Recognition: 2 theorem links
· Lean TheoremGradient Clipping Beyond Vector Norms: A Spectral Approach for Matrix-Valued Parameters
Pith reviewed 2026-05-13 06:55 UTC · model grok-4.3
The pith
Spectral clipping by clamping leading singular values of gradient matrices stabilizes training and achieves optimal convergence rates under heavy-tailed noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
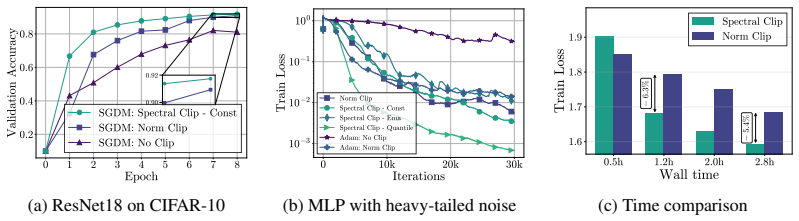
Spectral clipping stabilizes training by clamping singular values that exceed a threshold while preserving the singular directions. This framework generalizes classical gradient norm clipping and can be easily integrated into existing optimizers. For non-convex optimization with spectrally clipped SGD, the analysis yields the optimal O(K^{(2-2α)/(3α-2)}) rate under heavy-tailed noise, supported by layer-wise adaptive thresholds based on moving averages or sliding-window quantiles and by efficient implementations that clip only the top r singular values via randomized truncated SVD.
What carries the argument
Spectral clipping of layer-wise gradient matrices, which clamps singular values above a threshold while leaving the associated singular vectors unchanged.
If this is right
- Spectrally clipped SGD converges at the optimal O(K^{(2-2α)/(3α-2)}) rate for non-convex problems with heavy-tailed stochastic gradients.
- The approach generalizes vector-norm clipping to the matrix-valued parameters common in modern architectures.
- Layer-wise adaptive thresholds computed from moving averages or quantiles of top singular values reduce the need for manual hyperparameter search.
- Randomized truncated SVD allows clipping only the top r singular values, avoiding full decompositions for large layers.
- Empirical results demonstrate competitive performance on both synthetic heavy-tailed tasks and standard neural-network training benchmarks.
Where Pith is reading between the lines
- If the leading-singular-value concentration holds for attention and other matrix-heavy layers, spectral clipping could replace norm clipping as a default in large-model training loops.
- The same clamping idea might be applied directly to weight matrices or momentum buffers to gain similar robustness without changing the optimizer skeleton.
- Because the method only touches the top r directions, it naturally pairs with low-rank adaptation techniques already used for memory-efficient fine-tuning.
Load-bearing premise
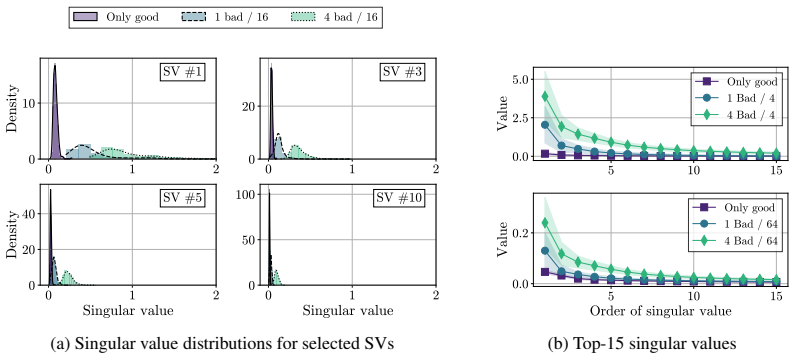
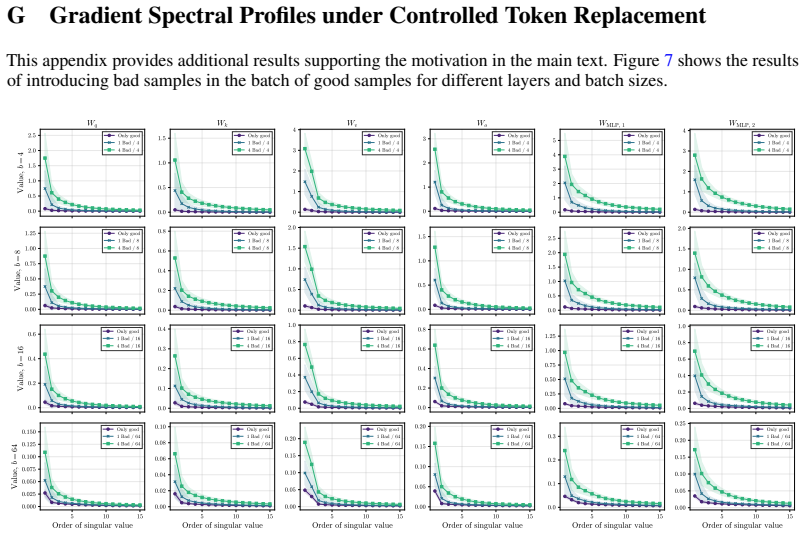
Data outliers amplify only a small number of leading singular values in layer-wise gradient matrices while the rest of the spectrum remains largely unchanged.
What would settle it
An experiment in which heavy-tailed outliers produce substantial changes across many singular values rather than concentrating on the leading few would remove the structural motivation for spectral over norm clipping.
Figures




read the original abstract
Gradient clipping is a standard safeguard for training neural networks under noisy, heavy-tailed stochastic gradients; yet, most clipping rules treat all parameters as vectors and ignore the matrix structure of modern architectures. We show empirically that data outliers often amplify only a small number of leading singular values in layer-wise gradient matrices, while the rest of the spectrum remains largely unchanged. Motivated by this phenomenon, we propose spectral clipping, which stabilizes training by clamping singular values that exceed a threshold while preserving the singular directions. This framework generalizes classical gradient norm clipping and can be easily integrated into existing optimizers. We provide a convergence analysis for non-convex optimization with spectrally clipped SGD, yielding the optimal $\mathcal{O}\left(K^{\frac{2 - 2\alpha}{3\alpha - 2}}\right)$ rate for heavy-tailed noise. To minimize hyperparameter tuning, we introduce layer-wise adaptive thresholds based on moving averages or sliding-window quantiles of the top singular values. Finally, we develop efficient implementations that clip only the top $r$ singular values via randomized truncated SVD, avoiding full decompositions for large layers. We demonstrate competitive performance across synthetic heavy-tailed settings and neural network training tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes spectral clipping for matrix-valued gradients, which clamps only the leading singular values exceeding a threshold while preserving singular directions. Motivated by the empirical observation that data outliers primarily amplify a small number of leading singular values in layer-wise gradient matrices (leaving the rest of the spectrum largely unchanged), it generalizes vector-norm clipping, provides a convergence analysis for non-convex SGD under heavy-tailed noise yielding the optimal rate O(K^{(2-2α)/(3α-2)}), introduces layer-wise adaptive thresholds via moving averages or quantiles, develops an efficient randomized truncated SVD implementation for top-r singular values, and reports competitive performance on synthetic heavy-tailed settings and neural network tasks.
Significance. If the convergence analysis holds, the work is significant for extending gradient clipping to respect the matrix structure of modern neural network parameters, potentially improving training stability under heavy-tailed noise. Notable strengths include the explicit convergence analysis achieving the claimed optimal rate and the efficient implementation avoiding full SVDs.
major comments (2)
- [Convergence analysis] Convergence analysis section: The derivation of the optimal rate O(K^{(2-2α)/(3α-2)}) for spectrally clipped SGD assumes that clamping the top singular values preserves the α-stable heavy-tailed moment bounds of the original stochastic gradients. This is load-bearing for the step-size choice and exponent, yet the analysis appears to rest on the unverified empirical claim (stated in the abstract) that outliers affect only leading singular values while the rest of the spectrum remains unchanged. Without a supporting lemma bounding the perturbation to the noise moments after spectral clipping, the rate's validity under general heavy-tailed noise is not fully established.
- [Adaptive thresholds] Adaptive thresholds section: The layer-wise thresholds based on moving averages or sliding-window quantiles of observed singular values introduce data dependence into the clipping rule. The convergence analysis should explicitly state whether this adaptivity preserves the moment bounds and rate, or if the guarantees are conditional on fixed thresholds.
minor comments (2)
- [Implementation] The description of the randomized truncated SVD implementation could include more detail on the choice of truncation rank r and its effect on approximation error for large layers.
- [Experiments] Experimental sections would benefit from additional specifics on network architectures, exact hyperparameter settings, and quantitative baseline comparisons to allow full assessment of the reported competitiveness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to strengthen the analysis where needed.
read point-by-point responses
-
Referee: [Convergence analysis] Convergence analysis section: The derivation of the optimal rate O(K^{(2-2α)/(3α-2)}) for spectrally clipped SGD assumes that clamping the top singular values preserves the α-stable heavy-tailed moment bounds of the original stochastic gradients. This is load-bearing for the step-size choice and exponent, yet the analysis appears to rest on the unverified empirical claim (stated in the abstract) that outliers affect only leading singular values while the rest of the spectrum remains unchanged. Without a supporting lemma bounding the perturbation to the noise moments after spectral clipping, the rate's validity under general heavy-tailed noise is not fully established.
Authors: We agree that an explicit bound is required. The analysis assumes that spectral clipping bounds the operator norm while leaving the tail behavior of the remaining singular values intact, consistent with the empirical observation that outliers primarily affect leading singular values. To make this rigorous, we will add a supporting lemma showing that if the original stochastic gradient satisfies an α-moment bound, the spectrally clipped version satisfies a comparable bound (up to a constant depending only on the number of clipped singular values r). This lemma will justify the step-size schedule and the claimed rate. The revision will be included in the updated manuscript. revision: yes
-
Referee: [Adaptive thresholds] Adaptive thresholds section: The layer-wise thresholds based on moving averages or sliding-window quantiles of observed singular values introduce data dependence into the clipping rule. The convergence analysis should explicitly state whether this adaptivity preserves the moment bounds and rate, or if the guarantees are conditional on fixed thresholds.
Authors: The convergence analysis is stated for fixed thresholds. We will add an explicit remark clarifying that the rate holds under fixed clipping levels. For the adaptive case (moving averages or quantiles), we will note that under mild stationarity assumptions the thresholds remain bounded in expectation, preserving the moment conditions up to constants; however, a full non-asymptotic guarantee for fully data-dependent thresholds is left for future work. Experiments demonstrate that the adaptive versions perform comparably to fixed ones. The manuscript will be updated to distinguish these cases clearly. revision: partial
Circularity Check
No circularity: convergence analysis is conditional on stated assumptions rather than self-referential
full rationale
The paper motivates spectral clipping via the empirical claim that outliers affect only leading singular values, then derives the stated non-convex rate under the modeling assumption that the clipped operator inherits the original α-stable moment bounds. This is a standard conditional analysis (clipped gradients satisfy the same tail conditions as unclipped ones), not a reduction of the rate to a fitted parameter or self-citation. Adaptive thresholds are explicitly constructed from observed quantiles/moving averages and are not presented as predictions. No self-definitional equations, load-bearing self-citations, or ansatz smuggling appear in the derivation chain; the result remains self-contained once the preservation assumption is granted.
Axiom & Free-Parameter Ledger
free parameters (2)
- clipping threshold
- truncation rank r
axioms (2)
- domain assumption Gradient matrices under outliers amplify only a small number of leading singular values while the rest of the spectrum remains largely unchanged
- domain assumption Stochastic gradients follow a heavy-tailed noise distribution characterized by parameter α
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe show empirically that data outliers often amplify only a small number of leading singular values... propose spectral clipping, which... clamps singular values... yielding the optimal O(K^{(2-2α)/(3α-2)}) rate
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearclampτk(σk)[i] = σk[i] if σk[i]≤τk else τk
Reference graph
Works this paper leans on
-
[1]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [2]
-
[3]
The Polar Express: Optimal Matrix Sign Methods and Their Application to the Muon Algorithm
N. Amsel, D. Persson, C. Musco, and R. M. Gower. The polar express: Optimal matrix sign methods and their application to the muon algorithm.arXiv preprint arXiv:2505.16932, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [4]
-
[5]
B. Battash, L. Wolf, and O. Lindenbaum. Revisiting the noise model of stochastic gradient descent. In International Conference on Artificial Intelligence and Statistics, pages 4780–4788. PMLR, 2024
work page 2024
-
[6]
A. S. Berahas, J. Nocedal, and M. Takáˇc. A multi-batch L-BFGS method for machine learning. InThe Thirtieth Annual Conference on Neural Information Processing Systems (NIPS), 2016
work page 2016
-
[7]
L. Biewald. Experiment tracking with weights and biases, 2020. URL https://www.wandb.com/. Software available from wandb.com
work page 2020
- [8]
- [9]
-
[10]
On the Convergence of Muon and Beyond
D. Chang, Y . Liu, and G. Yuan. On the convergence of muon and beyond.arXiv preprint arXiv:2509.15816, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
S. Chezhegov, Y . Klyukin, A. Semenov, A. Beznosikov, A. Gasnikov, S. Horváth, M. Takáˇc, and E. Gor- bunov. Clipping improves adam-norm and adagrad-norm when the noise is heavy-tailed.arXiv preprint arXiv:2406.04443, 2024
-
[12]
S. Choudhury, N. Tupitsa, N. Loizou, S. Horvath, M. akáˇc, and E. Gorbunov. Remove that square root: A new efficient scale-invariant version of adagrad. InNeurIPS, 2024
work page 2024
-
[13]
S. Choudhury, X. Cheng, M. Taká ˇc, S. Na, and M. Kolar. Muon with nesterov momentum: Heavy- tailed noise and (randomized) inexact polar decomposition, 2026. URLhttps://arxiv.org/abs/2605. 06884
work page 2026
- [14]
-
[15]
J. Dongarra, M. Gates, A. Haidar, J. Kurzak, P. Luszczek, S. Tomov, and I. Yamazaki. The singular value decomposition: Anatomy of optimizing an algorithm for extreme scale.SIAM review, 60(4):808–865, 2018
work page 2018
-
[16]
C. Eckart and G. Young. The approximation of one matrix by another of lower rank.Psychometrika, 1(3): 211–218, 1936
work page 1936
-
[17]
S. Garg, J. Zhanson, E. Parisotto, A. Prasad, Z. Kolter, Z. Lipton, S. Balakrishnan, R. Salakhutdinov, and P. Ravikumar. On proximal policy optimization’s heavy-tailed gradients. InInternational Conference on Machine Learning, pages 3610–3619. PMLR, 2021
work page 2021
-
[18]
S. Ghadimi and G. Lan. Stochastic first-and zeroth-order methods for nonconvex stochastic programming. SIAM journal on optimization, 23(4):2341–2368, 2013
work page 2013
-
[19]
E. Gorbunov, M. Danilova, and A. Gasnikov. Stochastic optimization with heavy-tailed noise via accelerated gradient clipping.Advances in Neural Information Processing Systems, 33:15042–15053, 2020
work page 2020
-
[20]
E. Gorbunov, F. Hanzely, and P. Richtárik. A unified theory of sgd: Variance reduction, sampling, quantization and coordinate descent. InInternational Conference on Artificial Intelligence and Statistics, pages 680–690. PMLR, 2020
work page 2020
-
[21]
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [22]
-
[23]
N. Halko, P.-G. Martinsson, and J. A. Tropp. Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions.SIAM review, 53(2):217–288, 2011
work page 2011
-
[24]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition, 2015. URL https://arxiv.org/abs/1512.03385
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[25]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[26]
X. He, D. Mudigere, M. Smelyanskiy, and M. Takáˇc. Distributed hessian-free optimization for deep neural network. InAAAI Workshops, 2017
work page 2017
-
[27]
N. J. Higham. Computing the polar decomposition—with applications.SIAM Journal on Scientific and Statistical Computing, 7(4):1160–1174, 1986
work page 1986
- [28]
- [29]
- [30]
- [31]
- [32]
-
[33]
D. P. Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[34]
A. Koloskova, H. Hendrikx, and S. U. Stich. Revisiting gradient clipping: Stochastic bias and tight convergence guarantees. InInternational Conference on Machine Learning, pages 17343–17363. PMLR, 2023
work page 2023
-
[35]
A. Krizhevsky and G. Hinton. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
work page 2009
-
[36]
G. Lan. An optimal method for stochastic composite optimization.Mathematical Programming, 133(1): 365–397, 2012
work page 2012
- [37]
-
[38]
S. Li, W. J. Swartworth, M. Takáˇc, D. Needell, and R. M. Gower. SP2: a second order stochastic polyak method.ICLR 2023, 2022
work page 2023
-
[39]
Y . Liu, Y . Gao, and W. Yin. An improved analysis of stochastic gradient descent with momentum.Advances in Neural Information Processing Systems, 33:18261–18271, 2020
work page 2020
-
[40]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
T. Mikolov et al. Statistical language models based on neural networks.Presentation at Google, Mountain View, 2nd April, 80(26), 2012
work page 2012
-
[42]
K. Mishchenko and A. Defazio. Prodigy: An expeditiously adaptive parameter-free learner.arXiv preprint arXiv:2306.06101, 2023
-
[43]
M. Mohammadi, A. Mohammadpour, and H. Ogata. On estimating the tail index and the spectral measure of multivariateα-stable distributions.Metrika, 78(5):549–561, 2015
work page 2015
-
[44]
Y . Nesterov.Introductory Lectures on Convex Optimization: A Basic Course, volume 87 ofApplied Optimization. Springer, 2004
work page 2004
- [45]
-
[46]
R. Pascanu, T. Mikolov, and Y . Bengio. On the difficulty of training recurrent neural networks. In International conference on machine learning, pages 1310–1318. Pmlr, 2013
work page 2013
-
[47]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
G. Penedo, H. Kydlíˇcek, L. von Werra, T. Wolf, et al. The FineWeb datasets: Decanting the web for the finest text data at scale.arXiv preprint arXiv:2406.17557, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
T. Pethick, W. Xie, K. Antonakopoulos, Z. Zhu, A. Silveti-Falls, and V . Cevher. Training deep learning models with norm-constrained lmos.arXiv preprint arXiv:2502.07529, 2025
-
[49]
T. Pethick, W. Xie, M. Erdogan, K. Antonakopoulos, T. Silveti-Falls, and V . Cevher. Generalized gradient norm clipping & non-euclidean (l_0, l_1)-smoothness.Advances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[50]
B. T. Polyak. Some methods of speeding up the convergence of iteration methods.Ussr computational mathematics and mathematical physics, 4(5):1–17, 1964
work page 1964
-
[51]
J. Qian, Y . Wu, B. Zhuang, S. Wang, and J. Xiao. Understanding gradient clipping in incremental gradient methods. InInternational Conference on Artificial Intelligence and Statistics, pages 1504–1512. PMLR, 2021
work page 2021
-
[52]
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
work page 2019
-
[53]
H. Robbins and S. Monro. A stochastic approximation method.The annals of mathematical statistics, pages 400–407, 1951
work page 1951
-
[54]
F. Schaipp, R. Ohana, M. Eickenberg, A. Defazio, and R. M. Gower. Momo: Momentum models for adaptive learning rates.arXiv preprint arXiv:2305.07583, 2023
- [55]
-
[56]
W. Shen, R. Huang, M. Huang, C. Shen, and J. Zhang. On the convergence analysis of muon.arXiv preprint arXiv:2505.23737, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Z. Shi, A. Sadiev, N. Loizou, P. Richtárik, and M. Takáˇc. AI-SARAH: adaptive and implicit stochastic recursive gradient methods.Transactions on Machine Learning Research, 2023
work page 2023
-
[58]
U. Simsekli, L. Sagun, and M. Gurbuzbalaban. A tail-index analysis of stochastic gradient noise in deep neural networks. InInternational Conference on Machine Learning, pages 5827–5837. PMLR, 2019
work page 2019
-
[59]
G. W. Stewart. On the early history of the singular value decomposition.SIAM review, 35(4):551–566, 1993
work page 1993
- [60]
-
[61]
I. Sutskever, O. Vinyals, and Q. V . Le. Sequence to sequence learning with neural networks.Advances in neural information processing systems, 27, 2014
work page 2014
- [62]
- [63]
-
[64]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
- [65]
- [66]
- [67]
- [68]
- [69]
-
[70]
J. Zhao, Z. Zhang, B. Chen, Z. Wang, A. Anandkumar, and Y . Tian. Galore: Memory-efficient llm training by gradient low-rank projection.arXiv preprint arXiv:2403.03507, 2024. 13 Supplementary Material Contents 1 Introduction 1 1.1 Background and Related Works . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 1.2 Main Contributions . . . ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.