Recognition: 2 theorem links
· Lean TheoremPRISM: A Geometric Risk Bound that Decomposes Drift into Scale, Shape, and Head
Pith reviewed 2026-05-13 01:31 UTC · model grok-4.3
The pith
PRISM derives a closed-form upper bound on LLM risk gaps by decomposing post-training drift into scale mismatch, shape mismatch, and head divergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
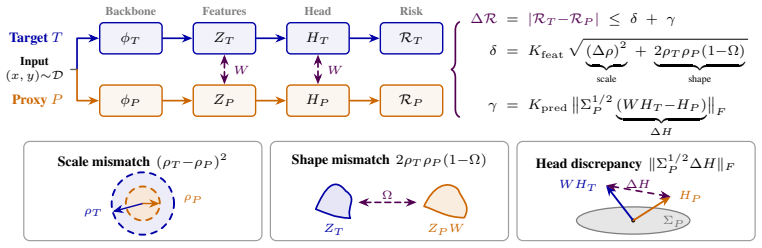
PRISM exploits the linear output head of LLMs and the empirically near-isometric structure of their backbones to derive a closed-form upper bound on the cross-entropy risk gap between a target model and a post-training variant. The bound decomposes drift into scale mismatch, shape mismatch, and head divergence. Each axis corresponds to a distinct failure mode, including shape distortion under low-bit quantization, scale separability under LoRA forgetting, and head divergence under GGUF k-quantization. The same geometry yields variant rankings with mean Spearman correlations of 0.820 for quantization and 0.831 for LoRA forgetting and supplies a differentiable shape regularizer that mitigates忘
What carries the argument
PRISM, the geometric upper bound obtained by mapping representation drift through the linear head to isolate scale, shape, and head components.
If this is right
- Variants can be ranked by their total drift score with mean Spearman correlations above 0.82 to measured risk on quantization and LoRA tasks.
- The axis with the largest contribution indicates a concrete remediation direction such as adjusting bit width for shape issues.
- The differentiable shape term can be inserted directly into training as a regularizer that outperforms experience replay at preserving downstream performance.
- Each of the three components can be measured independently on new variants without retraining the full model.
Where Pith is reading between the lines
- If the near-isometric property extends to additional model families, the same decomposition could be applied to distillation or full fine-tuning pipelines.
- The three-axis view could help practitioners choose among competing post-training methods by inspecting only the dominant mismatch rather than running complete evaluations.
- Analogous bounds might be derived for losses other than cross-entropy by substituting the appropriate head mapping.
Load-bearing premise
The backbones of LLMs possess a near-isometric structure that allows the linear head to produce a closed-form risk bound.
What would settle it
A set of post-trained models on which the PRISM-computed bound fails to upper-bound the measured cross-entropy risk gap or on which the Spearman correlation with actual risk falls below 0.6.
Figures






read the original abstract
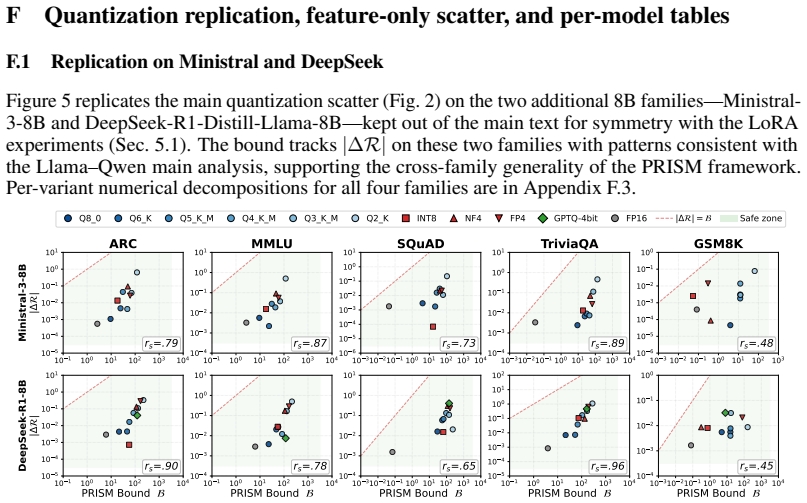
Comparing post-training LLM variants, such as quantized, LoRA-adapted, and distilled models, requires a diagnostic that identifies how a variant has drifted, not only whether it has degraded. Existing similarity scores such as CKA and SVCCA can flag degradation, but they do not directly link representation drift to risk or mechanism. We propose PRISM, Proxy Risk Inference via Structural Mapping, which exploits the linear output head of LLMs and the empirically near-isometric structure of their backbones to derive a closed-form upper bound on the cross-entropy risk gap between a target model and a post-training variant. The bound is calibrated for variant ranking and decomposes drift into three independently measurable axes: scale mismatch, shape mismatch, and head divergence. Each axis corresponds to a distinct failure mode, including shape distortion under low-bit quantization, scale separability under LoRA forgetting, and head divergence under GGUF k-quantization. As a result, the dominant axis suggests a remediation direction rather than merely raising a degradation flag. Because the shape term is differentiable, the same geometry can also serve as a training-time regularizer against catastrophic forgetting. Across two model families and five benchmarks, PRISM ranks variants with mean Spearman correlations of 0.820 for post-training quantization and 0.831 for LoRA forgetting, and its axis-guided shape regularizer outperforms experience replay in aggregate at mitigating downstream forgetting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PRISM, which exploits the linear output head of LLMs and their empirically near-isometric backbone representations to derive a closed-form upper bound on the cross-entropy risk gap between a target model and post-training variants (e.g., quantized or LoRA-adapted). The bound decomposes drift into scale mismatch, shape mismatch, and head divergence terms, is calibrated for ranking, and yields mean Spearman correlations of 0.820 for quantization and 0.831 for LoRA forgetting across two model families and five benchmarks. The differentiable shape term is additionally used as a training regularizer that outperforms experience replay at mitigating forgetting.
Significance. If the derivation holds and the near-isometry assumption is quantitatively verified, PRISM would offer a useful advance by linking geometric drift directly to risk in a decomposable, actionable way that goes beyond similarity metrics like CKA or SVCCA. The reported ranking correlations and the regularizer result are concrete strengths that demonstrate potential practical value for diagnosing and mitigating specific post-training failure modes.
major comments (2)
- [§3] §3 (derivation of the PRISM bound): The closed-form claim depends on the backbone being near-isometric so that inner-product or distance preservation allows elimination of explicit integration over the representation distribution. The manuscript states this only as an empirical observation without reporting a quantitative tolerance (e.g., max or average deviation from isometry) or measured values on the evaluated models. This is load-bearing; material deviation would invalidate the algebraic simplification and make the bound non-closed-form, undermining the interpretation of the reported Spearman correlations as evidence for the three-axis decomposition.
- [§5] §5 (experimental results and tables): The mean Spearman correlations of 0.820 and 0.831 are presented without error bars, per-axis ablations, or comparisons to baselines such as direct risk estimation or other geometric measures. It is also unclear whether the 'calibration for variant ranking' introduces any data-dependent fitting that would contradict the parameter-free character implied by the closed-form derivation.
minor comments (2)
- [Abstract] The abstract refers to 'five benchmarks' without naming them; this should be stated explicitly for reproducibility.
- [§2] Notation for the three axes (scale, shape, head) should be introduced with explicit equations early in the paper to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important points for strengthening the manuscript's rigor. We address each major comment below and will incorporate revisions to provide quantitative verification of the isometry assumption and enhanced experimental details.
read point-by-point responses
-
Referee: [§3] §3 (derivation of the PRISM bound): The closed-form claim depends on the backbone being near-isometric so that inner-product or distance preservation allows elimination of explicit integration over the representation distribution. The manuscript states this only as an empirical observation without reporting a quantitative tolerance (e.g., max or average deviation from isometry) or measured values on the evaluated models. This is load-bearing; material deviation would invalidate the algebraic simplification and make the bound non-closed-form, undermining the interpretation of the reported Spearman correlations as evidence for the three-axis decomposition.
Authors: We agree that the near-isometry assumption is central to the closed-form derivation and that quantitative evidence is required. The current manuscript presents this as an empirical observation supported by prior work on LLM representations, but does not include explicit metrics. In the revision, we will add a dedicated subsection with measured deviations from isometry (e.g., average and maximum relative error in inner-product preservation and Euclidean distance preservation) computed on the evaluated models and layers. These will be reported for both model families across the benchmarks. If deviations remain small, this will corroborate the approximation; we will also discuss sensitivity of the bound to larger deviations. revision: yes
-
Referee: [§5] §5 (experimental results and tables): The mean Spearman correlations of 0.820 and 0.831 are presented without error bars, per-axis ablations, or comparisons to baselines such as direct risk estimation or other geometric measures. It is also unclear whether the 'calibration for variant ranking' introduces any data-dependent fitting that would contradict the parameter-free character implied by the closed-form derivation.
Authors: We acknowledge these gaps in statistical reporting and comparative analysis. In the revised manuscript, we will add error bars to the Spearman correlations (via bootstrap resampling over variants or seeds where applicable) and include per-axis ablations showing the ranking contribution of scale, shape, and head terms individually. We will also add comparisons to baselines including CKA, SVCCA, and direct risk estimation. Regarding calibration: it consists of a fixed, monotonic post-hoc scaling (derived once from a small held-out set of variants) solely to improve interpretability for ranking; the core bound remains parameter-free and closed-form. We will clarify the exact procedure and confirm it does not involve per-experiment fitting on evaluation data. revision: yes
Circularity Check
PRISM derivation is self-contained from linear-head and isometry assumptions
full rationale
The paper states that it exploits the linear output head of LLMs together with the empirically near-isometric structure of their backbones to derive a closed-form upper bound on the cross-entropy risk gap, which is then calibrated for ranking and validated on post-training quantization and LoRA forgetting tasks. No equation or step is shown to reduce by construction to a fitted parameter, a self-citation chain, or a renaming of the input data; the bound is presented as an algebraic consequence of the stated geometric assumptions, with the reported Spearman correlations serving as external empirical checks rather than tautological outputs of the derivation itself.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM output head is linear
- domain assumption Backbone representations are empirically near-isometric
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 1 (Exact Scale–Shape Decomposition). For any W∈O(d), 1/n ∥ZT−ZPW∥²F=(ρT−ρP)² + 2ρTρP(1−ΩW)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 (Unified Risk Bound) ... δ + γ with Kfeat from pairwise token-embedding distances
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
GPTQ: Accurate post-training quantization for generative pre-trained transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate post-training quantization for generative pre-trained transformers. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[2]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 30318–30332. Curran Associates, Inc., 2022
work page 2022
-
[3]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models. In International Conference on Learning Representations (ICLR), 2022
work page 2022
-
[4]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[5]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Maithra Raghu, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein. SVCCA: Singu- lar vector canonical correlation analysis for deep learning dynamics and interpretability. In Advances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[8]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InInternational Conference on Machine Learning (ICML), 2019
work page 2019
-
[9]
Grounding representation similarity with statistical testing
Frances Ding, Jean-Stanislas Denain, and Jacob Steinhardt. Grounding representation similarity with statistical testing. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
work page 2021
-
[10]
Reliability of CKA as a similarity measure in deep learning
MohammadReza Davari, Stefan Horoi, Amine Natik, Guillaume Lajoie, Guy Wolf, and Eugene Belilovsky. Reliability of CKA as a similarity measure in deep learning. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[11]
Max Klabunde, Tobias Schumacher, Markus Strohmaier, and Florian Lemmerich. Similarity of neural network models: A survey of functional and representational measures.ACM Computing Surveys, 57(9):1–52, 2025. doi: 10.1145/3728458
-
[12]
The linear representation hypothesis and the geometry of large language models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. InInternational Conference on Machine Learning (ICML), 2024
work page 2024
-
[13]
Relative representations enable zero-shot latent space communication
Luca Moschella, Valentino Maiorca, Marco Fumero, Antonio Norelli, Francesco Locatello, and Emanuele Rodolà. Relative representations enable zero-shot latent space communication. In International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[14]
Generalized shape metrics on neural representations
Alex H Williams, Erin Kunz, Simon Kornblith, and Scott W Linderman. Generalized shape metrics on neural representations. InAdvances in Neural Information Processing Systems (NeurIPS), 2021. 10
work page 2021
-
[15]
What representational similarity measures imply about decodable information
Sarah E Harvey, David Lipshutz, and Alex H Williams. What representational similarity measures imply about decodable information. InProceedings of UniReps: the Second Edition of the Workshop on Unifying Representations in Neural Models, volume 285 ofProceedings of Machine Learning Research, pages 140–151. PMLR, 2024
work page 2024
-
[16]
Position: The platonic representation hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. Position: The platonic representation hypothesis. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 20617–20642. PMLR, 2024
work page 2024
-
[17]
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models. InInternational Conference on Machine Learning (ICML), pages 38087–38099. PMLR, 2023
work page 2023
-
[18]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences (PNAS), 114(13):3521–3526, 2017
work page 2017
-
[19]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[20]
Training compute-optimal large language models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[21]
tinyBenchmarks: Evaluating LLMs with fewer examples
Felipe Maia Polo, Lucas Weber, Leshem Choshen, Yuekai Sun, Gongjun Xu, and Mikhail Yurochkin. tinyBenchmarks: Evaluating LLMs with fewer examples. InInternational Confer- ence on Machine Learning (ICML), 2024
work page 2024
-
[22]
Efficient benchmarking (of language models)
Yotam Perlitz, Elron Bandel, Ariel Gera, Ofir Arviv, Liat Ein-Dor, Eyal Shnarch, Noam Slonim, Michal Shmueli-Scheuer, and Leshem Choshen. Efficient benchmarking (of language models). InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), page...
-
[23]
Weak-to-strong generalization: Eliciting strong capabilities with weak supervision
Collin Burns, Pavel Izmailov, Jan Hendrik Kirchner, Bowen Baker, Leo Gao, Leopold Aschen- brenner, Yining Chen, Adrien Ecoffet, Manas Joglekar, Jan Leike, Ilya Sutskever, and Jeffrey Wu. Weak-to-strong generalization: Eliciting strong capabilities with weak supervision. In International Conference on Machine Learning (ICML), 2024
work page 2024
-
[24]
Alexander H Liu et al. Ministral 3.arXiv preprint arXiv:2601.08584, 2026
work page internal anchor Pith review arXiv 2026
-
[25]
Available: http://dx.doi.org/10.1038/s41586-025-09422-z
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.Nature, 645:633–638, 2025. doi: 10.1038/s41586-025-09422-z
-
[26]
Bradley Efron and Robert J Tibshirani.An introduction to the bootstrap, volume
Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA: Measuring how models mimic human falsehoods. InProceedings of the 60th Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers), pages 3214–3252, Dublin, Ireland, 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-long.229
-
[27]
Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jana Thomp- son, Phu Mon Htut, and Samuel R. Bowman. BBQ: A hand-built bias benchmark for ques- tion answering. InFindings of the Association for Computational Linguistics: ACL 2022, pages 2086–2105, Dublin, Ireland, 2022. Association for Computational Linguistics. doi: 10.1865...
-
[28]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations (ICLR), 2021. 11
work page 2021
-
[29]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? Try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, Vancouver, Canada, 2017. Association for Computational Linguistics. do...
-
[31]
SQuAD : 100,000+ questions for machine comprehension of text
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ questions for machine comprehension of text. InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383–2392, Austin, Texas, 2016. Association for Computational Linguistics. doi: 10.18653/v1/D16-1264
-
[32]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mo Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
A generalized solution of the orthogonal Procrustes problem.Psychome- trika, 31(1):1–10, 1966
Peter H Schönemann. A generalized solution of the orthogonal Procrustes problem.Psychome- trika, 31(1):1–10, 1966
work page 1966
-
[34]
John C Gower and Garmt B Dijksterhuis.Procrustes Problems. Oxford University Press, 2004
work page 2004
-
[35]
Kawin Ethayarajh. How contextual are contextualized word representations? Comparing the geometry of BERT, ELMo, and GPT-2 embeddings. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2019. 12 Appendix Table of Contents A Proof of the unified risk bound (Theorem 1) 13 A.1 Relation to classical Procrustes sha...
-
[36]
Larger1− ¯Ω= larger headroom under condition (i). • Relative trace effect ∆|∆R|/|∆R|0 := (|∆R|trace − |∆R|λ=0)/|∆R|λ=0: across-benchmark mean of the trace-vs-no-reg relative change in empirical forgetting at λ=1.0 (negative = trace helps; positive=trace hurts). Three of four settings match the gating prediction directly: trace produces the largest benefit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.