Recognition: no theorem link
Towards Fine-Grained Multi-Dimensional Speech Understanding: Data Pipeline, Benchmark, and Model
Pith reviewed 2026-05-13 03:56 UTC · model grok-4.3
The pith
Curated spontaneous speech data and decoupled attribute modeling let FM-Speech outperform open-source models on 14 fine-grained speech dimensions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that their FM-Speech model, trained on a high-quality spontaneous speech corpus extracted via a robust data curation pipeline, uses decoupled attribute modeling and progressive curriculum fine-tuning to achieve substantially better fine-grained, multi-dimensional understanding than current open-source speech LLMs, as measured on the new FMSU-Bench covering 14 speech attribute dimensions, while showing that existing models still require significant improvement.
What carries the argument
Decoupled attribute modeling with progressive curriculum fine-tuning, which separates handling of distinct speech attributes before staged training to build layered perception on the curated spontaneous corpus.
If this is right
- Speech LLMs can now be assessed and improved on disentangling micro-acoustic cues, acoustic scenes, and paralinguistic signals instead of coarse tasks.
- The data pipeline provides a scalable way to obtain expressive spontaneous speech for training more perceptive models.
- A new evaluation standard exists that reveals gaps in current open-source models and guides future development.
- Real-world speech systems gain a pathway toward empathetic responses based on detailed attribute understanding.
Where Pith is reading between the lines
- The same decoupled training pattern could be tested on other audio domains such as music or environmental sounds to check transfer.
- Extending FMSU-Bench to include live unscripted dialogues would test whether the gains hold outside curated sources.
- Combining the attribute modeling with visual cues from the original audiovisual sources might further improve multimodal speech understanding.
Load-bearing premise
The spontaneous speech corpus pulled from audiovisual sources is high-quality and representative with no alignment errors, and the 14 dimensions in FMSU-Bench fully capture the critical aspects of fine-grained speech perception.
What would settle it
Direct head-to-head evaluation on FMSU-Bench where FM-Speech shows no performance gain over existing open-source speech LLMs across multiple dimensions, or where the benchmark omits attributes that other models handle better, would falsify the superiority claim.
Figures
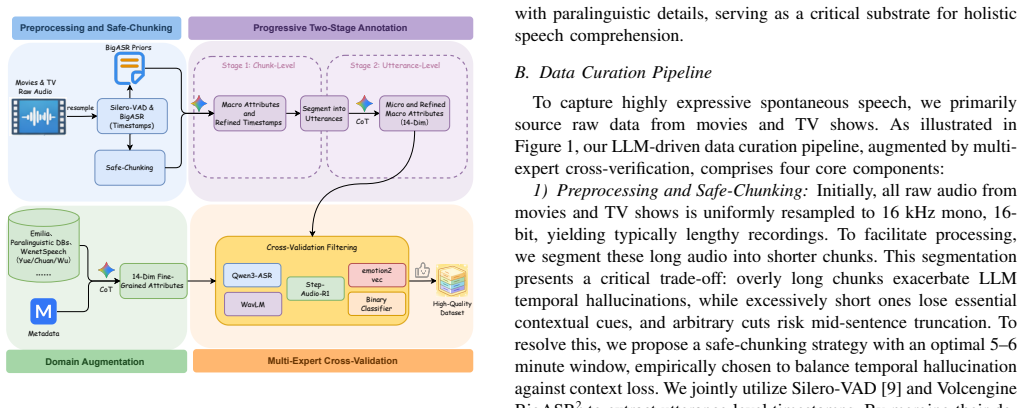
read the original abstract
While speech Large Language Models (LLMs) excel at conventional tasks like basic speech recognition, they lack fine-grained, multi-dimensional perception. This deficiency is evident in their struggle to disentangle complex features like micro-acoustic cues, acoustic scenes, and paralinguistic signals. This resulting incomplete comprehension of real-world speech fundamentally bottlenecks the development of perceptive and empathetic next-generation speech systems. At its core, this persistent perceptual limitation primarily stems from three interacting factors: scarce high-quality expressive data, absent fine-grained modeling for multi-dimensional attributes, and reliance on restricted coverage, coarse-grained benchmarks. We address these challenges through three pillars: First, our robust data curation pipeline resolves complex acoustic environments and long-audio timestamp alignment challenges to extract a high-quality spontaneous speech corpus from audiovisual sources. Second, we construct FMSU-Bench, a pioneering benchmark covering 14 speech attribute dimensions to rigorously assess the fine-grained, multi-dimensional speech understanding capabilities of current models. Third, empowered by our curated corpus, we introduce FM-Speech. Driven by a decoupled attribute modeling and progressive curriculum fine-tuning framework, it substantially elevates fine-grained, multi-dimensional acoustic perception. Extensive evaluations on FMSU-Bench reveal that current speech LLMs still require significant improvement in multi-dimensional, fine-grained understanding. In contrast, FM-Speech substantially outperforms current open-source models, establishing a robust paradigm for real-world speech understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that speech LLMs lack fine-grained multi-dimensional perception due to scarce data, absent modeling, and coarse benchmarks. It addresses this via a data curation pipeline extracting a high-quality spontaneous speech corpus from audiovisual sources (resolving acoustic environments and timestamp alignment), the FMSU-Bench benchmark spanning 14 speech attribute dimensions, and the FM-Speech model using decoupled attribute modeling plus progressive curriculum fine-tuning. Extensive evaluations purportedly show current open-source speech LLMs require significant improvement while FM-Speech substantially outperforms them, establishing a new paradigm.
Significance. If the data quality, benchmark coverage, and performance gains hold under scrutiny, the work could meaningfully advance speech LLMs toward real-world multi-dimensional understanding by providing both resources and a modeling framework; the decoupled modeling and curriculum approach is a potentially reusable idea, though its impact depends on external validation of the author-created corpus and benchmark.
major comments (3)
- [Abstract / Evaluations section] Abstract and § on evaluations: the central claim that 'FM-Speech substantially outperforms current open-source models' and that 'current speech LLMs still require significant improvement' is presented without any quantitative results, baselines, data splits, error bars, or statistical tests, which is load-bearing for assessing whether the outperformance is real or an artifact of the self-constructed benchmark.
- [Data curation pipeline] Data curation pipeline section: the assumption that the pipeline produces a 'high-quality' corpus free of alignment errors and representative of real-world spontaneous speech is unverified (no inter-annotator agreement, external validation, or error-rate quantification is described), directly undermining both the training of FM-Speech via decoupled attribute modeling and the benchmark results.
- [FMSU-Bench] FMSU-Bench construction: the claim that the 14 dimensions 'comprehensively capture' key fine-grained attributes lacks justification, ablation studies, or coverage analysis showing no critical omissions; this is load-bearing because the benchmark's validity and the 'need for significant improvement' conclusion rest on it.
minor comments (2)
- [Model / Benchmark sections] Notation for the 14 dimensions and the decoupled modeling framework should be defined more explicitly with a table or diagram for clarity.
- [Abstract] The abstract would benefit from at least one key quantitative result (e.g., average score improvement) to support the 'substantially outperforms' claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment point by point below with clarifications from the manuscript and indicate where revisions will be made to strengthen the presentation of results, validation, and justification.
read point-by-point responses
-
Referee: [Abstract / Evaluations section] Abstract and § on evaluations: the central claim that 'FM-Speech substantially outperforms current open-source models' and that 'current speech LLMs still require significant improvement' is presented without any quantitative results, baselines, data splits, error bars, or statistical tests, which is load-bearing for assessing whether the outperformance is real or an artifact of the self-constructed benchmark.
Authors: The abstract is a high-level summary without numbers by design, but the Evaluations section reports quantitative results with comparisons to open-source baselines on FMSU-Bench, including per-dimension scores and overall averages. Data splits are detailed in the benchmark construction subsection. To directly address the concern about load-bearing claims, we will revise the abstract to include key quantitative highlights (e.g., relative improvements) and expand the evaluations section with error bars and statistical tests where applicable. This will make the outperformance evidence more transparent without altering the core findings. revision: partial
-
Referee: [Data curation pipeline] Data curation pipeline section: the assumption that the pipeline produces a 'high-quality' corpus free of alignment errors and representative of real-world spontaneous speech is unverified (no inter-annotator agreement, external validation, or error-rate quantification is described), directly undermining both the training of FM-Speech via decoupled attribute modeling and the benchmark results.
Authors: The pipeline relies on automated audiovisual alignment and environment resolution techniques to handle spontaneous speech challenges, which we describe as producing higher quality than purely manual or synthetic alternatives. We acknowledge that explicit error-rate quantification and external validation steps are not detailed in the current text. In revision, we will add a validation subsection reporting sample-based manual checks for alignment accuracy, representation statistics across acoustic conditions, and any human verification performed during curation. Inter-annotator agreement is less directly applicable to the automated components but will be noted for any manual review portions. revision: yes
-
Referee: [FMSU-Bench] FMSU-Bench construction: the claim that the 14 dimensions 'comprehensively capture' key fine-grained attributes lacks justification, ablation studies, or coverage analysis showing no critical omissions; this is load-bearing because the benchmark's validity and the 'need for significant improvement' conclusion rest on it.
Authors: The 14 dimensions were chosen to span acoustic, paralinguistic, and environmental attributes drawn from established speech analysis taxonomies in the literature. To provide the requested justification, we will expand the FMSU-Bench section with explicit selection criteria, citations to prior works defining these attributes, and a coverage analysis comparing against existing benchmarks to highlight included vs. omitted areas. While exhaustive ablations of every conceivable dimension exceed the paper scope, we will include a brief discussion of why these 14 are foundational and note avenues for future extensions. revision: yes
Circularity Check
No significant circularity in empirical data, benchmark, and model construction.
full rationale
The paper describes an empirical workflow: a data curation pipeline to extract a spontaneous speech corpus, construction of FMSU-Bench covering 14 author-defined speech attribute dimensions, and introduction of FM-Speech via decoupled attribute modeling plus curriculum fine-tuning. Central claims rest on evaluations showing outperformance versus other models on the same benchmark. No equations, predictions, or first-principles derivations are present that reduce any result to inputs by construction. Self-defined dimensions and corpus are standard for new benchmarks and do not force the outperformance claim; comparisons remain externally falsifiable against other open-source models. No load-bearing self-citations, uniqueness theorems, or ansatz smuggling appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Speech LLMs can be improved via fine-tuning on curated spontaneous speech data
- ad hoc to paper Decoupled attribute modeling and progressive curriculum fine-tuning enable better multi-dimensional perception
Reference graph
Works this paper leans on
-
[1]
Librispeech: an asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: an asr corpus based on public domain audio books,” in2015 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2015, pp. 5206–5210
work page 2015
-
[2]
Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline,
H. Bu, J. Du, X. Na, B. Wu, and H. Zheng, “Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline,” in2017 20th conference of the oriental chapter of the international coordinating committee on speech databases and speech I/O systems and assessment (O-COCOSDA). IEEE, 2017, pp. 1–5
work page 2017
-
[3]
Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation,
H. He, Z. Shang, C. Wang, X. Li, Y . Gu, H. Hua, L. Liu, C. Yang, J. Li, P. Shiet al., “Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation,” in2024 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2024, pp. 885–890
work page 2024
-
[4]
Air-bench: Benchmarking large audio-language models via generative comprehension,
Q. Yang, J. Xu, W. Liu, Y . Chu, Z. Jiang, X. Zhou, Y . Leng, Y . Lv, Z. Zhao, C. Zhouet al., “Air-bench: Benchmarking large audio-language models via generative comprehension,” inProceedings of the 62nd An- nual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 1979–1998
work page 2024
-
[5]
Mmar: A challenging benchmark for deep reasoning in speech, audio, music, and their mix,
Z. Ma, Y . Ma, Y . Zhu, C. Yang, Y .-W. Chao, R. Xu, W. Chen, Y . Chen, Z. Chen, J. Conget al., “Mmar: A challenging benchmark for deep reasoning in speech, audio, music, and their mix,”arXiv preprint arXiv:2505.13032, 2025
-
[6]
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
S. Sakshi, U. Tyagi, S. Kumar, A. Seth, R. Selvakumar, O. Nieto, R. Duraiswami, S. Ghosh, and D. Manocha, “Mmau: A massive multi- task audio understanding and reasoning benchmark,”arXiv preprint arXiv:2410.19168, 2024
work page internal anchor Pith review arXiv 2024
-
[7]
J. Xu, Z. Guo, H. Hu, Y . Chu, X. Wang, J. He, Y . Wang, X. Shi, T. He, X. Zhuet al., “Qwen3-omni technical report,”arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,
A. Goel, S. Ghosh, J. Kim, S. Kumar, Z. Kong, S.-g. Lee, C.-H. H. Yang, R. Duraiswami, D. Manocha, R. Valleet al., “Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,”arXiv preprint arXiv:2507.08128, 2025
-
[9]
S. Team, “Silero vad: pre-trained enterprise-grade voice activity detector (vad), number detector and language classifier,” https://github.com/snakers4/silero-vad, 2024
work page 2024
-
[10]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosenet al., “Gem- ini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,”arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
H. Liao, Q. Ni, Y . Wang, Y . Lu, H. Zhan, P. Xie, Q. Zhang, and Z. Wu, “Nvspeech: An integrated and scalable pipeline for human- like speech modeling with paralinguistic vocalizations,”arXiv preprint arXiv:2508.04195, 2025
-
[12]
Z. Wu, D. Liu, J. Liu, Y . Wang, L. Li, L. Jin, H. Bu, P. Zhang, and M. Li, “Smiip-nv: A multi-annotation non-verbal expressive speech corpus in mandarin for llm-based speech synthesis,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 12 564–12 570
work page 2025
-
[13]
R. Ye, Y . Zhou, R. Yu, Z. Lin, K. Li, X. Li, X. Liu, G. Zeng, and Z. Wu, “A scalable pipeline for enabling non-verbal speech generation and understanding,”arXiv preprint arXiv:2508.05385, 2025
-
[14]
M. Borisov, E. Spirin, and D. Diatlova, “Nonverbaltts: A public english corpus of text-aligned nonverbal vocalizations with emotion annotations for text-to-speech,”arXiv preprint arXiv:2507.13155, 2025
-
[15]
Wenetspeech-yue: A large-scale cantonese speech corpus with multi-dimensional annotation,
L. Li, Z. Guo, H. Chen, Y . Dai, Z. Zhang, H. Xue, T. Zuo, C. Wang, S. Wang, X. Xuet al., “Wenetspeech-yue: A large-scale cantonese speech corpus with multi-dimensional annotation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 37, 2026, pp. 31 627–31 635
work page 2026
-
[16]
Y . Dai, Z. Zhang, S. Wang, L. Li, Z. Guo, T. Zuo, S. Wang, H. Xue, C. Wang, Q. Wanget al., “Wenetspeech-chuan: A large-scale sichuanese corpus with rich annotation for dialectal speech processing,”arXiv preprint arXiv:2509.18004, 2025
-
[17]
C. Wang, M. Shao, J. Hu, Z. Zhu, H. Xue, B. Mu, X. Xu, X. Duan, B. Zhang, P. Zhuet al., “Wenetspeech-wu: Datasets, benchmarks, and models for a unified chinese wu dialect speech processing ecosystem,” arXiv preprint arXiv:2601.11027, 2026
-
[18]
Common voice: A massively-multilingual speech corpus,
R. Ardila, M. Branson, K. Davis, M. Kohler, J. Meyer, M. Henretty, R. Morais, L. Saunders, F. Tyers, and G. Weber, “Common voice: A massively-multilingual speech corpus,” inProceedings of the twelfth language resources and evaluation conference, 2020, pp. 4218–4222
work page 2020
-
[19]
X. Shi, X. Wang, Z. Guo, Y . Wang, P. Zhang, X. Zhang, Z. Guo, H. Hao, Y . Xi, B. Yanget al., “Qwen3-asr technical report,”arXiv preprint arXiv:2601.21337, 2026
work page internal anchor Pith review arXiv 2026
-
[20]
emotion2vec: Self-supervised pre-training for speech emotion repre- sentation,
Z. Ma, Z. Zheng, J. Ye, J. Li, Z. Gao, S. Zhang, and X. Chen, “emotion2vec: Self-supervised pre-training for speech emotion repre- sentation,” inFindings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 15 747–15 760
work page 2024
-
[21]
Step-audio-r1 technical report,
F. Tian, X. T. Zhang, Y . Zhang, H. Zhang, Y . Li, D. Liu, Y . Deng, D. Wu, J. Chen, L. Zhaoet al., “Step-audio-r1 technical report,”arXiv preprint arXiv:2511.15848, 2025
-
[22]
T. Feng, J. Lee, A. Xu, Y . Lee, T. Lertpetchpun, X. Shi, H. Wang, T. Thebaud, L. Moro-Velazquez, D. Byrdet al., “V ox-profile: A speech foundation model benchmark for characterizing diverse speaker and speech traits,”arXiv preprint arXiv:2505.14648, 2025
-
[23]
Mmsu: A massive multi-task spoken language understanding and reasoning benchmark,
D. Wang, J. Wu, J. Li, D. Yang, X. Chen, T. Zhang, and H. Meng, “Mmsu: A massive multi-task spoken language understanding and reasoning benchmark,”arXiv preprint arXiv:2506.04779, 2025
-
[24]
Hpsu: A benchmark for human-level perception in real-world spoken speech understanding,
C. Li, P. Yang, Y . Zhong, J. Yu, Z. Wang, Z. Gou, W. Chen, and J. Yin, “Hpsu: A benchmark for human-level perception in real-world spoken speech understanding,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 37, 2026, pp. 31 536–31 544
work page 2026
-
[25]
D. Ding, Z. Ju, Y . Leng, S. Liu, T. Liu, Z. Shang, K. Shen, W. Song, X. Tan, H. Tanget al., “Kimi-audio technical report,”arXiv preprint arXiv:2504.18425, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Step-audio 2 technical report,
B. Wu, C. Yan, C. Hu, C. Yi, C. Feng, F. Tian, F. Shen, G. Yu, H. Zhang, J. Liet al., “Step-audio 2 technical report,”arXiv preprint arXiv:2507.16632, 2025
-
[27]
Omni-captioner: Data pipeline, models, and benchmark for omni detailed perception,
Z. Ma, R. Xu, Z. Xing, Y . Chu, Y . Wang, J. He, J. Xu, P.-A. Heng, K. Yu, J. Linet al., “Omni-captioner: Data pipeline, models, and benchmark for omni detailed perception,”arXiv preprint arXiv:2510.12720, 2025
-
[28]
Mimo-audio: Audio language models are few-shot learners,
D. Zhang, G. Wang, J. Xue, K. Fang, L. Zhao, R. Ma, S. Ren, S. Liu, T. Guo, W. Zhuanget al., “Mimo-audio: Audio language models are few-shot learners,”arXiv preprint arXiv:2512.23808, 2025
-
[29]
J. Xu, Z. Guo, J. He, H. Hu, T. He, S. Bai, K. Chen, J. Wang, Y . Fan, K. Dang, B. Zhang, X. Wang, Y . Chu, and J. Lin, “Qwen2.5-omni technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2503.20215
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Linet al., “Qwen2-audio technical report,”arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Swift: Software implemented fault tolerance,
G. A. Reis, J. Chang, N. Vachharajani, R. Rangan, and D. I. August, “Swift: Software implemented fault tolerance,” inInternational sympo- sium on Code generation and optimization. IEEE, 2005, pp. 243–254
work page 2005
-
[32]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catan- zaro, “Megatron-lm: Training multi-billion parameter language models using model parallelism,”arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[33]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.