Recognition: no theorem link
High-lift Wing Separation Control via Bayesian Optimization and Deep Reinforcement Learning
Pith reviewed 2026-05-13 04:52 UTC · model grok-4.3
The pith
Bayesian optimization identifies steady jet velocities that raise high-lift wing efficiency by 10.9 percent via 9.7 percent drag reduction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
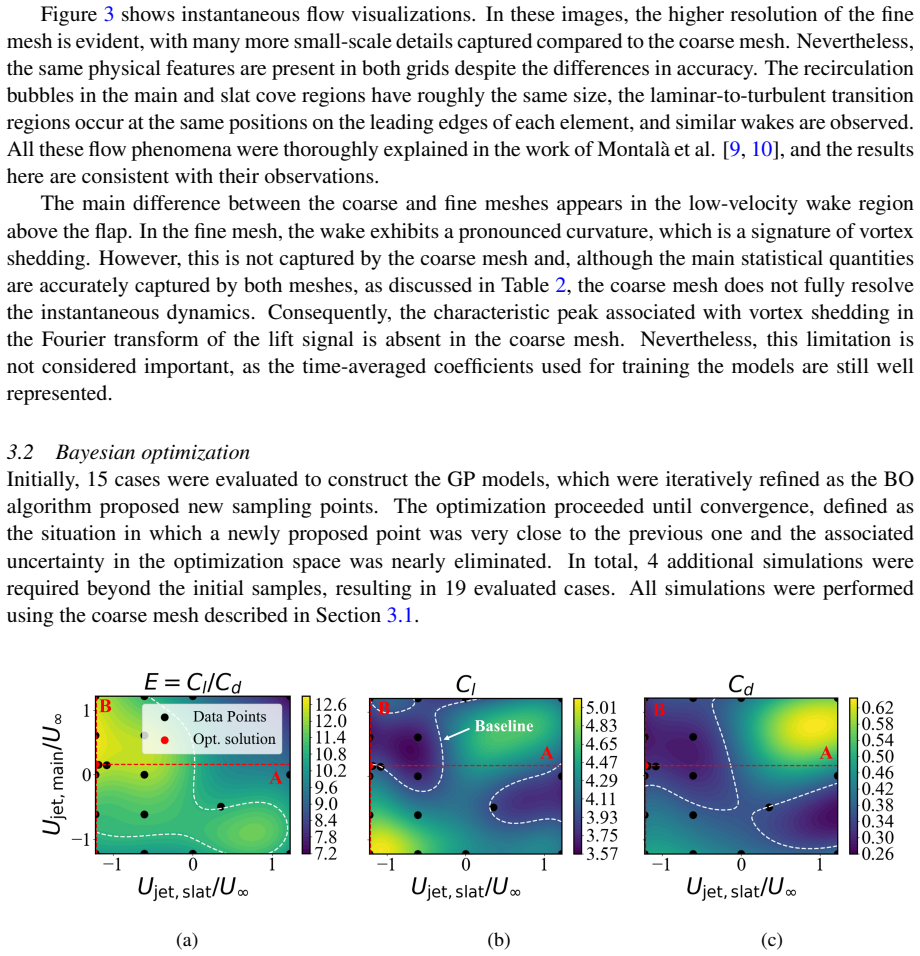
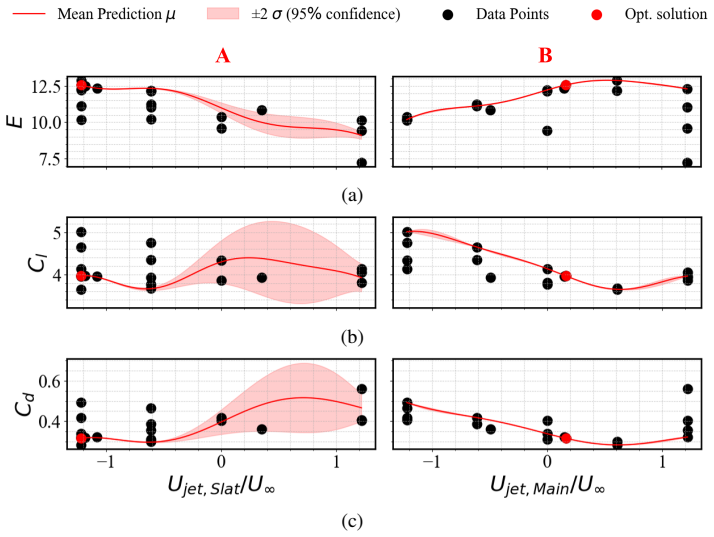
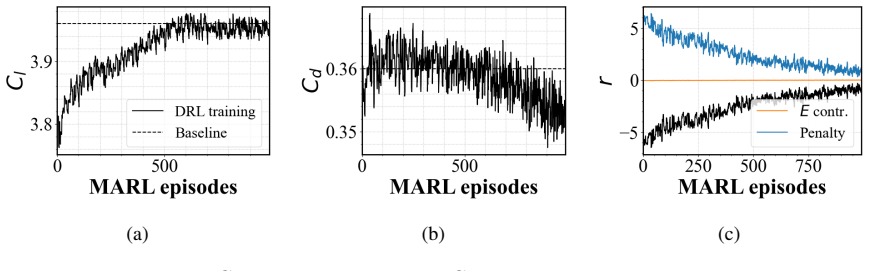
The Bayesian optimization framework successfully identified steady jet velocities that increased efficiency by +10.9% through a -9.7% drag reduction while maintaining lift. In contrast, the DRL agent, despite leveraging instantaneous flow information from distributed sensors, achieved only minor improvements in lift and drag, with negligible efficiency gain. Training analysis indicated that the penalty-dominated reward constrained exploration.
What carries the argument
Bayesian optimization search over steady synthetic jet velocities placed on the slat, main wing element, and flap.
If this is right
- Steady jet velocities located by Bayesian optimization reduce drag by 9.7 percent while lift remains unchanged.
- Aerodynamic efficiency rises by 10.9 percent under these fixed jet settings.
- Deep reinforcement learning produces only minor lift and drag changes when its reward heavily penalizes deviations.
- Wall-resolved large-eddy simulations reproduce the baseline flow in agreement with prior measurements.
- Reward design must allow greater exploration before closed-loop control can match open-loop search performance.
Where Pith is reading between the lines
- Open-loop Bayesian optimization currently provides a more practical route than the tested reinforcement learning setup for reducing separation at this Reynolds number.
- A less penalty-heavy reward could allow the reinforcement learning agent to reach or exceed the efficiency gains of the open-loop method.
- The jet velocities identified here supply a specific target that could be checked in a wind-tunnel experiment.
- The same optimization approach could be applied at other angles of attack to locate efficient control settings across the operating range.
Load-bearing premise
The penalties built into the reinforcement learning reward were the main reason the agent did not discover stronger control settings.
What would settle it
Re-train the reinforcement learning agent with a reward that rewards efficiency gains more directly and check whether the resulting efficiency improvement reaches the 10.9 percent level found by Bayesian optimization.
Figures


read the original abstract
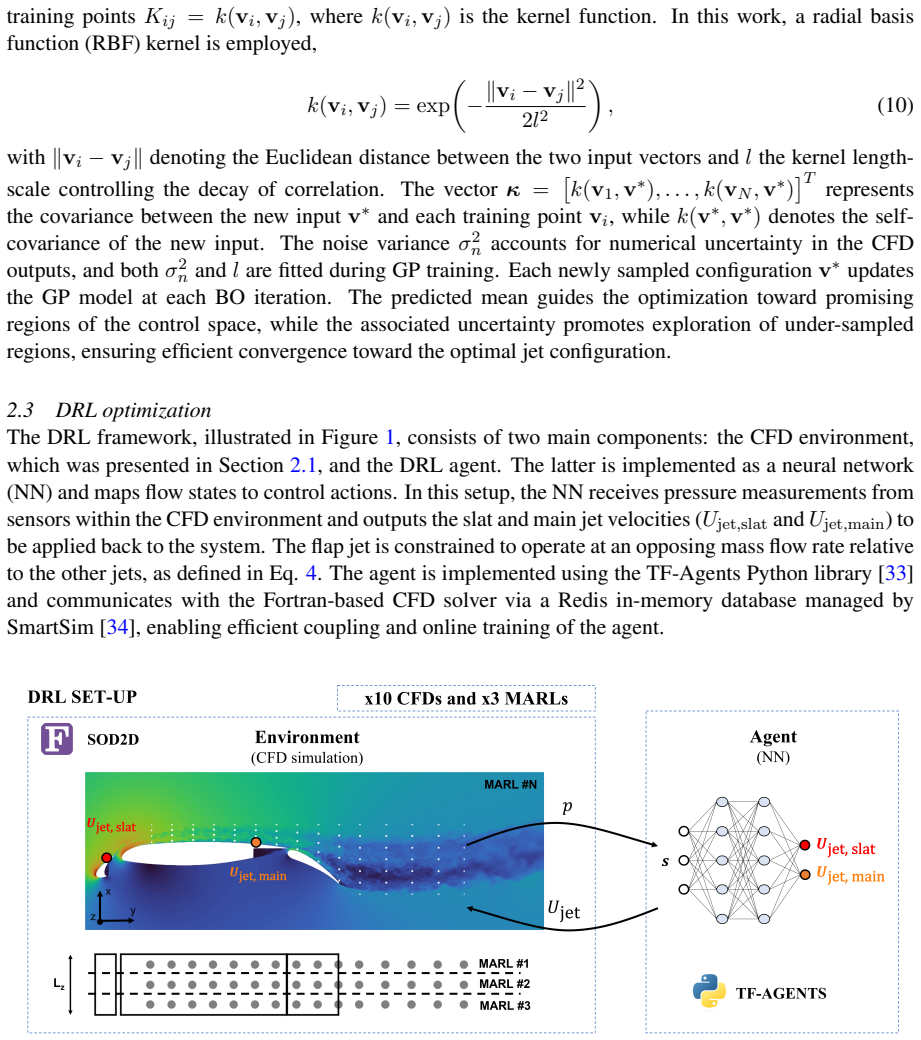
This study investigates active flow control (AFC) of a 30P30N high-lift wing at a Reynolds number Re$_c$ = 450,000 and angle of attack $\alpha$ = 23$^\circ$ using wallresolved large-eddy simulations (LES). Two optimization strategies are explored: open-loop Bayesian optimization (BO) and closed-loop deep reinforcement learning (DRL), both targeting the mitigation of stall and the improvement of aerodynamic efficiency via synthetic jets on the slat, main, and flap elements. The uncontrolled configuration was validated against literature data, confirming the reliability of the LES setup. The BO framework successfully identified steady jet velocities that increased efficiency by +10.9% through a -9.7% drag reduction while maintaining lift. In contrast, the DRL agent, despite leveraging instantaneous flow information from distributed sensors, achieved only minor improvements in lift and drag, with negligible efficiency gain. Training analysis indicated that the penalty-dominated reward constrained exploration. These results highlight the need for carefully designed rewards and computational acceleration strategies in DRL-based flow control at high Reynolds numbers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper investigates active flow control on a 30P30N high-lift wing at Re_c = 450,000 and α = 23° using wall-resolved LES. It compares open-loop Bayesian optimization (BO) for identifying steady synthetic jet velocities on the slat, main element, and flap against closed-loop deep reinforcement learning (DRL) that uses instantaneous sensor data. The uncontrolled LES is validated against literature data. BO yields a +10.9% efficiency gain via -9.7% drag reduction at fixed lift, while DRL produces only minor lift/drag changes with negligible efficiency improvement, which the authors attribute to a penalty-dominated reward function limiting exploration.
Significance. If the numerical results hold, the work supplies a concrete, validated demonstration that BO can locate effective steady actuation parameters for stall mitigation in a realistic high-lift configuration, delivering a quantifiable aerodynamic-efficiency improvement. The side-by-side comparison with DRL highlights practical difficulties in applying reinforcement learning to high-Re turbulent flows and points to reward design as a key area for future refinement. The explicit LES validation and reporting of specific percentage gains strengthen the contribution to computational aerodynamics and data-driven flow control.
major comments (1)
- [DRL training analysis] DRL training analysis section: the attribution of limited DRL performance primarily to the penalty-dominated reward function is interpretive rather than demonstrated; no ablation studies or alternative reward formulations are presented to isolate this factor from sensor placement, episode length, or controlled-case LES fidelity, weakening the contrast drawn with the BO results.
minor comments (3)
- [Abstract] Abstract and §3: the definition of aerodynamic efficiency as the lift-to-drag ratio is stated but should be repeated explicitly when the +10.9% figure is first introduced to avoid any ambiguity for readers.
- [Methods] Methods: the specific BO acquisition function, kernel choice, and number of evaluations are not detailed; adding these parameters would improve reproducibility of the reported optimum jet velocities.
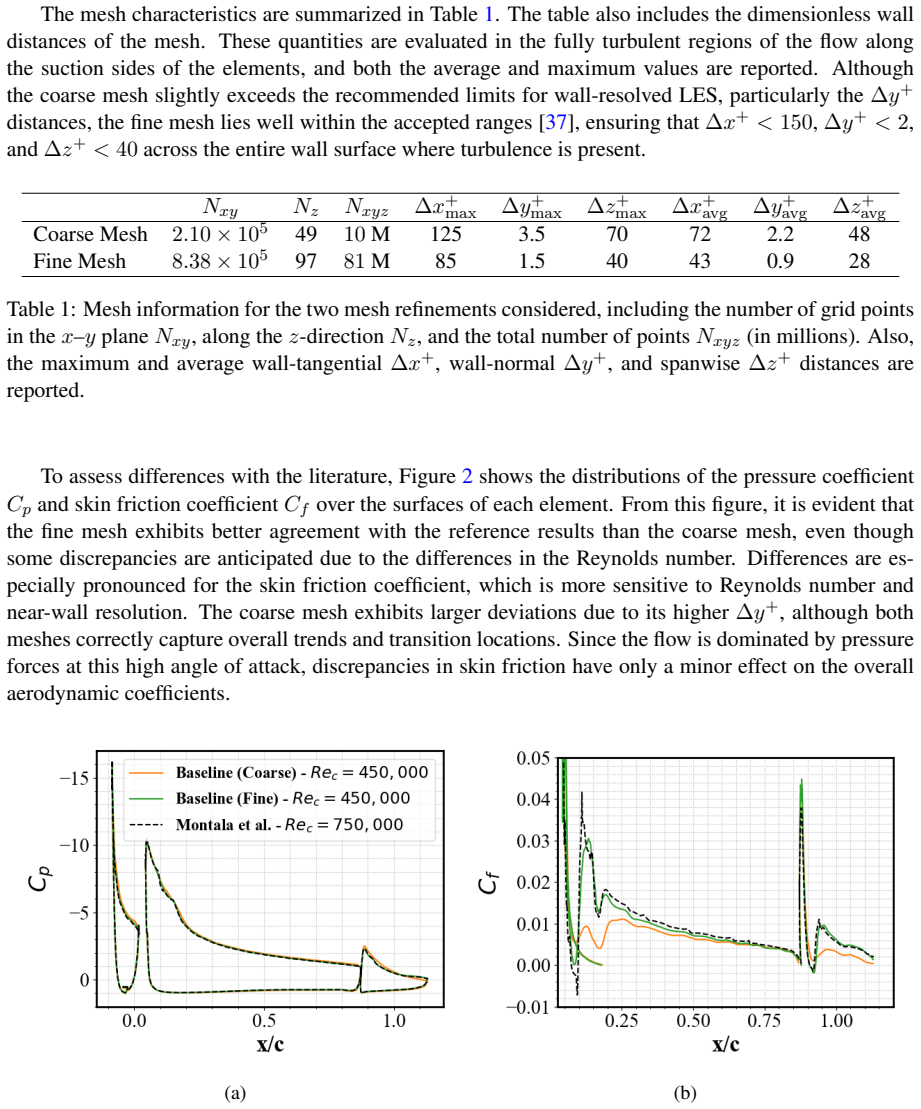
- [Figures and tables] Figure captions and tables: axis labels and units for jet velocity, lift, and drag coefficients should be checked for consistency with the text; several captions are terse and would benefit from one additional sentence describing the key trend shown.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our manuscript. We have carefully considered the major comment and provide a point-by-point response below. We are prepared to revise the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [DRL training analysis] DRL training analysis section: the attribution of limited DRL performance primarily to the penalty-dominated reward function is interpretive rather than demonstrated; no ablation studies or alternative reward formulations are presented to isolate this factor from sensor placement, episode length, or controlled-case LES fidelity, weakening the contrast drawn with the BO results.
Authors: We agree that the attribution of limited DRL performance to the penalty-dominated reward function is interpretive, as it is derived from analysis of the observed training curves and reward component breakdowns rather than from controlled ablation experiments. The manuscript's training analysis shows that the penalty term rapidly dominated the cumulative reward, which we interpret as limiting exploration of lift-enhancing or drag-reducing actions. We acknowledge that factors such as sensor placement, episode length, and LES fidelity in the controlled cases could also play a role, and that the absence of ablations weakens the strength of the contrast with the BO results. In the revised manuscript, we will expand the DRL training analysis section with additional details on the reward formulation, include supplementary plots breaking down the individual reward terms over training episodes, and explicitly qualify our conclusions as interpretive while noting the computational constraints that precluded ablations. We will also moderate the language comparing DRL and BO outcomes to reflect these limitations. revision: yes
- We cannot perform the requested ablation studies or test alternative reward formulations, as they would require extensive additional wall-resolved LES computations at Re_c = 450,000 that exceed available resources.
Circularity Check
No significant circularity detected
full rationale
The paper reports direct outcomes from wall-resolved LES of the 30P30N configuration at fixed Re and alpha, validated against external literature data for the uncontrolled case. Bayesian optimization and DRL are then applied as standard black-box optimizers to search for jet velocities; the +10.9% efficiency gain is the numerical result of those runs, not a quantity fitted or defined in terms of itself. The observation that the penalty term limited DRL exploration is an empirical training-log conclusion, not a self-referential definition. No load-bearing step reduces to a self-citation, ansatz smuggled via prior work, or renaming of a known result; the derivation chain is self-contained against external benchmarks and computational experiments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The wall-resolved large-eddy simulation accurately represents the flow physics for both uncontrolled and controlled cases at the given Reynolds number.
Reference graph
Works this paper leans on
-
[1]
Thibert J J, Reneaux J, Moens F and Preist J 1995The Aeronautical Journal99395–411
-
[2]
Klausmeyer S M and Lin J C 1997 Comparative results from a CFD challenge over a 2D three- element high-lift airfoil Tech. Rep. NASA TM-112858 NASA Langley Research Center NASA Technical Memorandum
work page 1997
-
[3]
Choudhari M and Lockard D 2015 Assessment of slat noise predictions for 30P30N high-lift con- figuration from BANC-III workshop21st AIAA/CEAS Aeroacoustics Conference
work page 2015
-
[4]
Pascioni K, Cattafesta L and Choudhari M 2014 An experimental investigation of the 30P30N multi-element high-lift airfoil20th AIAA/CEAS Aeroacoustics Conference
work page 2014
-
[5]
Ashton N, West A and Mendonça F 2016AIAA Journal543657–3667
-
[6]
Gao J, Li X and Lin D 2020AIAA Journal582517–2532
-
[7]
Ueno Y and Ochi A 2019 Airframe noise prediction using Navier-Stokes code with cartesian and boundary-fitted layer meshes25th AIAA/CEAS Aeroacoustics Conference
work page 2019
-
[8]
Shur M, Strelets M, Spalart P and Travin A 2023Journal of Turbulence24554–576
-
[9]
Montalà R, Lehmkuhl O and Rodriguez I 2024Physics of Fluids36025125 ISSN 1070-6631
-
[10]
Montalà R, Lehmkuhl O and Rodriguez I 2025Flow, Turbulence and Combustion11551–77
-
[11]
You D and Moin P 2008Journal of Fluids and Structures241349–1357 ISSN 0889-9746 unsteady Separated Flows and their Control
-
[12]
Rodriguez I, Lehmkuhl O and Borrell R 2020Flow, Turbulence and Combustion105607–626
-
[13]
Melton L, Yao C and Seifert A 2006AIAA Journal44012017
-
[14]
Shmilovich A and Yadlin Y 2009Journal of Aircraft461354–1364
-
[15]
Lehmkuhl O, Lozano-Durán A and Rodriguez I 2020Journal of Physics: Conference Series1522 012017
-
[16]
Rabault J, Kuchta M, Jensen A, Réglade U and Cerardi N 2019J. Fluid Mech.865281–302
-
[17]
Rabault J and Kuhnle A 2019Phys. Fluids31094105 ISSN 1070-6631
-
[18]
Suárez P, Alcántara-Ávila F, Rabault J, Miró A, Font B, Lehmkuhl O and Vinuesa R 2025Commun. Eng.4
-
[19]
Suárez P, Alcántara-Ávila F, Rabault J, Miró A, Font B, Lehmkuhl O and Vinuesa R 2025Flow Turbul. Combust.1153–27
-
[20]
Guastoni L, Rabault J, Schlatter P, Azizpour H and Vinuesa R 2023Eur . Phys. J. E4627
-
[21]
Vasanth J, Rabault J, Alcántara-Ávila F, Mortensen M and Vinuesa R 2024Flow Turbul. Combust
- [22]
-
[23]
Garcia X, Miró A, Suárez P, Alcántara-Ávila F, Rabault J, Font B, Lehmkuhl O and Vinuesa R 2025 Int. J. Heat Fluid Flow116109913 ISSN 0142-727X
work page 2025
-
[24]
Font B, Alcántara-Ávila F, Rabault J, Vinuesa R and Lehmkuhl O 2025Nat. Commun.161422
-
[25]
Montalà R, Font B, Suárez P, Rabault J, Lehmkuhl O, Vinuesa R and Rodriguez I 2025 Deep reinforcement learning for active flow control around a three-dimensional flow-separated wing at Re = 1,000https://doi.org/10.48550/arXiv.2509.10195
-
[26]
Montalà R, Font B, Suárez P, Rabault J, Lehmkuhl O, Vinuesa R and Rodriguez I 2025 Discovering flow separation control strategies in 3D wings via deep reinforcement learninghttps://doi. org/10.48550/arXiv.2509.10185
-
[27]
Morita Y , Rezaeiravesh S, Tabatabaei N, Vinuesa R, Fukagata K and Schlatter P 2022Journal of Computational Physics449110788 ISSN 0021-9991
-
[28]
Mahfoze O A, Moody A, Wynn A, Whalley R D and Laizet S 2019Phys. Rev. Fluids4(9) 094601
-
[29]
Han B Z, Huang W X and Xu C X 2023Physics of Fluids35115144 ISSN 1070-6631
-
[30]
Li Y , Noack B R, Wang T, Cornejo Maceda G Y , Pickering E, Shaqarin T and Tyliszczak A 2024 Journal of Fluid Mechanics991A5
work page 2024
-
[31]
Vreman A W 2004Physics of Fluids163670–3681
-
[32]
Gasparino L, Spiga F and Lehmkuhl O 2024Computer Physics Communications297109067 ISSN 0010-4655
-
[33]
Guadarrama S, Korattikara A, Ramirez O, Castro P, Holly E, Fishman S, Wang K, Gonina E, Wu N, Kokiopoulou E, Sbaiz L, Smith J, Bartók G, Berent J, Harris C, Vanhoucke V and Brevdo E 2018 TF-Agents: A library for reinforcement learning in TensorFlow URLhttps://github. com/tensorflow/agents
work page 2018
-
[34]
Partee S, Ellis M, Rigazzi A, Shao A, Bachman S, Marques G and Robbins B 2022J. Comput. Sci. 62101707 ISSN 1877-7503
-
[35]
Belus V , Rabault J, Viquerat J, Che Z, Hachem E and Reglade U 2019AIP Advances9125014 ISSN 2158-3226
-
[36]
Schulman J, Wolski F, Dhariwal P, Radford A and Klimov O 2017 Proximal policy optimization algorithmshttps://doi.org/10.48550/arXiv.1707.06347
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1707.06347 2017
-
[37]
Piomelli U and Chasnov J R 1996Large-Eddy Simulations: Theory and Applications(Dordrecht: Springer Netherlands) pp 269–336 ISBN 978-94-015-8666-5
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.