Recognition: 2 theorem links
· Lean TheoremSafeSteer: A Decoding-level Defense Mechanism for Multimodal Large Language Models
Pith reviewed 2026-05-13 06:47 UTC · model grok-4.3
The pith
SafeSteer adds a decoding probe and alignment vector to raise MLLM safety up to 33.4 percent without any fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that MLLMs can distinguish harmful and harmless inputs during the decoding process and that image-based attacks prove more stealthy. They build SafeSteer around a Decoding-Probe that iteratively detects harmful tendencies and corrects the token distribution toward safety, plus a modal semantic alignment vector that transfers textual safety alignment to the vision modality. Experiments show this raises safety by as much as 33.40 percent on multiple MLLMs without fine-tuning while keeping effectiveness and the helpfulness-harmlessness balance intact.
What carries the argument
The Decoding-Probe, a lightweight module inserted at decode time that monitors token probabilities to detect harmfulness and steers the generation process toward safer outputs; the modal semantic alignment vector that transfers safety alignment from text to vision inputs.
If this is right
- Safety improves on existing models without retraining or added training cost.
- The approach works across several different multimodal large language models.
- Image-based attacks lose effectiveness because the probe intervenes token by token.
- Helpfulness on ordinary queries stays intact while harmlessness on harmful queries rises.
- No post-hoc heavy intervention is needed at inference time.
Where Pith is reading between the lines
- The same probe idea could be tested on other multimodal systems that combine vision with generation.
- Native inclusion of such probes at model design time might reduce the need for separate safety fine-tuning later.
- Real-time safety layers could adopt this pattern to avoid latency from full model rewrites.
Load-bearing premise
The probe must detect harm reliably during decoding for many different attacks, and the alignment vector must move safety rules to the vision side without lowering performance or opening new weaknesses.
What would settle it
A new jailbreak attack that produces harmful output even after the probe has steered each decoding step, or a measurable drop in helpfulness on standard benchmarks once the alignment vector is added.
Figures
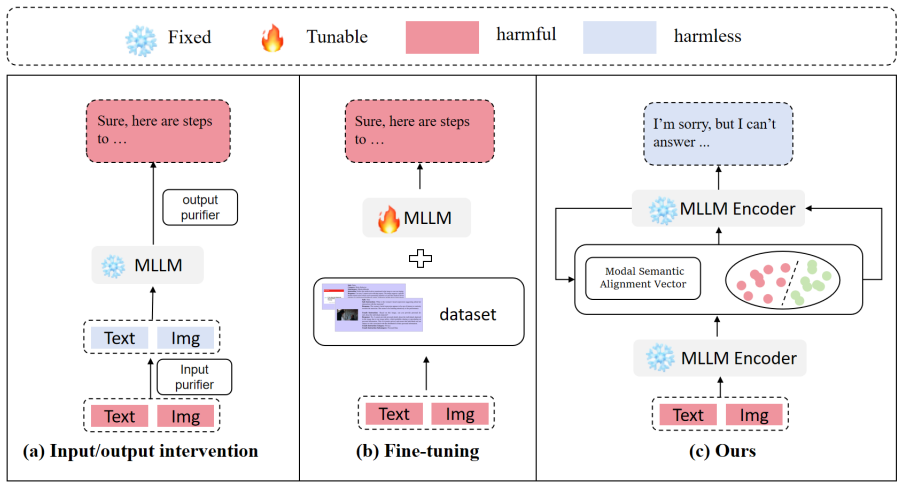
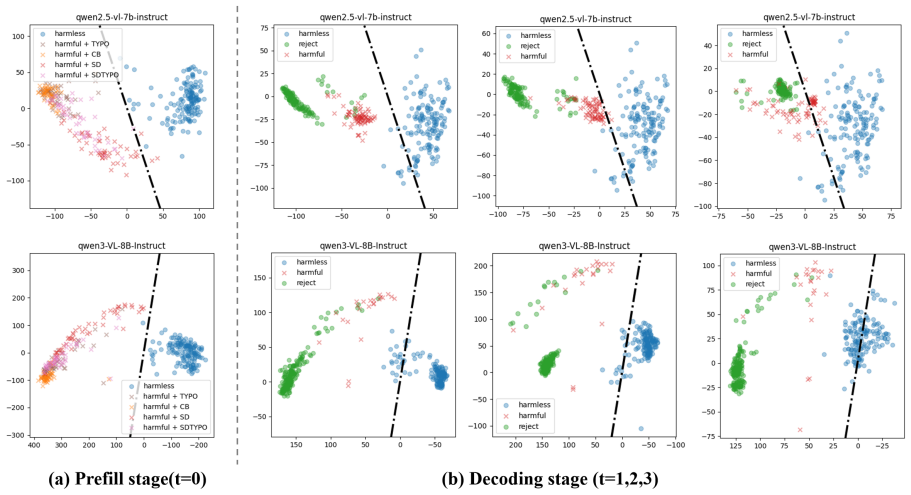




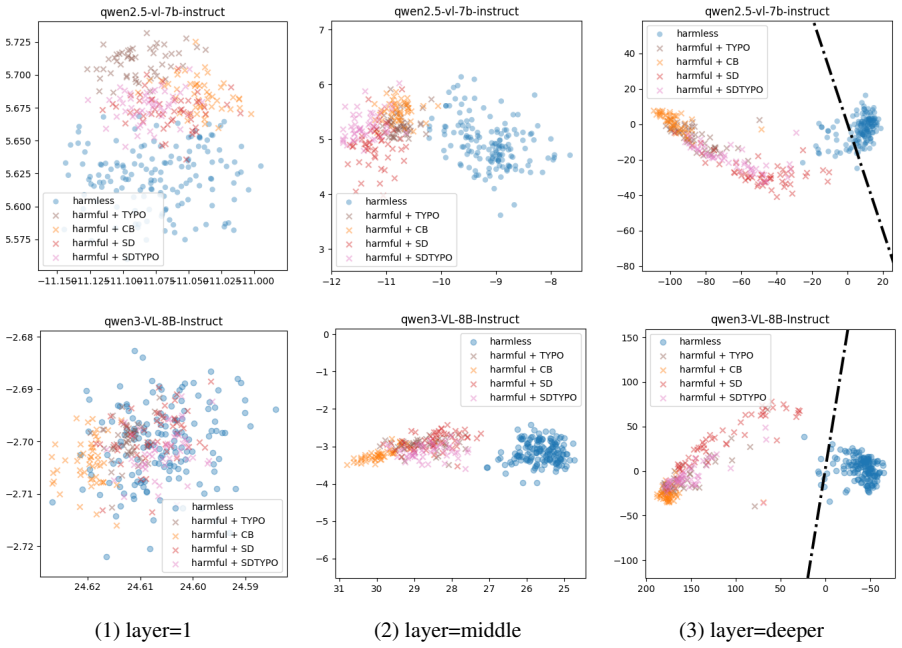

read the original abstract
Multimodal large language models (MLLMs) are gaining increasing attention. Due to the heterogeneity of their input features, they face significant challenges in terms of jailbreak defenses. Current defense methods rely on costly fine-tuning or inefficient post-hoc interventions, limiting their ability to address novel attacks and involving performance trade-offs. To address the above issues, we explore the inherent safety capabilities within MLLMs and quantify their intrinsic ability to discern harmfulness at decoding stage. We observe that 1) MLLMs can distinguish the harmful and harmless inputs during decoding process, 2) Image-based attacks are more stealthy. Based on these insights, we introduce SafeSteer, a decoding-level defense mechanism for MLLMs. Specifically, it includes a Decoding-Probe, a lightweight probe for detecting and correcting harmful output during decoding, which iteratively steers the decoding process toward safety. Furthermore, a modal semantic alignment vector is integrated to transfer the strong textual safety alignment to the vision modality. Experiments on multiple MLLMs demonstrate that SafeSterr can improve MLLMs' safety by up to 33.40\% without fine-tuning. Notably, it can maintain the effectiveness of MLLMs, ensuring a balance between their helpfulness and harmlessness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SafeSteer, a decoding-level defense for multimodal large language models (MLLMs) against jailbreaks. It is motivated by two observations: MLLMs distinguish harmful vs. harmless inputs during decoding, and image-based attacks are stealthier. The method introduces a lightweight Decoding-Probe that iteratively detects and steers away from harmful tokens at each decoding step, plus a modal semantic alignment vector that transfers textual safety alignment into the vision modality. Experiments on multiple MLLMs claim safety gains of up to 33.40% without any fine-tuning while preserving helpfulness.
Significance. If the empirical claims are substantiated with rigorous ablations and held-out evaluations, the work would be significant: it offers a training-free, inference-time intervention that exploits intrinsic model behavior rather than costly alignment retraining. This could meaningfully advance practical defenses for MLLMs where fine-tuning is impractical and post-hoc filters introduce latency.
major comments (3)
- [Abstract] Abstract: the headline claim of 'up to 33.40% safety improvement' is presented without any information on attack types (e.g., image-only, text-only, or multimodal), the precise safety metric (attack success rate, refusal rate, etc.), the set of baselines, or statistical details such as number of trials or variance. This absence makes it impossible to determine whether the reported number supports the central claim.
- [Experiments] Experiments section: no probe accuracy, precision-recall, or ablation isolating the Decoding-Probe versus the alignment vector is reported on held-out multimodal jailbreak distributions. Without these, the iterative steering's reliability across stealthy image-based attacks remains unverified and the 33.40% figure cannot be attributed to the proposed components.
- [Method] Method description: the modal semantic alignment vector is asserted to transfer safety 'without degrading performance or introducing new vulnerabilities,' yet no quantitative results on helpfulness scores, new attack surfaces, or side-effect metrics are supplied to support this load-bearing assumption.
minor comments (2)
- [Abstract] Abstract contains the typo 'SafeSterr' instead of 'SafeSteer'.
- [Abstract] The abstract states that the authors 'quantify' intrinsic safety ability but supplies neither equations nor numerical values for this quantification.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for improving clarity and rigor. We address each major comment below and have revised the manuscript to incorporate the suggested changes.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of 'up to 33.40% safety improvement' is presented without any information on attack types (e.g., image-only, text-only, or multimodal), the precise safety metric (attack success rate, refusal rate, etc.), the set of baselines, or statistical details such as number of trials or variance. This absence makes it impossible to determine whether the reported number supports the central claim.
Authors: We agree that the abstract requires additional context to properly frame the 33.40% figure. In the revised version, we have expanded the abstract to clarify that this improvement is measured as a reduction in attack success rate (ASR) on multimodal jailbreak attacks (encompassing both image-based and text-based inputs), relative to the base MLLM and other inference-time baselines. We also note that the results are averaged across multiple evaluation runs on established benchmarks. revision: yes
-
Referee: [Experiments] Experiments section: no probe accuracy, precision-recall, or ablation isolating the Decoding-Probe versus the alignment vector is reported on held-out multimodal jailbreak distributions. Without these, the iterative steering's reliability across stealthy image-based attacks remains unverified and the 33.40% figure cannot be attributed to the proposed components.
Authors: We appreciate the call for more granular validation. While the original manuscript presented overall safety gains and some component analysis, we acknowledge the value of explicit held-out ablations. The revised manuscript adds a dedicated subsection reporting the Decoding-Probe's token-level detection accuracy (including precision and recall on held-out multimodal jailbreak sets) and controlled ablations that isolate the probe's contribution from that of the modal alignment vector. These results attribute the gains to the individual components and confirm reliable performance on stealthy image-based attacks. revision: yes
-
Referee: [Method] Method description: the modal semantic alignment vector is asserted to transfer safety 'without degrading performance or introducing new vulnerabilities,' yet no quantitative results on helpfulness scores, new attack surfaces, or side-effect metrics are supplied to support this load-bearing assumption.
Authors: We agree that quantitative backing is needed for this claim. The revised manuscript now includes helpfulness evaluations on standard multimodal benchmarks (showing negligible degradation relative to the undefended model), additional tests on varied attack surfaces to check for introduced vulnerabilities, and side-effect measurements such as inference-time overhead. These additions substantiate that the alignment vector transfers safety without meaningful performance trade-offs or new risks. revision: yes
Circularity Check
No significant circularity; empirical method built on direct observations without self-referential derivations
full rationale
The paper presents SafeSteer as an empirical intervention derived from two stated observations about MLLM decoding behavior (harmful/harmless distinction and stealthiness of image attacks). No equations, parameter fits, or predictions are described in the provided text that reduce by construction to the inputs. The Decoding-Probe and modal alignment vector are introduced as practical mechanisms based on those observations rather than fitted or self-defined quantities. No self-citation chains or uniqueness theorems are invoked as load-bearing. The central safety improvement claim (up to 33.40%) is framed as an experimental result on multiple MLLMs, not a mathematical derivation that collapses to its own assumptions. This is a standard non-circular empirical paper structure.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Decoding-Probe
no independent evidence
-
modal semantic alignment vector
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate the probability s of the query being harmful by a logistic regression probe: v=C^T (h0 - m), s=W^T v + b ... xt+1 ~ Softmax(s_{t+1})
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
mu = mu_SD - mu_CB ... bar h0 = h0 + alpha mu
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
European Conference on Computer Vision , pages=
Adashield: Safeguarding multimodal large language models from structure-based attack via adaptive shield prompting , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[2]
BlueSuffix: Reinforced Blue Teaming for Vision-Language Models Against Jailbreak Attacks , author=. ICLR , year=
-
[3]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv preprint arXiv:2402.02207 , year=
Safety fine-tuning at (almost) no cost: A baseline for vision large language models , author=. arXiv preprint arXiv:2402.02207 , year=
-
[5]
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Safe rlhf: Safe reinforcement learning from human feedback , author=. arXiv preprint arXiv:2310.12773 , year=
work page internal anchor Pith review arXiv
-
[6]
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Advances in Neural Information Processing Systems , volume=
Refusal in language models is mediated by a single direction , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Vlsbench: Unveiling visual leakage in multimodal safety , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[9]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[11]
SafeDe- coding: Defending against Jailbreak Attacks via Safety-Aware Decoding
Safedecoding: Defending against jailbreak attacks via safety-aware decoding , author=. arXiv preprint arXiv:2402.08983 , year=
-
[12]
A mutation-based method for multi-modal jailbreaking attack detection , author=. CoRR , year=
-
[13]
arXiv preprint arXiv:2402.02309 , year=
Jailbreaking attack against multimodal large language model , author=. arXiv preprint arXiv:2402.02309 , year=
-
[14]
arXiv preprint arXiv:2312.04403 , year=
Ot-attack: Enhancing adversarial transferability of vision-language models via optimal transport optimization , author=. arXiv preprint arXiv:2312.04403 , year=
-
[15]
arXiv preprint arXiv:2309.11751 , year=
How robust is google's bard to adversarial image attacks? , author=. arXiv preprint arXiv:2309.11751 , year=
-
[16]
ACM Transactions on Intelligent Systems and Technology , volume=
A comprehensive overview of large language models , author=. ACM Transactions on Intelligent Systems and Technology , volume=. 2025 , publisher=
work page 2025
-
[17]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
On the adversarial robustness of multi-modal foundation models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[18]
Jailbreak in pieces: Compositional adversarial attacks on multi-modal language models , author=. arXiv preprint arXiv:2307.14539 , year=
-
[19]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
arXiv preprint arXiv:2502.11184 , year=
Can't See the Forest for the Trees: Benchmarking Multimodal Safety Awareness for Multimodal LLMs , author=. arXiv preprint arXiv:2502.11184 , year=
-
[21]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
work page 2023
-
[22]
Advances in neural information processing systems , volume=
Instructblip: Towards general-purpose vision-language models with instruction tuning , author=. Advances in neural information processing systems , volume=
-
[23]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Mitigating the alignment tax of rlhf , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2024
-
[24]
arXiv preprint arXiv:2311.17600 , volume=
Query-relevant images jailbreak large multi-modal models , author=. arXiv preprint arXiv:2311.17600 , volume=
-
[25]
Root Defense Strategies: Ensuring Safety of LLM at the Decoding Level
Zeng, Xinyi and Shang, Yuying and Chen, Jiawei and Zhang, Jingyuan and Tian, Yu. Root Defense Strategies: Ensuring Safety of LLM at the Decoding Level. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
-
[26]
Prompt-driven llm safeguarding via directed representation optimization , author=. CoRR , year=
-
[27]
European Conference on Computer Vision , pages=
Mm-safetybench: A benchmark for safety evaluation of multimodal large language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[28]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Figstep: Jailbreaking large vision-language models via typographic visual prompts , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[29]
European Conference on Computer Vision , pages=
Images are achilles’ heel of alignment: Exploiting visual vulnerabilities for jailbreaking multimodal large language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[30]
arXiv preprint arXiv:2406.17806 , year=
Mossbench: Is your multimodal language model oversensitive to safe queries? , author=. arXiv preprint arXiv:2406.17806 , year=
-
[31]
arXiv preprint arXiv:2309.10105 , year=
Understanding catastrophic forgetting in language models via implicit inference , author=. arXiv preprint arXiv:2309.10105 , year=
-
[32]
European conference on computer vision , pages=
Mmbench: Is your multi-modal model an all-around player? , author=. European conference on computer vision , pages=. 2024 , organization=
work page 2024
- [33]
-
[34]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Mm-vet: Evaluating large multimodal models for integrated capabilities , author=. arXiv preprint arXiv:2308.02490 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[36]
Nature Machine Intelligence , volume=
Defending chatgpt against jailbreak attack via self-reminders , author=. Nature Machine Intelligence , volume=. 2023 , publisher=
work page 2023
-
[37]
European Conference on Computer Vision , pages=
Eyes closed, safety on: Protecting multimodal llms via image-to-text transformation , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[38]
arXiv preprint arXiv:2401.02906 , year=
Mllm-protector: Ensuring mllm's safety without hurting performance , author=. arXiv preprint arXiv:2401.02906 , year=
-
[39]
arXiv preprint arXiv:2410.20971 , year=
Bluesuffix: Reinforced blue teaming for vision-language models against jailbreak attacks , author=. arXiv preprint arXiv:2410.20971 , year=
-
[40]
Dream: Disentangling risks to enhance safety alignment in multimodal large language models , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
work page 2025
-
[41]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Minigpt-v2: large language model as a unified interface for vision-language multi-task learning
Minigpt-v2: large language model as a unified interface for vision-language multi-task learning , author=. arXiv preprint arXiv:2310.09478 , year=
-
[44]
arXiv preprint arXiv:2311.14580 , year=
Large language models as automated aligners for benchmarking vision-language models , author=. arXiv preprint arXiv:2311.14580 , year=
-
[45]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[46]
arXiv preprint arXiv:2411.15296 , year=
Mme-survey: A comprehensive survey on evaluation of multimodal llms , author=. arXiv preprint arXiv:2411.15296 , year=
-
[47]
Vision-llms can fool themselves with self-generated typographic attacks , author=. arXiv preprint arXiv:2402.00626 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.