Recognition: no theorem link
Position: LLM Inference Should Be Evaluated as Energy-to-Token Production
Pith reviewed 2026-05-13 05:13 UTC · model grok-4.3
The pith
LLM inference should be treated as energy-to-token production bounded by both compute and power ceilings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
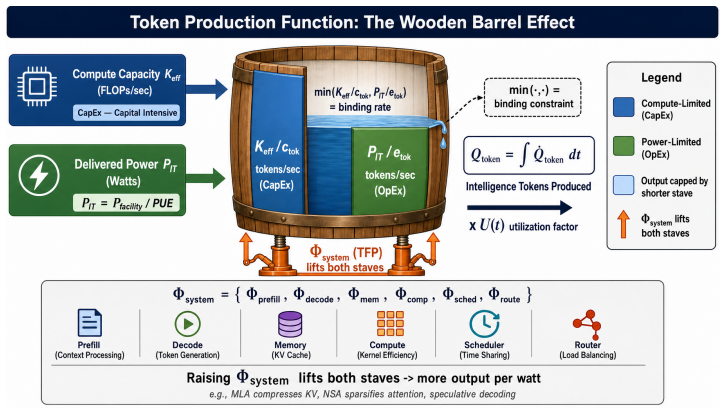
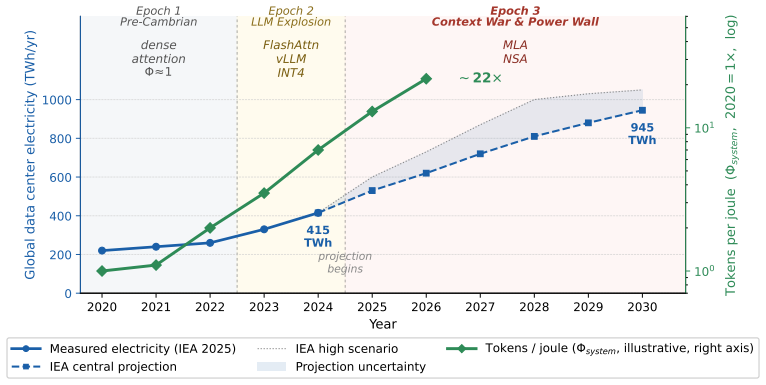
LLM inference should be evaluated as energy-to-token production. The authors formalize this view with a dimensionally consistent Token Production Function in which token rate is bounded by both compute-per-token and energy-per-token ceilings. At deployment scale the relevant output is a quality-conditioned token produced under joint constraints from effective compute, delivered data-center power, cooling capacity, PUE, and utilization. System optimizations are reframed as energy-to-token levers because they reduce FLOPs/token, joules/token, memory traffic, or utilization losses under fixed quality and service targets.
What carries the argument
The Token Production Function, a dimensionally consistent model that bounds token production rate by ceilings on both compute per token and energy per token.
If this is right
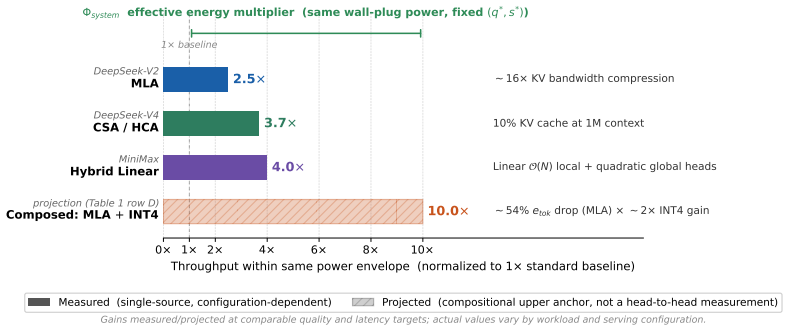
- Optimizations such as KV-cache compression, quantization, and sparse attention reduce joules per token or utilization losses under fixed quality and service targets.
- Inference papers and benchmarks must report Joules/token, the active binding constraint, PUE-adjusted delivered power, and utilization-adjusted token output.
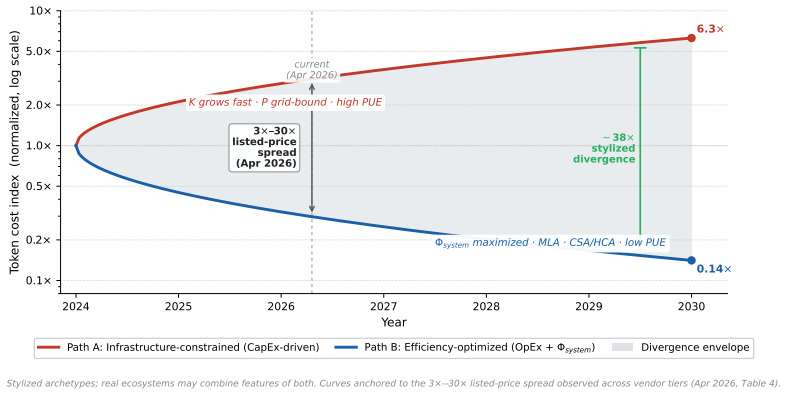
- API price dispersion across providers may reflect differences in underlying energy costs, though this serves only as directional motivation.
- The binding constraint shifts from theoretical peak compute to delivered power and operational efficiency when scale increases.
Where Pith is reading between the lines
- Hardware roadmaps could shift priority toward maximizing sustained power delivery efficiency rather than peak FLOPS.
- Model architectures might be co-designed specifically to minimize energy per token at inference time rather than training FLOPs alone.
- Data-center planning could incorporate renewable-energy matching directly into inference workload scheduling.
- Evaluation suites could add simulated power and cooling caps to test whether claimed throughputs hold under realistic constraints.
Load-bearing premise
That at deployment scale the binding constraint on LLM inference moves from theoretical peak compute toward delivered power, cooling capacity, PUE, and operational efficiency.
What would settle it
An observation that even in large-scale deployments the primary limit on high-quality token output remains available FLOPS rather than delivered power or energy delivery.
Figures
read the original abstract
LLM inference is still evaluated mainly as a model or software problem: accuracy, latency, throughput, and hardware utilization. This is incomplete. At deployment scale, the relevant output is a quality-conditioned token produced under joint constraints from effective compute, delivered data-center power, cooling capacity, PUE, and utilization. We argue that the ML community should treat inference as \emph{energy-to-token production}. We formalize this view with a dimensionally consistent Token Production Function in which token rate is bounded by both compute-per-token and energy-per-token ceilings. Listed API prices vary by over an order of magnitude across providers, but we use price dispersion only as directional motivation, not as causal evidence of marginal cost. The core physical question is instead: under fixed quality and service targets, when does the binding constraint move from theoretical peak compute toward delivered power, cooling, and operational efficiency? Under this framing, system optimizations -- latent KV-cache compression, sparse or heavily compressed attention, quantization, routing, and difficulty-adaptive reasoning -- are not merely local engineering tricks. They are energy-to-token levers because they reduce FLOPs/token, joules/token, memory traffic, or utilization losses under fixed $(q^{*},s^{*})$. We therefore call for inference papers and benchmarks to report Joules/token, active binding constraint, PUE-adjusted delivered power, and utilization-adjusted token output alongside accuracy and latency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that LLM inference should be evaluated as energy-to-token production rather than primarily through model accuracy, latency, and hardware utilization metrics. It proposes a dimensionally consistent Token Production Function that bounds token production rates by both compute and energy constraints. The authors emphasize that at large deployment scales, factors such as delivered power, cooling capacity, PUE, and utilization become critical, and advocate for new reporting standards in inference papers and benchmarks, including Joules/token and active binding constraints.
Significance. If the central premise holds—that energy and power constraints become the binding limits on LLM inference at deployment scale—this position could substantially influence the ML community by redirecting optimization efforts and benchmarking practices toward energy efficiency and sustainable computing. It highlights the need to consider operational data center realities in model evaluation, potentially leading to more holistic system designs.
major comments (1)
- The premise that the binding constraint on token production shifts from theoretical peak compute to delivered power, cooling, PUE, and operational efficiency at deployment scale lacks supporting measurements, utilization data, power traces, or scaling analysis from real deployments. This assumption is load-bearing for the justification of treating inference as energy-to-token production and reorienting benchmarks accordingly.
minor comments (1)
- The Token Production Function is described as dimensionally consistent but no explicit mathematical formulation, equations, or derivation is provided, making it difficult to assess its novelty or applicability.
Simulated Author's Rebuttal
We thank the referee for their constructive review and the opportunity to respond. We address the single major comment below.
read point-by-point responses
-
Referee: The premise that the binding constraint on token production shifts from theoretical peak compute to delivered power, cooling, PUE, and operational efficiency at deployment scale lacks supporting measurements, utilization data, power traces, or scaling analysis from real deployments. This assumption is load-bearing for the justification of treating inference as energy-to-token production and reorienting benchmarks accordingly.
Authors: We agree that the manuscript does not contain new empirical measurements, power traces, or utilization data from production deployments. As a position paper, the central contribution is the dimensionally consistent Token Production Function together with the recommendation to report Joules/token and active binding constraints; the premise that power and cooling become binding at scale is presented as a physically motivated hypothesis rather than a claim proven by new data. The text already qualifies API price dispersion as directional motivation only and does not assert causal evidence of marginal cost. We will make a partial revision by inserting a short paragraph that (a) explicitly labels the constraint-shift claim as a hypothesis grounded in known data-center characteristics (PUE > 1, finite rack power delivery, cooling limits) and (b) calls for future empirical studies to measure when and at what scale the binding constraint moves. This addition will clarify the evidential scope without altering the proposed evaluation framework. revision: partial
- We cannot supply proprietary power traces, utilization statistics, or scaling measurements from commercial LLM deployments, as such operational data are not publicly available and we have no access to them.
Circularity Check
Conceptual position paper with no derivation chain or self-referential reductions
full rationale
The manuscript is a position paper that advocates reframing LLM inference evaluation around energy-to-token production and introduces a Token Production Function as a dimensional formalization. No equations, parameter fits, or step-by-step derivations appear in the provided text. The authors explicitly disclaim price dispersion as causal evidence and pose the binding-constraint question as open rather than solved by internal construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing premises. The argument therefore contains no steps that reduce by construction to their own inputs; it remains a self-contained conceptual proposal whose validity rests on external physical and operational data rather than circular redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption At deployment scale, the binding constraint on LLM inference shifts from peak compute to delivered power, cooling, and operational efficiency.
Reference graph
Works this paper leans on
-
[1]
International Energy Agency. Energy and ai. Technical report, IEA Special Report, 2025. URL https://www.iea.org/reports/energy-and-ai
work page 2025
-
[2]
Analyzing artificial intelligence and data center energy consumption
Electric Power Research Institute. Analyzing artificial intelligence and data center energy consumption. Technical Report 3002028905, EPRI, 2024. URL https://www.epri.com/r esearch/products/3002028905. EPRI White Paper No. 3002028905
-
[3]
NVIDIA. Ai factories. NVIDIA solutions page, 2026. URL https://www.nvidia.com/e n-us/solutions/ai-factories/
work page 2026
-
[4]
NVIDIA. Ai inference. NVIDIA solutions page, 2026. URL https://www.nvidia.com/e n-us/solutions/ai/inference/
work page 2026
-
[5]
OpenAI. Api pricing. OpenAI documentation, 2026. URL https://openai.com/api/pri cing/
work page 2026
-
[6]
Models overview and api pricing
Anthropic. Models overview and api pricing. Anthropic documentation, 2026. URL https: //docs.anthropic.com/en/docs/models-overview
work page 2026
-
[7]
DeepSeek. Models and pricing. DeepSeek API documentation, 2026. URL https://api-d ocs.deepseek.com/quick_start/pricing
work page 2026
-
[8]
R. Schwartz, J. Dodge, N. A. Smith, and O. Etzioni. Green ai.Communications of the ACM, 63 (12):54–63, 2020. doi: 10.1145/3381831. URLhttps://doi.org/10.1145/3381831
-
[9]
D. Patterson, J. Gonzalez, Q. Le, C. Liang, L. M. Munguia, D. Rothchild, J. Dean, et al. Carbon emissions and large neural network training, 2021. URL https://arxiv.org/abs/2104.1
work page 2021
-
[10]
arXiv preprint arXiv:2104.10350
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
D. Patterson, J. Gonzalez, U. Hölzle, Q. Le, C. Liang, L.-M. Munguia, J. Dean, et al. The carbon footprint of machine learning training will plateau, then shrink.Computer, 55(7):18–28, 2022. doi: 10.1109/MC.2022.3148714. URLhttps://doi.org/10.1109/MC.2022.3148714
-
[12]
C. J. Wu, R. Raghavendra, U. Gupta, B. Acun, N. Ardalani, K. Maeng, K. Hazelwood, et al. Sustainable ai: Environmental implications, challenges and opportunities. InProceedings of Machine Learning and Systems (MLSys), volume 4, pages 795–813, 2022. URL https: //arxiv.org/abs/2111.00364
-
[13]
Quantifying the Carbon Emissions of Machine Learning
A. Lacoste, A. Luccioni, V . Schmidt, and T. Dandres. Quantifying the carbon emissions of machine learning, 2019. URL https://arxiv.org/abs/1910.09700 . arXiv preprint arXiv:1910.09700
work page internal anchor Pith review arXiv 2019
-
[14]
In: Korhonen, A., Traum, D., Màrquez, L
E. Strubell, A. Ganesh, and A. McCallum. Energy and policy considerations for deep learning in nlp. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), pages 3645–3650, 2019. URLhttps://arxiv.org/abs/1906.02243
work page Pith review arXiv 2019
-
[15]
A. S. Luccioni, Y . Jernite, and E. Strubell. Power hungry processing: Watts driving the cost of ai deployment? InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency (F AccT), 2024. doi: 10.1145/3630106.3658542. URL h t t p s : //doi.org/10.1145/3630106.3658542
-
[16]
Mlperf inference v4.1 power results
MLCommons. Mlperf inference v4.1 power results. Technical report, MLCommons, 2024. URL https://mlcommons.org/benchmarks/inference-datacenter/ . MLCommons Technical Report. 10
work page 2024
-
[17]
W. W. Leontief.The Structure of American Economy, 1919–1929: An Empirical Application of Equilibrium Analysis. Harvard University Press, 1941
work page 1919
-
[18]
K. J. Arrow, H. B. Chenery, B. S. Minhas, and R. M. Solow. Capital-labor substitution and economic efficiency.The Review of Economics and Statistics, 43(3):225–250, 1961. doi: 10.2307/1927286. URLhttps://doi.org/10.2307/1927286
-
[19]
2024 global data center survey results
Uptime Institute. 2024 global data center survey results. Technical report, Uptime Institute,
work page 2024
-
[20]
Global average PUE: 1.56; industry leaders: 1.08–1.09
- [21]
- [22]
-
[23]
R. M. Solow. Technical change and the aggregate production function.Review of Economics and Statistics, 39(3):312–320, 1957. doi: 10.2307/1926047. URL https://doi.org/10.2 307/1926047
-
[24]
Roofline: An insightful visual performance model for multicore architectures,
S. Williams, A. Waterman, and D. Patterson. Roofline: An insightful visual performance model for multicore architectures.Communications of the ACM, 52(4):65–76, 2009. doi: 10.1145/1498765.1498785. URLhttps://doi.org/10.1145/1498765.1498785
-
[25]
J. Sevilla and E. Roldán. Training compute of frontier ai models grows by 4-5x per year. Epoch AI Blog, 2024. URL https://epochai.org/blog/training-compute-of-frontier-a i-models-grows-by-4-5x-per-year
work page 2024
- [26]
-
[27]
J. Delavande, R. Pierrard, and S. Luccioni. Understanding efficiency: Quantization, batching, and serving strategies in llm energy use, 2026. URL https://arxiv.org/abs/2601.22362. arXiv preprint arXiv:2601.22362
-
[28]
H. P. Cavagna, A. Proia, G. Madella, G. B. Esposito, F. Antici, D. Cesarini, Z. Kiziltan, and A. Bartolini. Sweetspot: An analytical model for predicting energy efficiency of llm inference,
-
[29]
SweetSpot: An Analytical Model for Predicting Energy Efficiency of LLM Inference
URLhttps://arxiv.org/abs/2602.05695. arXiv preprint arXiv:2602.05695
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Nvidia h100 tensor core gpu: Product specifications
NVIDIA. Nvidia h100 tensor core gpu: Product specifications. NVIDIA product page, 2026. URLhttps://www.nvidia.com/en-us/data-center/h100/
work page 2026
-
[31]
Nvidia hgx platform specifications (hgx h100 4/8-gpu)
NVIDIA. Nvidia hgx platform specifications (hgx h100 4/8-gpu). NVIDIA product page, 2026. URLhttps://www.nvidia.com/en-us/data-center/hgx
work page 2026
-
[32]
International Energy Agency. Ai is set to drive surging electricity demand from data centres while offering the potential to transform how the energy sector works. IEA News, 2025. URL https://www.iea.org/news/ai-is-set-to-drive-surging-electricity-deman d-from-data-centres-while-offering-the-potential-to-transform-how-the -energy-sector-works
work page 2025
-
[33]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-AI. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. Technical report, DeepSeek-AI, 2024. URL https://arxiv.org/abs/2405.04434. arXiv:2405.04434
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, D. Amodei, et al. Scaling laws for neural language models, 2020. URLhttps://arxiv.org/abs/2001.08361. arXiv preprint arXiv:2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[35]
Training Compute-Optimal Large Language Models
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, L. Sifre, et al. Training compute-optimal large language models, 2022. URL https://arxiv.org/abs/22 03.15556. arXiv preprint arXiv:2203.15556. 11
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
J. W. Rae, S. Borgeaud, T. Cai, K. Millican, J. Hoffmann, F. Song, G. Irving, et al. Scaling language models: Methods, analysis and insights from training gopher, 2021. URL https: //arxiv.org/abs/2112.11446. arXiv preprint arXiv:2112.11446
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[37]
J. Sevilla, L. Heim, A. Ho, T. Besiroglu, M. Hobbhahn, and P. Villalobos. Compute trends across three eras of machine learning. In2022 International Joint Conference on Neural Networks (IJCNN), pages 1–8, 2022. URLhttps://arxiv.org/abs/2202.05924
-
[38]
T. Dao, D. Y . Fu, S. Ermon, A. Rudra, and C. Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. InAdvances in Neural Information Processing Systems, volume 35, pages 16344–16359, 2022. URLhttps://arxiv.org/abs/2205.14135
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, I. Stoica, et al. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP), pages 611–626, 2023. URL https: //arxiv.org/abs/2309.06180
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers. InProceedings of the 11th International Conference on Learning Representations, 2023. URLhttps://arxiv.org/abs/2210.17323
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
J. Lin, J. Tang, H. Tang, S. Yang, X. Dang, and S. Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration. InProceedings of Machine Learning and Systems, volume 6, 2024. URLhttps://arxiv.org/abs/2306.00978
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [43]
-
[44]
Xiang Liu, Peijie Dong, Xuming Hu, and Xiaowen Chu. LongGenBench: Long-context generation benchmark. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 865–883. Association for Computational Linguistics, 2024. doi: 10.18653/v1/2024 .findings-emnlp.48. URLhttps://doi.org/10.18653/v1/2024.findings-emnlp.48
-
[45]
U.S. Department of Energy. Doe releases new report evaluating increase in electricity demand from data centers. Technical report, U.S. Department of Energy, 2024. URL https://www.en ergy.gov/articles/doe-releases-new-report-evaluating-increase-electrici ty-demand-data-centers. DOE News
work page 2024
- [46]
-
[47]
URL https://epoch.ai/data- insights/hyperscaler- capex- trend/ . Combined Alphabet, Amazon, Meta, Microsoft, and Oracle capex extracted from SEC EDGAR 10-Q/10-K filings
-
[48]
L. Liu. Speech at the china development forum 2026: Token (“ciyuan”) as the value anchor of the intelligent era; daily token-call volume in china exceeds 140 trillion as of march 2026. National Data Administration of China, 2026. URL https://www.nda.gov.cn/sjj/swdt/ mtsy/0325/20260325113132934906079_pc.html
work page 2026
-
[49]
Doubao surpasses 120 trillion daily tokens as usage doubles in three months
TechNode. Doubao surpasses 120 trillion daily tokens as usage doubles in three months. TechNode, 2026. URL https://technode.com/2026/04/07/doubao-surpasses-120 -trillion-daily-tokens-as-usage-doubles-in-three-months/
work page 2026
-
[50]
W. A. Wulf and S. A. McKee. Hitting the memory wall: Implications of the obvious.ACM SIGARCH Computer Architecture News, 23(1):20–24, 1995. doi: 10.1145/216585.216588. URLhttps://doi.org/10.1145/216585.216588
-
[51]
J. Yuan, H. Gao, D. Dai, J. Luo, L. Zhao, Z. Zhang, Z. Xie, Y . X. Wei, L. Wang, Z. Xiao, Y . Wang, C. Ruan, M. Zhang, W. Liang, W. Zeng, et al. Native sparse attention: Hardware- aligned and natively trainable sparse attention. InProceedings of ACL 2025, 2025. URL https://arxiv.org/abs/2502.11089. Best Paper; arXiv:2502.11089. 12
-
[52]
Deepseek-v4: Towards highly efficient million-token context intelligence
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence. Technical report, DeepSeek-AI, 2026. URL https://huggingface.co/deepseek-ai/De epSeek-V4-Pro/blob/main/DeepSeek_V4.pdf. Technical report
work page 2026
-
[53]
X. Liu, Z. Tang, P. Dong, Z. Li, Y . Liu, B. Li, X. Hu, and X. Chu. Chunkkv: Semantic- preserving kv cache compression for efficient long-context llm inference. InAdvances in Neural Information Processing Systems (NeurIPS) 39, 2025. URL https://arxiv.org/abs/2502 .00299. arXiv:2502.00299
-
[54]
arXiv preprint arXiv:2306.14048 , year=
Z. Zhang, Y . Sheng, T. Zhou, T. Chen, L. Zheng, R. Cai, B. Chen, et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models. InAdvances in Neural Information Processing Systems, volume 36, 2023. URLhttps://arxiv.org/abs/2306.14048
-
[55]
Xiang Liu, Hong Chen, Xuming Hu, and Xiaowen Chu. FlowKV: Enhancing multi-turn conversational coherence in LLMs via isolated key-value cache management. InNeurIPS Workshop on Multi-Turn Interactions in Large Language Models, 2025. URL https://arxiv. org/abs/2505.15347
-
[56]
Xiang Liu, Zhenheng Tang, Hong Chen, Peijie Dong, Zeyu Li, Xiuze Zhou, Bo Li, Xuming Hu, and Xiaowen Chu. Semantic integrity matters: Benchmarking and preserving high-density reasoning in KV cache compression. InInternational Conference on Machine Learning (ICML),
-
[57]
URLhttps://arxiv.org/abs/2502.01941
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Hong Chen, Xiang Liu, Bo Wang, Yuxuan Fan, Yuanlin Chu, Zongluo Li, Xiaowen Chu, and Xuming Hu. SONIC: Segmented optimized nexus for information compression in key-value caching.arXiv preprint arXiv:2601.21927, 2026. URL https://arxiv.org/abs/2601.2 1927
-
[59]
Zeyu Li, Chuanfu Xiao, Yang Wang, Xiang Liu, Zhenheng Tang, Baotong Lu, Mao Yang, Xinyu Chen, and Xiaowen Chu. AnTKV: Anchor token-aware sub-bit vector quantization for KV cache in large language models.arXiv preprint arXiv:2506.19505, 2025. URL https: //arxiv.org/abs/2506.19505
-
[60]
Ora- cleKV: Oracle guidance for question-independent KV cache eviction
Yuanbing Zhu, Zhenheng Tang, Xiang Liu, Ang Li, Bo Li, Xiaowen Chu, and Bo Han. Ora- cleKV: Oracle guidance for question-independent KV cache eviction. InICML Workshop on Long-Context F oundation Models, 2025. URL https://openreview.net/pdf?id=KHM2YO GgX9
work page 2025
-
[61]
Y . Sheng, L. Zheng, B. Yuan, Z. Li, M. Ryabinin, B. Chen, I. Stoica, et al. Flexgen: High- throughput generative inference of large language models with a single gpu. InProceedings of the 40th International Conference on Machine Learning (ICML), pages 31094–31116, 2023. URLhttps://arxiv.org/abs/2303.06865
- [62]
-
[63]
X. Liu, X. Hu, X. Chu, and E. Choi. Diffadapt: Difficulty-adaptive reasoning for token-efficient llm inference, 2025. URL https://arxiv.org/abs/2510.19669 . arXiv preprint arXiv:2510.19669
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Reasoning language model inference serving unveiled: An empirical study
Qi Li, Junpan Wu, Xiang Liu, Yuxin Wang, Zeyu Li, Zhenheng Tang, Yuhan Chen, Shaohuai Shi, and Xiaowen Chu. Reasoning language model inference serving unveiled: An empirical study. InInternational Conference on Learning Representations (ICLR), 2026. URL https: //arxiv.org/abs/2510.18672
-
[65]
Peijie Dong, Zhenheng Tang, Xiang Liu, Lujun Li, Xiaowen Chu, and Bo Li. Can compressed LLMs truly act? an empirical evaluation of agentic capabilities in LLM compression. In International Conference on Machine Learning (ICML), 2025. URL https://arxiv.org/ab s/2505.19433
-
[66]
Zhenheng Tang, Xiang Liu, Qian Wang, Peijie Dong, Bingsheng He, Xiaowen Chu, and Bo Li. The lottery LLM hypothesis, rethinking what abilities should LLM compression preserve? In ICLR Blogposts Track, 2025. URLhttps://arxiv.org/abs/2502.17535. 13
-
[67]
National energy administration releases 2024 national electric power industry statistics
National Energy Administration. National energy administration releases 2024 national electric power industry statistics. National Energy Administration of China, 2025. URL https: //www.nea.gov.cn/20250121/097bfd7c1cd3498897639857d86d5dac/c.html
-
[68]
Interpretation of the work plan for stabilizing growth in the power equipment industry (2025–2026)
Ministry of Industry and Information Technology, State Administration for Market Regulation, and National Energy Administration. Interpretation of the work plan for stabilizing growth in the power equipment industry (2025–2026). Technical report, Ministry of Industry and Information Technology, 2025. URL https://www.miit.gov.cn/zwgk/zcjd/art/2025 /art_44b...
work page 2025
-
[69]
Launch of second data centre – call for application
Infocomm Media Development Authority and Singapore Economic Development Board. Launch of second data centre – call for application. Technical report, IMDA / EDB, 2025. URL https://www.imda.gov.sg/resources/press-releases-factsheets-and-speeche s/factsheets/2025/launch-of-second-data-centre. IMDA / EDB Factsheet
work page 2025
-
[70]
State of ai: token-usage rankings, q1 2026
OpenRouter. State of ai: token-usage rankings, q1 2026. OpenRouter, 2026. URL https: //openrouter.ai/state-of-ai
work page 2026
-
[71]
2025 ai index report: Ai model performance gaps narrowing, compute costs plummeting
Stanford Institute for Human-Centered Artificial Intelligence. 2025 ai index report: Ai model performance gaps narrowing, compute costs plummeting. Technical report, Stanford HAI, 2025. URLhttps://aiindex.stanford.edu/report/
work page 2025
- [72]
-
[73]
W. S. Jevons.The Coal Question: An Inquiry Concerning the Progress of the Nation, and the Probable Exhaustion of Our Coal-Mines. Macmillan and Co., London, 1865
-
[74]
S. Sorrell. Jevons’ paradox revisited: The evidence for backfire from improved energy efficiency. Energy Policy, 37(4):1456–1469, 2009. doi: 10.1016/j.enpol.2008.12.003. URL https: //doi.org/10.1016/j.enpol.2008.12.003
-
[75]
G. Appenzeller. Welcome to llmflation: Llm inference cost is going down fast. Andreessen Horowitz, 2024. URLhttps://a16z.com/llmflation-llm-inference-cost/
work page 2024
-
[76]
M. Demirer, A. Fradkin, N. Tadelis, and S. Peng. The emerging market for intelligence: pricing, supply, and demand for llms. Technical Report 34608, National Bureau of Economic Research,
- [77]
-
[78]
High cost of energy: industrial electricity prices in the eu vs the us and china
BusinessEurope. High cost of energy: industrial electricity prices in the eu vs the us and china. BusinessEurope Data Hub, 2024. URL https://www.businesseurope.eu/media-room/ data-hub/high-cost-of-energy/
work page 2024
-
[79]
C. Shapiro and H. R. Varian.Information Rules: A Strategic Guide to the Network Economy. Harvard Business School Press, 1999
work page 1999
-
[80]
Energy Information Administration
U.S. Energy Information Administration. Electric power monthly, table 5.6.b: Average price of electricity to ultimate customers by end-use sector, by state (december 2025 ytd). Technical report, U.S. Energy Information Administration, 2026. URL https://www.eia.gov/electr icity/monthly/epm_table_grapher.php?t=epmt_5_6_b
work page 2025
-
[81]
E. Wu. Sovereignty and data localization. Technical report, Belfer Center for Science and International Affairs, Harvard Kennedy School, 2021. URL https://www.belfercenter.o rg/publication/sovereignty-and-data-localization
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.