Recognition: no theorem link
Improving the Performance and Learning Stability of Parallelizable RNNs Designed for Ultra-Low Power Applications
Pith reviewed 2026-05-13 06:28 UTC · model grok-4.3
The pith
The cumulative update formulation in CMRU and αCMRU restores gradient flow while preserving bistable memory for ultra-low power RNNs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that introducing a cumulative formulation for state updates in the Bistable Memory Recurrent Unit creates the Cumulative Memory Recurrent Unit (CMRU) and its αCMRU variant, which restore gradient flow through time via skip connections, improve convergence stability and initialization robustness, and achieve competitive or superior results to LRUs and minGRUs on benchmarks while retaining the quantized states, persistent memory, and noise-resilient dynamics required for analog implementation.
What carries the argument
The cumulative update formulation that accumulates increments to produce skip-connections through time in the bistable recurrent dynamics.
If this is right
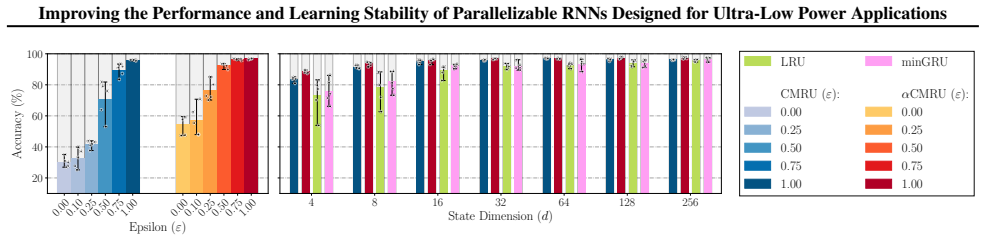
- The cumulative formulation dramatically improves convergence stability and reduces initialization sensitivity.
- CMRU and αCMRU match or outperform LRUs and minGRUs across diverse benchmarks at small model sizes.
- Advantages are pronounced on tasks requiring discrete long-range retention.
- CMRU retains quantized states, persistent memory, and noise-resilient dynamics essential for analog implementation.
Where Pith is reading between the lines
- This method could apply to other recurrent units to enhance trainability under hardware constraints.
- Direct analog mapping of the preserved dynamics might enable ultra-low power chips for real-time sequence processing.
- Stability gains may support training on longer sequences or with fewer examples.
- Extensions to hybrid digital-analog systems could be tested for further power reductions.
Load-bearing premise
That the cumulative update formulation preserves the quantized states with hysteresis, persistent memory, and noise-resilient dynamics required for direct analog hardware mapping while restoring gradient flow.
What would settle it
A training run on a long-range dependency benchmark where the CMRU shows no improvement in retention accuracy over long distances or exhibits vanishing gradients during backpropagation would falsify the central claim.
Figures






read the original abstract
Sequence learning is dominated by Transformers and parallelizable recurrent neural networks (RNNs) such as state-space models, yet learning long-term dependencies remains challenging, and state-of-the-art designs trade power consumption for performance. The Bistable Memory Recurrent Unit (BMRU) was introduced to enable hardware-software co-design of ultra-low power RNNs: quantized states with hysteresis provide persistent memory while mapping directly to analog primitives. However, BMRU performance lags behind parallelizable RNNs on complex sequential tasks. In this paper, we identify gradient blocking during state updates as a key limitation and propose a cumulative update formulation that restores gradient flow while preserving persistent memory, creating skip-connections through time. This leads to the Cumulative Memory Recurrent Unit (CMRU) and its relaxed variant, the $\alpha$CMRU. Experiments show that the cumulative formulation dramatically improves convergence stability and reduces initialization sensitivity. The CMRU and $\alpha$CMRU match or outperform Linear Recurrent Units (LRUs) and minimal Gated Recurrent Units (minGRUs) across diverse benchmarks at small model sizes, with particular advantages on tasks requiring discrete long-range retention, while the CMRU retains quantized states, persistent memory, and noise-resilient dynamics essential for analog implementation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Cumulative Memory Recurrent Unit (CMRU) and its relaxed variant αCMRU as modifications to the Bistable Memory Recurrent Unit (BMRU). It identifies gradient blocking in BMRU state updates as a limitation and proposes a cumulative formulation that creates skip connections through time to restore gradient flow. The central claims are dramatically improved convergence stability, reduced initialization sensitivity, competitive or superior performance versus LRUs and minGRUs on diverse benchmarks at small sizes (especially discrete long-range retention tasks), and retention of quantized states, hysteresis, persistent memory, and noise resilience for direct analog hardware mapping.
Significance. If the invariance of the bistable properties under the cumulative update is established, the work would meaningfully advance hardware-software co-design for ultra-low-power sequence models by delivering improved digital-task performance without sacrificing the analog-primitive mapping advantages of BMRU. This addresses a key power-performance tradeoff in edge-deployed RNNs.
major comments (1)
- [Abstract] Abstract: the claim that CMRU 'retains quantized states, persistent memory, and noise-resilient dynamics essential for analog implementation' is load-bearing for the hardware co-design motivation, yet the manuscript supplies neither a fixed-point analysis nor a derivation showing that the cumulative update leaves the hysteresis loop, bistable equilibria, and noise tolerance unchanged from BMRU.
minor comments (2)
- [Abstract] Abstract and experiments: no error bars, dataset sizes, or ablation isolating the cumulative update are reported, which weakens verification of the 'dramatically improves convergence stability' claim.
- The manuscript should clarify the precise recurrence equation for the cumulative update (including how the skip connection is implemented) to allow reproduction of the gradient-flow restoration.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the concern regarding the preservation of bistable properties by adding the requested analysis in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that CMRU 'retains quantized states, persistent memory, and noise-resilient dynamics essential for analog implementation' is load-bearing for the hardware co-design motivation, yet the manuscript supplies neither a fixed-point analysis nor a derivation showing that the cumulative update leaves the hysteresis loop, bistable equilibria, and noise tolerance unchanged from BMRU.
Authors: We agree that an explicit fixed-point analysis is needed to rigorously support the claim. In the revised manuscript we will add a derivation (as a new subsection in Section 3) showing that the CMRU equilibria coincide exactly with those of the BMRU: the cumulative formulation can be rewritten as a state-dependent skip connection that does not alter the quantization thresholds or the locations of the stable fixed points, thereby leaving the hysteresis loop and noise-resilience properties unchanged. This analysis directly substantiates the abstract claim while preserving the hardware-mapping advantages. revision: yes
Circularity Check
No significant circularity; claims rest on external benchmarks and stated assumptions
full rationale
The paper identifies gradient blocking in BMRU as a limitation, proposes cumulative update to restore flow while claiming preservation of quantized states/hysteresis, and validates via digital benchmarks against LRU/minGRU. No equations reduce a prediction to a fitted input by construction, no load-bearing self-citation chain, and no ansatz or uniqueness theorem imported from prior self-work. Performance results are independent of the preservation claim, which is presented as a design property rather than a derived result equivalent to the input. This is the common case of a self-contained proposal with external validation.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard backpropagation through time enables gradient-based training of recurrent models
invented entities (2)
-
CMRU
no independent evidence
-
αCMRU
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
International Conference on Learning Representations , year=
Efficiently Modeling Long Sequences with Structured State Spaces , author=. International Conference on Learning Representations , year=
-
[3]
Tri Dao and Albert Gu , booktitle=. Transformers are. 2024 , organization=
work page 2024
-
[4]
International Conference on Machine Learning , pages=
Resurrecting Recurrent Neural Networks for Long Sequences , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[5]
Advances in Neural Information Processing Systems , volume=
Attention Is All You Need , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
Gray, Robert M. and Neuhoff, David L. , journal=. Quantization , year=
-
[7]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[8]
International Conference on Machine Learning , pages=
Language Modeling with Gated Convolutional Networks , author=. International Conference on Machine Learning , pages=. 2017 , organization=
work page 2017
- [9]
- [10]
-
[11]
IEEE Transactions on Neural Networks , volume=
Bengio, Yoshua and Simard, Patrice and Frasconi, Paolo , title=. IEEE Transactions on Neural Networks , volume=. 1994 , doi=
work page 1994
-
[12]
A Simple Way to Initialize Recurrent Networks of Rectified Linear Units , author=. 2015 , eprint=
work page 2015
-
[13]
Albert Gu and Tri Dao and Stefano Ermon and Atri Rudra and Christopher R\'e , booktitle=
-
[14]
International Conference on Machine Learning , pages=
On the difficulty of training Recurrent Neural Networks , author=. International Conference on Machine Learning , pages=. 2013 , organization=
work page 2013
-
[15]
Advances in Neural Information Processing Systems , editor=
Voelker, Aaron and Kaji\'. Advances in Neural Information Processing Systems , editor=
-
[16]
International Conference on Machine Learning , pages=
Unitary Evolution Recurrent Neural Networks , author=. International Conference on Machine Learning , pages=. 2016 , organization=
work page 2016
-
[17]
Advances in Neural Information Processing Systems , volume=
Full-Capacity Unitary Recurrent Neural Networks , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Orthogonal Recurrent Neural Networks with Scaled
Kyle Helfrich and Devin Willmott and Qiang Ye , booktitle=. Orthogonal Recurrent Neural Networks with Scaled. 2018 , organization=
work page 2018
-
[19]
International Conference on Machine Learning , pages=
On orthogonality and learning recurrent networks with long term dependencies , author=. International Conference on Machine Learning , pages=. 2017 , organization=
work page 2017
-
[20]
Boyd, Stephen and Chua, Leon O. , journal=. Fading memory and the problem of approximating nonlinear operators with. 1985 , publisher=
work page 1985
-
[21]
International Conference on Learning Representations , year=
Efficiently modeling long sequences with structured state spaces , author=. International Conference on Learning Representations , year=
-
[22]
Advances in Neural Information Processing Systems , volume=
On the parameterization and initialization of diagonal state space models , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
International Conference on Machine Learning , year=
The illusion of state in state-space models , author=. International Conference on Machine Learning , year=
-
[24]
Talathi and Aniket Vartak , year=
Sachin S. Talathi and Aniket Vartak , year=. Improving performance of recurrent neural network with. 1511.03771 , archivePrefix=
-
[25]
International Conference on Machine Learning , pages=
Cheap orthogonality constraints in neural networks: A simple parametrization of the orthogonal and unitary group , author=. International Conference on Machine Learning , pages=. 2019 , organization=
work page 2019
-
[26]
Long short-term memory , author=. Neural Computation , volume=. 1997 , publisher=
work page 1997
-
[27]
Learning phrase representations using
Cho, Kyunghyun and Van Merri. Learning phrase representations using. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
work page 2014
- [28]
-
[29]
IEEE Signal Processing Magazine , volume=
Surrogate gradient learning in spiking neural networks: Bringing the power of gradient-based optimization to spiking neural networks , author=. IEEE Signal Processing Magazine , volume=. 2019 , publisher=
work page 2019
-
[30]
Theoretical neuroscience: computational and mathematical modeling of neural systems , author=. 2005 , publisher=
work page 2005
-
[31]
International Conference on Learning Representations , year=
Simplified state space layers for sequence modeling , author=. International Conference on Learning Representations , year=
-
[32]
A bio-inspired bistable recurrent cell allows for long-lasting memory , author=. PLoS ONE , volume=. 2021 , publisher=
work page 2021
-
[33]
Warming up recurrent neural networks to maximise reachable multistability greatly improves learning , author=. Neural Networks , volume=. 2023 , publisher=
work page 2023
-
[34]
International Conference on Learning Representations , year=
Long Range Arena: A Benchmark for Efficient Transformers , author=. International Conference on Learning Representations , year=
-
[35]
Overcoming the vanishing gradient problem in plain recurrent networks , author=. 2019 , eprint=
work page 2019
-
[36]
Unlocking State-Tracking in Linear
Riccardo Grazzi and Julien Siems and Arber Zela and J. Unlocking State-Tracking in Linear. International Conference on Learning Representations , year=
-
[37]
A Fully Tunable Ultra-Low Power Current-Mode Memory Cell in Standard CMOS Technology , author=. 2026 , eprint=
work page 2026
- [38]
-
[39]
Hardware-Software Co-Design of Scalable, Energy-Efficient Analog Recurrent Computations , author=. 2026 , note=
work page 2026
-
[40]
On the Importance of Multistability for Horizon Generalization in Reinforcement Learning , author=. 2026 , note=
work page 2026
-
[41]
Advances in Neural Information Processing Systems , volume=
Combining Recurrent, Convolutional, and Continuous-time Models with Linear State-Space Layers , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
Parallelizing Linear Recurrent Neural Nets Over Sequence Length , author=. 2018 , eprint=
work page 2018
- [43]
-
[44]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
Simple Recurrent Units for Highly Parallelizable Recurrence , author=. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=. 2018 , publisher=
work page 2018
-
[45]
Maximilian Beck and Korbinian P. x. Advances in Neural Information Processing Systems , volume=
-
[46]
Advances in Neural Information Processing Systems , volume=
Hierarchically Gated Recurrent Neural Network for Sequence Modeling , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
Scalable matmul-free language modeling,
Rui-Jie Zhu and Yu Zhang and Steven Abreu and Ethan Sifferman and Tyler Sheaves and Yiqiao Wang and Dustin Richmond and Sumit Bam Shrestha and Peng Zhou and Jason K. Eshraghian , year=. Scalable. 2406.02528 , archivePrefix=
-
[48]
Proceedings of the IEEE , volume=
Gradient-based learning applied to document recognition , author=. Proceedings of the IEEE , volume=. 1998 , publisher=
work page 1998
-
[49]
Krizhevsky, Alex and Hinton, Geoffrey , title=
-
[50]
Maas, Andrew L. and Daly, Raymond E. and Pham, Peter T. and Huang, Dan and Ng, Andrew Y. and Potts, Christopher , title=. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , month=. 2011 , address=
work page 2011
-
[51]
Nikita Nangia and Samuel R. Bowman , booktitle=. 2018 , publisher=
work page 2018
-
[52]
librosa/librosa: 0.11.0 , month=
McFee, Brian and Matt McVicar and Daniel Faronbi and Iran Roman and Matan Gover and Stefan Balke and Scott Seyfarth and Ayoub Malek and Colin Raffel and Vincent Lostanlen and Benjamin van Niekirk and Dana Lee and Frank Cwitkowitz and Frank Zalkow and Oriol Nieto and Dan Ellis and Jack Mason and Kyungyun Lee and Bea Steers and Emily Halvachs and Carl Thom....
-
[53]
Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition , author=. 2018 , eprint=
work page 2018
-
[54]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Deep Reinforcement Learning that Matters , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[55]
Proceedings of Machine Learning and Systems , volume=
Accounting for Variance in Machine Learning Benchmarks , author=. Proceedings of Machine Learning and Systems , volume=
-
[56]
Tiny Machine Learning and On-Device Inference: A Survey of Applications, Challenges, and Future Directions , author=. Sensors , volume=. 2025 , doi=
work page 2025
-
[57]
Banbury, Colby and Reddi, Vijay Janapa and Torelli, Peter and Holleman, Jeremy and Jeffries, Nat and Kiraly, Csaba and Montino, Pietro and Kanter, David and Ahmed, Sebastian and Pau, Danilo and others , booktitle=
-
[58]
Warden, Pete and Situnayake, Daniel , year=
-
[59]
and Mattina, Matthew and Whatmough, Paul N
Fedorov, Igor and Adams, Ryan P. and Mattina, Matthew and Whatmough, Paul N. , booktitle=. 2019 , address=
work page 2019
-
[60]
Recurrent Neural Networks Hardware Implementation on
Chang, Andre Xian Ming and Martini, Berin and Culurciello, Eugenio , year=. Recurrent Neural Networks Hardware Implementation on. 1511.05552 , archivePrefix=
-
[61]
Sebastian Billaudelle and Laura Kriener and Filippo Moro and Tristan Torchet and Melika Payvand , year=. 2505.08599 , archivePrefix=
-
[62]
James Bradbury and Roy Frostig and Peter Hawkins and Matthew James Johnson and Chris Leary and Dougal Maclaurin and George Necula and Adam Paszke and Jake VanderPlas and Skye Wanderman-Milne and Qiao Zhang , title=
-
[63]
Jonathan Heek and Anselm Levskaya and Avital Oliver and Marvin Ritter and Bertrand Rondepierre and Andreas Steiner and Marc van Zee , title=
-
[64]
McMahan, Brendan and Moore, Eider and Ramage, Daniel and Hampson, Seth and Arcas, Blaise Aguera y , booktitle =. 2017 , editor =
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.