Recognition: 2 theorem links
· Lean TheoremGraphFlash: Enabling Fast and Elastic Graph Processing on Serverless Infrastructure
Pith reviewed 2026-05-13 01:14 UTC · model grok-4.3
The pith
GraphFlash makes serverless graph processing up to 127 times faster than prior systems while cutting resource use by 98 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
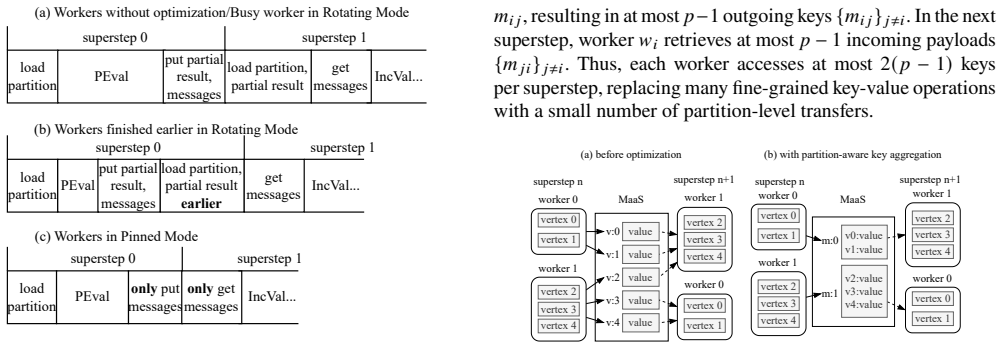
GraphFlash adopts a subgraph-centric programming model and leverages shared external storage for coordination and communication, enabling stateless, fine-grained function execution. It supports two execution modes: rotating mode for resource-constrained environments and pinned mode for higher performance when resources are sufficient. To address serverless limitations, GraphFlash introduces system-level optimizations, including partition-aware key aggregation, intra-function partition co-location, and superstep-aware activation.
What carries the argument
The subgraph-centric model paired with shared external storage, executed through rotating or pinned modes and supported by partition-aware key aggregation, intra-function partition co-location, and superstep-aware activation.
If this is right
- Graph processing workloads can scale elastically without manual cluster provisioning.
- Execution time can drop by up to 127 times relative to earlier serverless graph systems.
- Resource consumption can fall by up to 98 percent when higher-resource configurations are used.
- Performance on large graphs can match that of traditional distributed frameworks.
- Cost can decrease by up to 99.97 percent under resource-limited conditions.
Where Pith is reading between the lines
- The approach may generalize to other iterative cloud workloads that suffer from communication bottlenecks.
- Organizations could shift graph analytics to serverless platforms for variable data sizes without maintaining idle capacity.
- Further reductions in external storage latency would amplify the cost advantages shown here.
Load-bearing premise
The three system-level optimizations can be realized in a real serverless environment without adding latency or overhead that erases the claimed performance and cost gains.
What would settle it
A measurement on live serverless infrastructure showing that the added latency from aggregation, co-location, or activation steps exceeds the reported speedups would falsify the central performance claim.
Figures







read the original abstract
Graph processing systems are essential for analyzing large-scale data with complex relationships, yet most existing frameworks rely on statically provisioned clusters, resulting in poor elasticity and inefficient resource utilization under dynamic workloads. Serverless computing offers automatic scaling and fine-grained billing, but existing serverless graph systems suffer from performance limitations due to inefficient state management and high communication overhead through external storage. We present GraphFlash, a fast and elastic graph processing framework built on serverless infrastructure. GraphFlash adopts a subgraph-centric programming model and leverages shared external storage for coordination and communication, enabling stateless, fine-grained function execution. It supports two execution modes: rotating mode for resource-constrained environments and pinned mode for higher performance when resources are sufficient. To address serverless limitations, GraphFlash introduces system-level optimizations, including partition-aware key aggregation, intra-function partition co-location, and superstep-aware activation. Across multiple graph algorithms and datasets, GraphFlash outperforms existing serverless-compatible systems by up to 127x in execution time and reduces resource consumption by up to 98% under higher-resource configurations, while matching the performance of traditional distributed frameworks on large workloads. Even with limited resources, it achieves up to 48x speedup and 99.97% cost reduction over prior serverless solutions, demonstrating that GraphFlash makes serverless graph processing practical and performant.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GraphFlash, a graph processing framework designed for serverless infrastructure. It uses a subgraph-centric programming model with shared external storage for coordination, supporting rotating and pinned execution modes. Key optimizations include partition-aware key aggregation, intra-function partition co-location, and superstep-aware activation to overcome serverless challenges like stateless functions and high communication costs. The authors report that GraphFlash achieves up to 127x faster execution times and 98% lower resource consumption compared to other serverless systems, matches traditional distributed frameworks on large graphs, and offers up to 48x speedup with 99.97% cost savings under limited resources.
Significance. If the empirical results are validated, this work would be significant for the field of distributed systems and serverless computing by showing that graph processing can be made elastic and cost-effective on serverless platforms without major performance penalties. It provides concrete engineering solutions to common issues in serverless environments and could encourage adoption of serverless for data analytics workloads that currently rely on provisioned clusters.
major comments (2)
- [System Optimizations (likely §4 or §5)] The description of intra-function partition co-location and superstep-aware activation does not explain how these are achieved in practice on commercial serverless platforms, where function scheduling is opaque and independent. Since these are central to realizing the claimed speedups of 127x and 48x, the manuscript should include measurements of any coordination overhead or evidence that they can be enforced without additional latency.
- [Evaluation (§6)] The quantitative performance claims are presented without sufficient details on the experimental methodology, such as the specific serverless platforms used, baseline implementations, graph dataset characteristics (e.g., number of vertices/edges), number of experimental runs, or error bars. This undermines the ability to assess the reliability of the results and compare them fairly.
minor comments (2)
- [Abstract] The abstract refers to 'multiple graph algorithms and datasets' without naming them; including at least the main ones would improve readability and allow readers to quickly gauge the scope.
- [Introduction or Related Work] Ensure that comparisons to prior serverless graph systems are clearly differentiated, perhaps with a table summarizing key differences in approach and reported performance.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable feedback on our manuscript. We have addressed each of the major comments by revising the relevant sections to provide greater clarity and additional details. Our point-by-point responses are provided below.
read point-by-point responses
-
Referee: [System Optimizations (likely §4 or §5)] The description of intra-function partition co-location and superstep-aware activation does not explain how these are achieved in practice on commercial serverless platforms, where function scheduling is opaque and independent. Since these are central to realizing the claimed speedups of 127x and 48x, the manuscript should include measurements of any coordination overhead or evidence that they can be enforced without additional latency.
Authors: We appreciate the referee's observation regarding the need for more practical implementation details. The original manuscript indeed provided a high-level description without sufficient elaboration on enforcement in opaque scheduling environments. In the revised manuscript, we have added a detailed explanation in the system optimizations section on how these features are realized using the shared external storage for coordination signals and invocation patterns that promote co-location where possible. Furthermore, we have incorporated measurements of the coordination overhead and latency analysis to demonstrate that these optimizations contribute to the reported speedups without introducing prohibitive additional costs. We believe this strengthens the manuscript's claims. revision: yes
-
Referee: [Evaluation (§6)] The quantitative performance claims are presented without sufficient details on the experimental methodology, such as the specific serverless platforms used, baseline implementations, graph dataset characteristics (e.g., number of vertices/edges), number of experimental runs, or error bars. This undermines the ability to assess the reliability of the results and compare them fairly.
Authors: We agree with this assessment. The evaluation section in the original submission lacked the necessary methodological specifics for full reproducibility and assessment. We have revised Section 6 to include comprehensive details on the commercial serverless platform used in our experiments, the implementation of baselines, the exact characteristics of the graph datasets used (including vertex and edge counts for each), the number of experimental repetitions, and the inclusion of error bars in all performance figures. These revisions should allow for a fairer comparison and validation of the quantitative claims. revision: yes
Circularity Check
No circularity: empirical system description with no derivations or self-referential predictions
full rationale
The paper describes an engineering system (GraphFlash) with optimizations like partition-aware key aggregation, intra-function partition co-location, and superstep-aware activation, evaluated via experiments on multiple algorithms and datasets. Claims of speedups (up to 127x) and cost reductions rest on measured performance comparisons against baselines, not on any equations, fitted parameters, or predictions that reduce to inputs by construction. No self-citations are load-bearing for a derivation chain, and the contribution is self-contained as a practical implementation whose validity is externally falsifiable through reproduction on serverless platforms.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GraphFlash adopts a subgraph-centric programming model and leverages shared external storage for coordination and communication, enabling stateless, fine-grained function execution. It supports two execution modes: rotating mode... pinned mode... partition-aware key aggregation, intra-function partition co-location, and superstep-aware activation.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GraphFlash... outperforms existing serverless-compatible systems by up to 127× in execution time...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
An analysis of the graph processing landscape,
M. E. Coimbra, A. P. Francisco, and L. Veiga, “An analysis of the graph processing landscape,”J. Big Data, vol. 8, no. 1, p. 55, 2021
work page 2021
-
[2]
Ligra: a lightweight graph processing framework for shared memory,
J. Shun and G. E. Blelloch, “Ligra: a lightweight graph processing framework for shared memory,”SIGPLAN Not., vol. 48, no. 8, p. 135–146, Feb. 2013
work page 2013
-
[3]
Ringo: Interactive graph analytics on big-memory machines,
Y. Perez, R. Sosi ˇc, A. Banerjee, R. Puttagunta, M. Raison, P. Shah, and J. Leskovec, “Ringo: Interactive graph analytics on big-memory machines,” inProceedings of the 2015 ACM SIGMOD International Conference on Management of Data, ser. SIGMOD ’15. New York, NY, USA: Association for Computing Machinery, 2015, p. 1105–1110
work page 2015
-
[4]
Graphmat: high performance graph analytics made productive,
N. Sundaram, N. Satish, M. M. A. Patwary, S. R. Dulloor, M. J. Anderson, S. G. Vadlamudi, D. Das, and P. Dubey, “Graphmat: high performance graph analytics made productive,”Proc. VLDB Endow., vol. 8, no. 11, p. 1214–1225, Jul. 2015
work page 2015
-
[5]
Giraph: Large-scale graph processing infrastructure on hadoop,
C. Avery, “Giraph: Large-scale graph processing infrastructure on hadoop,” inProceedings of the Hadoop Summit, Santa Clara, 2011
work page 2011
-
[6]
Apache flink™: Stream and batch processing in a single engine,
P. Carbone, A. Katsifodimos, S. Ewen, V. Markl, S. Haridi, and K. Tzoumas, “Apache flink™: Stream and batch processing in a single engine,”IEEE Data Eng. Bull., vol. 38, no. 4, pp. 28–38, 2015
work page 2015
-
[7]
Spark: cluster computing with working sets,
M. Zaharia, M. Chowdhury, M. J. Franklin, S. Shenker, and I. Stoica, “Spark: cluster computing with working sets,” inProceedings of the 2nd USENIX Conference on Hot Topics in Cloud Computing, ser. HotCloud’10. USA: USENIX Association, 2010, p. 10
work page 2010
-
[8]
Graphscope: a unified engine for big graph processing,
W. Fan, T. He, L. Lai, X. Li, Y. Li, Z. Li, Z. Qian, C. Tian, L. Wang, J. Xu, Y. Yao, Q. Yin, W. Yu, J. Zhou, D. Zhu, and R. Zhu, “Graphscope: a unified engine for big graph processing,”Proc. VLDB Endow., vol. 14, no. 12, p. 2879–2892, Jul. 2021
work page 2021
-
[9]
Gemini: a computation- centric distributed graph processing system,
X. Zhu, W. Chen, W. Zheng, and X. Ma, “Gemini: a computation- centric distributed graph processing system,” inProceedings of the 12th USENIX Conference on Operating Systems Design and Implementation, ser. OSDI’16. USA: USENIX Association, 2016, p. 301–316
work page 2016
-
[10]
The parallel bgl: A generic library for distributed graph computations,
D. Gregor and A. Lumsdaine, “The parallel bgl: A generic library for distributed graph computations,”Parallel Object-Oriented Scientific Computing (POOSC), vol. 2, no. 1, 2005
work page 2005
-
[11]
The combinatorial BLAS: design, implemen- tation, and applications,
A. Buluc ¸ and J. R. Gilbert, “The combinatorial BLAS: design, implemen- tation, and applications,”Int. J. High Perform. Comput. Appl., vol. 25, no. 4, pp. 496–509, 2011
work page 2011
-
[12]
Scaling techniques for massive scale-free graphs in distributed (external) memory,
R. Pearce, M. Gokhale, and N. M. Amato, “Scaling techniques for massive scale-free graphs in distributed (external) memory,” inProceedings of the 2013 IEEE 27th International Symposium on Parallel and Distributed Processing, ser. IPDPS ’13. USA: IEEE Computer Society, 2013, p. 825–836
work page 2013
-
[13]
Graphless: Toward serverless graph processing,
L. Toader, A. Uta, A. Musaafir, and A. Iosup, “Graphless: Toward serverless graph processing,” inProceedings of the 2019 18th Inter- national Symposium on Parallel and Distributed Computing (ISPDC). Amsterdam, Netherlands: IEEE, June 2019, pp. 66–73
work page 2019
-
[14]
Y. Liu, S. Sun, Z. Li, Q. Chen, S. Gao, B. He, C. Li, and M. Guo, “Faas- graph: Enabling scalable, efficient, and cost-effective graph processing with serverless computing,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ser. ASPLOS ’24. New York, NY, USA: Associat...
work page 2024
-
[15]
Serverlessllm: low-latency serverless inference for large language models,
Y. Fu, L. Xue, Y. Huang, A.-O. Brabete, D. Ustiugov, Y. Patel, and L. Mai, “Serverlessllm: low-latency serverless inference for large language models,” inProceedings of the 18th USENIX Conference on Operating Systems Design and Implementation, ser. OSDI’24. USA: USENIX Association, 2024
work page 2024
-
[16]
Cirrus: a serverless framework for end-to-end ml workflows,
J. Carreira, P. Fonseca, A. Tumanov, A. Zhang, and R. Katz, “Cirrus: a serverless framework for end-to-end ml workflows,” inProceedings of the ACM Symposium on Cloud Computing, ser. SoCC ’19. New York, NY, USA: Association for Computing Machinery, 2019, p. 13–24
work page 2019
-
[17]
Pregel: a system for large-scale graph processing,
G. Malewicz, M. H. Austern, A. J. Bik, J. C. Dehnert, I. Horn, N. Leiser, and G. Czajkowski, “Pregel: a system for large-scale graph processing,” inProceedings of the 2010 ACM SIGMOD International Conference on Management of Data, ser. SIGMOD ’10. New York, NY, USA: Association for Computing Machinery, 2010, p. 135–146
work page 2010
-
[18]
One trillion edges: Graph processing at facebook-scale,
A. Ching, S. Edunov, M. Kabiljo, D. Logothetis, and S. Muthukrishnan, “One trillion edges: Graph processing at facebook-scale,”Proc. VLDB Endow., vol. 8, no. 12, pp. 1804–1815, 2015
work page 2015
-
[19]
Graphx: a resilient distributed graph system on spark,
R. S. Xin, J. E. Gonzalez, M. J. Franklin, and I. Stoica, “Graphx: a resilient distributed graph system on spark,” inFirst International Workshop on Graph Data Management Experiences and Systems, ser. GRADES ’13. New York, NY, USA: Association for Computing Machinery, 2013
work page 2013
-
[20]
X-stream: edge-centric graph processing using streaming partitions,
A. Roy, I. Mihailovic, and W. Zwaenepoel, “X-stream: edge-centric graph processing using streaming partitions,” inProceedings of the Twenty- Fourth ACM Symposium on Operating Systems Principles, ser. SOSP ’13. New York, NY, USA: Association for Computing Machinery, 2013, p. 472–488
work page 2013
-
[21]
Chaos: scale- out graph processing from secondary storage,
A. Roy, L. Bindschaedler, J. Malicevic, and W. Zwaenepoel, “Chaos: scale- out graph processing from secondary storage,” inProceedings of the 25th Symposium on Operating Systems Principles, ser. SOSP ’15. New York, NY, USA: Association for Computing Machinery, 2015, p. 410–424
work page 2015
-
[22]
Pk-graph: Partitioned k2-trees to enable compact and dynamic graphs in sparkgraphx,
B. Morais, M. E. Coimbra, and L. Veiga, “Pk-graph: Partitioned k2-trees to enable compact and dynamic graphs in sparkgraphx,” inCooperative In- formation Systems: 28th International Conference, CoopIS 2022, Bozen- Bolzano, Italy, October 4–7, 2022, Proceedings. Berlin, Heidelberg: Springer-Verlag, 2022, p. 149–167
work page 2022
-
[23]
Parallelizing sequential graph computations,
W. Fan, W. Yu, J. Xu, J. Zhou, X. Luo, Q. Yin, P. Lu, Y. Cao, and R. Xu, “Parallelizing sequential graph computations,”ACM Trans. Database Syst., vol. 43, no. 4, Dec. 2018
work page 2018
-
[24]
Starling: A scalable query engine on cloud functions,
M. Perron, R. Castro Fernandez, D. DeWitt, and S. Madden, “Starling: A scalable query engine on cloud functions,” inProceedings of the 2020 ACM SIGMOD International Conference on Management of Data, ser. SIGMOD ’20. New York, NY, USA: Association for Computing Machinery, 2020, p. 131–141
work page 2020
-
[25]
Lambada: Interactive data ana- lytics on cold data using serverless cloud infrastructure,
I. M¨ uller, R. Marroqu´ın, and G. Alonso, “Lambada: Interactive data ana- lytics on cold data using serverless cloud infrastructure,” inProceedings of the 2020 ACM SIGMOD International Conference on Management of Data, ser. SIGMOD ’20. New York, NY, USA: Association for Computing Machinery, 2020, p. 115–130
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.