Recognition: no theorem link
A Transfer Learning Evaluation of Deep Neural Networks for Image Classification
Pith reviewed 2026-05-13 07:25 UTC · model grok-4.3
The pith
Refining the output layers of eleven ImageNet-pretrained models on five target datasets reveals which model best matches accuracy, training time, and size needs for image classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By refining the output layers and general network parameters of eleven ImageNet-pretrained models and applying them to five different target datasets, the study shows that no single model leads on all four measured metrics and that the best choice depends on the specific accuracy, efficiency, and size requirements of the target domain.
What carries the argument
Fine-tuning the final layers of pre-trained convolutional networks to transfer ImageNet knowledge to new target image datasets, scored by accuracy, accuracy density, training time, and model size.
If this is right
- Model rankings shift across target domains, so selection must be repeated for each new dataset rather than relying on a fixed hierarchy.
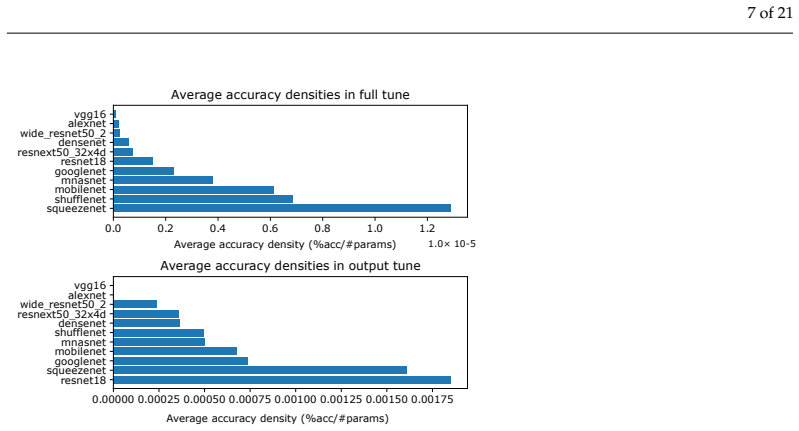
- Accuracy density lets users trade off raw accuracy against model size when memory is constrained.
- Large differences in training time let practitioners choose faster models when compute budgets are tight.
- Model size directly affects deployment feasibility on edge hardware.
- Ten-episode runs give a stability check that single runs miss.
Where Pith is reading between the lines
- A simple lookup table or small decision model could be trained on these metrics to suggest base networks for new datasets without full re-testing.
- The same evaluation pipeline could be applied to other pre-training sources such as self-supervised or multimodal models.
- Results hint that future architectures might be designed with explicit accuracy-density and speed targets rather than accuracy alone.
- Partial fine-tuning of earlier layers, not just the output, might further improve adaptation on domains far from ImageNet.
Load-bearing premise
The performance rankings observed on the five chosen target datasets and the chosen fine-tuning procedure will hold for other unseen image classification tasks.
What would settle it
Running the same eleven models through the identical fine-tuning procedure on a sixth dataset whose images differ markedly in content or statistics, such as medical X-rays, and finding that the top-ranked model by the four metrics changes.
Figures





read the original abstract
Transfer learning is a machine learning technique that uses previously acquired knowledge from a source domain to enhance learning in a target domain by reusing learned weights. This technique is ubiquitous because of its great advantages in achieving high performance while saving training time, memory, and effort in network design. In this paper, we investigate how to select the best pre-trained model that meets the target domain requirements for image classification tasks. In our study, we refined the output layers and general network parameters to apply the knowledge of eleven image processing models, pre-trained on ImageNet, to five different target domain datasets. We measured the accuracy, accuracy density, training time, and model size to evaluate the pre-trained models both in training sessions in one episode and with ten episodes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts an empirical evaluation of transfer learning for image classification by fine-tuning eleven ImageNet-pretrained models on five target datasets. It refines output layers and general parameters, then compares the models using accuracy, accuracy density, training time, and model size across single-episode and ten-episode runs to inform model selection for target domains.
Significance. If the measurements hold, the multi-metric comparison (including efficiency proxies like accuracy density and training time) could offer practical guidance for selecting pretrained models in computer vision applications. The repeated-episode design adds a modest robustness check over single-run results. However, the narrow scope of five datasets and one fine-tuning protocol limits broader applicability.
major comments (3)
- [§3 (Methodology)] §3 (Methodology): The fine-tuning protocol is described only at a high level ('refined the output layers and general network parameters') with no details on optimizer, learning-rate schedule, batch size, data augmentation, or which layers were frozen versus updated. These omissions are load-bearing because training time and final accuracy are directly sensitive to them.
- [Results tables] Results tables (e.g., Tables 2–4): Accuracy differences between models are reported without standard deviations across runs or any statistical significance tests. This undermines the central claim that the measurements reliably indicate the 'best' model for a target domain.
- [§4.2 (Metrics)] §4.2 (Metrics): The definition and exact formula for 'accuracy density' are not provided, so it is impossible to verify whether it normalizes accuracy by model size, parameter count, or another quantity.
minor comments (3)
- [Abstract] Abstract and §1: The phrasing 'refined the output layers' should be replaced with standard terminology ('fine-tuned') for consistency with the transfer-learning literature.
- [Related Work] Related-work section: Add citations to established transfer-learning benchmarks (e.g., Yosinski et al. 2014, Razavian et al. 2014) to situate the five-dataset evaluation.
- [Figures] Figure captions: Add explicit axis labels and units (e.g., 'training time in seconds') to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and suggestions. We address each of the major comments below and have made revisions to the manuscript where necessary to improve clarity and rigor.
read point-by-point responses
-
Referee: [§3 (Methodology)] The fine-tuning protocol is described only at a high level ('refined the output layers and general network parameters') with no details on optimizer, learning-rate schedule, batch size, data augmentation, or which layers were frozen versus updated. These omissions are load-bearing because training time and final accuracy are directly sensitive to them.
Authors: We agree that the methodology requires more detail for reproducibility. In the revised manuscript we have expanded §3 to specify the exact protocol used: Adam optimizer, initial learning rate 0.001 with step decay, batch size 32, random horizontal flips and rotations for augmentation, and fine-tuning of all layers (no freezing). These settings were applied uniformly across the reported experiments. revision: yes
-
Referee: Results tables (e.g., Tables 2–4): Accuracy differences between models are reported without standard deviations across runs or any statistical significance tests. This undermines the central claim that the measurements reliably indicate the 'best' model for a target domain.
Authors: We accept that the absence of variability measures weakens the reliability of the comparisons. The revised tables now report standard deviations computed over the ten episodes. We have also added paired t-test p-values between the top models to indicate whether accuracy differences are statistically significant. revision: yes
-
Referee: [§4.2 (Metrics)] The definition and exact formula for 'accuracy density' are not provided, so it is impossible to verify whether it normalizes accuracy by model size, parameter count, or another quantity.
Authors: We apologize for the missing definition. Section 4.2 has been revised to state that accuracy density is accuracy divided by model size in megabytes, with the explicit formula accuracy_density = accuracy / model_size_MB. This normalizes performance by storage footprint as originally intended. revision: yes
Circularity Check
No significant circularity in empirical evaluation
full rationale
The paper performs a standard empirical comparison by fine-tuning output layers and parameters of 11 ImageNet-pretrained models on five target datasets, then directly reporting observed values for accuracy, accuracy density, training time, and model size across single and ten-episode runs. No equations, derivations, fitted parameters renamed as predictions, or self-citations are used to justify any load-bearing claim. The central investigation is scoped as an evaluation on the chosen datasets and procedure, with results presented as direct observations rather than general rules derived from prior quantities. The work is self-contained against external benchmarks with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An overview of deep learning in medical imaging focusing on MRI.Z
Lundervold, A.S.; Lundervold, A. An overview of deep learning in medical imaging focusing on MRI.Z. Fur Med. Phys.2019, 29, 102–127, doi:10.1016/j.zemedi.2018.11.002
-
[2]
Pires de Lima, R.; Marfurt, K. Convolutional Neural Network for Remote-Sensing Scene Classification: Transfer Learning Analysis.Remote Sens.2020,12, 86, doi:10.3390/rs12010086
-
[3]
Transfer Learning for Classification of Optical Satellite Image.Sens
Zou, M.; Zhong, Y. Transfer Learning for Classification of Optical Satellite Image.Sens. Imaging2018,19, doi:10.1007/s11220-018- 0191-1
-
[4]
Abou Baker, N.; Szabo-Müller, P .; Handmann, U. Feature-fusion transfer learning method as a basis to support automated smartphone recycling in a circular smart city. In Proceedings of the EAI S-CUBE 2020—11th EAI International Conference on Sensor Systems and Software, Aalborg, Denmark, 10–11 December 2020
work page 2020
-
[5]
Parameter- Efficient Transfer Learning for NLP .arXiv2019, arXiv:1902.00751
Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; de Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter- Efficient Transfer Learning for NLP .arXiv2019, arXiv:1902.00751
-
[6]
Choe, D.; Choi, E.; Kim, D.K. The Real-Time Mobile Application for Classifying of Endangered Parrot Species Using the CNN Models Based on Transfer Learning.Mob. Inf. Syst.2020,2020, 1–13, doi:10.1155/2020/1475164
-
[7]
Ismail Fawaz, H.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P .A. Transfer learning for time series classification. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; doi:10.1109/bigdata.2018.8621990
-
[8]
An Analysis of Deep Neural Network Models for Practical Applications.arXiv2017, arXiv:1605.07678
Canziani, A.; Paszke, A.; Culurciello, E. An Analysis of Deep Neural Network Models for Practical Applications.arXiv2017, arXiv:1605.07678
-
[9]
Benchmark Analysis of Representative Deep Neural Network Architectures
Bianco, S.; Cadene, R.; Celona, L.; Napoletano, P . Benchmark Analysis of Representative Deep Neural Network Architectures. IEEE Access2018,6, 64270–64277, doi:10.1109/access.2018.2877890
-
[10]
Zero-Shot Learning Through Cross-Modal Transfer
Socher, R.; Ganjoo, M.; Sridhar, H.; Bastani, O.; Manning, C.D.; Ng, A.Y. Zero-Shot Learning Through Cross-Modal Transfer. arXiv2013, arXiv:1301.3666
-
[11]
Zero-Shot Learning—The Good, the Bad and the Ugly.arXiv2020, arXiv:1703.04394
Xian, Y.; Schiele, B.; Akata, Z. Zero-Shot Learning—The Good, the Bad and the Ugly.arXiv2020, arXiv:1703.04394
-
[12]
Attribute-Based Classification for Zero-Shot Visual Object Categorization.IEEE T rans
Lampert, C.H.; Nickisch, H.; Harmeling, S. Attribute-Based Classification for Zero-Shot Visual Object Categorization.IEEE T rans. Pattern Anal. Mach. Intell.2014,36, 453–465, doi:10.1109/TPAMI.2013.140
-
[13]
Zero-Shot Learning via Semantic Similarity Embedding.arXiv2015, arXiv:1509.04767
Zhang, Z.; Saligrama, V . Zero-Shot Learning via Semantic Similarity Embedding.arXiv2015, arXiv:1509.04767
-
[14]
Label-Embedding for Image Classification.IEEE T rans
Akata, Z.; Perronnin, F.; Harchaoui, Z.; Schmid, C. Label-Embedding for Image Classification.IEEE T rans. Pattern Anal. Mach. Intell.2016,38, 1425–1438, doi:10.1109/tpami.2015.2487986
-
[15]
Cross-generalization: Learning novel classes from a single example by feature replacement
Bart, E.; Ullman, S. Cross-generalization: Learning novel classes from a single example by feature replacement. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 672–679, doi:10.1109/CVPR.2005.117
-
[16]
Object Classification from a Single Example Utilizing Class Relevance Metrics
Fink, M. Object Classification from a Single Example Utilizing Class Relevance Metrics. InAdvances in Neural Information Processing Systems; Saul, L., Weiss, Y., Bottou, L., Eds.; MIT Press: Cambridge, MA, USA, 2005; Volume 17
work page 2005
-
[17]
Tommasi, T.; Caputo, B. The More You Know, the Less You Learn: From Knowledge Transfer to One-shot Learning of Object Categories. In Proceedings of the BMVC, 2009. Available online: http://www.bmva.org/bmvc/2009/Papers/Paper353/Paper3 53.html (accessed on 30 November 2021)
work page 2009
-
[18]
Generalizing from a Few Examples: A Survey on Few-Shot Learning.ACM Comput
Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a Few Examples: A Survey on Few-Shot Learning.ACM Comput. Surv. 2020,53, doi:10.1145/3386252
-
[19]
Multi-Content GAN for Few-Shot Font Style Transfer.arXiv 2017, arXiv:1712.00516
Azadi, S.; Fisher, M.; Kim, V .; Wang, Z.; Shechtman, E.; Darrell, T. Multi-Content GAN for Few-Shot Font Style Transfer.arXiv 2017, arXiv:1712.00516
-
[20]
Feature Space Transfer for Data Augmentation.arXiv2019, arXiv:1801.04356
Liu, B.; Wang, X.; Dixit, M.; Kwitt, R.; Vasconcelos, N. Feature Space Transfer for Data Augmentation.arXiv2019, arXiv:1801.04356
-
[21]
Luo, Z.; Zou, Y.; Hoffman, J.; Fei-Fei, L. Label Efficient Learning of Transferable Representations across Domains and Tasks.arXiv 2017, arXiv:1712.00123
-
[22]
Transfer Learning with PipNet: For Automated Visual Analysis of Piping Design
Tan, W.C.; Chen, I.M.; Pantazis, D.; Pan, S.J. Transfer Learning with PipNet: For Automated Visual Analysis of Piping Design. In Proceedings of the 2018 IEEE 14th International Conference on Automation Science and Engineering (CASE), Munich, Germany, 20–24 August 2018; pp. 1296–1301, doi:10.1109/COASE.2018.8560550
-
[23]
On the Number of Linear Regions of Deep Neural Networks.arXiv2014, arXiv:1402.1869
Montúfar, G.; Pascanu, R.; Cho, K.; Bengio, Y. On the Number of Linear Regions of Deep Neural Networks.arXiv2014, arXiv:1402.1869
-
[24]
Kawaguchi, K.; Huang, J.; Kaelbling, L.P . Effect of Depth and Width on Local Minima in Deep Learning.Neural Comput.2019, 31, 1462–1498, doi:10.1162/neco_a_01195
-
[25]
A survey of the recent architectures of deep convolutional neural networks.Artif
Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks.Artif. Intell. Rev.2020,53, 5455–5516, doi:10.1007/s10462-020-09825-6
-
[26]
The Vanishing Gradient Problem during Learning Recurrent Neural Nets and Problem Solutions.Int
Hochreiter, S. The Vanishing Gradient Problem during Learning Recurrent Neural Nets and Problem Solutions.Int. J. Uncertain. Fuzziness Knowl.-Based Syst.1998,6, 107–116, doi:10.1142/S0218488598000094
-
[27]
Srivastava, R.K.; Greff, K.; Schmidhuber, J. Highway Networks.arXiv2015, arXiv:1505.00387
-
[28]
Squeeze-and-Excitation Networks
Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141, doi:10.1109/CVPR.2018.00745. 21 of 21
-
[29]
ImageNet Classification with Deep Convolutional Neural Networks.Adv
Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks.Adv. Neural Inf. Process. Syst.2012,25, 1097–1105
work page 2012
-
[30]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition.arXiv2014, arXiv:1409.1556
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Going deeper with convolutions
Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P .; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V .; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9, doi:10.1109/CVPR.2015.7298594
-
[32]
Deep Residual Learning for Image Recognition
He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition.arXiv2015, arXiv:1512.03385
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size.arXiv2016, arXiv:1602.07360
-
[34]
In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pp
Xie, S.; Girshick, R.; Dollar, P .; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995, doi:10.1109/CVPR.2017.634
-
[35]
Densely Connected Convolutional Networks
Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269, doi:10.1109/CVPR.2017.243
-
[36]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications.arXiv2017, arXiv:1704.04861
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Zagoruyko, S.; Komodakis, N. Wide Residual Networks.arXiv2017, arXiv:1605.07146
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices.arXiv 2017, arXiv:1707.01083
-
[39]
MnasNet: Platform-Aware Neural Architecture Search for Mobile.arXiv2019, arXiv:1807.11626
Tan, M.; Chen, B.; Pang, R.; Vasudevan, V .; Sandler, M.; Howard, A.; Le, Q.V . MnasNet: Platform-Aware Neural Architecture Search for Mobile.arXiv2019, arXiv:1807.11626
-
[40]
A Study of the Optimization Algorithms in Deep Learning
Zaheer, R.; Shaziya, H. A Study of the Optimization Algorithms in Deep Learning. In Proceedings of the 2019 Third International Conference on Inventive Systems and Control (ICISC), Coimbatore, India, 10–11 January 2019; pp. 536–539, doi:10.1109/ICISC44355.2019.9036442
-
[41]
A Comparison of Quantized Convolutional and LSTM Recurrent Neural Network Models Using MNIST
Kaziha, O.; Bonny, T. A Comparison of Quantized Convolutional and LSTM Recurrent Neural Network Models Using MNIST. In Proceedings of the 2019 International Conference on Electrical and Computing Technologies and Applications (ICECTA), Ras Al Khaimah, United Arab Emirates, 19–21 November 2019; pp. 1–5, doi:10.1109/ICECTA48151.2019.8959793
-
[42]
PyTorch: An Imperative Style, High-Performance Deep Learning Library.Adv
Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library.Adv. Neural Inf. Process. Syst.2019,32, 8024–8035
work page 2019
-
[43]
Transfer learning-based method for automated e-waste recycling in smart cities
Baker, N.A.; Szabo-Mýller, P .; Handmann, U. Transfer learning-based method for automated e-waste recycling in smart cities. EAI Endorsed T rans. Smart Cities2021,5, doi:10.4108/eai.16-4-2021.169337
-
[44]
Chen, L.; Li, S.; Bai, Q.; Yang, J.; Jiang, S.; Miao, Y. Review of Image Classification Algorithms Based on Convolutional Neural Networks.Remote Sens.2021,13, 4712, doi:10.3390/rs13224712
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.