Recognition: 2 theorem links
· Lean TheoremThe Deepfakes We Missed: We Built Detectors for a Threat That Didn't Arrive
Pith reviewed 2026-05-13 04:56 UTC · model grok-4.3
The pith
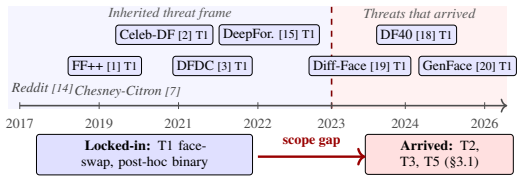
Deepfake detection research stayed locked on public-figure video manipulation while the actual harms shifted to non-consensual imagery, voice-clone scams, and emotional fraud.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
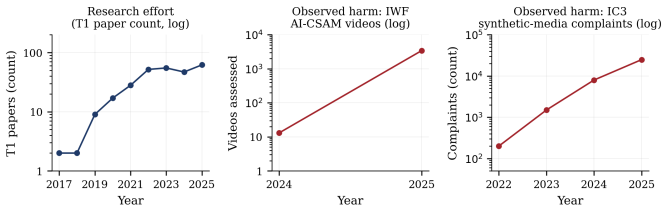
The paper establishes that the inherited threat model of public-figure face-swap and talking-head deepfakes for large-scale misinformation and evidence fraud did not materialize as anticipated, while documented incidents from 2022-2026 consist mainly of peer-generated non-consensual intimate imagery, voice-clone scam calls targeting families and finance workers, and emotional-manipulation fraud; this misalignment between sustained research focus and observed harms has become the dominant bottleneck on real-world deepfake defense.
What carries the argument
The inherited threat model of public-figure face-swap and talking-head manipulation, which continues to shape the majority of research effort, benchmarks, and detection methods despite contrary evidence from actual incident data.
If this is right
- Detection methods and benchmarks must be developed specifically for voice cloning in scam contexts.
- Research must incorporate peer-generated non-consensual intimate imagery cases rather than public-figure examples alone.
- The community should identify and address the structural reasons the old threat model persists.
- Three concrete technical research agendas should target the under-defended categories of NCII, voice scams, and emotional manipulation fraud.
Where Pith is reading between the lines
- Reallocation could improve day-to-day protection for ordinary individuals and small businesses instead of high-profile targets.
- Platform policies and law-enforcement tools might adopt new detectors faster once aligned with observed use cases.
- Similar mismatches between early threat models and later empirical patterns could be avoided in other areas of AI security research.
Load-bearing premise
The authors' accounting of 2022-2026 incidents accurately captures the dominant observed harms and that the absence of a predicted public-figure catastrophe demonstrates the inherited threat model was incorrect rather than mitigated by other unmeasured factors.
What would settle it
A clear surge in documented public-figure deepfake videos that produce measurable large-scale misinformation effects or election interference in the next two years would indicate the original threat model remains relevant.
Figures



read the original abstract
Nearly a decade of Machine Learning (ML) research on deepfake detection has been organized around a threat model inherited from 2017--2019, revolving around face-swap and talking-head manipulation of public figures, motivated by concerns about large-scale misinformation and video-evidence fraud. This position paper argues that the threat the field prepared for did not arrive, and the threats that did arrive are substantially different. An accounting of deepfake incidents in 2022--2026 shows that the dominant observed harms are peer-generated Non-Consensual Intimate Imagery (NCII), voice-clone scam calls targeting families and finance workers, and emotional-manipulation fraud. The predicted large-scale public-figure deepfake catastrophe did not materialize during the 2024 global information environment despite extensive preparation. Meanwhile, research effort, benchmarks, and detection methods remain concentrated on the inherited threat model. The central claim of this paper is that this misalignment is now the dominant bottleneck on real-world deepfake defense, not model capability. We argue the ML research community should substantially rebalance its research agenda toward the harm categories that are actually growing. We support this position with empirical accounting of research effort and harm distribution, identify the structural reasons the misalignment persists, and outline three concrete technical research agendas for the under-defended harm categories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This position paper argues that nearly a decade of ML research on deepfake detection has been organized around an inherited 2017-2019 threat model focused on face-swap and talking-head manipulations of public figures for misinformation and video-evidence fraud. An accounting of 2022-2026 incidents shows dominant observed harms are instead peer-generated NCII, voice-clone scam calls, and emotional-manipulation fraud, while the predicted public-figure catastrophe did not materialize despite the 2024 information environment. The central claim is that misalignment between research focus and actual harms is now the dominant bottleneck on real-world defense (not model capability), and the community should rebalance its agenda toward growing harm categories, supported by empirical accounting of incidents and research effort plus three concrete technical research agendas.
Significance. If the empirical accounting of incidents and research trends holds after methodological clarification, the paper could meaningfully redirect deepfake detection research toward higher-impact areas such as NCII and voice-clone defenses. Its explicit identification of structural reasons for misalignment and proposal of concrete agendas for under-defended categories is a constructive contribution for a position paper in the security and ML communities.
major comments (3)
- [Empirical accounting of harms (position and results sections)] The section describing the 2022-2026 incident accounting does not specify data sources, search criteria, inclusion/exclusion rules, or completeness assessment. This is load-bearing for the central claim that the inherited threat model was incorrect and that the listed harms are dominant, because without these details it is impossible to evaluate selection bias or the possibility that unreported/thwarted public-figure incidents were simply not captured.
- [Discussion of why the predicted catastrophe did not materialize] The argument that non-occurrence of large-scale public-figure deepfake fraud demonstrates the 2017-2019 threat model was simply wrong does not address alternative explanations such as platform moderation, early detectors, or attacker capability limits. This is load-bearing because the paper's conclusion that misalignment is the dominant bottleneck requires ruling out (or quantifying) these mitigation factors.
- [Empirical accounting of research effort] The quantification of 'research effort' and 'benchmarks' (used to claim concentration on the inherited model) lacks an explicit definition or methodology (e.g., paper counts, citation analysis, benchmark datasets surveyed). This is load-bearing for the misalignment claim.
minor comments (2)
- [Abstract and introduction] The abstract and main text use '2022--2026' inconsistently with any later date ranges; ensure uniform temporal framing.
- [Proposed research agendas] The three proposed technical research agendas would benefit from one-sentence pointers to existing datasets or evaluation protocols that could be adapted, to increase actionability.
Simulated Author's Rebuttal
We thank the referee for the insightful and constructive feedback on our position paper. We appreciate the emphasis on methodological rigor, which will help strengthen the paper's arguments. We will make revisions to provide the requested details on empirical methods and expand the discussion of alternative explanations for the non-materialization of the predicted threat. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Empirical accounting of harms (position and results sections)] The section describing the 2022-2026 incident accounting does not specify data sources, search criteria, inclusion/exclusion rules, or completeness assessment. This is load-bearing for the central claim that the inherited threat model was incorrect and that the listed harms are dominant, because without these details it is impossible to evaluate selection bias or the possibility that unreported/thwarted public-figure incidents were simply not captured.
Authors: We agree that explicit methodological details are essential for evaluating the reliability of our incident accounting. The current manuscript provides a high-level description but omits the specifics requested. In the revised version, we will insert a new subsection titled 'Data Collection Methodology' that details: (1) primary data sources including news aggregators (e.g., Google News searches), reports from organizations like the Internet Watch Foundation and cybersecurity firms, and academic compilations; (2) search criteria such as keywords ('deepfake', 'NCII', 'voice clone scam'), date range (2022-2026), and languages (English primarily with some multilingual); (3) inclusion rules (verified incidents with evidence of deepfake use) and exclusion rules (rumors without confirmation, non-deepfake manipulations); and (4) completeness assessment via cross-validation with multiple independent sources and acknowledgment of potential underreporting in certain categories. This addition will enable assessment of selection bias and support the claim that the observed harms differ from the predicted ones. revision: yes
-
Referee: [Discussion of why the predicted catastrophe did not materialize] The argument that non-occurrence of large-scale public-figure deepfake fraud demonstrates the 2017-2019 threat model was simply wrong does not address alternative explanations such as platform moderation, early detectors, or attacker capability limits. This is load-bearing because the paper's conclusion that misalignment is the dominant bottleneck requires ruling out (or quantifying) these mitigation factors.
Authors: The referee raises a valid point regarding alternative explanations. Our manuscript emphasizes the non-occurrence despite the 2024 information environment and widespread tool availability, but it does not systematically address factors like platform moderation, the impact of early detection research, or limitations in attacker capabilities. We will revise by adding a dedicated paragraph in the 'Why the Predicted Threat Did Not Materialize' section. This paragraph will discuss these alternatives, noting that while platform policies and some detection tools may have played a role, the proliferation of accessible deepfake generation tools and the high visibility of 2024 events (e.g., elections) without corresponding large-scale incidents suggests that the original threat model overestimated the scale and feasibility of such attacks. We argue that even accounting for these factors, the misalignment remains significant because the research community continued focusing on the inherited model rather than adapting to emerging harms. However, we acknowledge that fully quantifying the contribution of each factor is beyond the scope of this position paper. revision: partial
-
Referee: [Empirical accounting of research effort] The quantification of 'research effort' and 'benchmarks' (used to claim concentration on the inherited model) lacks an explicit definition or methodology (e.g., paper counts, citation analysis, benchmark datasets surveyed). This is load-bearing for the misalignment claim.
Authors: We concur that the quantification of research effort requires clearer methodology to be convincing. The manuscript currently refers to 'research effort' and 'benchmarks' in aggregate terms without specifying the approach. In the revision, we will expand the 'Research Trends' section with an explicit 'Methodology for Assessing Research Focus' subsection. This will define research effort as the number of papers published in top ML and security venues (e.g., CVPR, NeurIPS, IEEE S&P) from 2018-2025 that focus on deepfake detection, using keyword searches in Google Scholar and arXiv with terms like 'deepfake detection' and 'face swap detection'. We will also describe the survey of benchmark datasets (e.g., FaceForensics++, DFDC) and citation analysis for influential papers. This will provide a transparent basis for claiming concentration on the inherited threat model. revision: yes
Circularity Check
No significant circularity in the position paper's empirical argument
full rationale
The paper is a position paper whose central claim—that research effort is misaligned with observed deepfake harms—rests on an external accounting of 2022-2026 incidents and published research trends. No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations reduce the conclusion to its own inputs by construction. The argument is self-contained against external benchmarks of reported harms and research output, with no internal loops that force the result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The dominant observed deepfake harms from 2022-2026 consist of peer-generated NCII, voice-clone scam calls targeting families and finance workers, and emotional-manipulation fraud.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The central claim of this paper is that this misalignment is now the dominant bottleneck on real-world deepfake defense, not model capability.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
FaceForensics++: Learning to Detect Manipulated Facial Images
Andreas Rössler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Niessner. FaceForensics++: Learning to Detect Manipulated Facial Images. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1–11, 2019
work page 2019
-
[2]
Celeb-df: A large-scale challenging dataset for deepfake forensics
Yuezun Li, Xin Yang, Pu Sun, Honggang Qi, and Siwei Lyu. Celeb-df: A large-scale challenging dataset for deepfake forensics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3207–3216, 2020
work page 2020
-
[3]
The DeepFake Detection Challenge (DFDC) Dataset
Brian Dolhansky, Joanna Bitton, Ben Pflaum, Jikuo Lu, Russ Howes, Menglin Wang, and Cristian Canton Ferrer. The deepfake detection challenge (dfdc) dataset.arXiv preprint arXiv:2006.07397, 2020
work page internal anchor Pith review arXiv 2006
-
[4]
Ruben Tolosana, Ruben Vera-Rodriguez, Julian Fierrez, Aythami Morales, and Javier Ortega- Garcia. Deepfakes and beyond: A survey of face manipulation and fake detection.Information Fusion, 64:131–148, 2020
work page 2020
-
[5]
The creation and detection of deepfakes: A survey.ACM Computing Surveys (CSUR), 54(1):1–41, 2021
Yisroel Mirsky and Wenke Lee. The creation and detection of deepfakes: A survey.ACM Computing Surveys (CSUR), 54(1):1–41, 2021
work page 2021
-
[6]
World Economic Forum. The global risks report 2024. Technical report, World Economic Forum, Geneva, Switzerland, 2024. 19th Edition. Accessed 2026-03-03
work page 2024
-
[7]
Bobby Chesney and Danielle Citron. Deep fakes: A looming challenge for privacy, democracy, and national security.California Law Review, 107:1753, 2019
work page 2019
-
[8]
Felix M. Simon and Sacha Altay. Don’t panic (yet): Assessing the evidence and discourse around generative AI and elections. Technical report, Knight First Amendment Institute at Columbia University, 2025. Accessed 2026-04-22
work page 2025
-
[9]
Preparing to fight AI-backed voter suppression
Mekela Panditharatne. Preparing to fight AI-backed voter suppression. Technical report, Brennan Center for Justice, April 2024. Accessed 2026-04-22
work page 2024
-
[10]
IC3 annual internet crime reports
Internet Crime Complaint Center (IC3), Federal Bureau of Investigation. IC3 annual internet crime reports. https://www.ic3.gov/AnnualReport/Reports, 2026. Annual analysis of cybercrime complaints, trends, and financial losses reported to the FBI. Accessed 2026-04-22
work page 2026
-
[11]
Harm without limits: AI child sexual abuse material through the eyes of our analysts
Internet Watch Foundation. Harm without limits: AI child sexual abuse material through the eyes of our analysts. Technical report, Internet Watch Foundation, 2026. Accessed 2026-04-23
work page 2026
-
[12]
AI incident database: Catalog of real-world AI harms and failures
Responsible AI Collaborative. AI incident database: Catalog of real-world AI harms and failures. https://incidentdatabase.ai/, 2026. Open-source repository documenting AI incidents, harms, near-misses, and failures. Accessed 2026-04-22
work page 2026
-
[13]
Nicola Henry and Anastasia Powell. Technology-facilitated sexual violence: A literature review of empirical research.Trauma, Violence, & Abuse, 19(2):195–208, 2018
work page 2018
-
[14]
Ai-assisted fake porn is here and we’re all fucked.Motherboard (Vice), December 2017
Samantha Cole. Ai-assisted fake porn is here and we’re all fucked.Motherboard (Vice), December 2017. Published 11 December 2017; accessed 2026-04-22
work page 2017
-
[15]
DeeperForensics-1.0: A large-scale dataset for real-world face forgery detection
Liming Jiang, Ren Li, Wayne Wu, Chen Qian, and Chen Change Loy. DeeperForensics-1.0: A large-scale dataset for real-world face forgery detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2886–2895, 2020. 10
work page 2020
-
[16]
Tianfei Zhou, Wenguan Wang, Zhiyuan Liang, and Jianbing Shen. Face forensics in the wild. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5778–5788, 2021
work page 2021
-
[17]
Nguyen, Junichi Yamagishi, and Isao Echizen
Trung-Nghia Le, Huy H. Nguyen, Junichi Yamagishi, and Isao Echizen. OpenForensics: Large- scale challenging dataset for multi-face forgery detection and segmentation in-the-wild. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10117–10127, 2021
work page 2021
-
[18]
DF40: Toward next-generation deepfake detection
Zhiyuan Yan, Taiping Yao, Shen Chen, Yandan Zhao, Xinghe Fu, Junwei Zhu, Donghao Luo, Chengjie Wang, Shouhong Ding, Yunsheng Wu, et al. DF40: Toward next-generation deepfake detection. InAdvances in Neural Information Processing Systems (NeurIPS), volume 37, pages 29387–29434, 2024
work page 2024
-
[19]
Diffusionface: Towards a comprehensive dataset for diffusion-based face forgery analysis,
Zhongxi Chen, Ke Sun, Ziyin Zhou, Xianming Lin, Xiaoshuai Sun, Liujuan Cao, and Rongrong Ji. DiffusionFace: Towards a comprehensive dataset for diffusion-based face forgery analysis. arXiv preprint arXiv:2403.18471, 2024
-
[20]
Yaning Chen, Hongchen Zhao, Huiling Liu, Shuying Li, Kunhua Huang, and Jun Yang. GenFace: A large-scale fine-grained face forgery benchmark and cross appearance-edge learning.IEEE Transactions on Information F orensics and Security, 2024
work page 2024
-
[21]
DeepfakeBench: A comprehensive benchmark of deepfake detection
Zhiyuan Yan, Yong Zhang, Xinhang Yuan, Siwei Lyu, and Baoyuan Wu. DeepfakeBench: A comprehensive benchmark of deepfake detection. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[22]
Enes Altuncu, Virginia N. L. Franqueira, and Shujun Li. Deepfake: Definitions, performance metrics and standards, datasets, and a meta-review.Frontiers in Big Data, 7, 2024
work page 2024
-
[23]
Zhizheng Wu, Junichi Yamagishi, Tomi Kinnunen, Cemal Hanilçi, Mohammed Sahidullah, Aleksandr Sizov, Nicholas Evans, Massimiliano Todisco, and Hector Delgado. Asvspoof: The automatic speaker verification spoofing and countermeasures challenge.IEEE Journal of Selected Topics in Signal Processing, 11(4):588–604, 2017
work page 2017
- [24]
-
[25]
Zhixi Cai, Shreya Ghosh, Abhinav Dhall, Tom Gedeon, Kalin Stefanov, and Munawar Hayat. Glitch in the matrix: A large scale benchmark for content driven audio-visual forgery detection and localization.Computer Vision and Image Understanding, 236:103818, 2023
work page 2023
-
[26]
A V-Deepfake1M: A large-scale LLM-driven audio-visual deepfake dataset
Zhixi Cai, Shreya Ghosh, Aman Pankaj Adatia, Munawar Hayat, Abhinav Dhall, Tom Gedeon, and Kalin Stefanov. A V-Deepfake1M: A large-scale LLM-driven audio-visual deepfake dataset. InProceedings of the 32nd ACM International Conference on Multimedia (MM ’24), pages 7414–7423, Melbourne, VIC, Australia, 2024
work page 2024
-
[27]
South korea: The deepfake crisis engulfing hundreds of schools, September 2024
Jean Mackenzie and Laura Choi. South korea: The deepfake crisis engulfing hundreds of schools, September 2024. Accessed 2024-09-03
work page 2024
-
[28]
799 students, 31 teachers victimized by deepfake videos this year: Education ministry
Yonhap. 799 students, 31 teachers victimized by deepfake videos this year: Education ministry. The Korea Times, October 2024. Accessed 2024-10-30
work page 2024
-
[29]
Finance worker pays out $25 million after video call with deepfake ‘chief financial officer’
Heather Chen and Kathleen Magramo. Finance worker pays out $25 million after video call with deepfake ‘chief financial officer’. CNN, February 2024. Accessed 2026-04-17
work page 2024
-
[30]
AI ’resurrects’ long dead dictator in murky new era of deepfake electioneering
Heather Chen and Kathleen Magramo. AI ’resurrects’ long dead dictator in murky new era of deepfake electioneering. CNN, February 2024. Accessed 2026-04-22
work page 2024
-
[31]
Incident 573: Deepfake Recordings Allegedly Influence Slo- vakian Election
Responsible AI Collaborative. Incident 573: Deepfake Recordings Allegedly Influence Slo- vakian Election. AI Incident Database, 2023. Accessed 2026-04-22
work page 2023
-
[32]
Federal Communications Commission. FCC Issues $6M Fine for N.H. Robocalls Using Biden Deepfake V oice. FCC Enforcement Bureau, September 2024. Accessed 2026-04-22. 11 A Corpus Construction This appendix documents the construction of the 438-paper research-effort corpus used in Section 3.1. We describe the collection pipeline, filtering steps, and final co...
work page 2024
-
[33]
Core-term filter.Required a deepfake or synthetic-media vocabulary match (“deepfake”, “face-swap”, “face reenactment”, “talking head”, “voice clone”, “voice spoof”, “audio spoof”, “synthetic speech”, “synthetic video”, “face forgery”, “facial manipulation”, “gen- erative video”, “audio-visual deepfake”, “ASVspoof”, “content provenance”, “C2PA”, “non-conse...
-
[34]
International Journal For Multidisciplinary Research
Predatory-venue block.Dropped records from a block-list of predatory or non-peer- reviewed outlets (IJRASET, IJSREM, IJFMR, “International Journal For Multidisciplinary Research”, “International Journal of Scientific Research in Engineering and Management”, and similar). 206 records dropped; 5,065 remained
-
[35]
9 records dropped; 5,056 remained
Non-research type filter.Dropped errata, editorials, letters, library guides, peer-review records, and paratext. 9 records dropped; 5,056 remained
-
[36]
Year-scaled citation threshold.Applied a minimum citation count that scales with re- cency, reflecting the intuition that older uncited papers represent essentially zero research- community engagement while recent preprints should be given the benefit of the doubt. Thresholds: ≥10 citations for 2017–2020, ≥5 for 2021–2022, ≥3 for 2023, ≥1 for 2024, and no...
work page 2017
-
[37]
54 records dropped; 3,782 remained
Preprint deduplication.When the same normalized title appeared at both an arXiv/preprint venue and a peer-reviewed venue, we kept only the peer-reviewed copy. 54 records dropped; 3,782 remained
-
[38]
Year hold-out.Records dated 2026 were held out of the main research-effort corpus to avoid mixing partially-reported publication years into the year-by-year trend. 658 records held out; 3,124 constituted the full scoped corpus. From the 3,124-paper scoped corpus we constructed theresearch-effort corpusused in Section 3.1 by applying a major-venue filter. ...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.