Recognition: 2 theorem links
· Lean TheoremRealDiffusion: Physics-informed Attention for Multi-character Storybook Generation
Pith reviewed 2026-05-13 06:20 UTC · model grok-4.3
The pith
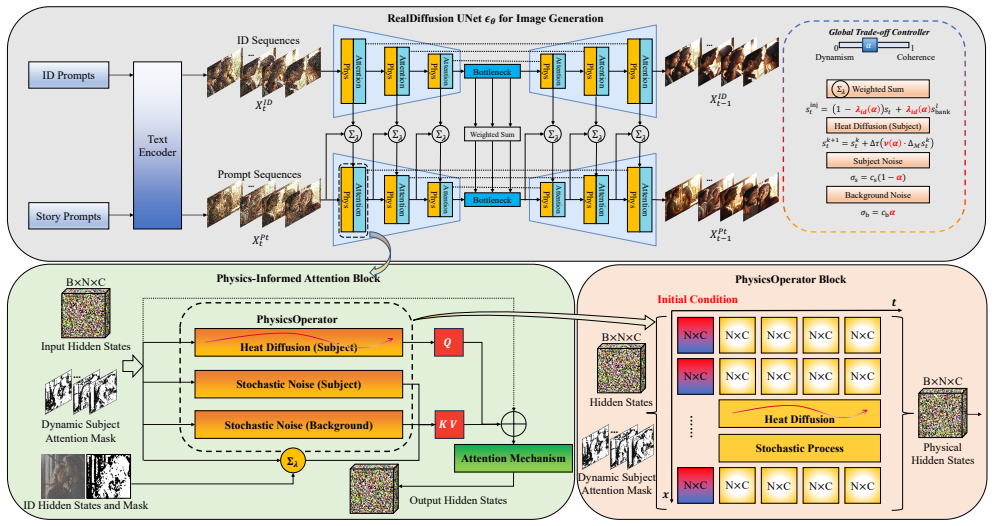
RealDiffusion models attention features as heat diffusion plus stochastic perturbations to keep characters consistent while letting stories evolve.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RealDiffusion reconciles robust character coherence with narrative dynamism by injecting a configurable physical prior into self-attention: heat diffusion averages neighboring features to suppress attribute drift and stabilize identities across frames, while a region-aware stochastic process introduces controlled perturbations that allow pose changes and scene evolution to continue.
What carries the argument
Physics-informed Attention, a training-free modification that treats feature evolution in self-attention layers as a heat-diffusion dissipative prior combined with stochastic perturbations.
If this is right
- Suppresses attribute drift inside subject regions and stabilizes identity across sequential frames.
- Prevents story collapse by allowing small pose and scene changes through stochastic perturbations.
- Regularizes spatio-temporal relationships in attention without suppressing intentional prompt-driven variations.
- Delivers measurable gains in character coherence on multi-character storybook tasks while matching or exceeding prior methods on dynamism.
Where Pith is reading between the lines
- The same diffusion-plus-stochastic prior could be tested on other sequential generation tasks such as comic panels or short video clips.
- Physical analogies of this kind offer a way to add controllable regularization to generative models without retraining or large datasets.
- Longer story sequences might benefit if the heat-diffusion scale is made adaptive to sequence length rather than fixed.
Load-bearing premise
That casting attention features as heat diffusion plus small stochastic noise will reduce unwanted identity drift without blocking prompt-driven story changes or creating new visual artifacts.
What would settle it
Compare generated story sequences with and without the physics-informed attention on the same prompts and measure whether character attributes stay more consistent across frames while narrative elements such as poses and scene actions continue to vary.
Figures





read the original abstract
While modern diffusion models excel at generating diverse single images, extending this to sequential generation reveals a fundamental challenge: balancing narrative dynamism with multi-character coherence. Existing methods often falter at this trade-off, leading to artifacts where characters lose their identity or the story stagnates. To resolve this critical tension, we introduce RealDiffusion, a unified framework designed to reconcile robust coherence with narrative dynamism. Heat diffusion serves as a dissipative prior that averages neighboring features along the sequence and removes high-frequency noise within the subject region. This suppresses attribute drift and stabilizes identity across frames. A region-aware stochastic process then introduces small perturbations that explore nearby modes and prevent collapse so the story maintains pose change and scene evolution. We thus introduce a lightweight, training-free Physics-informed Attention mechanism that injects controllable physical priors into the self-attention layers during inference. By modeling feature evolution as a configurable physical system, our method regularizes spatio-temporal relationships without suppressing intentional, prompt-driven changes. Extensive experiments demonstrate that RealDiffusion achieves substantial gains in character coherence while preserving narrative dynamism, outperforming state-of-the-art approaches. Code is available at https://github.com/ShmilyQi-CN/RealDiffusion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RealDiffusion, a training-free framework that injects a Physics-informed Attention mechanism into the self-attention layers of diffusion models during inference for multi-character storybook generation. Heat diffusion acts as a dissipative prior that averages neighboring features to suppress attribute drift and stabilize identity, while a region-aware stochastic process adds small perturbations to explore modes and preserve prompt-driven pose and scene changes. The central claim is that this configurable physical system regularizes spatio-temporal relationships to achieve substantial gains in character coherence while maintaining narrative dynamism, outperforming state-of-the-art methods.
Significance. If the claimed balance holds under quantitative scrutiny, the work would demonstrate a lightweight, inference-only route for embedding external physical priors into generative models, offering a practical solution to the coherence-dynamism trade-off in sequential image synthesis without retraining. This could influence downstream applications in consistent character animation and story visualization.
major comments (2)
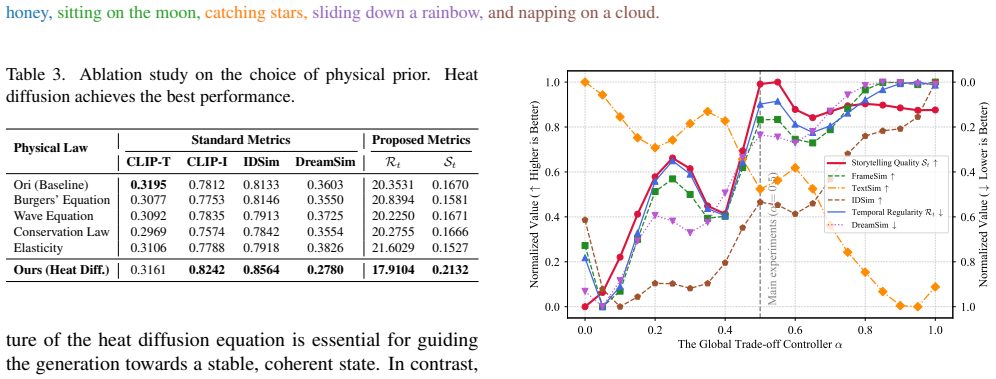
- [Abstract] Abstract: the assertion of 'substantial gains in character coherence' and 'outperforming state-of-the-art approaches' is unsupported by any metrics, baselines, ablation results, or quantitative tables, which directly undermines verification of the central claim.
- [Method] Method description (physics-informed attention): no explicit equations, diffusion coefficients, noise schedules, or parameter values are supplied for the heat-diffusion term or stochastic perturbations, leaving the mechanism for balancing drift suppression against prompt-driven evolution unverified and load-bearing for the reported trade-off.
minor comments (1)
- [Abstract] Abstract: the GitHub link for code availability is a positive step toward reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and have revised the manuscript to improve clarity and verifiability of our claims and method.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of 'substantial gains in character coherence' and 'outperforming state-of-the-art approaches' is unsupported by any metrics, baselines, ablation results, or quantitative tables, which directly undermines verification of the central claim.
Authors: We agree that the abstract would be stronger with explicit quantitative support. The full manuscript contains detailed experiments (Section 4) with metrics for character coherence (e.g., identity preservation scores), narrative dynamism measures, baselines, and ablation tables demonstrating improvements over SOTA methods. We will revise the abstract to include key numerical results, such as average coherence gains and comparisons, to make the central claims immediately verifiable. revision: yes
-
Referee: [Method] Method description (physics-informed attention): no explicit equations, diffusion coefficients, noise schedules, or parameter values are supplied for the heat-diffusion term or stochastic perturbations, leaving the mechanism for balancing drift suppression against prompt-driven evolution unverified and load-bearing for the reported trade-off.
Authors: We appreciate this observation. The method section provides a conceptual description of the physics-informed attention, but we acknowledge the need for explicit formulations. We will add the governing equations for the heat diffusion term (including the diffusion coefficient and discretization scheme), the region-aware stochastic process with its noise schedule, and the specific hyperparameter values used in experiments to fully specify the balance between coherence and dynamism. revision: yes
Circularity Check
No circularity: physical priors introduced as external mechanism without reduction to inputs
full rationale
The paper presents RealDiffusion as a training-free inference-time injection of heat diffusion (as dissipative averaging) plus stochastic perturbations into self-attention layers. No equations, parameter fits, or derivations are shown that reduce the claimed coherence-dynamism balance to a self-defined quantity, fitted input renamed as prediction, or self-citation chain. The physical system is motivated as an external configurable prior rather than derived from the target result itself, and the abstract provides no self-referential steps that would force the outcome by construction. This is the common case of an independent modeling choice whose validity rests on empirical verification rather than definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Heat diffusion acts as a dissipative prior that averages neighboring features and removes high-frequency noise within subject regions.
- domain assumption A region-aware stochastic process can introduce perturbations that explore nearby modes without causing collapse.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Heat diffusion serves as a dissipative prior that averages neighboring features along the sequence... PhysicsOperator... insulated heat diffusion kernel and a stochastic kernel... sk+1_t = s^k_t + Delta tau * nu(alpha) * Delta_M s^k_t + sqrt(2 Delta tau) sigma_t N(0,I)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Table 1... Ours (Heat Diff.) partial s / partial tau = nu(alpha) nabla^2_t s
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Align your latents: High-resolution video synthesis with la- tent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dock- horn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with la- tent diffusion models. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 22563–22575, 2023. 2
work page 2023
-
[2]
Scientific machine learning through physics– informed neural networks: Where we are and what’s next
Salvatore Cuomo, Vincenzo Schiano Di Cola, Fabio Gi- ampaolo, Gianluigi Rozza, Maziar Raissi, and Francesco Piccialli. Scientific machine learning through physics– informed neural networks: Where we are and what’s next. Journal of Scientific Computing, 92(3):88, 2022. 3
work page 2022
-
[3]
Shaan Desai, Marios Mattheakis, Hayden Joy, Pavlos Pro- topapas, and Stephen Roberts. One-shot transfer learn- ing of physics-informed neural networks.arXiv preprint arXiv:2110.11286, 2021. 3
-
[4]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning,
-
[5]
Stephanie Fu, Netanel Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola. Dream- sim: Learning new dimensions of human visual similar- ity using synthetic data.arXiv preprint arXiv:2306.09344,
-
[6]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patash- nik, Amit H Bermano, Gal Chechik, and Daniel Cohen- Or. An image is worth one word: Personalizing text-to- image generation using textual inversion.arXiv preprint arXiv:2208.01618, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Talecrafter: Interactive story visualization with multiple characters,
Yuan Gong, Youxin Pang, Xiaodong Cun, Menghan Xia, Yingqing He, Haoxin Chen, Longyue Wang, Yong Zhang, Xintao Wang, Ying Shan, et al. Talecrafter: Interactive story visualization with multiple characters.arXiv preprint arXiv:2305.18247, 2023. 2
-
[8]
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation met- ric for image captioning.arXiv preprint arXiv:2104.08718,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 2
work page 2020
-
[11]
Imagen Video: High Definition Video Generation with Diffusion Models
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion mod- els.arXiv preprint arXiv:2210.02303, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 2
work page 2022
-
[13]
Multi-concept customization of text-to-image diffusion
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1931–1941, 2023. 2
work page 1931
-
[14]
Con- sistent story generation: Unlocking the potential of zigzag sampling
Mingxiao Li, Mang Ning, and Marie-Francine Moens. Con- sistent story generation: Unlocking the potential of zigzag sampling. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 2, 7
work page 2025
-
[15]
Photomaker: Customizing re- alistic human photos via stacked id embedding
Zhen Li, Mingdeng Cao, Xintao Wang, Zhongang Qi, Ming- Ming Cheng, and Ying Shan. Photomaker: Customizing re- alistic human photos via stacked id embedding. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8640–8650, 2024. 2, 7
work page 2024
-
[16]
Magic3d: High-resolution text-to-3d content creation
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High-resolution text-to-3d content creation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 300–309, 2023. 2
work page 2023
-
[17]
One-prompt-one-story: Free-lunch consistent text-to-image generation using a single prompt
Tao Liu, Kai Wang, Senmao Li, Joost van de Weijer, Fa- had Shahbaz Khan, Shiqi Yang, Yaxing Wang, Jian Yang, and Ming-Ming Cheng. One-prompt-one-story: Free-lunch consistent text-to-image generation using a single prompt. arXiv preprint arXiv:2501.13554, 2025. 2, 7
-
[18]
Gpt-5 system card.https://openai.com/ index/gpt-5-system-card/, 2025
OpenAI. Gpt-5 system card.https://openai.com/ index/gpt-5-system-card/, 2025. Accessed 2025- 11-12. 5
work page 2025
-
[19]
Nobuyuki Otsu. A threshold selection method from gray- level histograms.IEEE Transactions on Systems, Man, and Cybernetics, 9(1):62–66, 1979. 4
work page 1979
-
[20]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4195–4205,
-
[21]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Milden- hall. Dreamfusion: Text-to-3d using 2d diffusion.arXiv preprint arXiv:2209.14988, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Meta-learning pinn loss functions.Journal of com- putational physics, 458:111121, 2022
Apostolos F Psaros, Kenji Kawaguchi, and George Em Kar- niadakis. Meta-learning pinn loss functions.Journal of com- putational physics, 458:111121, 2022. 3
work page 2022
-
[23]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning frame- work for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computa- tional physics, 378:686–707, 2019. 2
work page 2019
-
[24]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2
work page 2022
-
[25]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. InInternational Conference on Medical image com- puting and computer-assisted intervention, pages 234–241. Springer, 2015. 2
work page 2015
-
[26]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500– 22510, 2023. 2
work page 2023
-
[27]
Simo Ryu. Low-rank adaptation for fast text-to-image diffu- sion fine-tuning.Low-rank adaptation for fast text-to-image diffusion fine-tuning, 3, 2023. 2
work page 2023
-
[28]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022. 2
work page 2022
-
[29]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data.arXiv preprint arXiv:2209.14792,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational confer- ence on machine learning, pages 2256–2265. pmlr, 2015. 2
work page 2015
-
[31]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 5
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[32]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions.arXiv preprint arXiv:2011.13456, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[33]
Yoad Tewel, Omri Kaduri, Rinon Gal, Yoni Kasten, Lior Wolf, Gal Chechik, and Yuval Atzmon. Training-free consis- tent text-to-image generation.ACM Transactions on Graph- ics (TOG), 43(4):1–18, 2024. 2, 7
work page 2024
-
[34]
Adap- tive physics-informed neural networks: A survey.arXiv preprint arXiv:2503.18181, 2025
Edgar Torres, Jonathan Schiefer, and Mathias Niepert. Adap- tive physics-informed neural networks: A survey.arXiv preprint arXiv:2503.18181, 2025. 3
-
[35]
Characonsist: Fine- grained consistent character generation
Mengyu Wang, Henghui Ding, Jianing Peng, Yao Zhao, Yunpeng Chen, and Yunchao Wei. Characonsist: Fine- grained consistent character generation. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 16058–16067, 2025. 2, 7
work page 2025
-
[36]
Instantid: Zero-shot identity-preserving generation in seconds.arXiv preprint arXiv:2401.07519, 2024
Qixun Wang, Xu Bai, Haofan Wang, Zekui Qin, Anthony Chen, Huaxia Li, Xu Tang, and Yao Hu. Instantid: Zero-shot identity-preserving generation in seconds.arXiv preprint arXiv:2401.07519, 2024. 2
-
[37]
Guangxuan Xiao, Tianwei Yin, William T Freeman, Fr ´edo Durand, and Song Han. Fastcomposer: Tuning-free multi- subject image generation with localized attention.Interna- tional Journal of Computer Vision, 133(3):1175–1194, 2025. 2
work page 2025
-
[38]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip- adapter: Text compatible image prompt adapter for text-to- image diffusion models.arXiv preprint arXiv:2308.06721,
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 2
work page 2023
-
[40]
Yupeng Zhou, Daquan Zhou, Ming-Ming Cheng, Jiashi Feng, and Qibin Hou. Storydiffusion: Consistent self- attention for long-range image and video generation.Ad- vances in Neural Information Processing Systems, 37: 110315–110340, 2024. 2, 7
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.