Recognition: 2 theorem links
· Lean TheoremSkillGraph: Skill-Augmented Reinforcement Learning for Agents via Evolving Skill Graphs
Pith reviewed 2026-05-13 06:30 UTC · model grok-4.3
The pith
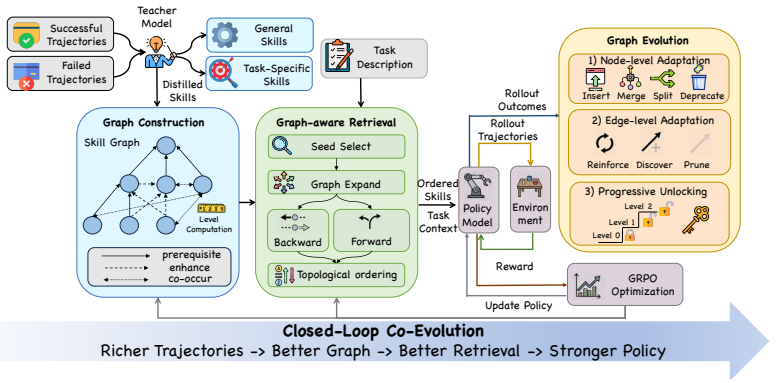
SkillGraph organizes reusable skills into an evolving directed graph so agents can retrieve ordered subgraphs that guide multi-step composition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By representing reusable skills as nodes in a directed graph with edges labeled for prerequisite, enhancement, and co-occurrence relations, SkillGraph retrieves ordered skill subgraphs to guide multi-step agent decisions and updates the graph from trajectories and RL feedback, achieving state-of-the-art performance on ALFWorld, WebShop, and search-augmented QA tasks especially when multiple skills must be combined.
What carries the argument
The directed skill graph with typed edges for prerequisite, enhancement, and co-occurrence, which enables subgraph retrieval for compositional guidance and continuous evolution from feedback.
If this is right
- Agents retrieve structured sequences of skills instead of isolated matches, supporting better multi-step planning.
- The graph structure provides cues for merging, splitting, or removing skills during maintenance.
- Both the skill library and the agent policy co-improve through the shared feedback loop.
- Performance gains are largest on tasks requiring composition of multiple skills across the tested environments.
Where Pith is reading between the lines
- Similar graph-based organization could be applied to other forms of agent memory beyond skills.
- Explicit modeling of skill relations may reduce errors in long-horizon tasks compared to implicit learning alone.
- Extending the graph to include learned edge weights could improve robustness to noisy trajectory data.
Load-bearing premise
Typed edges for prerequisite, enhancement, and co-occurrence relations can be reliably inferred and maintained from agent trajectories without introducing errors that degrade policy performance.
What would settle it
A direct comparison showing that semantic-similarity retrieval without any graph structure matches or exceeds SkillGraph performance on the same ALFWorld, WebShop, and QA benchmarks would falsify the claim that the graph structure is necessary.
Figures


read the original abstract
Skill libraries enable large language model agents to reuse experience from past interactions, but most existing libraries store skills as isolated entries and retrieve them only by semantic similarity. This leads to two key challenges for compositional tasks. Firstly, an agent must identify not only relevant skills but also how they depend on and build upon each other. Secondly, it also makes library maintenance difficult, since the system lacks structural cues for deciding when skills should be merged, split, or removed. We propose SKILLGRAPH, a framework that represents reusable skills as nodes in a directed graph, with typed edges encoding prerequisite, enhancement, and co-occurrence relations. Given a new task, SKILLGRAPH retrieves not just individual skills, but an ordered skill subgraph that can guide multi-step decision making. The graph is continuously updated from agent trajectories and reinforcement learning feedback, allowing both the skill library and the agent policy to improve together. Experiments on ALFWorld, WebShop, and seven search-augmented QA tasks show that SKILLGRAPH achieves state-of-the-art performance against memory-augmented RL methods, with especially large gains on complex tasks that require composing multiple skills.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SkillGraph, a framework representing reusable skills as nodes in a directed graph with typed edges for prerequisite, enhancement, and co-occurrence relations. Given a task, it retrieves an ordered skill subgraph to guide multi-step decisions rather than isolated skills by semantic similarity. The graph evolves continuously from agent trajectories and RL feedback to co-improve the library and policy. Experiments on ALFWorld, WebShop, and seven search-augmented QA tasks claim SOTA performance over memory-augmented RL baselines, with especially large gains on complex compositional tasks.
Significance. If the results hold, this work could meaningfully advance compositional reasoning in LLM agents by moving beyond flat skill libraries to structured, evolving graphs that encode dependencies. The joint optimization of graph and policy is a strength that may yield more robust multi-step guidance. However, significance is tempered by the absence of visible quantitative evidence or robustness checks in the provided abstract, making it unclear whether the structural approach delivers reliable gains or merely reflects unexamined inference noise.
major comments (2)
- [Abstract] Abstract: the central SOTA claim on ALFWorld, WebShop, and QA tasks is asserted without any reported numbers, baselines, ablation tables, or error bars. This is load-bearing for the paper's contribution, as the magnitude of gains on complex tasks cannot be assessed or reproduced from the given text.
- [Method] Method description (graph update procedure): the algorithm for inferring and maintaining typed edges (prerequisite, enhancement, co-occurrence) from trajectories and RL feedback is not specified, including any confidence thresholds, update rules, or error-correction mechanisms. Because the ordered subgraph retrieval is the key mechanism for compositional guidance, uncharacterized inference noise could prescribe invalid sequences and directly undermine the reported performance improvements.
minor comments (1)
- [Method] Notation for edge types and subgraph retrieval should be formalized with explicit definitions or pseudocode to improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We have addressed each major comment by revising the relevant sections to improve clarity and completeness. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central SOTA claim on ALFWorld, WebShop, and QA tasks is asserted without any reported numbers, baselines, ablation tables, or error bars. This is load-bearing for the paper's contribution, as the magnitude of gains on complex tasks cannot be assessed or reproduced from the given text.
Authors: We agree that the abstract should include key quantitative results to support the SOTA claims and allow assessment of the gains. In the revised manuscript, we have updated the abstract to report specific performance metrics on ALFWorld, WebShop, and the seven QA tasks, including success rates or scores relative to memory-augmented RL baselines and indications of variance from multiple runs. This revision makes the magnitude of improvements on compositional tasks explicit while remaining within abstract length constraints. revision: yes
-
Referee: [Method] Method description (graph update procedure): the algorithm for inferring and maintaining typed edges (prerequisite, enhancement, co-occurrence) from trajectories and RL feedback is not specified, including any confidence thresholds, update rules, or error-correction mechanisms. Because the ordered subgraph retrieval is the key mechanism for compositional guidance, uncharacterized inference noise could prescribe invalid sequences and directly undermine the reported performance improvements.
Authors: We acknowledge that the original method description provided only a high-level overview of graph evolution and omitted the precise inference algorithm. We have revised the Method section to include a detailed specification of the edge inference and maintenance procedure. This covers how prerequisite edges are inferred from sequential success patterns in trajectories, how enhancement and co-occurrence relations are derived from RL reward signals, the confidence thresholds applied for edge addition or removal, the update rules for continuous graph evolution, and error-correction mechanisms such as periodic validation against successful trajectories and pruning of low-confidence edges. These additions directly address potential inference noise and strengthen the justification for the ordered subgraph retrieval mechanism. revision: yes
Circularity Check
No significant circularity; framework self-contained against external benchmarks
full rationale
The paper defines SkillGraph as a directed graph with typed edges for prerequisite, enhancement, and co-occurrence relations, updated continuously from agent trajectories and RL feedback, then evaluates the resulting policy on independent benchmarks (ALFWorld, WebShop, search-augmented QA). No equations, self-citations, or derivations are present that reduce a claimed prediction or uniqueness result to a fitted parameter or prior self-result by construction. The graph-inference process is described at the level of a design choice rather than a mathematical identity that forces the reported gains; external task performance therefore supplies non-circular evidence.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
nodes represent skills ... typed edges capture relations such as prerequisite, enhancement, and co-occurrence ... graph-aware retrieval ... topological ordering ... graph evolution updates the graph during training by refining skill nodes and adjusting edge relations
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Path reinforcement ... w(e) ← min(w(e) + α, 1.0) ... Decay and pruning ... multiplicative decay with decay factor γ
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Memp: Exploring Agent Procedural Memory
Runnan Fang, Yuan Liang, Xiaobin Wang, Jialong Wu, Shuofei Qiao, Pengjun Xie, Fei Huang, Huajun Chen, and Ningyu Zhang. Memp: Exploring agent procedural memory.arXiv preprint arXiv:2508.06433,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Os- trow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Search-o1: Agentic search-enhanced large reasoning models
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5420–5438,
work page 2025
-
[8]
arXiv preprint arXiv:2601.02553 , year=
10 Jiaqi Liu, Yaofeng Su, Peng Xia, Siwei Han, Zeyu Zheng, Cihang Xie, Mingyu Ding, and Huaxiu Yao. Simplemem: Efficient lifelong memory for llm agents.arXiv preprint arXiv:2601.02553,
-
[9]
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
Siru Ouyang, Jun Yan, I Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long T Le, Samira Daruki, Xiangru Tang, et al. Reasoningbank: Scaling agent self-evolving with reasoning memory. arXiv preprint arXiv:2509.25140,
work page internal anchor Pith review arXiv
-
[10]
Measuring and narrowing the compositionality gap in language models
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 5687–5711,
work page 2023
-
[11]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
URL https://openreview.net/ forum?id=0IOX0YcCdTn. Hao Sun, Zile Qiao, Jiayan Guo, Xuanbo Fan, Yingyan Hou, Yong Jiang, Pengjun Xie, Yan Zhang, Fei Huang, and Jingren Zhou. Zerosearch: Incentivize the search capability of llms without searching.arXiv preprint arXiv:2505.04588,
-
[13]
arXiv preprint arXiv:2507.06229 , year=
Xiangru Tang, Tianrui Qin, Tianhao Peng, Ziyang Zhou, Daniel Shao, Tingting Du, Xinming Wei, Peng Xia, Fang Wu, He Zhu, et al. Agent kb: Leveraging cross-domain experience for agentic problem solving.arXiv preprint arXiv:2507.06229,
-
[14]
arXiv preprint arXiv:2509.25911 , year=
ISSN 2835-8856. URL https://openreview.net/forum?id=ehfRiF0R3a. Yu Wang, Ryuichi Takanobu, Zhiqi Liang, Yuzhen Mao, Yuanzhe Hu, Julian McAuley, and Xiaojian Wu. Mem-{\alpha}: Learning memory construction via reinforcement learning.arXiv preprint arXiv:2509.25911,
-
[15]
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
Rong Wu, Xiaoman Wang, Jianbiao Mei, Pinlong Cai, Daocheng Fu, Cheng Yang, Licheng Wen, Xuemeng Yang, Yufan Shen, Yuxin Wang, et al. Evolver: Self-evolving llm agents through an experience-driven lifecycle.arXiv preprint arXiv:2510.16079,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
11 Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, et al. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning.arXiv preprint arXiv:2602.08234,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
Renjun Xu and Yang Yan. Agent skills for large language models: Architecture, acquisition, security, and the path forward.arXiv preprint arXiv:2602.12430,
work page internal anchor Pith review arXiv
-
[18]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380,
work page 2018
-
[20]
arXiv preprint arXiv:2512.18746 , year=
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022a. Shunyu Yao, Jeffrey Zhao, Dian Yu, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language mo...
-
[21]
arXiv preprint arXiv:2601.03192 , year=
Shengtao Zhang, Jiaqian Wang, Ruiwen Zhou, Junwei Liao, Yuchen Feng, Zhuo Li, Yujie Zheng, Weinan Zhang, Ying Wen, Zhiyu Li, et al. Memrl: Self-evolving agents via runtime reinforcement learning on episodic memory.arXiv preprint arXiv:2601.03192,
-
[22]
Table 7: Search-augmented QA validation accuracy (%) for SKILLGRAPHover training
We report the unified step-200 checkpoint in Table 2 for a single consistent model selection rule across datasets. Table 7: Search-augmented QA validation accuracy (%) for SKILLGRAPHover training. NQ and HotpotQA are in-domain training datasets; the remaining datasets are held-out transfer evaluations. Step NQ TriviaQA PopQA HotpotQA 2Wiki MuSiQue Bamboog...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.