Recognition: 2 theorem links
· Lean TheoremBayesian low-rank latent-cluster regression for mixed health outcomes
Pith reviewed 2026-05-13 05:11 UTC · model grok-4.3
The pith
Bayesian latent-cluster reduced-rank regression contracts posteriors for mixed health outcomes and recovers partitions
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a Bayesian latent-cluster reduced-rank regression model as a finite mixture of regression surfaces, each equipped with a cluster-specific mean shift and a low-rank coefficient matrix. Responses may be Gaussian, Bernoulli, or negative binomial. Multiplicative gamma process shrinkage adapts the effective rank within each cluster and WAIC selects the number of clusters and maximal rank. Posterior contraction holds for the identifiable component-specific regression surfaces and mean shifts up to label permutation, with corresponding contraction for predictor-side singular subspaces. The default label-invariant reporting pipeline—an eigenspace embedding of the posterior similarity矩阵 0.
What carries the argument
Finite mixture of cluster-specific low-rank regression surfaces with mean shifts, using multiplicative gamma process shrinkage and posterior similarity matrix eigenspace embedding for label-invariant partition recovery
If this is right
- Posterior concentrates around the true component-specific regression surfaces, mean shifts, and predictor singular subspaces up to label permutation.
- The label-invariant pipeline recovers the latent partition consistently under the stated separation margin.
- Simulations recover the number of clusters accurately and outperform K-means, mclust, PCA-based clustering, and Gaussian reduced-rank mixtures across all-Gaussian, all-Bernoulli, all-negative-binomial, and mixed regimes.
- Applications produce interpretable county- and state-level cluster maps together with response-specific posterior predictive maps.
- WAIC provides a practical criterion for selecting the number of clusters and nominal maximal rank.
Where Pith is reading between the lines
- The framework may extend naturally to longitudinal or spatial health records that also contain mixed outcome types and latent subgroups.
- Alternative post-processing of the posterior similarity matrix could potentially weaken or remove the strong separation margin requirement.
- Direct comparison of WAIC against other Bayesian model-selection criteria for mixed-outcome mixtures would clarify robustness of the tuning step.
Load-bearing premise
The strong separation margin condition is required for the posterior similarity matrix eigenspace embedding followed by mean shift to consistently recover the latent partition.
What would settle it
A simulation or dataset in which clusters violate the strong separation margin yet the eigenspace embedding of the posterior similarity matrix still recovers the true groups would falsify the consistent-recovery claim.
Figures
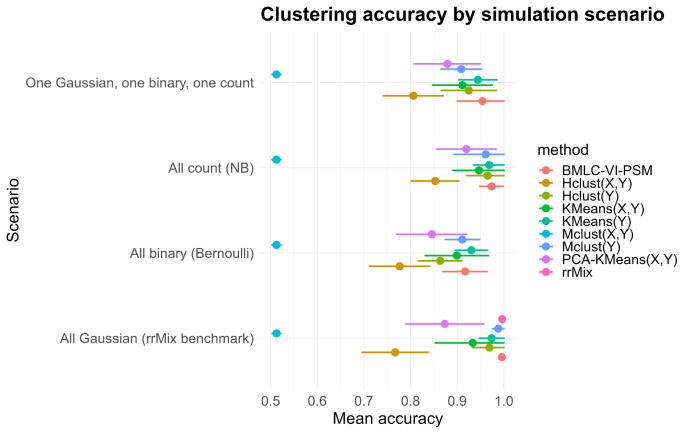
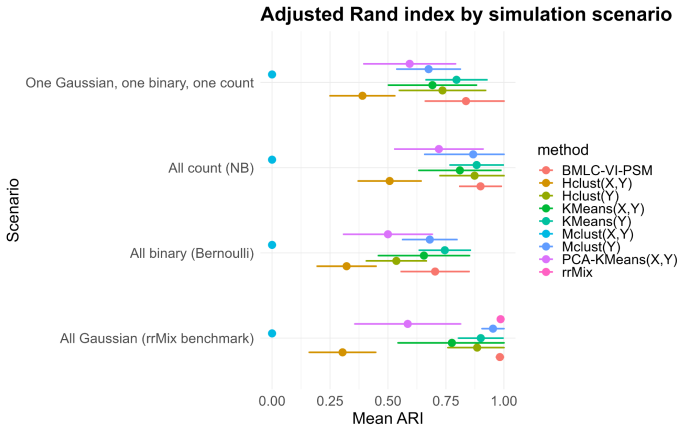
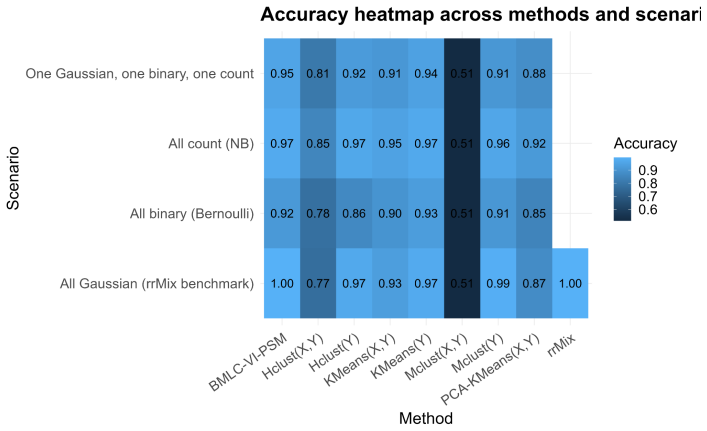


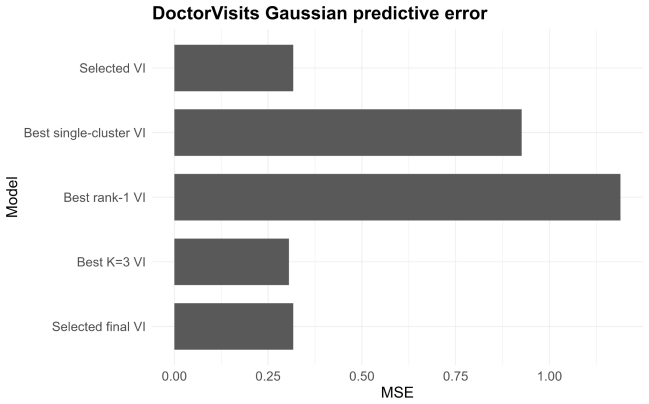
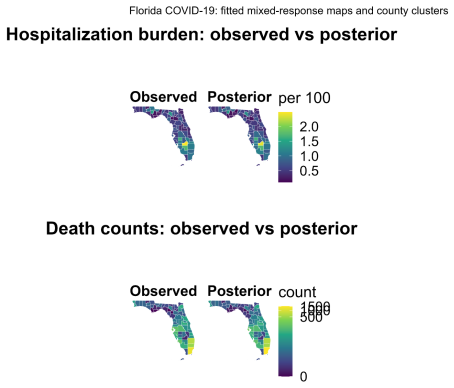
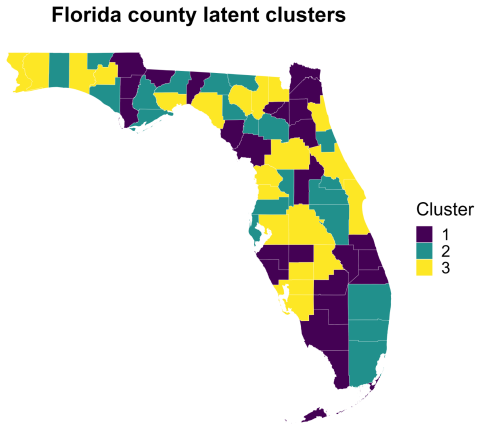



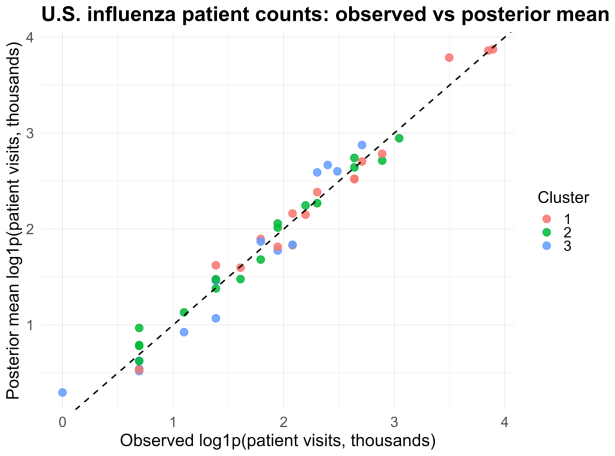
read the original abstract
High-dimensional health and surveillance studies often involve many collinear predictors, multiple correlated outcomes of different types, and latent heterogeneity across observational units. We propose a Bayesian latent-cluster reduced-rank regression model for multivariate mixed outcomes. The model is a finite mixture of regression surfaces: each latent cluster has a cluster-specific mean shift and a low-rank coefficient matrix, yielding simultaneous clustering, dimension reduction, and component-wise interpretability. Response coordinates may be Gaussian, Bernoulli, or negative binomial. Multiplicative gamma process shrinkage adapts the effective rank within each cluster, and a WAIC-based criterion is used to tune the number of clusters and the nominal maximal rank. We establish posterior contraction for the identifiable component-specific regression surfaces and mean shifts, up to label permutation, and derive corresponding contraction for predictor-side singular subspaces. We also analyze the default label-invariant reporting pipeline based on the posterior similarity matrix: an eigenspace embedding followed by mean shift is shown to consistently recover the latent partition under an additional strong separation margin. Simulation experiments spanning all-Gaussian, all-Bernoulli, all-negative-binomial, and mixed Gaussian--Bernoulli--negative-binomial regimes show accurate recovery of the number of clusters and competitive clustering performance against $K$-means, mclust, PCA-based clustering, and a Gaussian reduced-rank mixture benchmark. We illustrate the method in three applications that show how the model separates individual-level utilization groups and produces interpretable county- and state-level cluster maps together with response-specific posterior predictive maps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Bayesian finite mixture of reduced-rank regressions for multivariate mixed-type outcomes (Gaussian, Bernoulli, negative binomial), with cluster-specific mean shifts and low-rank coefficient matrices. It establishes posterior contraction for the identifiable cluster-specific regression surfaces, mean shifts, and predictor-side singular subspaces (up to label permutation). The default label-invariant reporting pipeline—an eigenspace embedding of the posterior similarity matrix followed by mean shift—is shown to recover the latent partition under an additional strong separation margin. Simulations across all-Gaussian, all-Bernoulli, all-negative-binomial, and mixed regimes demonstrate accurate WAIC-based selection of K and competitive clustering performance; three health-data applications illustrate cluster maps and posterior predictive surfaces.
Significance. If the contraction rates and recovery results hold, the paper supplies a theoretically supported tool for simultaneous clustering, dimension reduction, and interpretable modeling of heterogeneous mixed outcomes with collinear predictors. The explicit treatment of label-invariant reporting and the multiplicative gamma process for adaptive rank are strengths; the work addresses a practically relevant setting in health surveillance.
major comments (2)
- [Section analyzing the label-invariant reporting pipeline (posterior similarity matrix embedding)] The strong separation margin condition for consistent recovery of the latent partition via the posterior similarity matrix eigenspace embedding is introduced as an additional assumption beyond the posterior contraction theorems. This margin is not quantified in terms of minimal distances between cluster-specific mean shifts or low-rank coefficients, and the manuscript provides no verification that the condition holds in the simulation designs or the three health-data applications. This is load-bearing for the practical claim that the default reporting pipeline recovers the partition.
- [Simulation experiments section] The simulation experiments report accurate recovery of K and competitive clustering metrics, but do not include regimes that systematically vary the separation between clusters (e.g., by scaling mean shifts or regression coefficients). Consequently, it is unclear whether the strong separation margin is satisfied in the tested settings, weakening the link between theory and the reported empirical performance.
minor comments (1)
- [Model and prior specification] The WAIC-based selection of K and nominal maximal rank is presented as a practical default; a brief discussion of its consistency properties under the model would strengthen the methodological section.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments correctly identify that the strong separation margin is an additional assumption whose practical relevance is not yet fully bridged to the simulations and applications. We address both points below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: The strong separation margin condition for consistent recovery of the latent partition via the posterior similarity matrix eigenspace embedding is introduced as an additional assumption beyond the posterior contraction theorems. This margin is not quantified in terms of minimal distances between cluster-specific mean shifts or low-rank coefficients, and the manuscript provides no verification that the condition holds in the simulation designs or the three health-data applications. This is load-bearing for the practical claim that the default reporting pipeline recovers the partition.
Authors: We agree that the strong separation margin is an additional assumption required for the consistency result on the label-invariant reporting pipeline. In the revision we will (i) explicitly quantify the margin in terms of the minimal Euclidean separation between cluster-specific mean shifts and the minimal Frobenius (or operator-norm) separation between the low-rank coefficient matrices, (ii) relate the margin size to the posterior contraction rates already established for the regression surfaces and singular subspaces, and (iii) add a short supplementary section that reports empirical separation diagnostics (pairwise distances between estimated cluster means and coefficient matrices) for the simulation designs and the three health-data applications, together with a discussion of whether the observed separations are consistent with the margin condition. revision: yes
-
Referee: The simulation experiments report accurate recovery of K and competitive clustering metrics, but do not include regimes that systematically vary the separation between clusters (e.g., by scaling mean shifts or regression coefficients). Consequently, it is unclear whether the strong separation margin is satisfied in the tested settings, weakening the link between theory and the reported empirical performance.
Authors: We acknowledge that the current simulation designs fix moderate-to-strong separations chosen to reflect realistic health-data heterogeneity and do not systematically vary separation strength. In the revised manuscript we will add a new simulation experiment that scales the mean-shift vectors and the entries of the low-rank coefficient matrices across a grid of separation levels (including values near the theoretical margin). This will allow direct assessment of the reporting pipeline’s recovery rate as separation approaches the margin threshold and will strengthen the empirical link to the theoretical guarantee. revision: yes
Circularity Check
No significant circularity; derivations are self-contained theoretical results
full rationale
The paper proposes a new Bayesian finite mixture model with low-rank cluster-specific regressions and mean shifts for mixed outcomes, using multiplicative gamma process shrinkage and WAIC for tuning. It derives posterior contraction rates for identifiable component-specific surfaces, mean shifts (up to label permutation), and predictor singular subspaces directly from the model assumptions and standard Bayesian nonparametric techniques. The label-invariant reporting pipeline (posterior similarity matrix eigenspace embedding plus mean shift) is analyzed separately and shown to recover the partition only under an explicitly additional strong separation margin condition. No step reduces by construction to a fitted parameter renamed as a prediction, no self-definitional loop appears in the identifiability or contraction statements, and no load-bearing uniqueness theorem is imported solely via self-citation. The central claims therefore retain independent content from the stated assumptions and are not tautological.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of clusters K
- nominal maximal rank
axioms (2)
- domain assumption Posterior contraction holds for identifiable component-specific regression surfaces and mean shifts up to label permutation under the stated model and priors.
- ad hoc to paper Strong separation margin on the latent clusters for consistent recovery via posterior similarity matrix embedding.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe establish posterior contraction for the identifiable component-specific regression surfaces and mean shifts, up to label permutation... under an additional strong separation margin.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearMultiplicative gamma process shrinkage adapts the effective rank... Jcost uniqueness or recognition cost J(x) = 1/2(x + x^{-1}) - 1 nowhere appears.
Reference graph
Works this paper leans on
-
[1]
Saket Anand, Sushil Mittal, Oncel Tuzel, and Peter Meer. Semi- supervised kernel mean shift clustering.IEEE Transactions on Pattern Analysis and Machine Intelligence, 36(6):1201–1215, 2014
work page 2014
-
[2]
T. W. Anderson. Estimating linear restrictions on regression coefficients for multivariate normal distributions.The Annals of Mathematical Statistics, 22(3):327–351, 1951
work page 1951
-
[3]
Anirban Bhattacharya and David B. Dunson. Sparse bayesian infinite factor models.Biometrika, 98(2):291–306, 2011
work page 2011
-
[4]
Bishop.Pattern Recognition and Machine Learning
Christopher M. Bishop.Pattern Recognition and Machine Learning. Springer, 2006
work page 2006
-
[5]
Blei, Alp Kucukelbir, and Jon D
David M. Blei, Alp Kucukelbir, and Jon D. McAuliffe. Variational inference: A review for statisticians.Journal of the American Statistical Association, 112(518):859–877, 2017
work page 2017
-
[6]
Miguel A. Carreira-Perpi˜ n´ an. A review of mean-shift algorithms for clustering.arXiv preprint arXiv:1503.00687, 2015
-
[7]
Yen-Chi Chen, Christopher R. Genovese, and Larry Wasserman. A comprehensive approach to mode clustering.Electronic Journal of Statistics, 10(1):210–241, 2016
work page 2016
-
[8]
Chris Fraley and Adrian E. Raftery. Model-based clustering, discriminant analysis, and density estimation.Journal of the American Statistical Association, 97(458):611–631, 2002
work page 2002
-
[9]
Izenman.Modern Multivariate Statistical Techniques
Alan J. Izenman.Modern Multivariate Statistical Techniques. Springer, 2008. 44
work page 2008
-
[10]
Suyeon Kang, Kun Chen, and Weixin Yao.rrMixture: Reduced-Rank Mixture Models, 2022. R package version 0.1-2
work page 2022
-
[11]
Sahand Negahban, Pradeep Ravikumar, Martin J. Wainwright, and Bin Yu. A unified framework for high-dimensional analysis of M-estimators with decomposable regularizers.Statistical Science, 27(4):538–557, 2012
work page 2012
-
[12]
Nicholas G. Polson, James G. Scott, and Jesse Windle. Bayesian infer- ence for logistic models using P´ olya–Gamma latent variables.Journal of the American Statistical Association, 108(504):1339–1349, 2013
work page 2013
-
[13]
Riccardo Rastelli and Nial Friel. Optimal bayesian estimators for latent variable cluster models.Statistics and Computing, 28(6):1169–1186, 2018
work page 2018
-
[14]
Gregory C. Reinsel and Raja P. Velu.Multivariate Reduced-Rank Regression: Theory and Applications. Springer, New York, 1998
work page 1998
-
[15]
Luca Scrucca, Michael Fop, T. Brendan Murphy, and Adrian E. Raftery. mclust 5: Clustering, classification and density estimation using Gaus- sian finite mixture models.The R Journal, 8(1):289–317, 2016
work page 2016
-
[16]
S. H. Wang, R. Bai, and Hsin-Hsiung Huang. Two-step mixed-type multivariate bayesian sparse variable selection with shrinkage priors. Electronic Journal of Statistics, 19(1):397–457, 2025
work page 2025
-
[17]
Sumio Watanabe. Asymptotic equivalence of bayes cross validation and widely applicable information criterion in singular learning theory. Journal of Machine Learning Research, 11(Dec):3571–3594, 2010
work page 2010
-
[18]
Daniela M. Witten and Robert Tibshirani. A penalized matrix decompo- sition, with applications to sparse principal components and canonical correlation analysis.Biostatistics, 10(3):515–534, 2009
work page 2009
-
[19]
Dimension reduction and coefficient estimation in multivariate linear regression
Ming Yuan, Ali Ekici, Zhaosong Lu, and Renato Monteiro. Dimension reduction and coefficient estimation in multivariate linear regression. Journal of the Royal Statistical Society: Series B, 69(3):329–346, 2007. 45
work page 2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.