Recognition: unknown
Beyond Point-wise Neural Collapse: A Topology-Aware Hierarchical Classifier for Class-Incremental Learning
Pith reviewed 2026-05-13 06:30 UTC · model grok-4.3
The pith
A hierarchical topology-aware classifier outperforms point-based nearest-mean methods in class-incremental learning by modeling feature manifolds and tracking non-linear drift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Class features in incremental settings form complex manifolds rather than collapsed points, so a point-wise nearest class mean classifier is suboptimal. HC-SOINN captures the manifold topology through hierarchical clustering in a local-to-global manner, while STAR uses fine-grained residual trajectories to actively deform that topology and maintain alignment under non-linear feature drift. Procrustes distance analysis and integration experiments confirm that the resulting structure remains stable and improves performance when swapped into state-of-the-art class-incremental pipelines.
What carries the argument
HC-SOINN (Hierarchical-Cluster SOINN), a self-organizing network that builds hierarchical local-to-global topology representations of class manifolds, paired with the STAR residual-based deformation mechanism that tracks pointwise trajectories to adapt the topology to drift.
If this is right
- Replacing the classifier in any existing CIL method with HC-SOINN plus STAR yields measurable accuracy gains while preserving resistance to forgetting.
- The topology representation remains resilient to manifold deformations as measured by Procrustes distance between successive feature distributions.
- The local-to-global hierarchy allows the model to handle both fine-grained within-class structure and global separation across classes added over time.
- STAR's pointwise residual tracking enables precise adaptation to non-linear drift without requiring full retraining of earlier classes.
Where Pith is reading between the lines
- The same hierarchical tracking could be tested in non-classification continual settings such as incremental object detection where spatial manifolds also drift.
- Residual deformation might combine with explicit drift detectors to trigger updates only when manifold misalignment exceeds a threshold.
- If the topology model generalizes, it could reduce reliance on replay buffers by letting the classifier itself encode distribution history.
Load-bearing premise
Class features reliably form complex manifolds that hierarchical clustering can capture and that residual-based deformation can realign without creating new instabilities or extra forgetting.
What would settle it
A controlled CIL experiment on a dataset engineered for extreme non-linear manifold drift in which HC-SOINN plus STAR produces lower accuracy or higher forgetting than a standard nearest class mean classifier.
Figures




read the original abstract
The Nearest Class Mean (NCM) classifier is widely favored in Class-Incremental Learning (CIL) for its superior resistance to catastrophic forgetting compared to Fully Connected layers. While Neural Collapse (NC) theory supports NCM's optimality by assuming features collapse into single points, non-linear feature drift and insufficient training in CIL often prevent this ideal state. Consequently, classes manifest as complex manifolds rather than collapsed points, rendering the single-point NCM suboptimal. To address this, we propose Hierarchical-Cluster SOINN (HC-SOINN), a novel classifier that captures the topological structure of these manifolds via a ``local-to-global'' representation. Furthermore, we introduce Structure-Topology Alignment via Residuals (STAR) method, which employs a fine-grained pointwise trajectory tracking mechanism to actively deform the learned topology, allowing it to adapt precisely to complex non-linear feature drift. Theoretical analysis and Procrustes distance experiments validate our framework's resilience to manifold deformations. We integrated HC-SOINN into seven state-of-the-art methods by replacing their original classifiers, achieving consistent improvements that highlight the effectiveness and robustness of our approach. Code is available at https://github.com/yhyet/HC_SOINN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that in class-incremental learning, non-linear feature drift prevents the ideal point-wise collapse assumed by Neural Collapse theory, so classes form complex manifolds and Nearest Class Mean classifiers become suboptimal. It introduces Hierarchical-Cluster SOINN (HC-SOINN) to capture manifold topology through a local-to-global hierarchical representation and the Structure-Topology Alignment via Residuals (STAR) method, which uses fine-grained pointwise trajectory tracking to deform the learned topology and adapt to drift. Theoretical analysis and Procrustes distance experiments are claimed to validate resilience to deformations, and replacing the classifier in seven existing CIL methods yields consistent empirical gains. Code is released at the provided GitHub link.
Significance. If the central claims hold, the work would offer a practical topology-aware alternative to point-wise classifiers in CIL, potentially improving robustness to non-linear drift while preserving the forgetting resistance that motivates NCM. The explicit code release supports reproducibility and allows direct integration testing.
major comments (3)
- [Abstract / §3] Abstract and §3 (STAR description): the claim that residual-based pointwise trajectory tracking 'actively deforms the learned topology' without introducing instabilities or accelerating forgetting is load-bearing for the no-forgetting guarantee, yet no explicit stability analysis, curvature-mismatch bound, or ablation on post-deformation forgetting metrics is supplied; the skeptic concern that residuals may overfit noise rather than true drift therefore remains unaddressed.
- [§4] §4 (theoretical analysis): the abstract asserts that 'theoretical analysis' validates resilience to manifold deformations, but no equations, proof sketches, or formal statements appear; without these it is impossible to verify whether the local-to-global structure is preserved under the STAR deformation operator.
- [Table 1 / §5.1] Table 1 / §5.1 (integration experiments): while consistent improvements are reported when HC-SOINN+STAR replaces the original classifier in seven SOTA methods, the paper does not isolate the contribution of the residual deformation step versus the hierarchical clustering alone, leaving open whether the topology-alignment mechanism is the source of the gains.
minor comments (2)
- [§3] Notation for the hierarchical clustering levels and residual vectors should be defined once in a dedicated notation table or subsection to avoid repeated inline definitions.
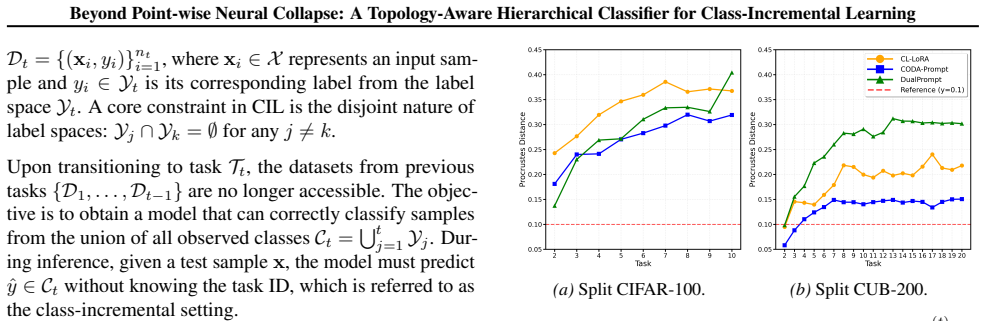
- [§5.2] The Procrustes distance plots in §5.2 would benefit from error bars or multiple random seeds to demonstrate statistical reliability of the reported alignment resilience.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (STAR description): the claim that residual-based pointwise trajectory tracking 'actively deforms the learned topology' without introducing instabilities or accelerating forgetting is load-bearing for the no-forgetting guarantee, yet no explicit stability analysis, curvature-mismatch bound, or ablation on post-deformation forgetting metrics is supplied; the skeptic concern that residuals may overfit noise rather than true drift therefore remains unaddressed.
Authors: We agree that the current version lacks explicit stability analysis to support the deformation claim. In the revision we will expand §3 with a formal bound on residual-induced deformation error (under the assumption of bounded non-linear drift) and add an ablation reporting forgetting metrics before and after STAR application, directly addressing the concern that residuals may fit noise. revision: yes
-
Referee: [§4] §4 (theoretical analysis): the abstract asserts that 'theoretical analysis' validates resilience to manifold deformations, but no equations, proof sketches, or formal statements appear; without these it is impossible to verify whether the local-to-global structure is preserved under the STAR deformation operator.
Authors: We acknowledge the omission of explicit theoretical content in §4. We will add a new subsection containing the formal definition of the STAR deformation operator, the relevant equations, and a proof sketch demonstrating preservation of the local-to-global hierarchical structure under bounded residuals. revision: yes
-
Referee: [Table 1 / §5.1] Table 1 / §5.1 (integration experiments): while consistent improvements are reported when HC-SOINN+STAR replaces the original classifier in seven SOTA methods, the paper does not isolate the contribution of the residual deformation step versus the hierarchical clustering alone, leaving open whether the topology-alignment mechanism is the source of the gains.
Authors: We agree that component isolation is necessary. We will add an ablation study in §5.1 that compares HC-SOINN (hierarchical clustering only) against the full HC-SOINN+STAR on the same benchmarks, thereby quantifying the incremental benefit of the residual-based topology alignment. revision: yes
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A comprehensive study of class incremental learning algorithms for visual tasks , author=. Neural Networks , volume=. 2021 , publisher=
work page 2021
-
[2]
arXiv preprint arXiv:2401.16386 , year=
Continual learning with pre-trained models: A survey , author=. arXiv preprint arXiv:2401.16386 , year=
- [3]
-
[4]
Proceedings of the National Academy of Sciences , volume=
Prevalence of neural collapse during the terminal phase of deep learning training , author=. Proceedings of the National Academy of Sciences , volume=. 2020 , publisher=
work page 2020
-
[5]
Embedding Space Allocation with Angle-Norm Joint Classifiers for few-shot class-incremental learning , author=. Neural Networks , pages=. 2025 , publisher=
work page 2025
-
[6]
2024 International Joint Conference on Neural Networks (IJCNN) , pages=
Few-Shot Class-Incremental Learning with Class Centers and Contrastive Learning for Incremental Vehicle Recognition , author=. 2024 International Joint Conference on Neural Networks (IJCNN) , pages=. 2024 , organization=
work page 2024
-
[7]
International Journal of Computer Vision , volume=
Revisiting class-incremental learning with pre-trained models: Generalizability and adaptivity are all you need , author=. International Journal of Computer Vision , volume=. 2025 , publisher=
work page 2025
-
[8]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Expandable subspace ensemble for pre-trained model-based class-incremental learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[9]
An enhanced self-organizing incremental neural network for online unsupervised learning , author=. Neural Networks , volume=. 2007 , publisher=
work page 2007
-
[10]
Pilot: A pre-trained model-based continual learning toolbox , author=. 2025 , publisher=
work page 2025
-
[11]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Kac: Kolmogorov-arnold classifier for continual learning , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[12]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
CL-LoRA: Continual Low-Rank Adaptation for Rehearsal-Free Class-Incremental Learning , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[13]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Self-expansion of pre-trained models with mixture of adapters for continual learning , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[14]
An incremental network for on-line unsupervised classification and topology learning , author=. Neural networks , volume=. 2006 , publisher=
work page 2006
-
[15]
European Conference on Computer Vision , pages=
Dualprompt: Complementary prompting for rehearsal-free continual learning , author=. European Conference on Computer Vision , pages=. 2022 , organization=
work page 2022
-
[16]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Coda-prompt: Continual decomposed attention-based prompting for rehearsal-free continual learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[17]
arXiv preprint arXiv:2302.03004 , year=
Neural collapse inspired feature-classifier alignment for few-shot class incremental learning , author=. arXiv preprint arXiv:2302.03004 , year=
-
[18]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Semantic drift compensation for class-incremental learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[19]
International conference on machine learning , pages=
Infinite mixture prototypes for few-shot learning , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[20]
European Conference on Computer Vision , pages=
Exemplar-free continual representation learning via learnable drift compensation , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[21]
Local procrustes for manifold embedding: a measure of embedding quality and embedding algorithms , author=. Machine learning , volume=. 2009 , publisher=
work page 2009
-
[22]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Multiple Queries with Multiple Keys: A Precise Prompt Matching Paradigm for Prompt-based Continual Learning , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[23]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Few-shot class-incremental learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[24]
A fast nearest neighbor classifier based on self-organizing incremental neural network , author=. Neural networks , volume=. 2008 , publisher=
work page 2008
-
[25]
Psychology of learning and motivation , volume=
Catastrophic interference in connectionist networks: The sequential learning problem , author=. Psychology of learning and motivation , volume=. 1989 , publisher=
work page 1989
-
[26]
Learning multiple layers of features from tiny images , author=. 2009 , publisher=
work page 2009
-
[27]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
The many faces of robustness: A critical analysis of out-of-distribution generalization , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[28]
The caltech-ucsd birds-200-2011 dataset , author=. 2011 , publisher=
work page 2011
- [29]
-
[30]
Proceedings of the 12th annual conference on Computer graphics and interactive techniques , pages=
Animating rotation with quaternion curves , author=. Proceedings of the 12th annual conference on Computer graphics and interactive techniques , pages=
-
[31]
Hierarchical clustering schemes , author=. Psychometrika , volume=. 1967 , publisher=
work page 1967
-
[32]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Der: Dynamically expandable representation for class incremental learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[33]
European conference on computer vision , pages=
Foster: Feature boosting and compression for class-incremental learning , author=. European conference on computer vision , pages=. 2022 , organization=
work page 2022
-
[34]
arXiv preprint arXiv:2205.13218 (2022)
A model or 603 exemplars: Towards memory-efficient class-incremental learning , author=. arXiv preprint arXiv:2205.13218 , year=
-
[35]
arXiv preprint arXiv:1908.01091 , year=
Toward understanding catastrophic forgetting in continual learning , author=. arXiv preprint arXiv:1908.01091 , year=
-
[36]
2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) , pages=
Advancing Ultrasound Medical Continuous Learning with Task-Specific Generalization and Adaptability , author=. 2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) , pages=. 2024 , organization=
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.