Recognition: 1 theorem link
· Lean TheoremBeyond Inefficiency: Systemic Costs of Incivility in Multi-Agent Monte Carlo Simulations
Pith reviewed 2026-05-13 06:23 UTC · model grok-4.3
The pith
Simulations of LLM agent debates confirm that incivility adds 25 percent to convergence time, with stronger effects in smaller models and a persistent first-mover advantage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
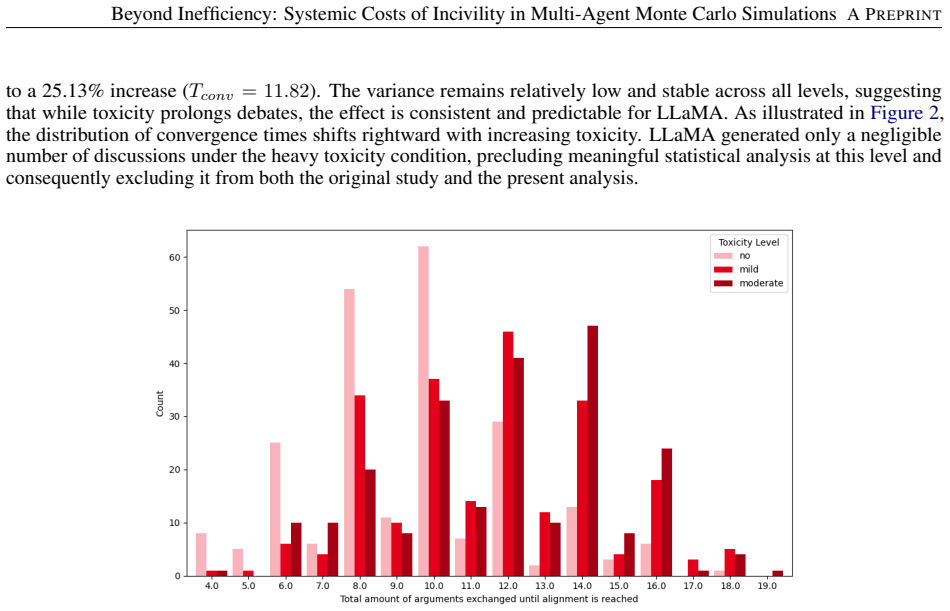
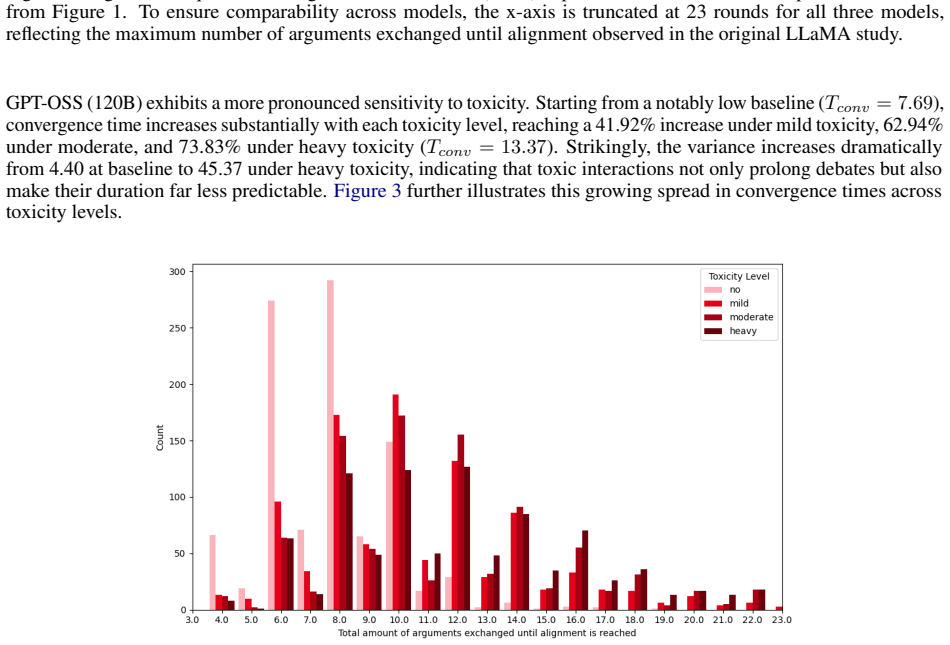
In Monte Carlo simulations of 1-on-1 adversarial debates between LLM agents, incivil or toxic communication increases the number of rounds required to reach a conclusion by 25 percent compared to civil conditions. This convergence latency is significantly larger for agents based on smaller-parameter models. Additionally, the agent that initiates the discussion achieves a winning rate significantly above chance, independent of the toxicity level imposed on the exchange.
What carries the argument
Monte Carlo simulation framework that systematically varies toxicity in structured 1-on-1 LLM agent debates and counts rounds to convergence.
If this is right
- Incivility imposes a consistent 25 percent penalty on debate convergence time across different LLM agents.
- Smaller models exhibit greater sensitivity to toxic communication, amplifying efficiency losses.
- First-mover status provides a structural advantage in winning debates irrespective of communication tone.
- The observed effects can be replicated and extended across multiple model scales using the same simulation protocol.
Where Pith is reading between the lines
- If LLM agents capture key dynamics of human debate, then interventions targeting first-mover advantages could improve outcomes in both AI and human collaborative settings.
- The scale-dependent latency suggests that efficiency costs of poor communication may be more pronounced in resource-limited AI deployments.
- Future work could test whether introducing explicit turn-taking rules reduces the first-mover edge in these simulations.
Load-bearing premise
The assumption that LLM agents' responses to manipulated toxicity conditions accurately model how human participants would behave and decide in similar debates.
What would settle it
Running the identical debate protocol with human participants and finding no increase in convergence time under toxic conditions would falsify the claim that the simulation captures real efficiency costs.
Figures





read the original abstract
Unconstructive debate and uncivil communication carry well-documented costs for productivity and cohesion, yet isolating their effect on operational efficiency has proven difficult. Human subject research in this domain is constrained by ethical oversight, limited reproducibility, and the inherent unpredictability of naturalistic settings. We address this gap by leveraging Large Language Model (LLM) based Multi-Agent Systems as a controlled sociological sandbox, enabling systematic manipulation of communicative behavior at scale. Using a Monte Carlo simulation framework, we generate thousands of structured 1-on-1 adversarial debates across varying toxicity conditions, measuring convergence time, defined as the number of rounds required to reach a conclusion, as a proxy for interactional efficiency. Building on a prior study, we replicate and extend its findings across two additional LLM agents of varying parameter size, allowing us to assess whether the effects of toxic behavior on debate dynamics generalize across model scale. The convergence latency of 25% reported in the previous study was confirmed. It was found that this latency is significantly bigger for models with fewer parameters. We further identify a significant first-mover advantage, whereby the agent initiating the discussion wins significantly above chance regardless of toxicity condition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper uses LLM-based multi-agent Monte Carlo simulations of 1-on-1 adversarial debates to isolate the effects of manipulated toxicity on interactional efficiency, measured as convergence latency (rounds to conclusion). Building on a prior study, it replicates a 25% latency increase under toxic conditions, reports that this latency scales inversely with model parameter count, and identifies a first-mover advantage in which the initiating agent wins significantly above chance independent of toxicity.
Significance. If the quantitative claims are robust, the work demonstrates a reproducible, scalable sandbox for studying communicative costs that bypasses ethical and logistical limits of human-subject research. The cross-scale replication and first-mover finding could supply falsifiable predictions for both AI and social-science literatures on debate dynamics. The absence of human-data validation and statistical reporting, however, confines the current contribution to an internal demonstration within the chosen LLM agents.
major comments (3)
- [Methods] Methods section: the Monte Carlo framework is described at a high level but provides no sample-size justification, number of independent runs per condition, or statistical procedure (e.g., t-test, ANOVA, or bootstrap) supporting the claims that latency is “significantly bigger” for smaller models and that first-mover wins are “significantly above chance.”
- [Results] Results section: reported effects lack error bars, confidence intervals, or p-values; without these, it is impossible to evaluate whether the 25% latency replication or the first-mover advantage exceeds what would be expected from prompt artifacts or model-specific refusal patterns.
- [Discussion] Discussion section: the central claim that LLM-agent toxicity manipulations serve as a valid proxy for human incivility effects is asserted without any validation against human debate corpora, sensitivity checks on the toxicity prompt template, or controls for LLM training-data biases toward polite language.
minor comments (2)
- [Abstract] Abstract: the phrase “two additional LLM agents of varying parameter size” is not accompanied by the actual model names or parameter counts, which are needed to interpret the scaling claim.
- [Introduction] Notation: “convergence latency” is used interchangeably with “number of rounds”; a single, explicit definition early in the text would improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We have revised the manuscript to incorporate additional methodological details, statistical reporting, and expanded discussion of limitations. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [Methods] Methods section: the Monte Carlo framework is described at a high level but provides no sample-size justification, number of independent runs per condition, or statistical procedure (e.g., t-test, ANOVA, or bootstrap) supporting the claims that latency is “significantly bigger” for smaller models and that first-mover wins are “significantly above chance.”
Authors: We agree that the original Methods section was insufficiently detailed for full reproducibility. In the revised manuscript we have added an explicit subsection that (i) justifies the choice of 1000 independent Monte Carlo runs per condition on the basis of observed convergence of the latency estimator, (ii) states the exact number of runs executed, and (iii) describes the statistical procedures employed: bootstrap resampling (10 000 iterations) to obtain 95 % confidence intervals and two-sample t-tests (with Bonferroni correction) for latency comparisons across model sizes, plus binomial tests for the first-mover advantage against the null of 50 % win probability. These additions directly support the significance claims. revision: yes
-
Referee: [Results] Results section: reported effects lack error bars, confidence intervals, or p-values; without these, it is impossible to evaluate whether the 25% latency replication or the first-mover advantage exceeds what would be expected from prompt artifacts or model-specific refusal patterns.
Authors: We accept this criticism. The revised Results section now presents all mean latencies with 95 % bootstrap confidence intervals as error bars, reports the corresponding p-values from the t-tests described in the updated Methods, and includes the exact binomial p-values for the first-mover effect. These additions allow readers to assess whether the observed 25 % latency increase and first-mover advantage are distinguishable from sampling variability or prompt-induced artifacts. revision: yes
-
Referee: [Discussion] Discussion section: the central claim that LLM-agent toxicity manipulations serve as a valid proxy for human incivility effects is asserted without any validation against human debate corpora, sensitivity checks on the toxicity prompt template, or controls for LLM training-data biases toward polite language.
Authors: We partially agree. Direct validation against human debate corpora lies outside the scope of the present simulation study and would require a separate human-subject protocol. However, we have added (i) sensitivity analyses that vary the toxicity prompt intensity and phrasing, (ii) explicit controls that test multiple prompt templates to mitigate training-data politeness biases, and (iii) a substantially expanded limitations paragraph that frames the work as an internal demonstration within LLM agents while citing relevant human literature for contextual comparison only. These changes clarify the proxy status without overstating equivalence. revision: partial
- Direct empirical validation of the LLM-agent results against human debate corpora, which would necessitate an independent human-subject study beyond the current Monte Carlo simulation framework.
Circularity Check
No circularity: results from forward Monte Carlo runs, not reduced to inputs by construction
full rationale
The paper's claims rest on direct measurement of convergence rounds and win rates from thousands of simulated 1-on-1 LLM debates under controlled toxicity prompts. No equations, fitted parameters, or self-referential definitions are described that would make the reported 25% latency, its scaling with model size, or the first-mover advantage equivalent to the simulation inputs by construction. Replication of the prior study's latency figure is presented as empirical confirmation rather than a statistically forced prediction. The methodology is self-contained against external benchmarks in the sense that outcomes are generated forward from the agent interactions, with no load-bearing self-citation chain or ansatz smuggling identified in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents under controlled toxicity prompts can serve as valid proxies for human communicators in measuring debate convergence time
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Using a Monte Carlo simulation framework, we generate thousands of structured 1-on-1 adversarial debates across varying toxicity conditions, measuring convergence time... as a proxy for interactional efficiency.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URL http://arxiv.org/abs/2208.10264. arXiv:2208.10264 [cs]. Elif Akata, Lion Schulz, Julian Coda-Forno, Seong Joon Oh, Matthias Bethge, and Eric Schulz. Playing repeated games with Large Language Models.Nature Human Behaviour, 9(7):1380–1390, May
-
[2]
ISSN 2397-3374. doi: 10.1038/s41562-025-02172-y. URLhttp://arxiv.org/abs/2305.16867. arXiv:2305.16867 [cs]. Lilia Cortina, Dana Kabat-Farr, Emily Leskinen, Marisela Huerta, and Vicki Magley. Selective Incivility as Modern Discrimination in Organizations Evidence and Impact.Journal of Management, 39:1579–1605, September
-
[3]
Ameet Deshpande, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, and Karthik Narasimhan
doi: 10.1177/0149206311418835. Ameet Deshpande, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, and Karthik Narasimhan. Toxicity in chatgpt: Analyzing persona-assigned language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Findings of the Association for Computational Linguistics: EMNLP 2023, pages 1236–1270, Singapore, December
-
[4]
doi: 10.18653/v1/2023.findings-emnlp.88
Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp.88. URL https:// aclanthology.org/2023.findings-emnlp.88/. Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. Improving Factuality and Reasoning in Language Models through Multiagent Debate, May
-
[5]
URL http://arxiv.org/abs/2305. 14325. arXiv:2305.14325 [cs]. Joshua M. Epstein and Robert Axtell.Growing Artificial Societies: Social Science from the Bottom Up. Brookings Institution Press, October
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
ISBN 978-0-262-05053-1. Google-Books-ID: xXvelSs2caQC. Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A. Smith. RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models. In Trevor Cohn, Yulan He, and Yang Liu, editors,Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3356–3369, Online, November
work page 2020
-
[7]
doi: 10.18653/v1/2020.findings-emnlp.301
Association for Computational Linguistics. doi: 10.18653/v1/2020.findings-emnlp.301. URL https://aclanthology.org/ 2020.findings-emnlp.301/. Nigel Gilbert and Pietro Terna. How to build and use agent-based models in social science.Mind & Society, 1(1):57–72, March
-
[8]
ISSN 1860-1839. doi: 10.1007/BF02512229. URLhttps://doi.org/10.1007/BF02512229. Zhe Hu, Hou Pong Chan, Jing Li, and Yu Yin. Debate-to-Write: A Persona-Driven Multi-Agent Framework for Diverse Argument Generation, January
-
[9]
URLhttp://arxiv.org/abs/2406.19643. arXiv:2406.19643 [cs]. Yiming Huang, Biquan Bie, Zuqiu Na, Weilin Ruan, Songxin Lei, Yutao Yue, and Xinlei He. Understanding the Anchoring Effect of LLM with Synthetic Data: Existence, Mechanism, and Potential Mitigations, March
-
[10]
URL http://arxiv.org/abs/2505.15392. arXiv:2505.15392 [cs]. 10 Beyond Inefficiency: Systemic Costs of Incivility in Multi-Agent Monte Carlo SimulationsA PREPRINT Smita Khapre, Melkamu Abay Mersha, Hassan Shakil, Jonali Baruah, and Jugal Kalita. Toxicity in Online Platforms and AI Systems: A Survey of Needs, Challenges, Mitigations, and Future Directions.E...
-
[11]
doi: 10.1016/j.eswa.2025.129832
ISSN 09574174. doi: 10.1016/j.eswa.2025.129832. URL http://arxiv.org/abs/ 2509.25539. arXiv:2509.25539 [cs]. Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society, November
-
[12]
CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society
URL http: //arxiv.org/abs/2303.17760. arXiv:2303.17760 [cs]. Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on E...
work page internal anchor Pith review arXiv 2024
-
[13]
Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.992. URL https://aclanthology.org/2024.emnlp-main. 992/. Jiaxu Lou and Yifan Sun. Anchoring Bias in Large Language Models: An Experimental Study, December
-
[14]
URL https://arxiv.org/abs/2412.06593v2. Benedikt Mangold. The High Cost of Incivility: Quantifying Interaction Inefficiency via Multi-Agent Monte Carlo Simulations, December
-
[15]
URLhttp://arxiv.org/abs/2512.08345. arXiv:2512.08345 [cs]. Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative Agents: Interactive Simulacra of Human Behavior, August
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
URL http://arxiv.org/abs/2304. 03442. arXiv:2304.03442 [cs]. Jiahu Qin, Qichao Ma, Yang Shi, and Long Wang. Recent Advances in Consensus of Multi-Agent Systems: A Brief Survey.IEEE Transactions on Industrial Electronics, 64(6):4972–4983, June
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
ISSN 1557-9948. doi: 10.1109/TIE.2016.2636810. URLhttps://ieeexplore.ieee.org/document/7776972/. Leonard Salewski, Stephan Alaniz, Isabel Rio-Torto, Eric Schulz, and Zeynep Akata. In-Context Impersonation Reveals Large Language Models’ Strengths and Biases, November
-
[18]
Francesco Salvi, Manoel Horta Ribeiro, Riccardo Gallotti, and Robert West
URL http://arxiv.org/abs/2305.14930. arXiv:2305.14930 [cs]. Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R. Johnston, Shauna Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang, and Ethan Perez. Towa...
-
[19]
Towards Understanding Sycophancy in Language Models
URL http://arxiv.org/abs/2310.13548. arXiv:2310.13548 [cs]. Yoshiki Takenami, Yin Jou Huang, Yugo Murawaki, and Chenhui Chu. How Does Cognitive Bias Affect Large Language Models? A Case Study on the Anchoring Effect in Price Negotiation Simulations, August
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Amos Tversky and Daniel Kahneman
URL https://arxiv.org/abs/2508.21137v2. Amos Tversky and Daniel Kahneman. Judgment under Uncertainty: Heuristics and Biases.Science, 185(4157): 1124–1131, September
-
[21]
URL https://www.science.org/doi/10
doi: 10.1126/science.185.4157.1124. URL https://www.science.org/doi/10. 1126/science.185.4157.1124. Laura Weidinger, John Mellor, Maribeth Rauh, Conor Griffin, Jonathan Uesato, Po-Sen Huang, Myra Cheng, Mia Glaese, Borja Balle, Atoosa Kasirzadeh, Zac Kenton, Sasha Brown, Will Hawkins, Tom Stepleton, Courtney Biles, Abeba Birhane, Julia Haas, Laura Rimell,...
-
[22]
Ethical and social risks of harm from Language Models
URL http://arxiv.org/abs/2112.04359. arXiv:2112.04359 [cs]. Andrea Wynn, Harsh Satija, and Gillian Hadfield. Talk Isn’t Always Cheap: Understanding Failure Modes in Multi- Agent Debate, October
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
URLhttp://arxiv.org/abs/2509.05396. arXiv:2509.05396 [cs]. Binwei Yao, Chao Shang, Wanyu Du, Jianfeng He, Ruixue Lian, Yi Zhang, Hang Su, Sandesh Swamy, and Yanjun Qi. Peacemaker or Troublemaker: How Sycophancy Shapes Multi-Agent Debate, September
-
[24]
URL http: //arxiv.org/abs/2509.23055. arXiv:2509.23055 [cs]. Wenxuan Zhou, Sheng Zhang, Hoifung Poon, and Muhao Chen. Context-faithful Prompting for Large Language Models, March
-
[25]
URLhttps://arxiv.org/abs/2303.11315v2. 11 Beyond Inefficiency: Systemic Costs of Incivility in Multi-Agent Monte Carlo SimulationsA PREPRINT Table 5: List of topics being used fromhttps://idebate.net, see Hu et al
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.