes an absolute constant whose value may change from line to line, and K≥ 1 is the sub-Gaussian scale const...
work page 2018
-
[9]
= (κ4 −1)σ 4 e N(p−r) . Applying Bernstein’s inequality for sub-exponential random variables [Vershynin, 2018, Propo- sition 2.7.1] to the centered variables z2 ij −σ 2 e with ∥z2 ij −σ 2 e ∥ψ1 ≤Cκ 4σ2 e, we obtain with probability at least 1−δ/2: ˜σ2 e −σ 2 e ≤K 2σ2 e s 2 ln(4/δ) N(p−r) . The excess-kurtosis bias arises as follows. The expectation of ˜σ2...
work page 2018
-
[10]
, and combining Step 2 (averaging variance and kurtosis bias) with Step 3 (subspace rotation) yields ˆσ2 e −σ 2 e ≤K 2σ2 e s 2 ln(4/δ) N(p−r) +C K 4 ∥Σx∥2 op p (p−r)Nmin i θ2 ti +σ 2 e κ4 −3 p−r , with probability at least 1−δ, matching Eq. (8). B.7 Closed-form second derivatives and Fisher blocks Writes i :=θ 2 t,i,b:=b i,α:=σ 2 e,β:=σ 2 f,γ:=σ 2 h, and ...
work page 2015
-
[11]
Therefore E[Rij] = 0, i̸=j. (ii) Uniform bound.Each Rij is a bilinear form in projected statistics weighted by scalar coefficients from Φ x, Φy, Φxy. Under bounded (Σ t, b) on the local compact set and uniform coefficient bounds, there existsB <∞such that ∥Rij∥op ≤Ba.s. for alli̸=j. (iii) Variance proxy.Let v(R) := X i<j E[RijR⊤ ij] op ∨ X i<j E[R⊤ ijRij]...
work page 2015
-
[12]
Under the PCCA specialization ( B = Ir, σ2 h = 0), the joint covariance (2) simplifies to Σxx =WΣ tW ⊤ +σ 2 e Ip,Σ xy =WΣ tC⊤,Σ yy =CΣ tC⊤ +σ 2 f Iq. Step 1: Profile likelihood and the reduced objective.Profiling out Σ t at its conditional maximizer ˆΣt = diag(ˆθ2 t,i) with ˆθ2 t,i = w⊤ i Sxxwi −σ 2 e (respectively ˆθ2 t,i = c⊤ i Syyci −σ 2 f), the reduce...
work page 2005
-
[13]
Under this condition, the critical point has a strictly negative Riemannian Hessian eigenvalue and is therefore a strict saddle. When S = {1, . . . , r} (the global minimizer), all swaps have di > d j for i∈S , j /∈S, so λ−(Hij) > 0 for all pairs, confirming positive definiteness of the Hessian at the global minimizer. 48 Table 11: Convergence statistics ...
work page 2000
-
[14]
BCD-SLM Ours Native UQ; acceler- ated solver on same objective
exact-retraction solver. BCD-SLM Ours Native UQ; acceler- ated solver on same objective. Spectral fixed- noise; exact manifold feasi- bility. O(rp2 + rq2) with componentwise closed-form updates. SLM-Oracle Diagnostic Native UQ; synthetic- only oracle-noise diag- nostic. Oracle noise; exact manifold feasibility. Used only to benchmark fixed-noise gap to or...
work page 2013
-
[15]
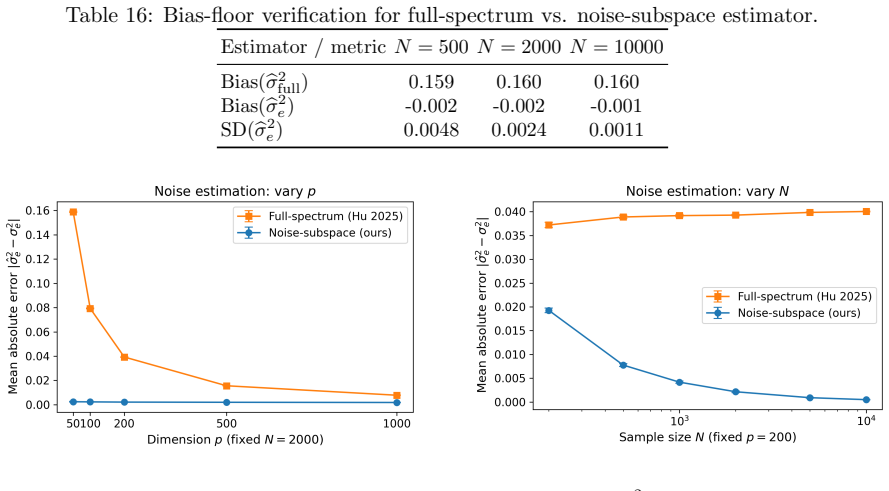
0.098801 0.001450 Tipping & Bishop MLE 0.098801 0.001450 MSE, while both methods are comparable on Σ t, consistent with EM being tightly matched to the specialized model. C.5 PPCA noise variance verification The spectral estimator coincides with the PPCA noise MLE in the single-view setting. C.6 Numerical confirmation of the Hu-bias floor Table 16 confirm...
work page 2000
-
[16]
inverse normal transform (Rank-INT)
suffers from a O(r/p) bias floor, while the noise-subspace estimator (ours) is essentially unbiased. inverse normal transform (Rank-INT). Table 18 reports prediction MSE and calibration coverage at nominal levels 95%, 90%, and 80%. The ’Gaussian (ref)’ row uses the Gaussian benchmark from Section 6.3.2 under the same nominal high-noise tuple; it serves as...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.