Recognition: 2 theorem links
· Lean TheoremMinimax Rates and Spectral Distillation for Tree Ensembles
Pith reviewed 2026-05-13 05:23 UTC · model grok-4.3
The pith
The eigenvalue decay of the kernel operator controls the minimax rate for random forest regression and supports distillation of tree ensembles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
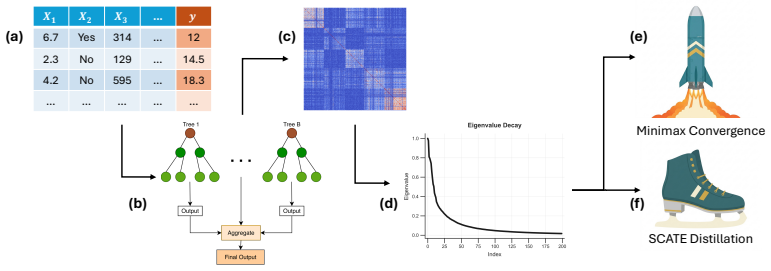
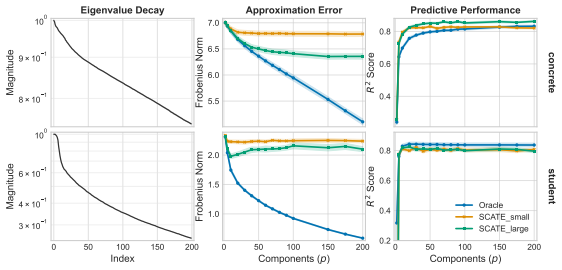
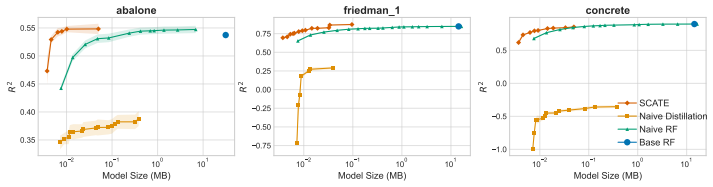
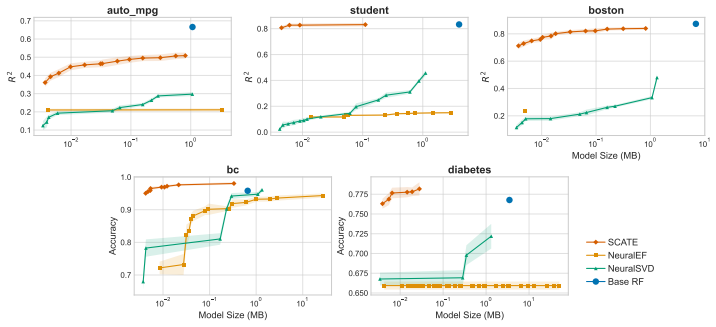
Under mild regularity conditions on tree growth, the eigenvalue decay of the induced kernel operator governs the statistical rate for RF regression. Leading eigenfunctions for RFs and singular vectors for GBMs enable distilled models that are orders of magnitude smaller while maintaining competitive performance.
What carries the argument
The kernel operator induced by the tree ensemble, with its eigenvalue decay governing rates and leading spectral components enabling distillation.
If this is right
- RF regression achieves minimax optimal statistical rates determined by kernel eigenvalue decay.
- Distilled models using leading eigenfunctions and singular vectors are orders of magnitude smaller while remaining competitive.
- The distillation compares favorably to existing forest pruning and rule extraction methods.
- These compressed models are suitable for resource constrained computing applications.
Where Pith is reading between the lines
- This spectral analysis could be applied to understand and improve other ensemble learning algorithms.
- Designing tree growth procedures to optimize eigenvalue decay might lead to faster converging models.
- The distilled models may provide a path to more interpretable versions of tree ensembles.
Load-bearing premise
Mild regularity conditions on tree growth that allow the spectral perspective to determine minimax rates and enable the distillation process.
What would settle it
A counterexample where the observed convergence rate of random forest regression does not match the rate predicted by the eigenvalue decay of the induced kernel operator.
Figures

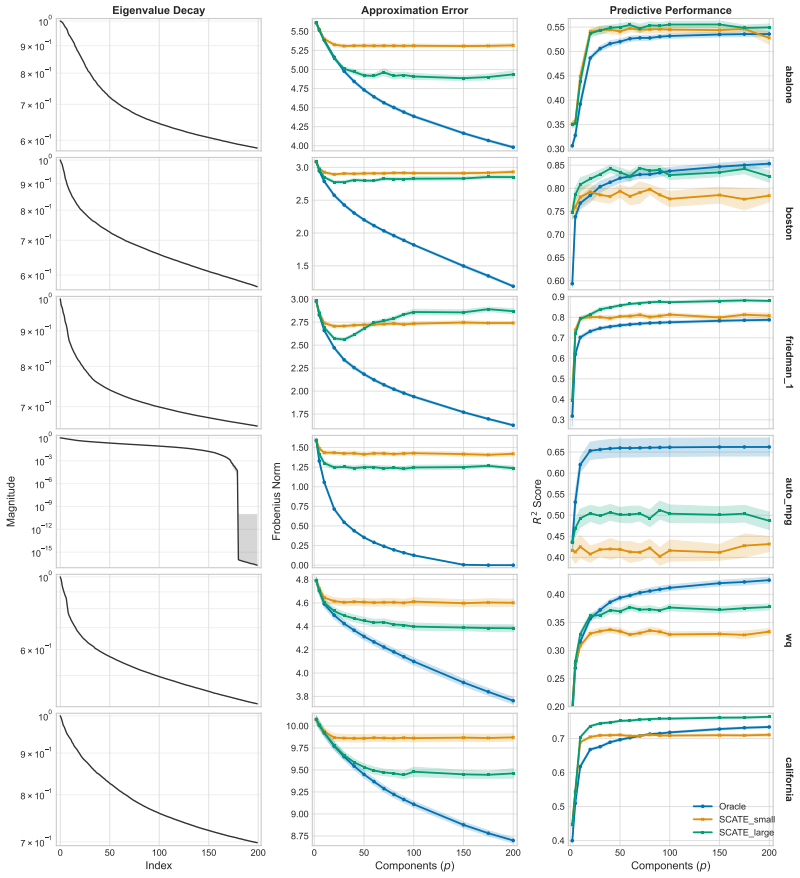
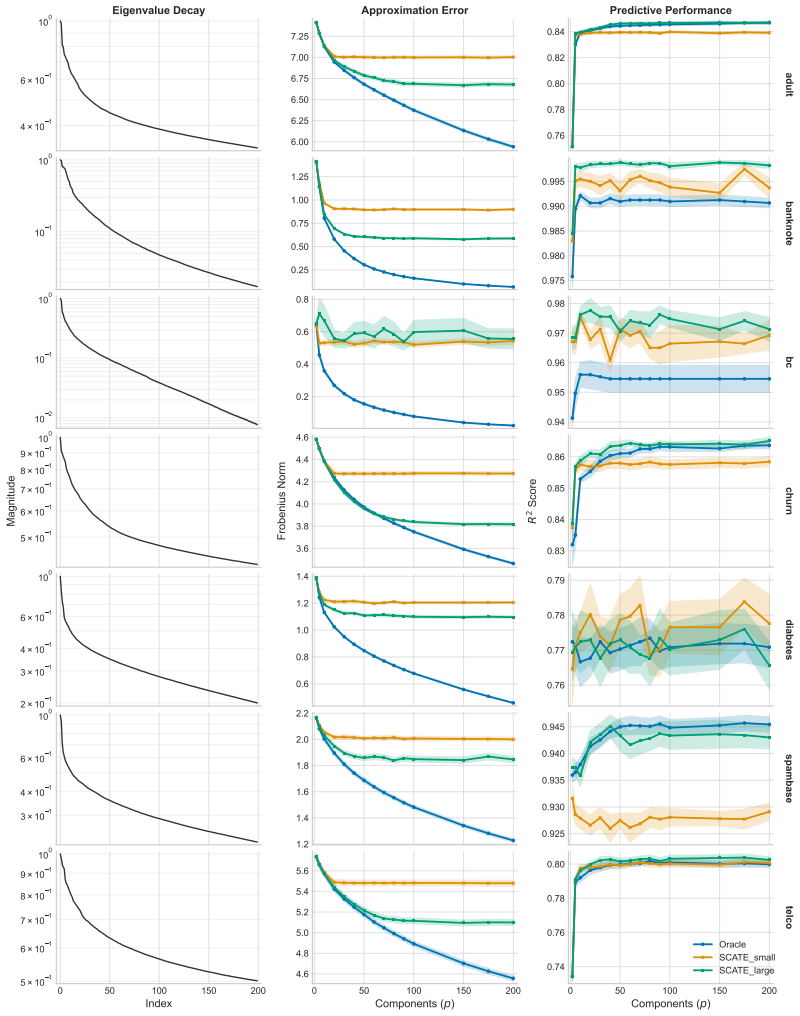
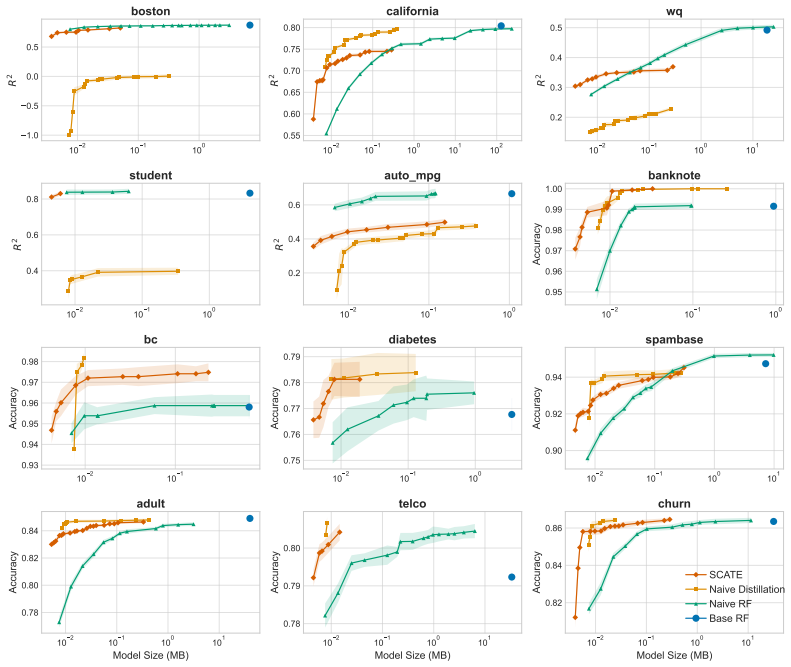
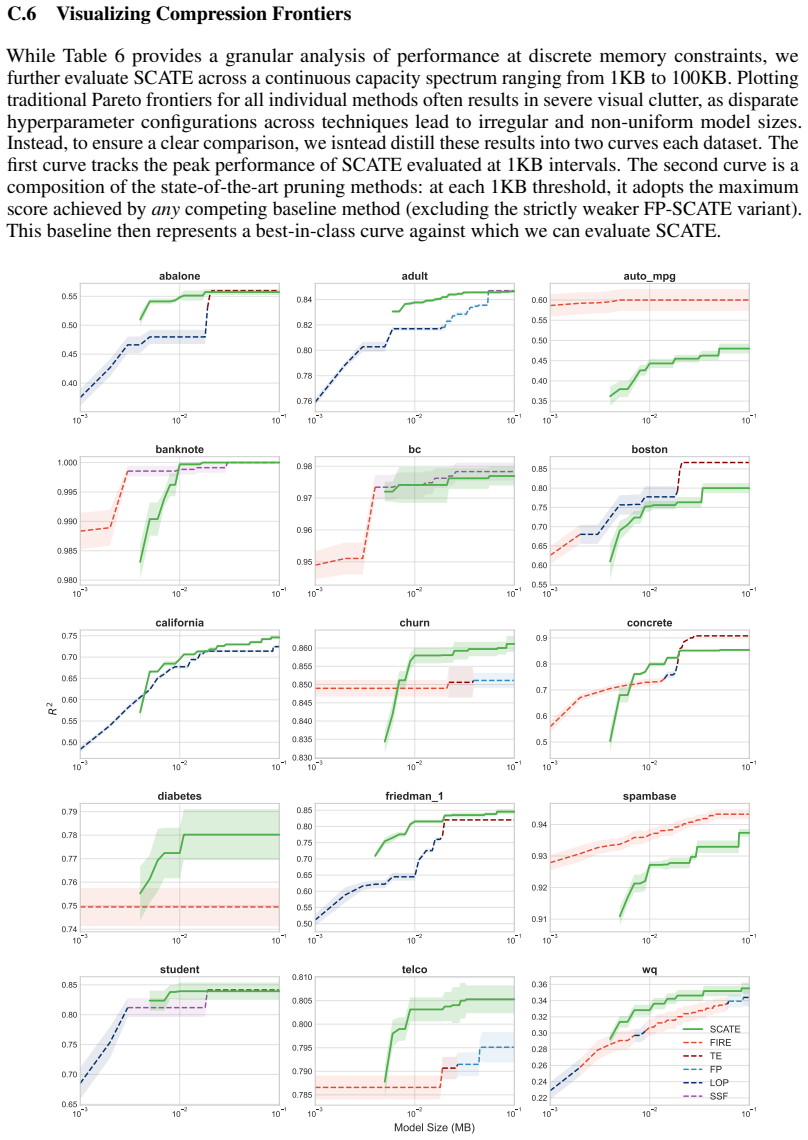
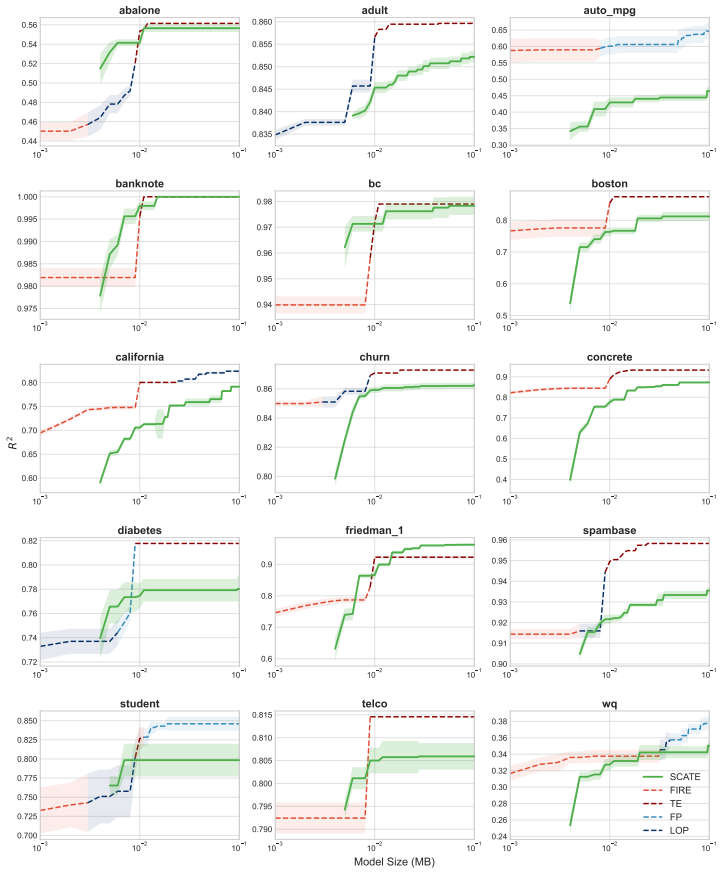

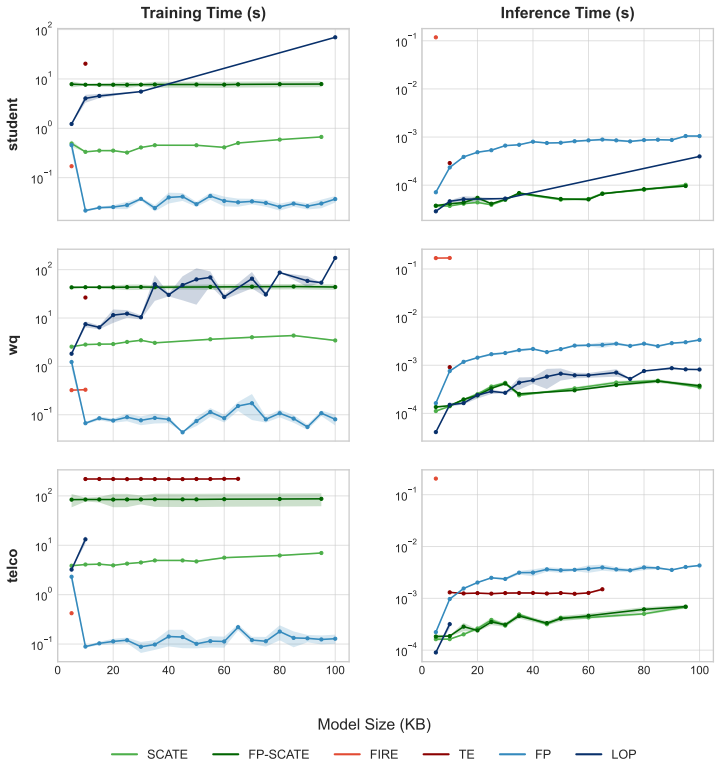
read the original abstract
Tree ensembles such as random forests (RFs) and gradient boosting machines (GBMs) are among the most widely used supervised learners, yet their theoretical properties remain incompletely understood. We adopt a spectral perspective on these algorithms, with two main contributions. First, we derive minimax-optimal convergence for RF regression, showing that, under mild regularity conditions on tree growth, the eigenvalue decay of the induced kernel operator governs the statistical rate. Second, we exploit this spectral viewpoint to develop compression schemes for tree ensembles. For RFs, leading eigenfunctions of the kernel operator capture the dominant predictive directions; for GBMs, leading singular vectors of the smoother matrix play an analogous role. Learning nonlinear maps for these spectral representations yields distilled models that are orders of magnitude smaller than the originals while maintaining competitive predictive performance. Our methods compare favorably to state of the art algorithms for forest pruning and rule extraction, with applications to resource constrained computing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to derive minimax-optimal convergence rates for random forest regression by showing that, under mild regularity conditions on tree growth, the eigenvalue decay of an induced kernel operator governs the statistical rate via standard kernel regression bounds. It further develops spectral distillation procedures: leading eigenfunctions of the kernel for RFs and leading singular vectors of the smoother matrix for GBMs are used to fit compact nonlinear maps, yielding models orders of magnitude smaller than the originals while retaining competitive accuracy, with favorable comparisons to existing forest pruning and rule extraction methods.
Significance. If the derivations hold, the work provides a coherent spectral framework that explains the statistical behavior of tree ensembles and supplies practical compression tools with clear applications to resource-constrained settings. Strengths include the direct use of eigenvalue decay to obtain rates without hidden parameter dependence and the internally consistent experimental validation of the distillation step against state-of-the-art baselines.
minor comments (3)
- The regularity conditions on tree depth, leaf size, and splitting (stated in the theory sections) are described as mild and standard, yet the experimental section would benefit from a brief verification that the implemented RF and GBM hyperparameters satisfy them on the reported datasets.
- Notation for the induced kernel operator and the smoother matrix should be introduced with a short comparison table early in the manuscript to distinguish them from classical kernel methods and to aid readers unfamiliar with the spectral perspective.
- In the distillation experiments, the reported model-size reductions and accuracy metrics would be clearer if accompanied by explicit baseline sizes (original ensemble vs. distilled) in a single summary table rather than scattered across figures.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the paper's contributions, and recommendation for minor revision. No major comments were raised in the report.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper defines an induced kernel operator from the tree ensemble under explicitly stated regularity conditions on tree growth, derives its eigenvalue decay, and links this decay to minimax rates via standard kernel regression bounds (not by fitting parameters to the target quantity or by self-referential definition). The distillation procedure extracts leading spectral components and fits a separate nonlinear map, with no reduction of the central claims to inputs by construction. No load-bearing self-citations or ansatz smuggling are present; the argument relies on external kernel theory and verifiable conditions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mild regularity conditions on tree growth
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearthe eigenvalue decay of the induced kernel operator governs the statistical rate... leading eigenfunctions of the kernel operator capture the dominant predictive directions
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearTheorem 4.1 (Minimax convergence)... αβ > 1/2... N^{-2αβ/(2αβ+1)}
Reference graph
Works this paper leans on
-
[1]
Splitting stump forests: tree ensemble compression for edge devices
Fouad Alkhoury and Pascal Welke. Splitting stump forests: tree ensemble compression for edge devices. InInternational Conference on Discovery Science, pages 3–18. Springer, 2024
work page 2024
-
[2]
Generalized random forests.Ann
Susan Athey, Julie Tibshirani, and Stefan Wager. Generalized random forests.Ann. Statist., 47(2): 1148–1178, 2019
work page 2019
-
[3]
Peter L. Bartlett, Peter J. Bickel, Peter Bühlmann, Yoav Freund, Jerome Friedman, Trevor Hastie, Wenxin Jiang, Michael J. Jordan, Vladimir Koltchinskii, Gábor Lugosi, Jon D. McAuliffe, Ya’acov Ritov, Sa- haran Rosset, Robert E. Schapire, Robert Tibshirani, Nicolas Vayatis, Bin Yu, Tong Zhang, and Ji Zhu. Discussions of boosting papers, and rejoinders.The ...
work page 2004
-
[4]
Interpretable random forests via rule extraction
Clément Bénard, Gérard Biau, Sébastien da Veiga, and Erwan Scornet. Interpretable random forests via rule extraction. InProceedings of The 24th International Conference on Artificial Intelligence and Statistics, pages 937–945, 2021
work page 2021
-
[5]
Clément Bénard, Gérard Biau, Sébastien Da Veiga, and Erwan Scornet. SIRUS: Stable and Interpretable RUle Set for classification.Electronic Journal of Statistics, 15(1):427 – 505, 2021
work page 2021
-
[6]
Representation learning: A review and new perspectives.IEEE Trans
Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A review and new perspectives.IEEE Trans. Pattern Anal. Mach. Intell., 35(8):1798–1828, 2013
work page 2013
-
[7]
Analysis of a random forests model.J
Gérard Biau. Analysis of a random forests model.J. Mach. Learn. Res., 13:1063–1095, 2012
work page 2012
-
[8]
A random forest guided tour.TEST, 25(2):197–227, 2016
Gérard Biau and Erwan Scornet. A random forest guided tour.TEST, 25(2):197–227, 2016
work page 2016
-
[9]
Consistency of random forests and other averaging classifiers.J
Gérard Biau, Luc Devroye, and Gábor Lugosi. Consistency of random forests and other averaging classifiers.J. Mach. Learn. Res., 9(66):2015–2033, 2008
work page 2015
-
[10]
Gérard Biau and Luc Devroye. On the layered nearest neighbour estimate, the bagged nearest neighbour estimate and the random forest method in regression and classification.J. Multivar. Anal., 101(10): 2499–2518, 2010
work page 2010
-
[11]
Gilles Blanchard and Nicole Mücke. Kernel regression, minimax rates and effective dimensionality: Beyond the regular case.Analysis and Applications, 18(4):683–696, 2020
work page 2020
-
[12]
A unified approach to extract interpretable rules from tree ensembles via integer programming.Comput
Lorenzo Bonasera and Emilio Carrizosa. A unified approach to extract interpretable rules from tree ensembles via integer programming.Comput. Oper. Res., 185:107283, 2026
work page 2026
-
[13]
Sérgio Branco, André G Ferreira, and Jorge Cabral. Machine learning in resource-scarce embedded systems, fpgas, and end-devices: A survey.Electronics, 8(11):1289, 2019
work page 2019
-
[14]
Some infinity theory for predictor ensembles
Leo Breiman. Some infinity theory for predictor ensembles. Technical Report 579, Statistics Department, UC Berkeley, 2000
work page 2000
- [15]
-
[16]
Consistency for a simple model of random forests
Leo Breiman. Consistency for a simple model of random forests. Technical Report 670, Statistics Department, UC Berkeley, Berkeley, CA, 2004
work page 2004
-
[17]
Leo Breiman, Jerome Friedman, C. J. Stone, and R. A. Olshen.Classification and Regression Trees. Taylor & Francis, Boca Raton, FL, 1984
work page 1984
-
[18]
Joint leaf-refinement and ensemble pruning through l1 regularization.Data Min
Sebastian Buschjäger and Katharina Morik. Joint leaf-refinement and ensemble pruning through l1 regularization.Data Min. Knowl. Discov., 37(3):1230–1261, 2023
work page 2023
-
[19]
Boosting with the l2 loss.Journal of the American Statistical Association, 98 (462):324–339, 2003
Peter Bühlmann and Bin Yu. Boosting with the l2 loss.Journal of the American Statistical Association, 98 (462):324–339, 2003
work page 2003
-
[20]
A. Caponnetto and E. De Vito. Optimal rates for the regularized least-squares algorithm.Foundations of Computational Mathematics, 7(3):331–368, 2007
work page 2007
-
[21]
Multitask learning.Machine Learning, 28(1):41–75, 1997
Rich Caruana. Multitask learning.Machine Learning, 28(1):41–75, 1997
work page 1997
-
[22]
A U-turn on double descent: Rethinking parameter counting in statistical learning
Alicia Curth, Alan Jeffares, and Mihaela van der Schaar. A U-turn on double descent: Rethinking parameter counting in statistical learning. In37th Conference on Neural Information Processing Systems, 2023
work page 2023
-
[23]
Alex Davies and Zoubin Ghahramani. The random forest kernel and other kernels for big data from random partitions.arXivpreprint, 1402.4293, 2014. 10
-
[24]
Neuralef: Deconstructing kernels by deep neural networks
Zh ijie Deng, Jiaxin Shi, and Jun Zhu. Neuralef: Deconstructing kernels by deep neural networks. In International Conference on Machine Learning, pages 4976–4992. PMLR, 2022
work page 2022
-
[25]
Compressing tree ensembles through level-wise optimization and pruning
Laurens Devos, Timo Martens, Deniz Can Oruc, Wannes Meert, Hendrik Blockeel, and Jesse Davis. Compressing tree ensembles through level-wise optimization and pruning. InProceedings of the 42nd International Conference on Machine Learning, pages 13419–13443, 2025
work page 2025
-
[26]
Springer- Verlag, New York, 1996
Luc Devroye, László Györfi, and Gábor Lugosi.A Probabilistic Theory of Pattern Recognition. Springer- Verlag, New York, 1996
work page 1996
-
[27]
UCI machine learning repository, 2019
Dheeru Dua and Casey Graff. UCI machine learning repository, 2019. URL http://archive.ics.uci. edu/ml
work page 2019
-
[28]
The approximation of one matrix by another of lower rank.Psychometrika, 1 (3):211–218, 1936
Carl Eckart and Gale Young. The approximation of one matrix by another of lower rank.Psychometrika, 1 (3):211–218, 1936
work page 1936
-
[29]
Stefan Elfwing, Eiji Uchibe, and Kenji Doya. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning.Neural Networks, 107:3–11, 2018
work page 2018
-
[30]
Jerome H. Friedman and Bogdan E. Popescu. Predictive learning via rule ensembles.The Annals of Applied Statistics, 2(3):916 – 954, 2008
work page 2008
-
[31]
Distilling a neural network into a soft decision tree.arXivpreprint, 1711.09784, 2017
Nicholas Frosst and Geoffrey Hinton. Distilling a neural network into a soft decision tree.arXivpreprint, 1711.09784, 2017
-
[32]
Towards convergence rate analysis of random forests for classification
Wei Gao and Zhi-Hua Zhou. Towards convergence rate analysis of random forests for classification. In Advances in Neural Information Processing Systems, volume 33, 2020
work page 2020
-
[33]
Towards convergence rate analysis of random forests for classification
Wei Gao, Fan Xu, and Zhi-Hua Zhou. Towards convergence rate analysis of random forests for classification. Artificial Intelligence, 313:103788, 2022
work page 2022
-
[34]
Variance reduction in purely random forests.J
Robin Genuer. Variance reduction in purely random forests.J. Nonparametr. Stat., 24(3):543–562, 2012
work page 2012
-
[35]
Leo Grinsztajn, Edouard Oyallon, and Gael Varoquaux. Why do tree-based models still outperform deep learning on typical tabular data? In36th Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2022
work page 2022
-
[36]
The MIT Press, Cambridge, MA, 2007
Peter Grünwald.The minimum description length principle. The MIT Press, Cambridge, MA, 2007
work page 2007
-
[37]
Cambridge University Press, Cambridge, 2022
Venkatesan Guruswami, Atri Rudra, and Madhu Sudan.Essential Coding Theory. Cambridge University Press, Cambridge, 2022
work page 2022
-
[38]
Springer-Verlag, New York, 2002
László Györfi, Michael Kohler, Adam Krzy˙zak, and Harro Walk.A Distribution-Free Theory of Nonpara- metric Regression. Springer-Verlag, New York, 2002
work page 2002
-
[39]
Nathan Halko, Per-Gunnar Martinsson, and Joel A. Tropp. Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions.SIAM Review, 53(2):217–288, 2011
work page 2011
-
[40]
Trevor Hastie and Robert Tibshirani.Generalized additive models. Chapman & Hall, London, 1990
work page 1990
-
[41]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint, 1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[42]
Hutter.Universal Artificial Intelligence: Sequential Decisions Based on Algorithmic Probability
M. Hutter.Universal Artificial Intelligence: Sequential Decisions Based on Algorithmic Probability. Springer Berlin Heidelberg, Berlin, 2004
work page 2004
-
[43]
Stuckey, and Joao Marques-Silva
Alexey Ignatiev, Yacine Izza, Peter J. Stuckey, and Joao Marques-Silva. Using MaxSAT for efficient explanations of tree ensembles. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 3776–3785, 2022
work page 2022
-
[44]
On explaining random forests with sat
Yacine Izza and Joao Marques-Silva. On explaining random forests with sat. InProceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, pages 2584–2591, 2021
work page 2021
-
[45]
Sharp analysis of a simple model for random forests
Jason Klusowski. Sharp analysis of a simple model for random forests. InProceedings of The 24th International Conference on Artificial Intelligence and Statistics, pages 757–765, 2021
work page 2021
-
[46]
Jason M. Klusowski and Peter M. Tian. Large scale prediction with decision trees.Journal of the American Statistical Association, 119(545):525–537, 2024. 11
work page 2024
-
[47]
Mondrian forests: Efficient online random forests
Balaji Lakshminarayanan, Daniel M Roy, and Yee Whye Teh. Mondrian forests: Efficient online random forests. InAdvances in Neural Information Processing Systems, volume 27, 2014
work page 2014
-
[48]
Kaiqiao Li, Sijie Yao, Zhenyu Zhang, Biwei Cao, Christopher M Wilson, Denise Kalos, Pei Fen Kuan, Ruoqing Zhu, and Xuefeng Wang. Efficient gradient boosting for prognostic biomarker discovery.Bioin- formatics, 38(6):1631–1638, 2022
work page 2022
-
[49]
Random forests and adaptive nearest neighbors.J
Yi Lin and Yongho Jeon. Random forests and adaptive nearest neighbors.J. Am. Stat. Assoc., 101(474): 578–590, 2006
work page 2006
-
[50]
Forestprune: Compact depth-pruned tree ensembles
Brian Liu and Rahul Mazumder. Forestprune: Compact depth-pruned tree ensembles. InProceedings of The 26th International Conference on Artificial Intelligence and Statistics, pages 9417–9428, 2023
work page 2023
-
[51]
Fire: An optimization approach for fast interpretable rule extraction
Brian Liu and Rahul Mazumder. Fire: An optimization approach for fast interpretable rule extraction. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 1396–1405, 2023
work page 2023
-
[52]
Brian Liu, Rahul Mazumder, and Peter Radchenko. Extracting interpretable models from tree ensembles: Computational and statistical perspectives.Journal of the American Statistical Association, 0:1–25, 2026
work page 2026
-
[53]
Lorenzen, Christian Igel, and Yevgeny Seldin
Stephan S. Lorenzen, Christian Igel, and Yevgeny Seldin. On pac-bayesian bounds for random forests. Machine Learning, 108(8):1503–1522, 2019
work page 2019
-
[54]
Nicolai Meinshausen. Quantile regression forests.J. Mach. Learn. Res., 7:983–999, 2006
work page 2006
-
[55]
Node harvest.The Annals of Applied Statistics, 4(4):2049–2072, 2010
Nicolai Meinshausen. Node harvest.The Annals of Applied Statistics, 4(4):2049–2072, 2010
work page 2049
-
[56]
Universal consistency and minimax rates for online mondrian forests
Jaouad Mourtada, Stéphane Gaïffas, and Erwan Scornet. Universal consistency and minimax rates for online mondrian forests. InAdvances in Neural Information Processing Systems, volume 30, 2017
work page 2017
-
[57]
Minimax optimal rates for Mondrian trees and forests.The Annals of Statistics, 48(4):2253–2276, 2020
Jaouad Mourtada, Stéphane Gaïffas, and Erwan Scornet. Minimax optimal rates for Mondrian trees and forests.The Annals of Statistics, 48(4):2253–2276, 2020
work page 2020
-
[58]
Minimax rates for high-dimensional random tessellation forests
Eliza O’Reilly and Ngoc Mai Tran. Minimax rates for high-dimensional random tessellation forests. Journal of Machine Learning Research, 25(89):1–32, 2024
work page 2024
-
[59]
David Pfau, Stig Petersen, Ashish Agarwal, David GT Barrett, and Kimberly L Stachenfeld. Spectral inference networks: Unifying deep and spectral learning.arXiv preprint arXiv:1806.02215, 2018
-
[60]
Inverse learning in hilbert scales.Machine Learning, 112(7): 2469–2499, 2023
Abhishake Rastogi and Peter Mathé. Inverse learning in hilbert scales.Machine Learning, 112(7): 2469–2499, 2023
work page 2023
-
[61]
World Scientific, Singapore, 1989
Jorma Rissanen.Stochastic complexity in statistical inquiry. World Scientific, Singapore, 1989
work page 1989
-
[62]
J Jon Ryu, Xiangxiang Xu, HS Erol, Yuheng Bu, Lizhong Zheng, and Gregory W Wornell. Operator svd with neural networks via nested low-rank approximation.arXiv preprint arXiv:2402.03655, 2024
-
[63]
Schapire and Yoav Freund.Boosting: Foundations and Algorithms
Robert E. Schapire and Yoav Freund.Boosting: Foundations and Algorithms. The MIT Press, Cambridge, MA, 2012
work page 2012
-
[64]
On the asymptotics of random forests.J
Erwan Scornet. On the asymptotics of random forests.J. Multivar. Anal., 146:72–83, 2016
work page 2016
-
[65]
Random forests and kernel methods.IEEE Trans
Erwan Scornet. Random forests and kernel methods.IEEE Trans. Inf. Theory, 62(3):1485–1500, 2016
work page 2016
-
[66]
Theory of Random Forests: A Review
Erwan Scornet and Giles Hooker. Theory of Random Forests: A Review. Technical Report, HAL, 2025
work page 2025
-
[67]
Consistency of random forests.Ann
Erwan Scornet, Gerard Biau, and Jean Philippe Vert. Consistency of random forests.Ann. Statist., 43(4): 1716–1741, 2015
work page 2015
-
[68]
Shahab Shoar, Nicholas Chileshe, and John David Edwards. Machine learning-aided engineering services’ cost overruns prediction in high-rise residential building projects: Application of random forest regression. Journal of Building Engineering, 50:104102, 2022
work page 2022
-
[69]
Tabular data: Deep learning is not all you need.Inf
Ravid Shwartz-Ziv and Amitai Armon. Tabular data: Deep learning is not all you need.Inf. Fusion, 81: 84–90, 2022
work page 2022
-
[70]
Charles J Stone. Optimal global rates of convergence for nonparametric regression.The Annals of Statistics, 10:1040–1053, 1982
work page 1982
-
[71]
Springer Berlin Heidelberg, Berlin, Heidelberg, 2009
Grigorios Tsoumakas, Ioannis Partalas, and Ioannis Vlahavas.An Ensemble Pruning Primer, pages 1–13. Springer Berlin Heidelberg, Berlin, Heidelberg, 2009. 12
work page 2009
-
[72]
Alexandre Tsybakov.Introduction to Nonparametric Estimation. Springer, New York, 2008
work page 2008
-
[73]
van Rijn, Bernd Bischl, and Luis Torgo
Joaquin Vanschoren, Jan N. van Rijn, Bernd Bischl, and Luis Torgo. OpenML: networked science in machine learning.ACM SIGKDD Explorations Newsletter, 15(2):49–60, 2013
work page 2013
-
[74]
Thibaut Vidal and Maximilian Schiffer. Born-again tree ensembles. InInternational conference on machine learning, pages 9743–9753. PMLR, 2020
work page 2020
-
[75]
Binh Vu, Jan Kapar, Marvin Wright, and David Watson. Autoencoding random forests. 2025
work page 2025
-
[76]
Estimation and inference of heterogeneous treatment effects using random forests.J
Stefan Wager and Susan Athey. Estimation and inference of heterogeneous treatment effects using random forests.J. Am. Stat. Assoc., 113(523):1228–1242, 2018
work page 2018
-
[77]
Christopher K. I. Williams and Matthias Seeger. Using the nyström method to speed up kernel machines. InAdvances in Neural Information Processing Systems (NeurIPS), 2001
work page 2001
-
[78]
Seungmin Yoo and Chanyoung Oh. Microforest: Lightweight bottleneck prediction for manufacturing processes on edge devices.Applied Sciences, 15(14):7798, 2025
work page 2025
-
[79]
Minimax rates for learning kernels in operators.arXivpreprint, 2502.20368, 2025
Sichong Zhang, Xiong Wang, and Fei Lu. Minimax rates for learning kernels in operators.arXivpreprint, 2502.20368, 2025
-
[80]
Interpreting models via single tree approximation.arXiv preprint arXiv:1610.09036, 2016
Yichen Zhou and Giles Hooker. Interpreting models via single tree approximation.arXiv preprint arXiv:1610.09036, 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.