Recognition: 2 theorem links
· Lean TheoremVariance-aware Reward Modeling with Anchor Guidance
Pith reviewed 2026-05-13 05:05 UTC · model grok-4.3
The pith
Two coarse response-level anchors suffice to identify both mean and variance in Gaussian reward models from pairwise preferences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
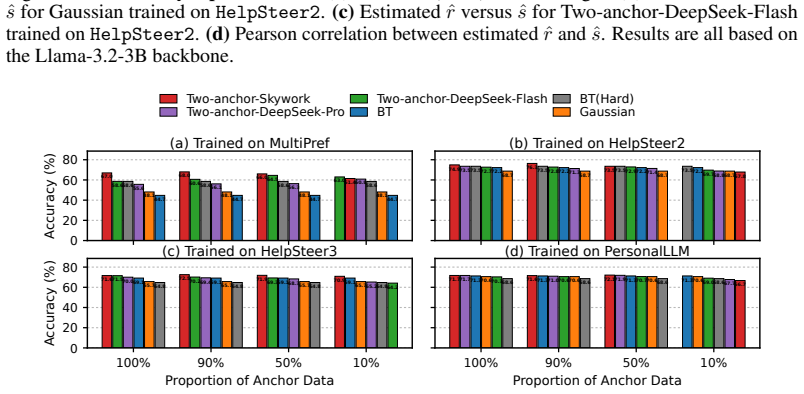
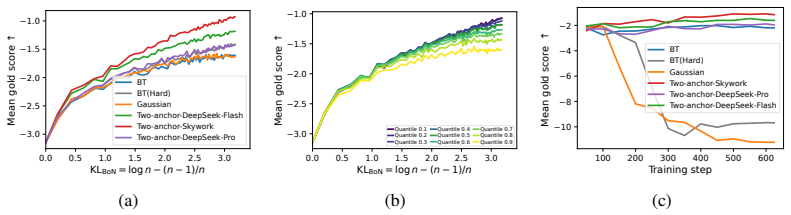
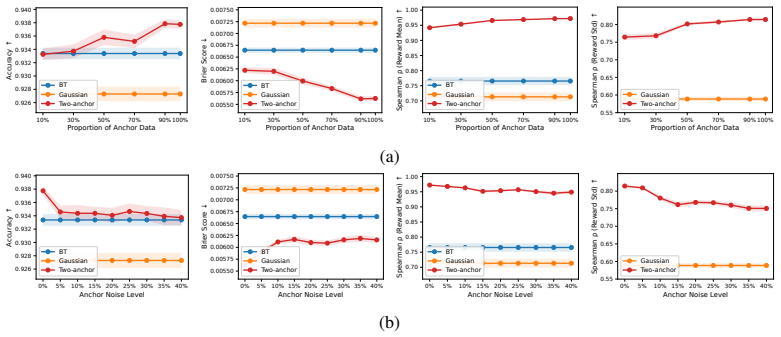
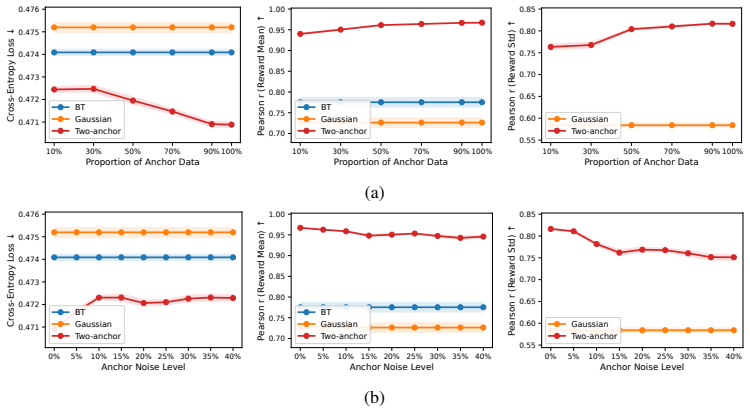
Anchor-guided Variance-aware Reward Modeling augments standard pairwise preference data with two coarse response-level anchor labels. This augmentation renders the joint mean-and-variance estimation problem identifiable, supports a joint training objective, and yields non-asymptotic convergence guarantees for both the mean and variance estimators. The framework is shown to outperform standard Bradley-Terry and unanchored Gaussian baselines on simulation studies and on four real-world diverging-preference datasets, with corresponding gains in PPO and best-of-N RLHF pipelines.
What carries the argument
Anchor-guided augmentation that supplies two coarse response-level labels to break the non-identifiability of Gaussian mean-variance reward models trained on pairwise preferences.
If this is right
- Reward models can now preserve disagreement information instead of shrinking margins.
- Joint mean-variance estimation becomes statistically consistent with explicit convergence rates.
- Downstream RLHF procedures such as PPO and best-of-N selection receive higher-quality reward signals on pluralistic data.
- The same two-anchor construction applies directly to any dataset already equipped with coarse response-level annotations.
Where Pith is reading between the lines
- The identification argument may extend to other non-identifiable preference-learning problems once a small number of cheap auxiliary labels are introduced.
- Data-collection protocols could be redesigned to request only two coarse anchors per response rather than dense preference annotations.
- The convergence rates supply a concrete sample-complexity target for scaling variance-aware models to larger preference corpora.
Load-bearing premise
Two coarse response-level anchor labels can be obtained reliably and contain enough information to separate mean from variance without adding new biases.
What would settle it
A controlled simulation in which the true reward variance is known shows that the estimated variance function remains unidentifiable or fails to converge at the stated rate even after the two-anchor labels are added.
Figures

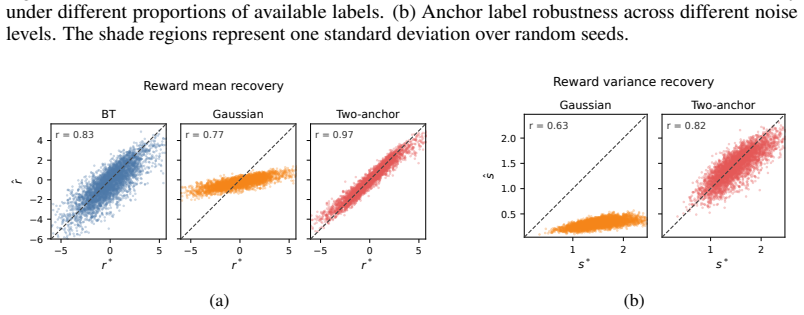



read the original abstract
Standard Bradley--Terry (BT) reward models are limited when human preferences are pluralistic. Although soft preference labels preserve disagreement information, BT can only express it by shrinking reward margins. Gaussian reward models provide an alternative by jointly predicting a reward mean and a reward variance, but suffer from a fundamental non-identifiability from pairwise preferences alone. We propose Anchor-guided Variance-aware Reward Modeling, a framework that resolves this non-identifiability by augmenting preference data with two coarse response-level anchor labels. Building on this, we prove that two anchors are sufficient for identification, develop a joint training objective and establish a non-asymptotic convergence rate for both the estimated reward mean and variance functions. Across simulation studies and four real-world diverging-preference datasets, our method consistently improves reward modeling performance and downstream RLHF, including PPO training and best-of-$N$ selection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Anchor-guided Variance-aware Reward Modeling (AVRM) to address non-identifiability in Gaussian reward models trained solely on pairwise preferences. By augmenting data with two coarse response-level anchor labels, the authors prove that two anchors suffice for identification of both reward mean and variance, introduce a joint training objective, derive non-asymptotic convergence rates for the estimators, and report improved performance on synthetic simulations plus four real-world diverging-preference datasets for reward modeling and downstream RLHF tasks (PPO training and best-of-N selection).
Significance. If the identification result and convergence rates hold under the stated assumptions, the work supplies a minimal, practical augmentation that resolves a known limitation of variance-aware models without requiring strong parametric assumptions on preferences. The non-asymptotic rates and joint objective provide theoretical grounding, while the empirical gains on pluralistic datasets suggest utility for more robust RLHF. This could encourage wider adoption of uncertainty-aware reward models when human disagreement is present.
minor comments (3)
- [Abstract] Abstract: the four real-world datasets are not named, which reduces immediate clarity for readers scanning the contribution.
- [§4] §4 (Experiments): the simulation setup for verifying non-asymptotic rates would benefit from explicit parameter values and seed details to support reproducibility of the reported convergence behavior.
- [Related Work] Related Work: a brief comparison to prior approaches that mitigate non-identifiability via multiple annotators or richer preference data is absent, which would better situate the two-anchor contribution.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our manuscript on Anchor-guided Variance-aware Reward Modeling (AVRM) and for recommending minor revision. The referee's description accurately captures the identification result, joint objective, convergence rates, and empirical improvements on pluralistic preference datasets. Since the report lists no major comments, we have no specific points to address point-by-point at this stage.
Circularity Check
No significant circularity detected
full rationale
The paper's derivation proceeds from a standard Gaussian reward model with pairwise preferences (known to be non-identifiable), augments it with two external coarse anchor labels, proves identifiability from that augmented data, constructs a joint objective, and derives non-asymptotic rates under stated assumptions. None of these steps reduce by construction to fitted parameters, self-referential definitions, or load-bearing self-citations; the identification argument and rates are presented as consequences of the augmented model rather than renamings or ansatzes imported from prior author work. The central claims therefore retain independent mathematical content.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard regularity conditions for non-asymptotic convergence rates in statistical estimation
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearProposition 2 (Identifiability under two anchors). ... two distinct anchor thresholds are sufficient to identify the function pair (rϕ,sϕ).
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearTheorem 1 (Non-asymptotic rate for the sieve MLE) ... Op(n−α/(2α+d)min)
Reference graph
Works this paper leans on
-
[1]
the method of paired comparisons , author=
Rank analysis of incomplete block designs: I. the method of paired comparisons , author=. Biometrika , volume=. 1952 , publisher=
work page 1952
- [2]
-
[3]
The Annals of Statistics , pages=
Convergence rate of sieve estimates , author=. The Annals of Statistics , pages=. 1994 , publisher=
work page 1994
-
[4]
Handbook of econometrics , volume=
Large sample sieve estimation of semi-nonparametric models , author=. Handbook of econometrics , volume=. 2007 , publisher=
work page 2007
-
[5]
Journal of econometrics , volume=
Convergence rates and asymptotic normality for series estimators , author=. Journal of econometrics , volume=. 1997 , publisher=
work page 1997
- [6]
-
[7]
Weak Convergence and Empirical Processes , author=. 1996 , publisher=
work page 1996
- [8]
- [9]
-
[10]
Annals of Statistics , volume=
Consistency and asymptotic normality of the maximum likelihood estimator in generalized linear models , author=. Annals of Statistics , volume=
- [11]
- [12]
-
[13]
The annals of statistics , pages=
Optimal global rates of convergence for nonparametric regression , author=. The annals of statistics , pages=. 1982 , publisher=
work page 1982
-
[14]
International Conference on Machine Learning , pages=
Principled reinforcement learning with human feedback from pairwise or k-wise comparisons , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[15]
International Conference on Artificial Intelligence and Statistics , pages=
Faithful heteroscedastic regression with neural networks , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2023 , organization=
work page 2023
-
[16]
arXiv preprint arXiv:2203.09168 , year=
On the pitfalls of heteroscedastic uncertainty estimation with probabilistic neural networks , author=. arXiv preprint arXiv:2203.09168 , year=
-
[17]
Advances in Neural Information Processing Systems , volume=
Reliable training and estimation of variance networks , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Pairwise Calibrated Rewards for Pluralistic Alignment , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[19]
Forty-first International Conference on Machine Learning , year=
Position: A Roadmap to Pluralistic Alignment , author=. Forty-first International Conference on Machine Learning , year=
-
[20]
Hybrid preferences: Learning to route instances for human vs. AI feedback , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[21]
The Thirteenth International Conference on Learning Representations , year=
HelpSteer2-Preference: Complementing Ratings with Preferences , author=. The Thirteenth International Conference on Learning Representations , year=
-
[22]
HelpSteer3-Preference: Open Human-Annotated Preference Data across Diverse Tasks and Languages , author=. 2025 , eprint=
work page 2025
- [23]
-
[24]
Gonzalez and Ion Stoica , booktitle=
Evan Frick and Tianle Li and Connor Chen and Wei-Lin Chiang and Anastasios Nikolas Angelopoulos and Jiantao Jiao and Banghua Zhu and Joseph E. Gonzalez and Ion Stoica , booktitle=. How to Evaluate Reward Models for. 2025 , url=
work page 2025
-
[25]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Rewardbench: Evaluating reward models for language modeling , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
work page 2025
-
[26]
The Fourteenth International Conference on Learning Representations , year=
Bradley-Terry and Multi-Objective Reward Modeling Are Complementary , author=. The Fourteenth International Conference on Learning Representations , year=
-
[27]
Advances in Neural Information Processing Systems , volume=
Regularizing hidden states enables learning generalizable reward model for llms , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
International Conference on Machine Learning , pages=
Scaling laws for reward model overoptimization , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[29]
Reward model ensembles help mitigate overoptimization.arXiv preprint arXiv:2310.02743, 2023
Reward model ensembles help mitigate overoptimization , author=. arXiv preprint arXiv:2310.02743 , year=
-
[30]
Large language models encode clinical knowledge , author=. Nature , volume=. 2023 , publisher=
work page 2023
-
[31]
Learning and individual differences , volume=
ChatGPT for good? On opportunities and challenges of large language models for education , author=. Learning and individual differences , volume=. 2023 , publisher=
work page 2023
-
[32]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[33]
Journal of machine learning research , volume=
Palm: Scaling language modeling with pathways , author=. Journal of machine learning research , volume=
-
[34]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
A Survey of Large Language Models
A survey of large language models , author=. arXiv preprint arXiv:2303.18223 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Large Language Models: A Survey
Large language models: A survey , author=. arXiv preprint arXiv:2402.06196 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Tulu 3: Pushing frontiers in open language model post-training , author=. arXiv preprint arXiv:2411.15124 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Openrlhf: An easy-to-use, scalable and high-performance rlhf framework , author=. arXiv preprint arXiv:2405.11143 , volume=
-
[39]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[41]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems , pages=
Jury learning: Integrating dissenting voices into machine learning models , author=. Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems , pages=
work page 2022
-
[44]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Value kaleidoscope: Engaging ai with pluralistic human values, rights, and duties , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[45]
The Twelfth International Conference on Learning Representations , year=
Distributional Preference Learning: Understanding and Accounting for Hidden Context in RLHF , author=. The Twelfth International Conference on Learning Representations , year=
-
[46]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Which examples should be multiply annotated? active learning when annotators may disagree , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
work page 2023
-
[47]
arXiv preprint arXiv:2310.16048 , year=
Ai alignment and social choice: Fundamental limitations and policy implications , author=. arXiv preprint arXiv:2310.16048 , year=
-
[48]
International Conference on Machine Learning , pages=
Diverging Preferences: When do Annotators Disagree and do Models Know? , author=. International Conference on Machine Learning , pages=. 2025 , organization=
work page 2025
-
[49]
arXiv preprint arXiv:2502.18770 , year=
Reward shaping to mitigate reward hacking in rlhf , author=. arXiv preprint arXiv:2502.18770 , year=
-
[50]
arXiv preprint arXiv:2503.22480 , year=
Probabilistic uncertain reward model , author=. arXiv preprint arXiv:2503.22480 , year=
-
[51]
Uncertainty- aware reward model: Teaching reward models to know what is unknown, 2025
Uncertainty-aware reward model: Teaching reward models to know what is unknown , author=. arXiv preprint arXiv:2410.00847 , year=
-
[52]
HelpSteer2: Open-source dataset for training top-performing reward models , author=. 2024 , eprint=
work page 2024
-
[53]
Transactions on Machine Learning Research , issn=
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback , author=. Transactions on Machine Learning Research , issn=. 2023 , url=
work page 2023
-
[54]
Forty-second International Conference on Machine Learning , year=
Reward Modeling with Ordinal Feedback: Wisdom of the Crowd , author=. Forty-second International Conference on Machine Learning , year=
-
[55]
Uncertainty Quantification for Large Language Model Reward Learning under Heterogeneous Human Feedback , author=. 2025 , eprint=
work page 2025
-
[56]
The Fourteenth International Conference on Learning Representations , year=
Learning Ordinal Probabilistic Reward from Preferences , author=. The Fourteenth International Conference on Learning Representations , year=
- [57]
-
[58]
High-Dimensional Probability: An Introduction with Applications in Data Science , author=. 2018 , publisher=
work page 2018
-
[59]
arXiv preprint arXiv:2406.08469 , year=
Pal: Pluralistic alignment framework for learning from heterogeneous preferences , author=. arXiv preprint arXiv:2406.08469 , year=
-
[60]
International Conference on Machine Learning , pages=
MaxMin-RLHF: Alignment with Diverse Human Preferences , author=. International Conference on Machine Learning , pages=. 2024 , organization=
work page 2024
-
[61]
The Thirteenth International Conference on Learning Representations , year=
Pal: Sample-efficient personalized reward modeling for pluralistic alignment , author=. The Thirteenth International Conference on Learning Representations , year=
-
[62]
The Fourteenth International Conference on Learning Representations , year=
Swap-guided Preference Learning for Personalized Reinforcement Learning from Human Feedback , author=. The Fourteenth International Conference on Learning Representations , year=
-
[63]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Personalizing Reinforcement Learning from Human Feedback with Variational Preference Learning , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[64]
Distill Not Only Data but Also Rewards: Can Smaller Language Models Surpass Larger Ones? , author=. 2026 , url=
work page 2026
-
[65]
The American Statistician , number=
An overview of large language models for statisticians , author=. The American Statistician , number=. 2026 , publisher=
work page 2026
-
[66]
Reinforcement Learning from Human Feedback: A Statistical Perspective
Reinforcement learning from human feedback: A statistical perspective , author=. arXiv preprint arXiv:2604.02507 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.