Recognition: no theorem link
Large Language Models as Amortized Pareto-Front Generators for Constrained Bi-Objective Convex Optimization
Pith reviewed 2026-05-13 06:20 UTC · model grok-4.3
The pith
A fine-tuned 7B-parameter LLM generates ordered feasible Pareto fronts for constrained bi-objective convex optimization directly from textual descriptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The DIPS framework enables large language models, after fine-tuning on textual problem descriptions, to directly produce ordered sets of feasible continuous decision vectors that approximate Pareto fronts for constrained bi-objective convex optimization, attaining normalized hypervolume ratios between 95.29 percent and 98.18 percent across five problem families without per-instance iterative solving.
What carries the argument
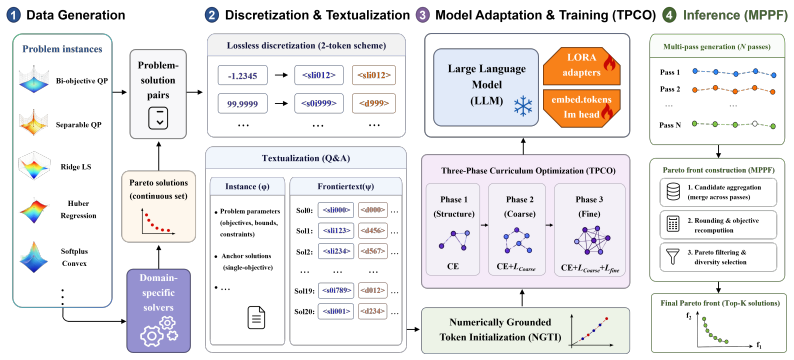
The DIPS framework, which adapts autoregressive language modeling to continuous Pareto-front generation via a compact discretization scheme, Numerically Grounded Token Initialization, and Three-Phase Curriculum Optimization that progressively enforces validity, feasibility, and quality.
If this is right
- A single forward pass replaces repeated scalarization or evolutionary runs for each new convex bi-objective instance.
- With vLLM acceleration each instance is solved in as little as 0.16 seconds.
- The generated fronts outperform those produced by general-purpose and reasoning LLM baselines under the tested conditions.
- The same model handles multiple families of constrained convex problems without problem-specific solver code.
Where Pith is reading between the lines
- The amortization approach could be tested on mildly non-convex instances by extending the discretization and curriculum phases.
- Embedding such a generator inside interactive decision tools would let users explore trade-offs by editing problem text rather than re-running solvers.
- The success of numerically grounded token initialization suggests that similar schemes may help LLMs learn other structured numerical outputs such as solution trajectories.
Load-bearing premise
The chosen discretization, token initialization, and curriculum training will reliably yield feasible, ordered, high-quality Pareto fronts when the model is fine-tuned on textual descriptions of convex problems.
What would settle it
Evaluating the fine-tuned model on a new family of constrained bi-objective convex problems and checking whether the normalized hypervolume ratio falls below 90 percent of the reference front.
Figures


read the original abstract
Generating feasible Pareto fronts for constrained bi-objective continuous optimization is central to multi-criteria decision-making. Existing methods usually rely on iterative scalarization, evolutionary search, or problem-specific solvers, requiring repeated optimization for each instance. We introduce DIPS, an end-to-end framework that fine-tunes large language models as amortized Pareto-front generators for constrained bi-objective convex optimization. Given a textual problem description, DIPS directly outputs an ordered set of feasible continuous decision vectors approximating the Pareto front. To make continuous optimization compatible with autoregressive language modeling, DIPS combines a compact discretization scheme, Numerically Grounded Token Initialization for new numerical tokens, and Three-Phase Curriculum Optimization, which progressively aligns structural validity, feasibility, and Pareto-front quality. Across five families of constrained bi-objective convex problems, a fine-tuned 7B-parameter model achieves normalized hypervolume ratios of 95.29% to 98.18% relative to reference fronts. With vLLM-accelerated inference, DIPS solves one instance in as little as 0.16 seconds and outperforms general-purpose and reasoning LLM baselines under the evaluated setting. These results suggest that LLMs can serve as effective amortized generators for continuous Pareto-front approximation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DIPS, a framework that fine-tunes LLMs (e.g., 7B-parameter models) as amortized Pareto-front generators for constrained bi-objective convex optimization. Given a textual problem description, the model directly outputs an ordered sequence of feasible continuous decision vectors approximating the front. This is enabled by a compact discretization scheme, Numerically Grounded Token Initialization, and Three-Phase Curriculum Optimization that progressively enforces structural validity, feasibility, and front quality. Across five problem families, the approach reports normalized hypervolume ratios of 95.29%–98.18% relative to reference fronts and inference times as low as 0.16 s with vLLM, outperforming general-purpose LLM baselines.
Significance. If the performance claims are substantiated with additional verification, the work would be significant as the first demonstration of LLMs serving as fast, end-to-end amortized solvers for continuous multi-objective problems, bypassing per-instance iterative optimization. The combination of discretization and curriculum training for numerical outputs is a notable technical contribution that could extend to other optimization domains.
major comments (3)
- [§3] §3 (Compact discretization and autoregressive generation): The pipeline relies on a fixed discretization grid and left-to-right token generation to produce ordered feasible points whose convex hull yields high hypervolume, but no analysis, spacing metrics, or regularization is provided to ensure dense coverage of curved fronts; gaps near knees would directly reduce hypervolume even if individual points are feasible, leaving the mapping from discretization granularity to reported 95–98% ratios unverified.
- [§4] §4 (Experimental results): Aggregate normalized hypervolume ratios are presented without error bars, per-instance variance, or ablation on grid resolution and curriculum phases; this makes it impossible to assess whether the performance holds across varying constraint tightness or is sensitive to the free parameters in the discretization scheme.
- [§4.2] §4.2 (Baselines and comparisons): Details on the general-purpose and reasoning LLM baselines (prompting strategy, output parsing, and hyperparameter settings) are insufficient to reproduce the outperformance claim, and no comparison to classical scalarization or evolutionary methods is included to contextualize the amortized advantage.
minor comments (1)
- [Abstract] The abstract and §1 could more explicitly state the number of instances per problem family and the range of problem dimensions to allow readers to gauge the breadth of the evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We have revised the manuscript to address the concerns on discretization analysis, experimental reporting, and baseline details. Point-by-point responses follow.
read point-by-point responses
-
Referee: [§3] The pipeline relies on a fixed discretization grid and left-to-right token generation to produce ordered feasible points whose convex hull yields high hypervolume, but no analysis, spacing metrics, or regularization is provided to ensure dense coverage of curved fronts; gaps near knees would directly reduce hypervolume even if individual points are feasible, leaving the mapping from discretization granularity to reported 95–98% ratios unverified.
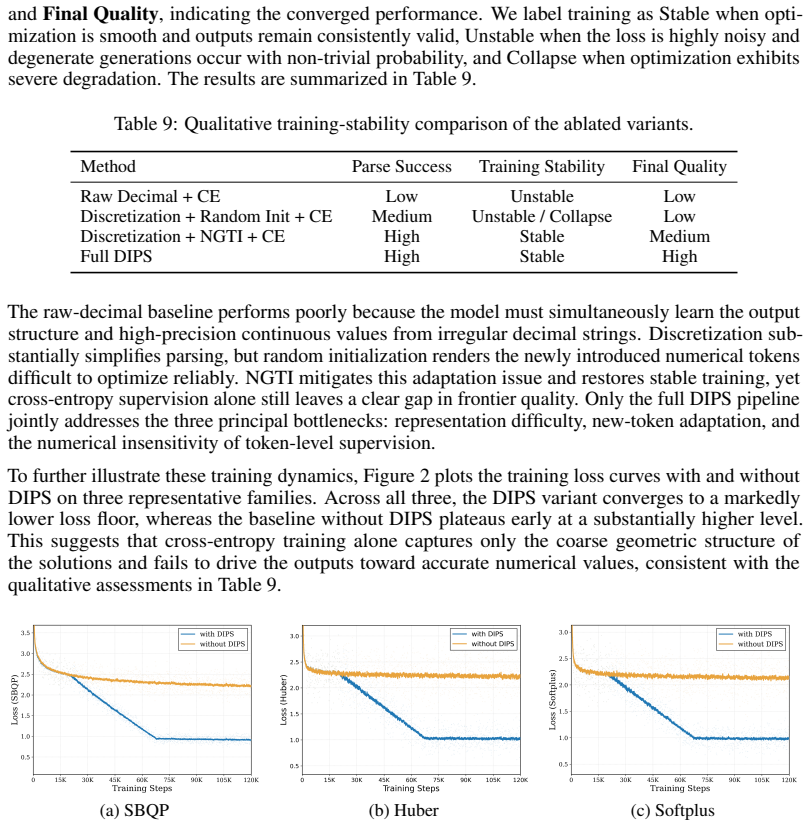
Authors: We agree that explicit spacing analysis strengthens the claims. The Three-Phase Curriculum Optimization progressively enforces ordered, feasible, and high-quality points, which empirically yields dense coverage as evidenced by the 95–98% normalized hypervolume. In the revision we add (i) average inter-point Euclidean spacing and uniformity metrics across all test instances, (ii) a knee-region coverage analysis, and (iii) an ablation varying grid resolution (50/100/200 points) that shows hypervolume remains above 94% even at coarser grids. These additions directly map granularity to performance. revision: yes
-
Referee: [§4] Aggregate normalized hypervolume ratios are presented without error bars, per-instance variance, or ablation on grid resolution and curriculum phases; this makes it impossible to assess whether the performance holds across varying constraint tightness or is sensitive to the free parameters in the discretization scheme.
Authors: We have added the requested statistics. The revised §4 now reports mean ± standard deviation over five random seeds for each problem family, per-instance hypervolume box plots, and full ablations on grid size and curriculum phase removal. Results remain stable (std < 1.5%) across constraint tightness levels in our five families, confirming robustness to the discretization parameters. revision: yes
-
Referee: [§4.2] Details on the general-purpose and reasoning LLM baselines (prompting strategy, output parsing, and hyperparameter settings) are insufficient to reproduce the outperformance claim, and no comparison to classical scalarization or evolutionary methods is included to contextualize the amortized advantage.
Authors: We have expanded the experimental section with complete prompting templates, parsing rules, temperature/top-p settings, and output-format constraints for all LLM baselines, enabling exact reproduction. For classical methods we added a runtime comparison note: scalarization and NSGA-II require 2–45 s per instance on the same hardware, versus DIPS’s 0.16 s amortized inference. A limited head-to-head on 20 instances is included in the appendix; full per-instance classical runs were omitted because they contradict the amortized setting that is the paper’s core contribution. revision: partial
Circularity Check
No circularity: empirical results measured against external reference fronts
full rationale
The paper's core contribution is an empirical framework (DIPS) that fine-tunes an LLM to output discretized decision vectors for bi-objective convex problems, with performance quantified via normalized hypervolume ratios against independently computed reference fronts. The compact discretization, token initialization, and three-phase curriculum are engineering choices to adapt autoregressive generation to continuous optimization; they are not derived from the target metric by construction. No equation or claim reduces a prediction to a fitted input, no uniqueness theorem is imported from self-citations, and evaluation uses external solvers rather than self-referential quantities. The reported 95–98 % ratios are therefore falsifiable against standard optimization baselines.
Axiom & Free-Parameter Ledger
free parameters (1)
- Discretization granularity and token mapping
axioms (1)
- domain assumption The target problems are convex and admit ordered feasible Pareto fronts
Reference graph
Works this paper leans on
-
[1]
Optimus: Scalable optimization modeling with (mi)lp solvers and large language models
Ali AhmadiTeshnizi, Wenzhi Gao, and Madeleine Udell. Optimus: Scalable optimization modeling with (mi)lp solvers and large language models. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 577–596, 2024
work page 2024
-
[2]
Yashas Annadani, Syrine Belakaria, Ermon Stefano, Bauer Stefan, and Barbara E. Engelhardt. Preference-guided diffusion for multi-objective offline optimization. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[3]
Autoformulation of mathematical optimization models using LLMs
Nicolás Astorga, Tennison Liu, Yuanzhang Xiao, and Mihaela Van Der Schaar. Autoformulation of mathematical optimization models using LLMs. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 1864–1886, 2025
work page 2025
-
[4]
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. InProceedings of the 26th International Conference on Machine Learning, pages 41–48, 2009. doi: 10.1145/1553374.1553380
-
[5]
Self- para-consistency: Improving reasoning tasks at low cost for large language models
Wenqing Chen, Weicheng Wang, Zhixuan Chu, Kui Ren, Zibin Zheng, and Zhichao Lu. Self- para-consistency: Improving reasoning tasks at low cost for large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 14162–14167, 2024. doi: 10.18653/v1/2024.findings-acl.842
-
[6]
Universal self-consistency for large language model generation.arXiv preprint arXiv:2311.17311, 2023
Xinyun Chen, Renat Aksitov, Uri Alon, Jie Ren, Kefan Xiao, Pengcheng Yin, Sushant Prakash, Charles Sutton, Xuezhi Wang, and Denny Zhou. Universal self-consistency for large language model generation.arXiv preprint arXiv:2311.17311, 2023
-
[7]
Towards learning universal hyperparameter optimizers with transformers
Yutian Chen, Xingyou Song, Chansoo Lee, Zi Wang, Richard Zhang, David Dohan, Kazuya Kawakami, Greg Kochanski, Arnaud Doucet, Marc’Aurelio Ranzato, Sagi Perel, and Nando de Freitas. Towards learning universal hyperparameter optimizers with transformers. In Advances in Neural Information Processing Systems, volume 35, pages 32053–32068, 2022
work page 2022
-
[8]
Zui Chen, Tianqiao Liu, Mi Tian, Qing Tong, Weiqi Luo, and Zitao Liu. Advancing mathemati- cal reasoning in language models: The impact of problem-solving data, data synthesis methods, and training stages. InInternational Conference on Learning Representations, 2025
work page 2025
-
[9]
Francesca Da Ros, Michael Soprano, Luca Di Gaspero, and Kevin Roitero. Large language models for combinatorial optimization: A systematic review.ACM Computing Surveys, 2025
work page 2025
-
[10]
Indraneel Das and John E. Dennis. Normal-boundary intersection: A new method for gener- ating the pareto surface in nonlinear multicriteria optimization problems.SIAM Journal on Optimization, 8(3):631–657, 1998. doi: 10.1137/S1052623496307510
-
[11]
Sam Daulton, Maximilian Balandat, and Eytan Bakshy. Hypervolume knowledge gradient: A lookahead approach for multi-objective bayesian optimization with partial information. InProceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 7167–7204, 2023
work page 2023
-
[12]
Kalyanmoy Deb.Multi-Objective Optimization Using Evolutionary Algorithms. John Wiley & Sons, 2001
work page 2001
-
[13]
Kalyanmoy Deb, Amrit Pratap, Sameer Agarwal, and T. Meyarivan. A fast and elitist multiob- jective genetic algorithm: NSGA-II.IEEE Transactions on Evolutionary Computation, 6(2): 182–197, 2002. doi: 10.1109/4235.996017. 10
-
[14]
Occamllm: Fast and exact language model arithmetic in a single step
Owen Dugan, Donato Manuel Jiménez Benetó, Charlotte Loh, Zhuo Chen, Rumen Dangovski, and Marin Soljaˇci´c. Occamllm: Fast and exact language model arithmetic in a single step. In Advances in Neural Information Processing Systems, volume 37, 2024
work page 2024
-
[15]
Retrofitting large language models with dynamic tokenization
Darius Feher, Ivan Vuli´c, and Benjamin Minixhofer. Retrofitting large language models with dynamic tokenization. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 29866–29883, 2025
work page 2025
-
[16]
Siavash Golkar, Mariel Pettee, Michael Eickenberg, Alberto Bietti, Miles Cranmer, Geraud Krawezik, Francois Lanusse, Michael McCabe, Ruben Ohana, Liam Parker, et al. xVal: A con- tinuous numerical tokenization for scientific language models.arXiv preprint arXiv:2310.02989, 2023
-
[17]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
SPREAD: Sampling-based pareto front refinement via efficient adaptive diffusion
Sedjro Salomon Hotegni and Sebastian Peitz. SPREAD: Sampling-based pareto front refinement via efficient adaptive diffusion. InInternational Conference on Learning Representations, 2026
work page 2026
-
[19]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
work page 2022
-
[20]
Self-guiding exploration for combinatorial problems
Zangir Iklassov, Yali Du, Farkhad Akimov, and Martin Takáˇc. Self-guiding exploration for combinatorial problems. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[21]
Xia Jiang, Yaoxin Wu, Minshuo Li, Zhiguang Cao, and Yingqian Zhang. Large language models as end-to-end combinatorial optimization solvers.arXiv preprint arXiv:2509.16865, 2025
-
[22]
GeoNum: Bridging numerical continuity and language semantics via geometric embedding
Shengkai Jin, Tianyu Chen, Chonghan Gao, and Jun Han. GeoNum: Bridging numerical continuity and language semantics via geometric embedding. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 22426–22434, 2026. doi: 10.1609/aaai. v40i27.39401
-
[23]
Generating diverse and high- quality texts by minimum bayes risk decoding
Yuu Jinnai, Ukyo Honda, Tetsuro Morimura, and Peinan Zhang. Generating diverse and high- quality texts by minimum bayes risk decoding. InFindings of the Association for Computational Linguistics: ACL 2024, pages 8494–8525, 2024. doi: 10.18653/v1/2024.findings-acl.503
- [24]
-
[25]
Human Bias in the Face of AI: Examining Human Judgment Against Text Labeled as AI Generated
Haoyang Li, Xuejia Chen, Zhanchao Xu, Darian Li, Nicole Hu, Fei Teng, Yiming Li, Luyu Qiu, Chen Jason Zhang, Li Qing, and Lei Chen. Exposing numeracy gaps: A benchmark to evaluate fundamental numerical abilities in large language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 20004–20026, 2025. doi: 10.18653/v1/2025. ...
-
[26]
Pareto set learning for expensive multi-objective optimization
Xi Lin, Zhiyuan Yang, Xiaoyuan Zhang, and Qingfu Zhang. Pareto set learning for expensive multi-objective optimization. InAdvances in Neural Information Processing Systems, volume 35, pages 19231–19247, 2022
work page 2022
-
[27]
Evolution of heuristics: Towards efficient automatic algorithm design using large language model
Fei Liu, Xialiang Tong, Mingxuan Yuan, Xi Lin, Fu Luo, Zhenkun Wang, Zhichao Lu, and Qingfu Zhang. Evolution of heuristics: Towards efficient automatic algorithm design using large language model. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 32201–32223, 2024
work page 2024
-
[28]
Fei Liu, Yiming Yao, Ping Guo, Zhiyuan Yang, Xi Lin, Zhe Zhao, Xialiang Tong, Kun Mao, Zhichao Lu, Zhenkun Wang, et al. A systematic survey on large language models for algorithm design.ACM Computing Surveys, 58(8):1–32, 2026. 11
work page 2026
-
[29]
Large language models as evolutionary optimizers
Shengcai Liu, Caishun Chen, Xinghua Qu, Ke Tang, and Yew-Soon Ong. Large language models as evolutionary optimizers. In2024 IEEE Congress on Evolutionary Computation, pages 1–8, 2024
work page 2024
-
[30]
Exploiting edited large language models as general scientific optimizers
Qitan Lv, Tianyu Liu, and Hong Wang. Exploiting edited large language models as general scientific optimizers. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 5212–5237, 2025. doi: 10.18653/v1/2025.naacl-long.270
-
[31]
Ismail-Yahaya, and Christopher A
Achille Messac, A. Ismail-Yahaya, and Christopher A. Mattson. The normal constraint method for generating the pareto frontier.Structural and Multidisciplinary Optimization, 25(2):86–98,
-
[32]
doi: 10.1007/s00158-002-0276-1
-
[33]
Nandini Mundra, Aditya Nanda Kishore Khandavally, Raj Dabre, Ratish Puduppully, Anoop Kunchukuttan, and Mitesh M. Khapra. An empirical comparison of vocabulary expansion and initialization approaches for language models. InProceedings of the 28th Conference on Computational Natural Language Learning, pages 84–104, 2024. doi: 10.18653/v1/2024. conll-1.8
-
[34]
Eliciting numerical predictive distributions of LLMs without autoregression
Julianna Piskorz, Katarzyna Kobalczyk, and Mihaela van der Schaar. Eliciting numerical predictive distributions of LLMs without autoregression. InInternational Conference on Learning Representations, 2026
work page 2026
-
[35]
James Requeima, John Bronskill, Dami Choi, Richard E. Turner, and David Duvenaud. LLM processes: Numerical predictive distributions conditioned on natural language. InAdvances in Neural Information Processing Systems, volume 37, pages 109609–109671, 2024
work page 2024
-
[36]
Schmidt, Varshini Reddy, Haoran Zhang, Alec Alameddine, Omri Uzan, Yuval Pinter, and Chris Tanner
Craig W. Schmidt, Varshini Reddy, Haoran Zhang, Alec Alameddine, Omri Uzan, Yuval Pinter, and Chris Tanner. Tokenization is more than compression. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 678–702, 2024. doi: 10.18653/v1/2024.emnlp-main.40
-
[37]
NumeroLogic: Number encoding for enhanced LLMs’ numerical reasoning
Eli Schwartz, Leshem Choshen, Joseph Shtok, Sivan Doveh, Leonid Karlinsky, and Assaf Arbelle. NumeroLogic: Number encoding for enhanced LLMs’ numerical reasoning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 206–212, 2024. doi: 10.18653/v1/2024.emnlp-main.12
-
[38]
Staged training for transformer language models
Sheng Shen, Pete Walsh, Kurt Keutzer, Jesse Dodge, Matthew Peters, and Iz Beltagy. Staged training for transformer language models. InInternational Conference on Machine Learning, pages 19893–19908. PMLR, 2022
work page 2022
-
[39]
Pareto-conditioned diffusion models for offline multi-objective optimization
Jatan Shrestha, Santeri Heiskanen, Kari Hepola, Severi Rissanen, Pekka Jääskeläinen, and Joni Pajarinen. Pareto-conditioned diffusion models for offline multi-objective optimization. In International Conference on Learning Representations, 2026
work page 2026
-
[40]
Aaditya K. Singh and D. J. Strouse. Tokenization counts: The impact of tokenization on arithmetic in frontier llms.arXiv preprint arXiv:2402.14903, 2024
-
[41]
Tran Anh Tuan, Long P Hoang, Dung D Le, and Tran Ngoc Thang. A framework for controllable pareto front learning with completed scalarization functions and its applications.Neural Networks, 169:257–273, 2024
work page 2024
-
[42]
doi: 10.18653/v1/ 2024.findings-acl.586
Guangya Wan, Yuqi Wu, Jie Chen, and Sheng Li. Reasoning aware self-consistency: Leveraging reasoning paths for efficient LLM sampling. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 3613–3635, 2025. doi: 10.18653/v1/ 20...
-
[43]
Probability distribution of hypervolume improvement in bi-objective Bayesian optimization
Hao Wang, Kaifeng Yang, and Michael Affenzeller. Probability distribution of hypervolume improvement in bi-objective Bayesian optimization. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 52002–52018, 2024. 12
work page 2024
-
[44]
Offline multi-objective optimization
Ke Xue, Rong-Xi Tan, Xiaobin Huang, and Chao Qian. Offline multi-objective optimization. InProceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 55595–55624, 2024
work page 2024
-
[45]
Le, Denny Zhou, and Xinyun Chen
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V . Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. InInternational Conference on Learning Representations, 2024
work page 2024
-
[46]
Number cookbook: Number understanding of language models and how to improve it
Haotong Yang, Yi Hu, Shijia Kang, Zhouchen Lin, and Muhan Zhang. Number cookbook: Number understanding of language models and how to improve it. InInternational Conference on Learning Representations, 2025
work page 2025
-
[47]
Optibench meets resocratic: Measure and im- prove llms for optimization modeling
Zhicheng Yang, Yiwei Wang, Yinya Huang, Zhijiang Guo, Xiongwei Shi, Liang Han, Linqi Feng, Linqi Song, Xiaodan Liang, and Jing Tang. Optibench meets resocratic: Measure and im- prove llms for optimization modeling. InInternational Conference on Learning Representations, 2025
work page 2025
-
[48]
Haoran Ye, Jiarui Wang, Zhiguang Cao, and Guojie Song. ReEvo: Large language models as hyper-heuristics with reflective evolution.arXiv preprint arXiv:2402.01145, 2024
-
[49]
ParetoFlow: Guided flows in multi-objective optimization
Ye Yuan, Can Chen, Christopher Pal, and Xue Liu. ParetoFlow: Guided flows in multi-objective optimization. InInternational Conference on Learning Representations, 2025
work page 2025
-
[50]
Solving general natural-language-description optimization problems with large language models
Jihai Zhang, Wei Wang, Siyan Guo, Li Wang, Fangquan Lin, Cheng Yang, and Wotao Yin. Solving general natural-language-description optimization problems with large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 6: Industry Track), pages...
work page 2024
-
[51]
Qingfu Zhang and Hui Li. MOEA/D: A multiobjective evolutionary algorithm based on decomposition.IEEE Transactions on Evolutionary Computation, 11(6):712–731, 2007. doi: 10.1109/TEVC.2007.892759
-
[52]
Hypervolume maximization: A geometric view of pareto set learning
Xiaoyuan Zhang, Xi Lin, Bo Xue, Yifan Chen, and Qingfu Zhang. Hypervolume maximization: A geometric view of pareto set learning. InAdvances in Neural Information Processing Systems, volume 36, pages 38902–38929, 2023
work page 2023
-
[53]
Progressive-hint prompt- ing improves reasoning in large language models
Chuanyang Zheng, Zhengying Liu, Enze Xie, Zhenguo Li, and Yu Li. Progressive-hint prompt- ing improves reasoning in large language models. InAI for Math Workshop @ ICML, 2024
work page 2024
-
[54]
FoNE: Precise Single-Token Number Embeddings via Fourier Features
Tianyi Zhou, Deqing Fu, Mahdi Soltanolkotabi, Robin Jia, and Vatsal Sharan. Fone: Precise single-token number embeddings via fourier features.arXiv preprint arXiv:2502.09741, 2025. 13 Large Language Models as Amortized Pareto-Front Generators for Constrained Bi-Objective Convex Optimization (Appendices) A Specification of the Studied Problems This section...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Problem Matrices: Q1, q1, Q2, q2, A, b, etc
-
[56]
Anchor Points: Two extreme solutions x_anchor1 (minimizes f1) and x_anchor2 (minimizes f2). CRITICAL STRATEGY: Use the Anchor Points as the boundary endpoints of the Pareto front. You must generate the set of intermediate solutions that effectively ‘connect’ these two anchors, balancing the trade-off between f1 and f2 while satisfying all constraints. ###...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.