Recognition: 2 theorem links
· Lean TheoremIntermediate Artifacts as First-Class Citizens: A Data Model for Durable Intermediate Artifacts in Agentic Systems
Pith reviewed 2026-05-13 04:34 UTC · model grok-4.3
The pith
AI agentic systems should store intermediate work products as durable, typed, versioned data objects that later steps and humans can inspect and revise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
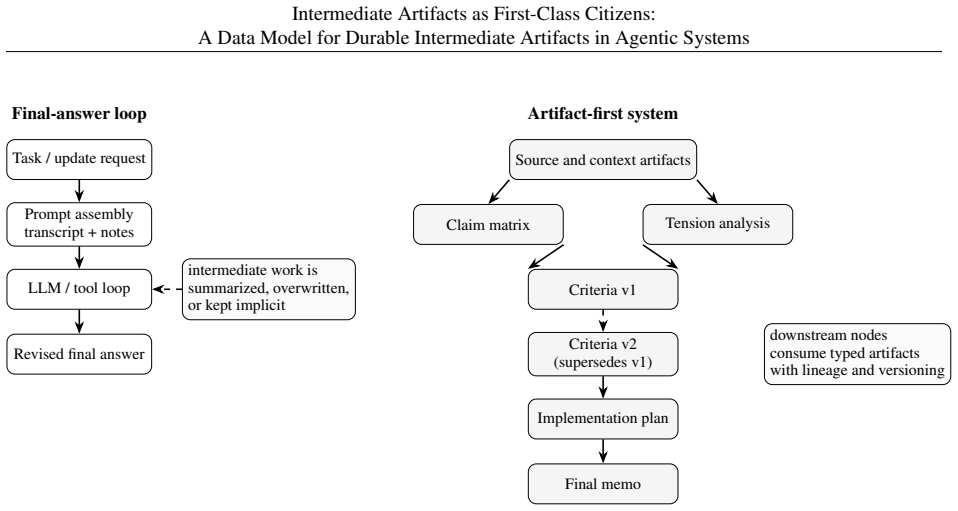
The paper presents a data model in which intermediate artifacts become first-class, durable objects: typed, structured, addressable, versioned, dependency-aware, authoritative, and consumable by other computation. These objects receive explicit additive and superseding update semantics with current-state resolution rules. Lineage tracking keeps the artifacts consistent across revisions. The model treats evaluation as a question of maintained-state quality rather than final-output quality alone.
What carries the argument
Durable intermediate artifact: a structured, addressable, versioned data object that represents maintained work products such as evidence maps or plans and carries explicit dependencies and update semantics so downstream computation can consume or revise it directly.
If this is right
- Artifact lineage supplies durable intermediate state that survives revisions without requiring regeneration.
- Evaluation of agentic systems must measure quality of the preserved artifacts, not only the final output.
- Downstream agents can consume and extend specific artifacts directly rather than re-deriving lost context.
- Humans gain direct access to edit or supersede individual artifacts instead of rewriting entire final products.
Where Pith is reading between the lines
- The model could be added to existing agent runtimes to give persistent, queryable memory of reasoning steps.
- Collaborative workflows become possible when multiple agents and users edit the same shared artifact set over time.
- A practical test would measure whether agents that read prior artifacts produce fewer redundant steps than agents that start from scratch each time.
Load-bearing premise
Final outputs lose important details from earlier steps, and preserving the intermediates as durable objects will improve inspectability and revisability without adding meaningful overhead.
What would settle it
Compare revision time and error rate for a human editor fixing a multi-step agent task when only the final artifact is available versus when the full set of typed, versioned intermediate artifacts and their lineage are also present.
Figures
read the original abstract
Many AI systems are organized around loops in which models reason, call tools, observe results, and continue until a task is complete. These systems often produce final artifacts such as memos, plans, recommendations, and analyses, while the intermediate work that shaped those outputs remains ephemeral. For multi-step, revisable AI work, final artifacts are often lossy projections over upstream state. We argue that such systems should preserve durable, inspectable intermediate artifacts: typed, structured, addressable, versioned, dependency-aware, authoritative, and consumable by downstream computation. These artifacts are not the model's private chain-of-thought. They are maintained work products such as evidence maps, claim structures, criteria, assumptions, plans, transformation rules, synthesis procedures, unresolved tensions, and partial products that later humans and agents can inspect, revise, supersede, and improve. The contribution is a systems-level data model. We distinguish intermediate artifacts from chat transcripts, memory, hidden chain-of-thought, narration, thinking, and final answers; formalize additive and superseding update semantics with explicit current-state resolution; describe how artifact lineage supports durable intermediate state across revisions; and argue that evaluation must target maintained-state quality, not only final-output quality. The claim is not that artifacts make models smarter. It is that durable intermediate artifacts make AI-generated work more inspectable, revisable, and maintainable over time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that agentic AI systems organized around reasoning-tool-observation loops often produce final artifacts that are lossy projections of upstream state because intermediate work remains ephemeral. It argues that such systems should instead preserve durable, inspectable intermediate artifacts that are typed, structured, addressable, versioned, dependency-aware, authoritative, and consumable by downstream computation. These artifacts include evidence maps, claim structures, criteria, assumptions, plans, transformation rules, synthesis procedures, unresolved tensions, and partial products. The contribution is a systems-level data model that distinguishes intermediate artifacts from chat transcripts, memory, hidden chain-of-thought, narration, thinking, and final answers; formalizes additive and superseding update semantics with explicit current-state resolution; describes how artifact lineage supports durable intermediate state across revisions; and advocates evaluating maintained-state quality rather than only final-output quality.
Significance. If the distinctions and update semantics hold in practice, the framework could meaningfully shift agentic system design toward greater long-term inspectability, revisability, and maintainability by treating intermediate work products as persistent, queryable entities. The paper's strengths include its self-contained conceptual framework, clear separation of artifact types, and explicit formalization of additive/superseding semantics and lineage mechanics, which provide a reusable vocabulary for future implementations even without empirical validation or machine-checked proofs.
major comments (1)
- [Data model and lineage mechanics] The manuscript describes the data model and lineage mechanics at a systems level but supplies neither asymptotic bounds, storage growth estimates under realistic revision patterns, nor any prototype measurements for maintaining the artifact graph in long-running agent loops. This is load-bearing for the central claim that durable intermediates will improve inspectability and maintainability without introducing prohibitive overhead or complexity.
minor comments (2)
- The abstract and introduction would benefit from one or two concrete, worked examples contrasting an ephemeral intermediate state with its durable counterpart to illustrate the claimed lossiness of final artifacts.
- [Data model description] The terms 'authoritative' and 'consumable' are introduced without explicit definitions or operational criteria, which could lead to inconsistent interpretations when the model is applied.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for identifying a point that merits clarification. The manuscript is a conceptual contribution focused on a systems-level data model, distinctions among artifact types, and update/lineage semantics. We address the major comment below and have made a targeted revision to acknowledge practical considerations without altering the paper's scope.
read point-by-point responses
-
Referee: The manuscript describes the data model and lineage mechanics at a systems level but supplies neither asymptotic bounds, storage growth estimates under realistic revision patterns, nor any prototype measurements for maintaining the artifact graph in long-running agent loops. This is load-bearing for the central claim that durable intermediates will improve inspectability and maintainability without introducing prohibitive overhead or complexity.
Authors: We agree that concrete performance data would strengthen any claim about non-prohibitive overhead. However, the manuscript's central claim concerns the semantic and structural properties that make durable intermediates inspectable, revisable, and authoritative, rather than a performance guarantee for a particular implementation. The data model is deliberately implementation-agnostic: it specifies typed, versioned, dependency-aware entities with additive and superseding update rules, but leaves storage representation, indexing, and retention policies to concrete systems. Lineage mechanics explicitly support superseding and current-state resolution, which in principle permit pruning of obsolete versions and delta-based storage—standard techniques that avoid unbounded growth. Because the paper does not present or evaluate an implementation, we do not supply asymptotic bounds or prototype measurements; doing so would require choosing specific data structures and workloads outside the stated contribution. We have added a brief discussion paragraph noting that storage overhead is governed by implementation choices (e.g., retention policies, garbage collection of superseded artifacts) and that the model's explicit versioning and dependency tracking are intended to make such management feasible rather than to eliminate it. revision: partial
Circularity Check
No circularity in conceptual data model proposal
full rationale
The paper is a systems-level conceptual proposal that defines durable intermediate artifacts, distinguishes them from chat transcripts and chain-of-thought, formalizes additive/superseding semantics, and argues for improved inspectability without any equations, derivations, fitted parameters, or predictions. No load-bearing steps reduce to self-definition, self-citation chains, or renamed known results; the framework is self-contained against external benchmarks and contains no internal circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Final artifacts in AI systems are lossy projections that discard useful upstream state
- domain assumption Durable, typed, versioned artifacts will improve inspectability and maintainability
invented entities (1)
-
Durable intermediate artifacts data model
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We argue that such systems should preserve durable, inspectable intermediate artifacts: typed, structured, addressable, versioned, dependency-aware, authoritative, and consumable by downstream computation.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Additive versus superseding update semantics... current-state resolution
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
ReAct: Syn- ergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Thomas Narasimhan, and Yuan Cao. ReAct: Syn- ergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations, 2023. 16 Intermediate Artifacts as First-Class Citizens: A Data Model for Durable Intermediate Artifacts in Agentic Systems
work page 2023
-
[2]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dess `ı, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language Models Can Teach Themselves to Use Tools. In Advances in Neural Information Processing Systems, 2023
work page 2023
-
[3]
CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: Communicative Agents for “Mind” Exploration of Large Language Model Society. arXiv:2303.17760, 2023
work page internal anchor Pith review arXiv 2023
-
[4]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An Open-Ended Embodied Agent with Large Language Models. arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and J¨urgen Schmid- huber. MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. arXiv:2308.00352, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. arXiv:2308.08155, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Show Your Work: Scratchpads for Intermediate Computation with Language Models
Max Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, Samy Bengio, and others. Show Your Work: Scratchpads for Inter- mediate Computation with Language Models. arXiv:2112.00114, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems, 2022
work page 2022
-
[9]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-Consistency Improves Chain of Thought Reasoning in Language Models. InInternational Conference on Learning Representations, 2023
work page 2023
-
[10]
Wei, Tianyi Zhou, Xuezhi Wang, Dale Schuurmans, Claire Cui, Hao Bian, and others
Denny Zhou, Nathanael Sch ¨arli, Le Hou, Jason Wei, Jason Y . Wei, Tianyi Zhou, Xuezhi Wang, Dale Schuurmans, Claire Cui, Hao Bian, and others. Least-to-Most Prompting Enables Complex Reasoning in Large Language Models. InInternational Conference on Learning Representations, 2023
work page 2023
-
[11]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[12]
Re- flexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Re- flexion: Language Agents with Verbal Reinforcement Learning. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[13]
Self-Refine: Iterative Refinement with Self-Feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, and others. Self-Refine: Iterative Refinement with Self-Feedback. In Advances in Neural Information Processing Systems, 2023
work page 2023
-
[14]
Language agent tree search unifies reasoning, acting, and planning in language models
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. Language Agent Tree Search Unifies Reasoning, Acting, and Planning in Language Models. arXiv:2310.04406, 2023
- [15]
-
[16]
Natural-Language Agent Harnesses
Linyue Pan, Lexiao Zou, Shuo Guo, Jingchen Ni, and Hai-Tao Zheng. Natural-Language Agent Harnesses. arXiv:2603.25723, 2026
-
[17]
Yuxuan Zhang, Haoyang Yu, Lanxiang Hu, Haojian Jin, and Hao Zhang. General Modular Harness for LLM Agents in Multi-Turn Gaming Environments. arXiv:2507.11633, 2025
-
[18]
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent Workflow Memory. arXiv:2409.07429, 2024
work page internal anchor Pith review arXiv 2024
-
[19]
Shengda Fan, Xin Cong, Yuepeng Fu, Zhong Zhang, Shuyan Zhang, Yuanwei Liu, Yesai Wu, Yankai Lin, Zhiyuan Liu, and Maosong Sun. WorkflowLLM: Enhancing Workflow Orchestration Capability of Large Lan- guage Models. arXiv:2411.05451, 2024
-
[20]
LEGOMem : Modular procedural memory for multi-agent LLM systems for workflow automation, 2025
Dongge Han, Camille Couturier, Daniel Madrigal Diaz, Xuchao Zhang, Victor R ¨uhle, and Saravan Rajmo- han. LEGOMem: Modular Procedural Memory for Multi-agent LLM Systems for Workflow Automation. arXiv:2510.04851, 2025. 17 Intermediate Artifacts as First-Class Citizens: A Data Model for Durable Intermediate Artifacts in Agentic Systems
-
[21]
Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Hinrich Sch¨utze, V olker Tresp, and Yunpu Ma. Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning. arXiv:2508.19828, 2025
work page internal anchor Pith review arXiv 2025
-
[22]
Luiz C. Borro, Luiz A. B. Macarini, Gordon Tindall, Michael Montero, and Adam B. Struck. Memori: A Persistent Memory Layer for Efficient, Context-Aware LLM Agents. arXiv:2603.19935, 2026
-
[23]
From Agent Loops to Deterministic Graphs: Execution Lineage for Reproducible AI-Native Work
Josh Rosen and Seth Rosen. From Agent Loops to Deterministic Graphs: Execution Lineage for Reproducible AI-Native Work. arXiv:2605.06365, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Dryad: Distributed Data-Parallel Programs from Sequential Building Blocks
Michael Isard, Mihai Budiu, Yuan Yu, Andrew Birrell, and Dennis Fetterly. Dryad: Distributed Data-Parallel Programs from Sequential Building Blocks. InEuroSys, 2007
work page 2007
-
[25]
Franklin, Scott Shenker, and Ion Stoica
Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, and Ion Stoica. Spark: Cluster Com- puting with Working Sets. InUSENIX HotCloud, 2010
work page 2010
-
[26]
Apache Software Foundation. Airflow Documentation: DAGs.https://airflow.apache.org/docs/ apache-airflow/3.0.4/core-concepts/dags.html, accessed May 6, 2026
work page 2026
-
[27]
dbt Developer Hub.https://docs.getdbt.com/, accessed May 6, 2026
dbt Labs. dbt Developer Hub.https://docs.getdbt.com/, accessed May 6, 2026
work page 2026
-
[28]
Why and Where: A Characterization of Data Prove- nance
Peter Buneman, Sanjeev Khanna, and Wang-Chiew Tan. Why and Where: A Characterization of Data Prove- nance. InInternational Conference on Database Theory, 2001
work page 2001
-
[29]
Juliana Freire, David Koop, Emanuele Santos, and Claudio T. Silva. Provenance for Computational Tasks: A Survey.Computing in Science & Engineering, 10(3):11–21, 2008
work page 2008
-
[30]
LLM Agents for Interactive Workflow Provenance: Reference Architecture and Evaluation Methodology
Renan Souza, Timothy Poteet, Brian Etz, Daniel Rosendo, Amal Gueroudji, Woong Shin, Prasanna Balaprakash, and Rafael Ferreira da Silva. LLM Agents for Interactive Workflow Provenance: Reference Architecture and Evaluation Methodology. arXiv:2509.13978, 2025
-
[31]
Donald E. Knuth. Literate Programming.The Computer Journal, 27(2):97–111, 1984
work page 1984
-
[32]
Jupyter Notebooks – a Publishing Format for Reproducible Computational Workflows
Thomas Kluyver, Benjamin Ragan-Kelley, Fernando P´erez, Brian Granger, Matthias Bussonnier, Jonathan Fred- eric, Kyle Kelley, Jessica Hamrick, Jason Grout, Sylvain Corlay, and others. Jupyter Notebooks – a Publishing Format for Reproducible Computational Workflows. InPositioning and Power in Academic Publishing: Players, Agents and Agendas, 2016
work page 2016
-
[33]
MLIR: Scaling Compiler Infrastructure for Do- main Specific Computation
Chris Lattner, Jacques Pienaar, Mehdi Amini, Uday Bondhugula, River Riddle, Albert Cohen, Tatiana Shpeis- man, Andy Davis, Nicolas Vasilache, and Oleksandr Zinenko. MLIR: Scaling Compiler Infrastructure for Do- main Specific Computation. InInternational Symposium on Code Generation and Optimization, 2021
work page 2021
-
[34]
Knowledge Graphs.ACM Computing Surveys, 54(4):1–37, 2021
Aidan Hogan, Eva Blomqvist, Michael Cochez, Claudia d’Amato, Gerard de Melo, Claudio Gutierrez, Sabrina Kirrane, Jos Lehmann, Roberto Navigli, Axel Polleres, and others. Knowledge Graphs.ACM Computing Surveys, 54(4):1–37, 2021. 18
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.