Recognition: no theorem link
Towards Visually-Guided Movie Subtitle Translation for Indic Languages
Pith reviewed 2026-05-13 05:04 UTC · model grok-4.3
The pith
Selective visual grounding on only the weakest 20-30% of subtitle segments improves COMET scores for English-to-Indic movie translation while avoiding full visual processing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
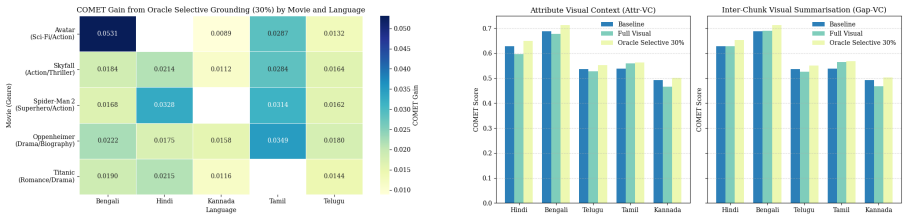
In experiments on five full-length films, indiscriminate visual grounding is ineffective due to temporal misalignment between subtitles and frames, yet oracle selective grounding that replaces only the lowest-quality 20-30% of baseline segments with outputs from either structured attribute summaries or free-text visual-gap summaries consistently raises COMET scores over the text-only baseline while using substantially less visual processing; attribute-based summaries prove more robust at capturing scene-level emotion and context.
What carries the argument
Oracle selective grounding, which identifies the lowest-quality text-only segments in advance and substitutes visual-enhanced translations only for those segments.
If this is right
- Overall translation quality for Indic languages rises on COMET without the cost of visual processing on every segment.
- Coarse attribute summaries from a sliding window capture useful cues more reliably than free-text descriptions.
- Temporal misalignment between subtitles and video frames limits the value of adding visuals indiscriminately.
- The selective method requires far less visual computation than full multimodal integration across an entire film.
Where Pith is reading between the lines
- A practical deployment would need a separate model to predict which segments are low-quality instead of relying on an oracle.
- The same selective approach could be tested on other low-resource language pairs or on different video genres such as news or lectures.
- Visual context may matter most in segments that contain action, emotion shifts, or social interactions, suggesting future detectors could focus on those cues.
Load-bearing premise
An oracle can accurately pick out the worst 20-30% of segments ahead of time and the added visual summaries will improve those segments without introducing new mistakes.
What would settle it
If replacing the oracle with a real automatic quality estimator causes the COMET gains to disappear or reverse, the selective strategy would fail to work in practice.
Figures

read the original abstract
Movie subtitle translation is inherently multimodal, yet text-only systems often miss visual cues needed to convey emotion, action, and social nuance, especially for low-resource Indic languages (English to Hindi, Bengali, Telugu, Tamil and Kannada). We present a case study on five full-length films and compare two lightweight visual grounding strategies: structured attribute summaries from a 5-minute sliding window and free-text summaries of inter-subtitle visual gaps. Our analysis shows that temporal misalignment between subtitles and frames is a major obstacle in long-form video, often rendering indiscriminate visual grounding ineffective. However, oracle selective grounding, which replaces only the lowest-quality 20-30\% of baseline segments with visual-enhanced outputs, consistently improves COMET over the text-only baseline while requiring far less visual processing. Among the two approaches, coarse attribute-based visual context summarization is more robust, capturing scene-level emotion and contextual subtle cues that text alone often misses
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts an empirical case study on subtitle translation from English to five Indic languages (Hindi, Bengali, Telugu, Tamil, Kannada) across five full-length films. It compares a text-only baseline against two lightweight visual-grounding strategies (structured attribute summaries from 5-minute sliding windows and free-text summaries of visual gaps), identifies temporal misalignment as the cause of indiscriminate grounding failures, and reports that oracle selective replacement of the lowest-quality 20-30% of segments with visual-enhanced outputs improves COMET while using less visual processing, with attribute summaries proving more robust.
Significance. If a practical reference-free proxy for the oracle can be developed, the work would usefully demonstrate how targeted visual context can address gaps in emotion and social nuance for low-resource multimodal MT. The explicit diagnosis of temporal misalignment as a load-bearing obstacle and the efficiency argument for selective rather than blanket grounding are concrete contributions supported by the film-level experiments.
major comments (1)
- The central positive result (oracle selective grounding improves COMET) depends on hindsight identification of the lowest-quality 20-30% segments via per-segment reference-based COMET scores. This selection mechanism is unavailable at inference time, and the manuscript provides no reference-free alternative (e.g., uncertainty estimation, length heuristics, or a trained selector) nor any ablation showing robustness when the oracle is replaced by a noisy proxy. This directly limits the practical significance of the reported gains.
minor comments (2)
- No error bars, statistical significance tests, or variance across the five films are reported, making it difficult to assess whether the COMET improvements are reliable or film-specific.
- Baseline details (exact model, training data, and hyper-parameters for the text-only system) and the precise definition of the 5-minute sliding window are insufficiently specified for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the oracle-based selective grounding result has practical limitations and will revise the manuscript to address this explicitly.
read point-by-point responses
-
Referee: The central positive result (oracle selective grounding improves COMET) depends on hindsight identification of the lowest-quality 20-30% segments via per-segment reference-based COMET scores. This selection mechanism is unavailable at inference time, and the manuscript provides no reference-free alternative (e.g., uncertainty estimation, length heuristics, or a trained selector) nor any ablation showing robustness when the oracle is replaced by a noisy proxy. This directly limits the practical significance of the reported gains.
Authors: We agree that the reported improvements rely on an oracle selector using reference-based per-segment COMET scores, which is unavailable at inference. The manuscript presents this explicitly as an oracle analysis to establish an upper bound on the value of targeted visual grounding and to diagnose temporal misalignment as the core obstacle to indiscriminate use. No reference-free proxy, ablation with noisy selectors, or inference-time method is included. We will revise the paper to more clearly frame the result as an oracle upper bound, expand the discussion of this limitation, and outline directions for future reference-free selectors such as uncertainty estimation or heuristics. revision: yes
Circularity Check
No circularity: empirical case study with direct measurements only.
full rationale
The paper is a straightforward empirical evaluation on five films comparing text-only baselines to two visual-grounding strategies for Indic subtitle translation. It reports measured COMET differences, notes temporal misalignment as an obstacle, and shows that oracle selection of the lowest-quality 20-30% segments yields gains. No equations, derivations, fitted parameters renamed as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear. The central result is a direct experimental comparison against an external baseline, with the oracle nature explicitly stated rather than hidden. This is self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
free parameters (2)
- 5-minute sliding window
- 20-30% replacement fraction
axioms (2)
- domain assumption COMET score is a reliable proxy for overall translation quality including emotional and contextual fidelity
- domain assumption Visual summaries extracted from frames contain cues that text subtitles lack and can be integrated without introducing contradictions
Reference graph
Works this paper leans on
-
[1]
B leu: a Method for Automatic Evaluation of Machine Translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. B leu: a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002. doi:10.3115/1073083.1073135
-
[2]
Evaluation of LLM for E nglish to H indi Legal Domain Machine Translation Systems
Singh, Kshetrimayum Boynao and Kumar, Deepak and Ekbal, Asif. Evaluation of LLM for E nglish to H indi Legal Domain Machine Translation Systems. Proceedings of the Tenth Conference on Machine Translation. 2025. doi:10.18653/v1/2025.wmt-1.57
-
[3]
Eberhard, David M. and Simons, Gary F. and Fennig, Charles D. , title =. 2025 , edition =
work page 2025
-
[4]
On the Cross-lingual Transferability of Monolingual Representations
Artetxe, Mikel and Ruder, Sebastian and Yogatama, Dani. On the Cross-lingual Transferability of Monolingual Representations. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.421
-
[5]
TRAM : Benchmarking Temporal Reasoning for Large Language Models
Wang, Yuqing and Zhao, Yun. TRAM : Benchmarking Temporal Reasoning for Large Language Models. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.382
-
[6]
Proceedings of the 5th Workshop on Vision and Language , pages=
Multi30k: Multilingual english-german image descriptions , author=. Proceedings of the 5th Workshop on Vision and Language , pages=
-
[7]
A Large-Scale C hinese Multimodal NER Dataset with Speech Clues
Sui, Dianbo and Tian, Zhengkun and Chen, Yubo and Liu, Kang and Zhao, Jun. A Large-Scale C hinese Multimodal NER Dataset with Speech Clues. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.ac...
-
[8]
Advances in neural information processing systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[9]
International conference on machine learning , pages=
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation , author=. International conference on machine learning , pages=. 2022 , organization=
work page 2022
-
[10]
Neural Machine Translation by Jointly Learning to Align and Translate , author=. 2016 , eprint=
work page 2016
-
[11]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Fastvlm: Efficient vision encoding for vision language models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[12]
Qwen2.5 Technical Report , author=
-
[13]
chr F : character n-gram F -score for automatic MT evaluation
Popovi \'c , Maja. chr F : character n-gram F -score for automatic MT evaluation. Proceedings of the Tenth Workshop on Statistical Machine Translation. 2015. doi:10.18653/v1/W15-3049
-
[14]
COMET : A Neural Framework for MT Evaluation
Rei, Ricardo and Stewart, Craig and Farinha, Ana C and Lavie, Alon. COMET : A Neural Framework for MT Evaluation. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.213
-
[15]
FastVLM: Efficient Vision Encoding for Vision Language Models , author=. 2025 , eprint=
work page 2025
-
[16]
Llama 3.1: The Llama 3.1 collection of multilingual large language models , author =. 2024 , month =
work page 2024
-
[17]
Gain, Baban and Bandyopadhyay, Dibyanayan and Mukherjee, Samrat and Adak, Chandranath and Ekbal, Asif , title =. ACM Trans. Asian Low-Resour. Lang. Inf. Process. , month = aug, articleno =. 2025 , issue_date =. doi:10.1145/3748311 , abstract =
-
[18]
Researching Subtitling Processes , pages=
Subtitling in Audiovisual Translation Studies , author=. Researching Subtitling Processes , pages=. 2025 , publisher=
work page 2025
-
[19]
A Case Study on Context-Aware Neural Machine Translation with Multi-Task Learning
Appicharla, Ramakrishna and Gain, Baban and Pal, Santanu and Ekbal, Asif and Bhattacharyya, Pushpak. A Case Study on Context-Aware Neural Machine Translation with Multi-Task Learning. Proceedings of the 25th Annual Conference of the European Association for Machine Translation (Volume 1). 2024
work page 2024
-
[20]
Singh, Kshetrimayum Boynao and Ekbal, Asif and Pakray, Partha. Evaluating I ndic T rans2 and B y T 5 for E nglish -- S antali Machine Translation Using the Ol Chiki Script. Proceedings of the 1st Workshop on Multimodal Models for Low-Resource Contexts and Social Impact (MMLoSo 2025). 2025
work page 2025
-
[21]
Does Vision Still Help? Multimodal Translation with CLIP -Based Image Selection
Kumar, Deepak and Gain, Baban and Singh, Kshetrimayum Boynao and Ekbal, Asif. Does Vision Still Help? Multimodal Translation with CLIP -Based Image Selection. Proceedings of the Twelfth Workshop on Asian Translation (WAT 2025). 2025. doi:10.18653/v1/2025.wat-1.12
-
[22]
Findings of the JUST - NLP 2025 Shared Task on E nglish-to- H indi Legal Machine Translation
Singh, Kshetrimayum Boynao and Kumar, Sandeep and Datta, Debtanu and Joshi, Abhinav and Mishra, Shivani and Paul, Shounak and Goyal, Pawan and Jain, Sarika and Ghosh, Saptarshi and Modi, Ashutosh and Ekbal, Asif. Findings of the JUST - NLP 2025 Shared Task on E nglish-to- H indi Legal Machine Translation. Proceedings of the 1st Workshop on NLP for Empower...
-
[23]
Findings of the JUST - NLP 2025 Shared Task on Summarization of I ndian Court Judgments
Datta, Debtanu and Paul, Shounak and Singh, Kshetrimayum Boynao and Kumar, Sandeep and Joshi, Abhinav and Mishra, Shivani and Jain, Sarika and Ekbal, Asif and Goyal, Pawan and Modi, Ashutosh and Ghosh, Saptarshi. Findings of the JUST - NLP 2025 Shared Task on Summarization of I ndian Court Judgments. Proceedings of the 1st Workshop on NLP for Empowering J...
-
[24]
C o E : A Clue of Emotion Framework for Emotion Recognition in Conversations
Shen, Zhiyu and Pang, Yunhe and Rao, Yanghui and Yu, Jianxing. C o E : A Clue of Emotion Framework for Emotion Recognition in Conversations. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1148
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.