Recognition: 2 theorem links
· Lean TheoremLearning Agentic Policy from Action Guidance
Pith reviewed 2026-05-13 04:57 UTC · model grok-4.3
The pith
Human action data injected as plan-style guidance lets agentic RL match SFT+RL performance without any cold-start fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ActGuide-RL injects human action data as adaptive plan-style reference guidance to overcome reachability barriers, then jointly optimizes guided and unguided rollouts under a minimal-intervention rule so that exploration gains are internalized into the final unguided policy; on search benchmarks this yields +10.7 points on GAIA and +19 points on XBench over zero RL with Qwen3-4B while matching the full SFT+RL baseline without any supervised cold start.
What carries the argument
ActGuide-RL's mixed-policy training loop that treats human action sequences as optional plan-style references and applies them only as an adaptive fallback under the minimal-intervention principle.
Load-bearing premise
Human action logs can be reliably turned into plan-style references that steer the policy past reachability barriers without creating harmful distribution shifts.
What would settle it
Measure whether performance collapses to zero-RL levels on a new task suite where human action logs cannot be formatted as usable plans.
Figures


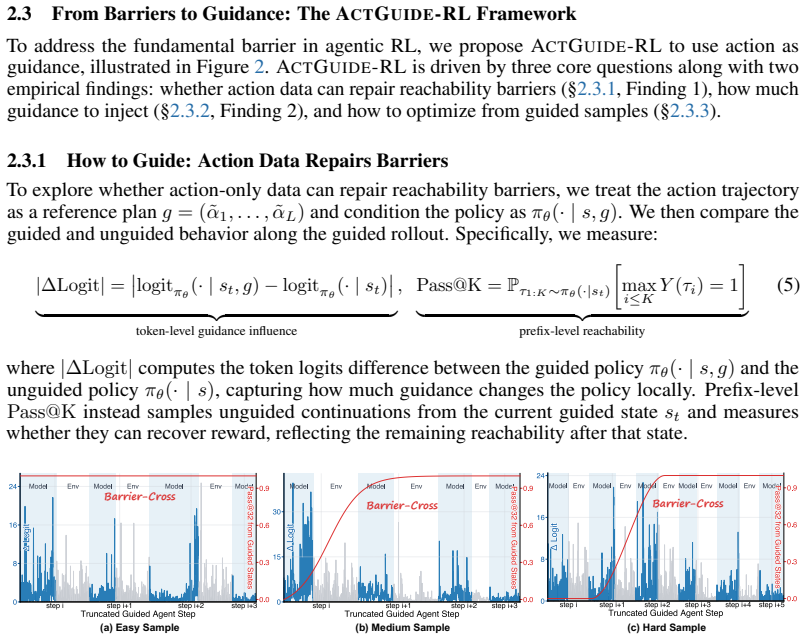





read the original abstract
Agentic reinforcement learning (RL) for Large Language Models (LLMs) critically depends on the exploration capability of the base policy, as training signals emerge only within its in-capability region. For tasks where the base policy cannot reach reward states, additional training or external guidance is needed to recover effective learning signals. Rather than relying on costly iterative supervised fine tuning (SFT), we exploit the abundant action data generated in everyday human interactions. We propose \textsc{ActGuide-RL}, which injects action data as plan-style reference guidance, enabling the agentic policy to overcome reachability barriers to reward states. Guided and unguided rollouts are then jointly optimized via mixed-policy training, internalizing the exploration gains back into the unguided policy. Motivated by a theoretical and empirical analysis of the benefit-risk trade-off, we adopt a minimal intervention principle that invokes guidance only as an adaptive fallback, matching task difficulty while minimizing off-policy risk. On search-agent benchmarks, \textsc{ActGuide-RL} substantially improves over zero RL (+10.7 pp on GAIA and +19 pp on XBench with Qwen3-4B), and performs on par with the SFT+RL pipeline without any cold start. This suggests a new paradigm for agentic RL that reduces the reliance on heavy SFT data by using scalable action guidance instead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ActGuide-RL for agentic RL in LLMs: human action data is formatted as plan-style reference guidance to overcome reachability barriers where the base policy cannot reach reward states. Guided and unguided rollouts are jointly optimized under mixed-policy training with a minimal-intervention rule (guidance as adaptive fallback) derived from a theoretical benefit-risk analysis. On search-agent benchmarks, the method reports +10.7 pp on GAIA and +19 pp on XBench (Qwen3-4B) over zero RL while matching an SFT+RL pipeline without any cold-start SFT.
Significance. If the mixed-policy training successfully internalizes exploration gains into the unguided policy, the approach offers a scalable path for agentic RL that exploits abundant human interaction data instead of costly iterative SFT. The explicit theoretical analysis of benefit-risk trade-offs and the minimal-intervention principle are positive elements that could reduce off-policy risk while still providing training signal on hard tasks.
major comments (2)
- [Section 4] Section 4 (Experiments) and associated tables: the reported gains (+10.7 pp GAIA, +19 pp XBench) are for the full ActGuide-RL system, but no unguided-only ablations or statistics on guidance invocation frequency (during training or evaluation) are provided. Without these, it is impossible to verify that mixed-policy training transfers reachability improvements to the pure unguided policy rather than the results reflecting the guided regime, directly undermining the central claim of matching SFT+RL without cold start.
- [Section 3.2] Section 3.2 (theoretical benefit-risk analysis): the minimal-intervention principle is motivated as keeping off-policy risk low by invoking guidance only as adaptive fallback, yet the manuscript provides no explicit quantification of guidance trigger rates on hard tasks, no bounds on the resulting distribution shift, and no empirical measurement of how often the unguided policy is actually updated on successful trajectories. This leaves the key assumption that exploration gains are internalized unverified.
minor comments (2)
- [Abstract and Section 3] The abstract and Section 3 could more precisely state the form of the mixed-policy objective (e.g., the weighting between guided and unguided losses) and the exact fallback condition used for guidance invocation.
- [Table 1 and Figure 2] Table 1 and Figure 2: axis labels and legend entries should explicitly distinguish guided vs. unguided evaluation modes to avoid ambiguity when interpreting the reported numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for acknowledging the theoretical analysis and potential scalability of ActGuide-RL. We address each major comment below with clarifications and commit to revisions that strengthen the evidence for internalization of exploration gains into the unguided policy.
read point-by-point responses
-
Referee: [Section 4] Section 4 (Experiments) and associated tables: the reported gains (+10.7 pp GAIA, +19 pp XBench) are for the full ActGuide-RL system, but no unguided-only ablations or statistics on guidance invocation frequency (during training or evaluation) are provided. Without these, it is impossible to verify that mixed-policy training transfers reachability improvements to the pure unguided policy rather than the results reflecting the guided regime, directly undermining the central claim of matching SFT+RL without cold start.
Authors: The reported ActGuide-RL results reflect evaluation of the policy after mixed-policy training with guidance disabled at test time, as the core objective is to internalize reachability improvements. The substantial gains over zero RL (a purely unguided baseline) provide supporting evidence of transfer. To directly address the concern and enable verification, we will add unguided-only ablations (including performance of the base policy versus the post-training unguided policy) and report guidance invocation frequencies during both training and evaluation on GAIA and XBench. These will be included in revised tables and text. revision: yes
-
Referee: [Section 3.2] Section 3.2 (theoretical benefit-risk analysis): the minimal-intervention principle is motivated as keeping off-policy risk low by invoking guidance only as adaptive fallback, yet the manuscript provides no explicit quantification of guidance trigger rates on hard tasks, no bounds on the resulting distribution shift, and no empirical measurement of how often the unguided policy is actually updated on successful trajectories. This leaves the key assumption that exploration gains are internalized unverified.
Authors: Section 3.2 derives the minimal-intervention rule from a benefit-risk analysis that limits guidance to adaptive fallback cases, thereby bounding off-policy shift by construction. We will augment the section and experiments with explicit empirical quantification of guidance trigger rates on hard tasks from the benchmarks, the derived bounds on distribution shift, and the fraction of successful trajectories used to update the unguided policy. This will provide direct verification of the internalization mechanism. revision: yes
Circularity Check
No significant circularity; claims rest on external benchmarks
full rationale
The paper's derivation proposes ActGuide-RL by injecting human action data as plan-style guidance and using mixed-policy training under a minimal-intervention rule. All reported gains (+10.7 pp GAIA, +19 pp XBench) are measured on named external benchmarks rather than quantities defined from the method. No equations, self-citations, or ansatzes are shown that reduce the internalization claim or benefit-risk analysis to a fit or definition by construction. The theoretical motivation is presented as independent analysis, and results remain falsifiable outside the paper's fitted values.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearDefinition 2.1 (Reachability Dynamics). Let Ψ(s) := sup_π P_π(Y=1|s) ... M_π_t := E_π[Ψ(s_t)] ... reachability barrier ... mass collapse
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearminimal intervention principle ... k* := min {k : max Y(τ_i^(k)) ≥ δ} ... off-policy risk R_k := Var(L_k(τ))
Reference graph
Works this paper leans on
-
[1]
Claude Opus 4.6 model card, 2026
Anthropic. Claude Opus 4.6 model card, 2026. URL https://www-cdn.anthropic.com/ bf10f64990cfda0ba858290be7b8cc6317685f47.pdf
work page 2026
-
[2]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. tau2 Bench: Eval- uating Conversational Agents in a Dual-Control Environment.arXiv preprint arXiv:2506.07982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Fine- tuning web agents: It works, but it’s trickier than you think
Massimo Caccia, Megh Thakkar, Léo Boisvert, Thibault Le Sellier De Chezelles, Alexandre Piché, Nicolas Chapados, Alexandre Drouin, Maxime Gasse, and Alexandre Lacoste. Fine- tuning web agents: It works, but it’s trickier than you think. InNeurIPS 2024 Workshop on Open-World Agents, 2024
work page 2024
-
[4]
Hardy Chen, Haoqin Tu, Fali Wang, Hui Liu, Xianfeng Tang, Xinya Du, Yuyin Zhou, and Cihang Xie. Sft or rl? an early investigation into training r1-like reasoning large vision-language models.arXiv preprint arXiv:2504.11468, 2025
-
[5]
Kaiyuan Chen, Yixin Ren, Yang Liu, Xiaobo Hu, Haotong Tian, Tianbao Xie, Fangfu Liu, Haoye Zhang, Hongzhang Liu, Yuan Gong, Chen Sun, Han Hou, Hui Yang, James Pan, Jianan Lou, Jiayi Mao, Jizheng Liu, Jinpeng Li, Kangyi Liu, Kenkun Liu, Rui Wang, Run Li, Tong Niu, Wenlong Zhang, Wenqi Yan, Xuanzheng Wang, Yuchen Zhang, Yi-Hsin Hung, Yuan Jiang, Zexuan Liu,...
-
[6]
Liang Chen, Xueting Han, Li Shen, Jing Bai, and Kam-Fai Wong. Beyond two-stage training: Cooperative sft and rl for llm reasoning.arXiv preprint arXiv:2509.06948, 2025
-
[7]
GPG: A simple and strong reinforcement learning baseline for model reasoning
Xiangxiang Chu, Hailang Huang, Xiao Zhang, Fei Wei, and Yong Wang. GPG: A simple and strong reinforcement learning baseline for model reasoning. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=inccdtfx8x
work page 2026
-
[8]
Zheng Chu, Xiao Wang, Jack Hong, Huiming Fan, Yuqi Huang, Yue Yang, Guohai Xu, Chenxiao Zhao, Cheng Xiang, Shengchao Hu, et al. Redsearcher: A scalable and cost-efficient framework for long-horizon search agents.arXiv preprint arXiv:2602.14234, 2026
-
[9]
Yanqi Dai, Yuxiang Ji, Xiao Zhang, Yong Wang, Xiangxiang Chu, and Zhiwu Lu. Harder is better: Boosting mathematical reasoning via difficulty-aware GRPO and multi-aspect question reformulation. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=nfURupkdRJ
work page 2026
-
[10]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
work page 2023
-
[11]
Yihe Deng, Hritik Bansal, Fan Yin, Nanyun Peng, Wei Wang, and Kai-Wei Chang. Open- vlthinker: Complex vision-language reasoning via iterative sft-rl cycles.arXiv preprint arXiv:2503.17352, 2025
-
[12]
Shuangrui Ding, Xuanlang Dai, Long Xing, Shengyuan Ding, Ziyu Liu, Jingyi Yang, Penghui Yang, Zhixiong Zhang, Xilin Wei, Yubo Ma, Haodong Duan, Jing Shao, Jiaqi Wang, Dahua Lin, Kai Chen, and Yuhang Zang. Wildclawbench. https://github.com/InternLM/WildClawBench,
-
[13]
Tool-star: Empowering llm-brained multi-tool reasoner via reinforcement learning
Guanting Dong, Yifei Chen, Xiaoxi Li, Jiajie Jin, Hongjin Qian, Yutao Zhu, Hangyu Mao, Guorui Zhou, Zhicheng Dou, and Ji-Rong Wen. Tool-star: Empowering llm-brained multi-tool reasoner via reinforcement learning.arXiv preprint arXiv:2505.16410, 2025
-
[14]
Agentic reinforced policy optimization
Guanting Dong, Hangyu Mao, Kai Ma, Licheng Bao, Yifei Chen, Zhongyuan Wang, Zhongxia Chen, Jiazhen Du, Huiyang Wang, Fuzheng Zhang, Guorui Zhou, Yutao Zhu, Ji-Rong Wen, and Zhicheng Dou. Agentic Reinforced Policy Optimization, July 2025. URL http://arxiv. org/abs/2507.19849. arXiv:2507.19849 [cs]. 10
-
[15]
Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence
Guanting Dong, Junting Lu, Junjie Huang, Wanjun Zhong, Longxiang Liu, Shijue Huang, Zhenyu Li, Yang Zhao, Xiaoshuai Song, Xiaoxi Li, et al. Agent-world: Scaling real-world environment synthesis for evolving general agent intelligence.arXiv preprint arXiv:2604.18292, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Lutfi Eren Erdogan, Nicholas Lee, Sehoon Kim, Suhong Moon, Hiroki Furuta, Gopala Anu- manchipalli, Kurt Keutzer, and Amir Gholami. Plan-and-act: Improving planning of agents for long-horizon tasks.arXiv preprint arXiv:2503.09572, 2025
-
[17]
Group-in-Group Policy Optimization for LLM Agent Training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-Group Policy Optimiza- tion for LLM Agent Training, May 2025. URL http://arxiv.org/abs/2505.10978. arXiv:2505.10978 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Yuqian Fu, Tinghong Chen, Jiajun Chai, Xihuai Wang, Songjun Tu, Guojun Yin, Wei Lin, Qichao Zhang, Yuanheng Zhu, and Dongbin Zhao. Srft: A single-stage method with supervised and reinforcement fine-tuning for reasoning.arXiv preprint arXiv:2506.19767, 2025
-
[19]
Beyond ten turns: Unlocking long-horizon agentic search with large-scale asynchronous rl, 2025
Jiaxuan Gao, Wei Fu, Minyang Xie, Shusheng Xu, Chuyi He, Zhiyu Mei, Banghua Zhu, and Yi Wu. Beyond ten turns: Unlocking long-horizon agentic search with large-scale asynchronous rl, 2025. URLhttps://arxiv.org/abs/2508.07976
-
[20]
Zhengyao Gu, Jonathan Light, Raul Astudillo, Ziyu Ye, Langzhou He, Henry Peng Zou, Wei Cheng, Santiago Paternain, Philip S Yu, and Yisong Yue. Actor-curator: Co-adaptive curriculum learning via policy-improvement bandits for rl post-training.arXiv preprint arXiv:2602.20532, 2026
-
[21]
Deep q-learning from demonstrations
Todd Hester, Matej Vecerik, Olivier Pietquin, Marc Lanctot, Tom Schaul, Bilal Piot, Dan Horgan, John Quan, Andrew Sendonaris, Ian Osband, et al. Deep q-learning from demonstrations. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[22]
Boosting mllm reasoning with text-debiased hint-grpo
Qihan Huang, Weilong Dai, Jinlong Liu, Wanggui He, Hao Jiang, Mingli Song, Jingyuan Chen, Chang Yao, and Jie Song. Boosting mllm reasoning with text-debiased hint-grpo. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4848–4857, 2025
work page 2025
-
[23]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Tree search for LLM agent reinforcement learning
Yuxiang Ji, Ziyu Ma, Yong Wang, Guanhua Chen, Xiangxiang Chu, and Liaoni Wu. Tree search for LLM agent reinforcement learning. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=ZpQwAFhU13
work page 2026
-
[25]
Thinking with map: Reinforced parallel map-augmented agent for geolocalization.ACL, 2026
Yuxiang Ji, Yong Wang, Ziyu Ma, Yiming Hu, Hailang Huang, Xuecai Hu, Guanhua Chen, Liaoni Wu, and Xiangxiang Chu. Thinking with map: Reinforced parallel map-augmented agent for geolocalization.ACL, 2026
work page 2026
-
[26]
Vcrl: Variance-based curriculum reinforcement learning for large language models
Guochao Jiang, Wenfeng Feng, Guofeng Quan, Chuzhan Hao, Yuewei Zhang, Guohua Liu, and Hao Wang. Vcrl: Variance-based curriculum reinforcement learning for large language models. arXiv preprint arXiv:2509.19803, 2025
-
[27]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Za- mani, and Jiawei Han. Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning, April 2025. URL http://arxiv.org/abs/2503.09516. arXiv:2503.09516 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
arXiv preprint arXiv:2507.02592 (2025)
Kuan Li, Zhongwang Zhang, Huifeng Yin, Liwen Zhang, Litu Ou, Jialong Wu, Wenbiao Yin, Baixuan Li, Zhengwei Tao, Xinyu Wang, Weizhou Shen, Junkai Zhang, Dingchu Zhang, Xixi Wu, Yong Jiang, Ming Yan, Pengjun Xie, Fei Huang, and Jingren Zhou. WebSailor: Navigating Super-human Reasoning for Web Agent, July 2025. URL http://arxiv.org/abs/2507. 02592. arXiv:250...
-
[30]
Renda Li, Hailang Huang, Fei Wei, Feng Xiong, Yong Wang, and Xiangxiang Chu. Adacurl: Adaptive curriculum reinforcement learning with invalid sample mitigation and historical revisiting. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 23123–23131, 2026
work page 2026
-
[31]
Webthinker: Empowering large reasoning models with deep research capability
Xiaoxi Li, Jiajie Jin, Guanting Dong, Hongjin Qian, Yutao Zhu, Yongkang Wu, Ji-Rong Wen, and Zhicheng Dou. WebThinker: Empowering Large Reasoning Models with Deep Research Capability, April 2025. URL http://arxiv.org/abs/2504.21776. arXiv:2504.21776 [cs]
-
[32]
arXiv preprint arXiv:2507.06892 (2025) 3
Jing Liang, Hongyao Tang, Yi Ma, Jinyi Liu, Yan Zheng, Shuyue Hu, Lei Bai, and Jianye Hao. Squeeze the soaked sponge: Efficient off-policy reinforcement finetuning for large language model.arXiv preprint arXiv:2507.06892, 2025
-
[33]
Guided exploration with proximal policy optimization using a single demonstration
Gabriele Libardi, Gianni De Fabritiis, and Sebastian Dittert. Guided exploration with proximal policy optimization using a single demonstration. InInternational Conference on Machine Learning, pages 6611–6620. PMLR, 2021
work page 2021
-
[34]
Truthfulqa: Measuring how models mimic hu- man falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic hu- man falsehoods. InProceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers), pages 3214–3252, 2022
work page 2022
-
[35]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bohan Wu, Binqi Chen, Ziyue Qiao, Qingqing Long, et al. Large language model agent: A survey on methodology, applications and challenges.arXiv preprint arXiv:2503.21460, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Lu Ma, Hao Liang, Meiyi Qiang, Lexiang Tang, Xiaochen Ma, Zhen Hao Wong, Junbo Niu, Chengyu Shen, Runming He, Yanhao Li, et al. Learning what reinforcement learning can’t: Interleaved online fine-tuning for hardest questions.arXiv preprint arXiv:2506.07527, 2025
-
[38]
SkillClaw: Let Skills Evolve Collectively with Agentic Evolver
Ziyu Ma, Shidong Yang, Yuxiang Ji, Xucong Wang, Yong Wang, Yiming Hu, Tongwen Huang, and Xiangxiang Chu. Skillclaw: Let skills evolve collectively with agentic evolver.arXiv preprint arXiv:2604.08377, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
GAIA: a benchmark for General AI Assistants
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: a benchmark for General AI Assistants, November 2023. URL http: //arxiv.org/abs/2311.12983. arXiv:2311.12983 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Minimax m2.1 system card, 2025
MiniMax. Minimax m2.1 system card, 2025. URL https://www.minimax.io/news/ minimax-m21
work page 2025
-
[41]
Over- coming exploration in reinforcement learning with demonstrations
Ashvin Nair, Bob McGrew, Marcin Andrychowicz, Wojciech Zaremba, and Pieter Abbeel. Over- coming exploration in reinforcement learning with demonstrations. In2018 IEEE international conference on robotics and automation (ICRA), pages 6292–6299. IEEE, 2018
work page 2018
-
[42]
Vaskar Nath, Elaine Lau, Anisha Gunjal, Manasi Sharma, Nikhil Baharte, and Sean Hendryx. Adaptive guidance accelerates reinforcement learning of reasoning models.arXiv preprint arXiv:2506.13923, 2025
-
[43]
Gpt-5.4 thinking system card, 2025
OpenAI. Gpt-5.4 thinking system card, 2025. URL https://openai.com/index/ gpt-5-4-thinking-system-card/
work page 2025
-
[44]
Richard Y Pang, Weizhe Yuan, Kyunghyun Cho, He He, Sainbayar Sukhbaatar, and Jason Weston. Iterative reasoning preference optimization.Advances in Neural Information Processing Systems, 37:116617–116637, 2024
work page 2024
-
[45]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. Ui-tars: Pioneering automated gui interaction with native agents.arXiv preprint arXiv:2501.12326, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Aravind Rajeswaran, Vikash Kumar, Abhishek Gupta, Giulia Vezzani, John Schulman, Emanuel Todorov, and Sergey Levine. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations.arXiv preprint arXiv:1709.10087, 2017
-
[47]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[49]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, April 2024. URL http://arxiv.org/ abs/2402.03300. arXiv:2402.03300 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Self-Distillation Enables Continual Learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-Distillation En- ables Continual Learning, January 2026. URL http://arxiv.org/abs/2601.19897. arXiv:2601.19897 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[53]
Qwen3.5: Accelerating productivity with native multimodal agents, February
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February
-
[54]
URLhttps://qwen.ai/blog?id=qwen3.5
-
[56]
Tongyi deepresearch technical report.arXiv preprint arXiv:2510.24701, 2025
Tongyi DeepResearch Team, Baixuan Li, Bo Zhang, Dingchu Zhang, Fei Huang, Guangyu Li, Guoxin Chen, Huifeng Yin, Jialong Wu, Jingren Zhou, et al. Tongyi deepresearch technical report.arXiv preprint arXiv:2510.24701, 2025
-
[57]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.Advances in Neural Information Processing Systems, 36:74952–74965, 2023
work page 2023
-
[58]
Deep reinforcement learning and the deadly triad
Hado Van Hasselt, Yotam Doron, Florian Strub, Matteo Hessel, Nicolas Sonnerat, and Joseph Modayil. Deep reinforcement learning and the deadly triad.arXiv preprint arXiv:1812.02648, 2018
-
[59]
Mel Vecerik, Todd Hester, Jonathan Scholz, Fumin Wang, Olivier Pietquin, Bilal Piot, Nicolas Heess, Thomas Rothörl, Thomas Lampe, and Martin Riedmiller. Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards.arXiv preprint arXiv:1707.08817, 2017
-
[60]
Weixun Wang, XiaoXiao Xu, Wanhe An, Fangwen Dai, Wei Gao, Yancheng He, Ju Huang, Qiang Ji, Hanqi Jin, Xiaoyang Li, et al. Let it flow: Agentic crafting on rock and roll, building the rome model within an open agentic learning ecosystem.arXiv preprint arXiv:2512.24873, 2025
-
[61]
OpenClaw-RL: Train Any Agent Simply by Talking
Yinjie Wang, Xuyang Chen, Xiaolong Jin, Mengdi Wang, and Ling Yang. Openclaw-rl: Train any agent simply by talking.arXiv preprint arXiv:2603.10165, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[62]
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
Zihan Wang, Kangrui Wang, Qineng Wang, Pingyue Zhang, Linjie Li, Zhengyuan Yang, Xing Jin, Kefan Yu, Minh Nhat Nguyen, Licheng Liu, Eli Gottlieb, Yiping Lu, Kyunghyun Cho, Jiajun Wu, Li Fei-Fei, Lijuan Wang, Yejin Choi, and Manling Li. RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning, May 2025. URL http://arxiv.org/a...
work page internal anchor Pith review arXiv 2025
-
[63]
arXiv preprint arXiv:2601.12538 , year=
Tianxin Wei, Ting-Wei Li, Zhining Liu, Xuying Ning, Ze Yang, Jiaru Zou, Zhichen Zeng, Ruizhong Qiu, Xiao Lin, Dongqi Fu, et al. Agentic reasoning for large language models.arXiv preprint arXiv:2601.12538, 2026
-
[64]
Webwalker: Benchmarking llms in web traversal.arXivpreprintarXiv:2501.07572, 2025
Jialong Wu, Wenbiao Yin, Yong Jiang, Zhenglin Wang, Zekun Xi, Runnan Fang, Linhai Zhang, Yulan He, Deyu Zhou, Pengjun Xie, and Fei Huang. WebWalker: Benchmarking LLMs in Web Traversal, August 2025. URL http://arxiv.org/abs/2501.07572. arXiv:2501.07572 [cs]
-
[65]
Yangzhen Wu, Shanda Li, Zixin Wen, Xin Zhou, Ameet Talwalkar, Yiming Yang, Wenhao Huang, and Tianle Cai. Learn hard problems during rl with reference guided fine-tuning.arXiv preprint arXiv:2603.01223, 2026
-
[66]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments, 2024
work page 2024
-
[68]
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. Learning to Reason under Off-Policy Guidance, June 2025. URL http://arxiv.org/abs/ 2504.14945. arXiv:2504.14945 [cs]
-
[69]
Rui Yang, Qianhui Wu, Zhaoyang Wang, Hanyang Chen, Ke Yang, Hao Cheng, Huaxiu Yao, Baoling Peng, Huan Zhang, Jianfeng Gao, et al. Gui-libra: Training native gui agents to reason and act with action-aware supervision and partially verifiable rl.arXiv preprint arXiv:2602.22190, 2026
-
[70]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
work page 2022
-
[71]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. tau bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains.arXiv preprint arXiv:2406.12045, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[72]
Zhiyuan Yao, Yi-Kai Zhang, Yuxin Chen, Yueqing Sun, Zishan Xu, Yu Yang, Tianhao Hu, Qi Gu, Hui Su, and Xunliang Cai. Coba-rl: Capability-oriented budget allocation for reinforcement learning in llms.arXiv preprint arXiv:2602.03048, 2026
-
[73]
Junkeun Yi, Damon Mosk-Aoyama, Baihe Huang, Ritu Gala, Charles Wang, Sugam Dipak Devare, Khushi Bhardwaj, Abhibha Gupta, Oleksii Kuchaiev, Jiantao Jiao, et al. Pivotrl: High accuracy agentic post-training at low compute cost.arXiv preprint arXiv:2603.21383, 2026
-
[74]
Ailing Yu, Lan Yao, Jingnan Liu, Zhe Chen, Jiajun Yin, Yuan Wang, Xinhao Liao, Zhiling Ye, Ji Li, Yun Yue, et al. Medresearcher-r1: Expert-level medical deep researcher via a knowledge-informed trajectory synthesis framework.arXiv preprint arXiv:2508.14880, 2025
-
[75]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?, May 2025. URL http://arxiv.org/abs/2504.13837. arXiv:2504.13837 [cs]. 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[77]
Agentevolver: Towards efficient self-evolving agent system.arXiv preprint arXiv:2511.10395, 2025
Yunpeng Zhai, Shuchang Tao, Cheng Chen, Anni Zou, Ziqian Chen, Qingxu Fu, Shinji Mai, Li Yu, Jiaji Deng, Zouying Cao, et al. Agentevolver: Towards efficient self-evolving agent system.arXiv preprint arXiv:2511.10395, 2025
-
[78]
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, Zaibin Zhang, Zelin Tan, Heng Zhou, Zhongzhi Li, Xiangyuan Xue, Yijiang Li, et al. The landscape of agentic reinforcement learning for llms: A survey.arXiv preprint arXiv:2509.02547, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[79]
Wenhao Zhang, Yuexiang Xie, Yuchang Sun, Yanxi Chen, Guoyin Wang, Yaliang Li, Bolin Ding, and Jingren Zhou. On-policy rl meets off-policy experts: Harmonizing supervised fine- tuning and reinforcement learning via dynamic weighting.arXiv preprint arXiv:2508.11408, 2026
-
[80]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[81]
Haizhong Zheng, Jiawei Zhao, and Beidi Chen. Prosperity before collapse: How far can off-policy rl reach with stale data on llms?arXiv preprint arXiv:2510.01161, 2025
-
[82]
Code2world: A gui world model via renderable code generation
Yuhao Zheng, Li’an Zhong, Yi Wang, Rui Dai, Kaikui Liu, Xiangxiang Chu, Linyuan Lv, Philip Torr, and Kevin Qinghong Lin. Code2world: A gui world model via renderable code generation. arXiv preprint arXiv:2602.09856, 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.