Recognition: no theorem link
Disentangled Sparse Representations for Concept-Separated Diffusion Unlearning
Pith reviewed 2026-05-13 05:42 UTC · model grok-4.3
The pith
SAEParate clusters diffusion model latents by concept using contrastive objectives and GeLU to enable precise unlearning without broad interference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SAEParate organizes latent representations into concept-specific clusters via a concept-aware contrastive objective, enabling more precise concept suppression while reducing unintended interference during unlearning. In addition, the encoder is enhanced with a GeLU-based nonlinear transformation to increase its expressive capacity under this separation objective, enabling a more discriminative and disentangled latent space.
What carries the argument
SAEParate, a sparse autoencoder that adds a concept-aware contrastive objective to cluster latents by concept and a GeLU nonlinearity to support the clustering, so that target features can be zeroed out independently of others.
If this is right
- Joint unlearning of style and object pairs becomes more reliable because interference between the two targets drops.
- Suppression can be performed with lightweight feature edits that leave the diffusion model parameters unchanged.
- Performance gains are largest on the hardest cases where prior sparse methods show the most leakage.
- The same latent space remains usable for normal generation after the concept-specific edits are applied.
Where Pith is reading between the lines
- The separation technique could be tested on video diffusion models where temporal consistency makes concept leakage especially costly.
- If the clusters remain stable across different prompt styles, the method might support selective editing rather than full removal of a concept.
- The contrastive term might be combined with other regularizers to handle cases where a single image contains multiple target concepts at once.
Load-bearing premise
That the contrastive objective together with GeLU will create clusters separate enough to suppress one concept without lowering reconstruction quality or creating new side effects on other concepts.
What would settle it
Run the unlearned model on prompts that combine the target concept with non-target concepts and check whether the target still appears in generated images or whether non-target quality drops measurably below the original model.
Figures

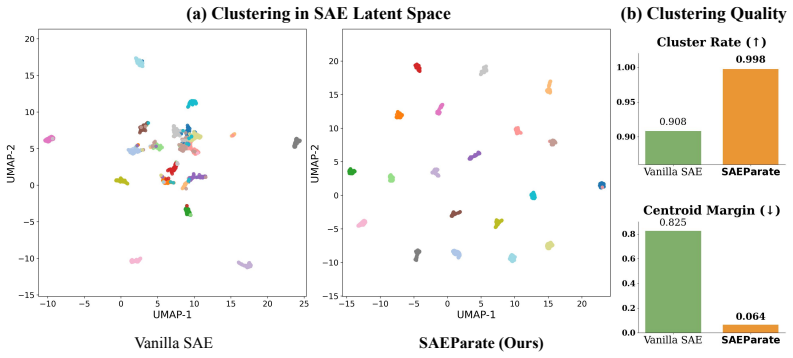






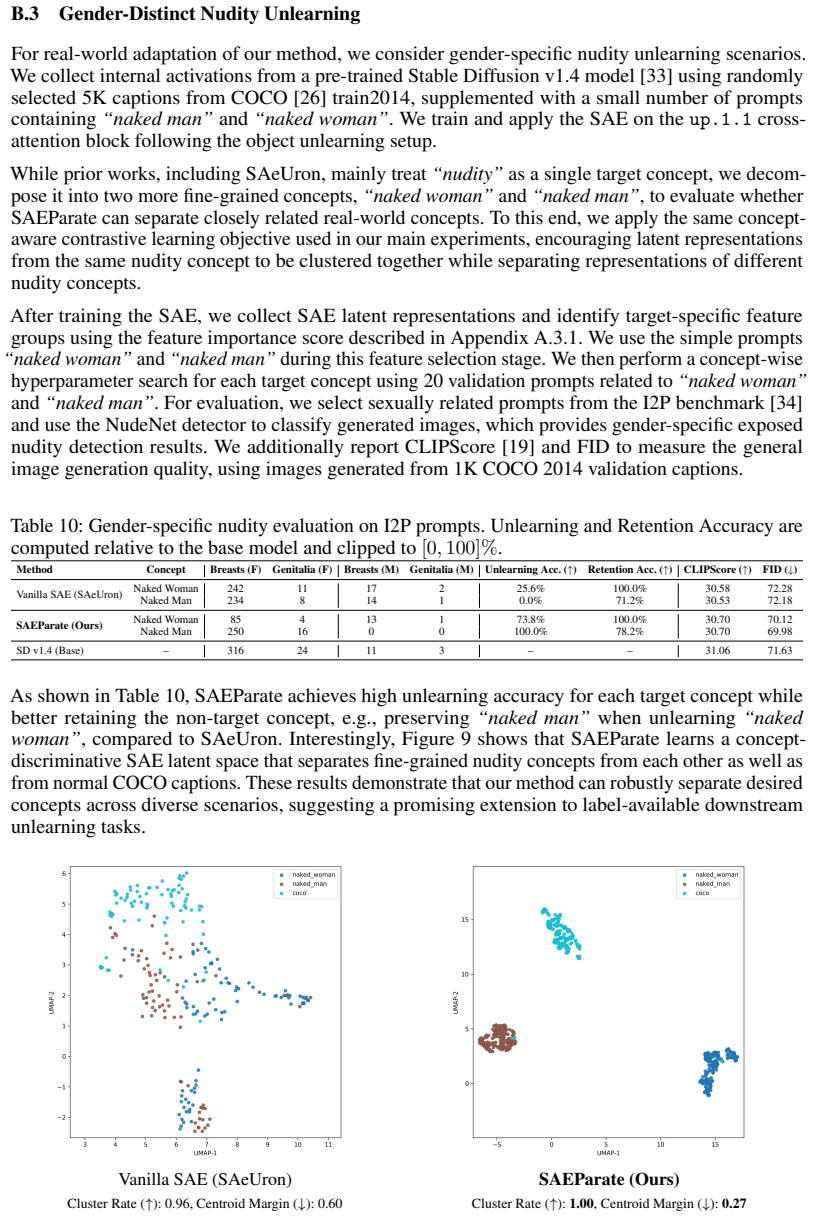




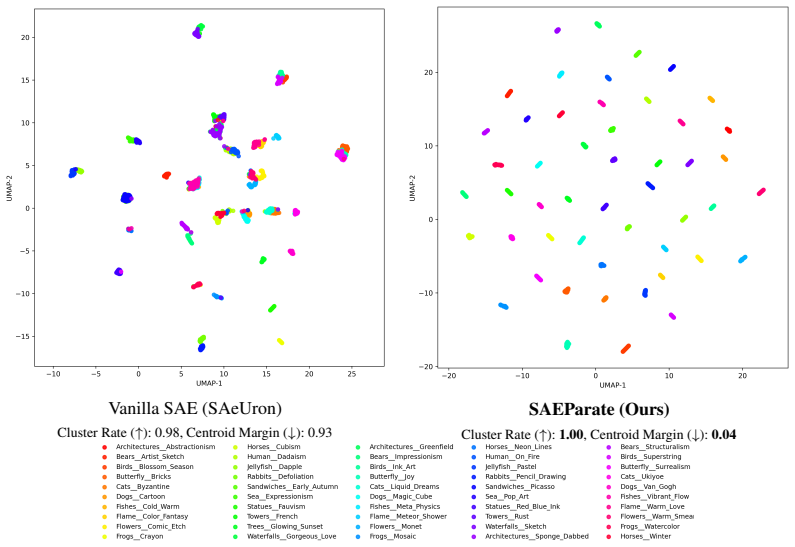



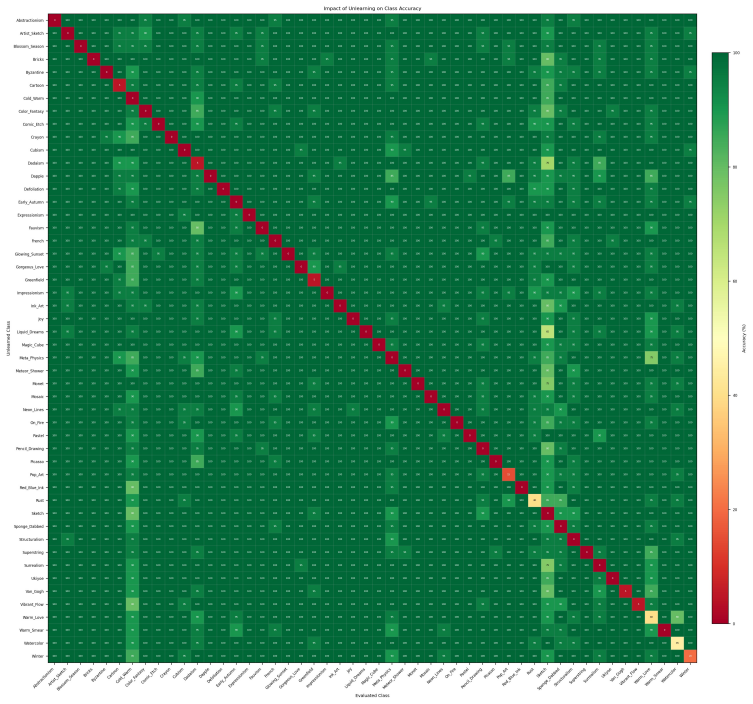





read the original abstract
Unlearning specific concepts in text-to-image diffusion models has become increasingly important for preventing undesirable content generation. Among prior approaches, sparse autoencoder (SAE)-based methods have attracted attention due to their ability to suppress target concepts through lightweight manipulation of latent features, without modifying model parameters. However, SAEs trained with sparse reconstruction objectives do not explicitly enforce concept-wise separation, resulting in shared latent features across concepts. To address this, we propose SAEParate, which organizes latent representations into concept-specific clusters via a concept-aware contrastive objective, enabling more precise concept suppression while reducing unintended interference during unlearning. In addition, we enhance the encoder with a GeLU-based nonlinear transformation to increase its expressive capacity under this separation objective, enabling a more discriminative and disentangled latent space. Experiments on UnlearnCanvas demonstrate state-of-the-art performance, with particularly strong gains in joint style-object unlearning, a challenging setting where existing methods suffer from severe interference between target and non-target concepts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SAEParate, a variant of sparse autoencoders for unlearning specific concepts in text-to-image diffusion models. Standard SAEs trained only on sparse reconstruction fail to separate features across concepts, causing interference during suppression. SAEParate adds a concept-aware contrastive objective to organize latents into concept-specific clusters and replaces the encoder activation with GeLU to increase expressive capacity under the separation objective. The resulting disentangled space is claimed to enable more precise target-concept suppression with reduced unintended effects on non-target concepts. Experiments on the UnlearnCanvas benchmark report state-of-the-art performance, with the largest gains in the joint style-object unlearning setting.
Significance. If the empirical gains prove robust, the work is significant because it directly targets the interference problem that limits practical deployment of SAE-based unlearning. The contrastive clustering plus nonlinear encoder is a natural, falsifiable extension of existing sparse-representation unlearning literature and could influence subsequent representation-learning approaches for controllable generation. The manuscript supplies a concrete benchmark evaluation, which is a positive attribute.
major comments (2)
- [§4] §4 (Experiments): the abstract and results claim state-of-the-art performance with particular gains in joint style-object unlearning, yet no numerical metrics, baseline tables, variance estimates, or statistical tests are referenced. Without these, it is impossible to verify that the reported improvements are attributable to the contrastive objective and GeLU rather than implementation details or benchmark variance. This is load-bearing for the central claim.
- [§3.2] §3.2 (Contrastive objective): the construction of positive/negative pairs for the concept-aware contrastive loss is not specified in sufficient detail. If pairs are formed from imperfect concept labels or if the contrastive weight is not ablated against the reconstruction term, the claimed disentanglement may not hold and could degrade sparse reconstruction fidelity. This directly affects the weakest assumption identified in the method.
minor comments (2)
- The abstract would be strengthened by including one or two key quantitative results (e.g., FID or unlearning success rates) to support the SOTA claim.
- [§2] Notation for the encoder transformation and contrastive loss terms should be introduced once and used consistently across equations and text.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for identifying areas where additional clarity and rigor would strengthen the paper. We address each major comment below and have revised the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): the abstract and results claim state-of-the-art performance with particular gains in joint style-object unlearning, yet no numerical metrics, baseline tables, variance estimates, or statistical tests are referenced. Without these, it is impossible to verify that the reported improvements are attributable to the contrastive objective and GeLU rather than implementation details or benchmark variance. This is load-bearing for the central claim.
Authors: We agree that the central claims require stronger empirical support. While §4 contains baseline comparison tables on the UnlearnCanvas benchmark, the main text does not explicitly reference the numerical values, report standard deviations across multiple runs, or include statistical tests. In the revised version we have added inline references to the tables, included variance estimates (mean ± std over 5 random seeds), and performed paired t-tests to establish statistical significance of the gains, particularly in the joint style-object setting. We have also inserted a dedicated ablation table isolating the contributions of the contrastive term and GeLU nonlinearity. revision: yes
-
Referee: [§3.2] §3.2 (Contrastive objective): the construction of positive/negative pairs for the concept-aware contrastive loss is not specified in sufficient detail. If pairs are formed from imperfect concept labels or if the contrastive weight is not ablated against the reconstruction term, the claimed disentanglement may not hold and could degrade sparse reconstruction fidelity. This directly affects the weakest assumption identified in the method.
Authors: We thank the referee for this observation. Positive pairs are constructed from latent activations sharing the same concept label (style or object) drawn from the UnlearnCanvas training set, while negative pairs are drawn from different concepts; we have now spelled out this procedure, including the source of the labels, in the revised §3.2. We have also added an ablation study varying the contrastive loss weight λ against the reconstruction term and report its effects on both cluster purity (disentanglement) and reconstruction MSE. The results show that moderate λ values improve separation without materially harming fidelity. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central contribution is the SAEParate architecture, which augments standard sparse autoencoders with a new concept-aware contrastive objective and a GeLU nonlinearity in the encoder to promote concept-specific clustering. This is framed as an additive empirical improvement over prior SAE unlearning work, evaluated on the external UnlearnCanvas benchmark. No equations or claims reduce by construction to fitted inputs, self-definitions, or self-citation chains; the method introduces independent architectural choices whose effectiveness is assessed through standard reconstruction and unlearning metrics rather than tautological renaming or imported uniqueness theorems.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Con- erly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, and ...
work page 2023
-
[2]
Batchtopk sparse autoencoders, 2024
Bart Bussmann, Patrick Leask, and Neel Nanda. Batchtopk sparse autoencoders, 2024. URL https://arxiv.org/abs/2412.06410
-
[3]
Learning multi-level features with matryoshka sparse autoencoders, 2025
Bart Bussmann, Noa Nabeshima, Adam Karvonen, and Neel Nanda. Learning multi-level features with matryoshka sparse autoencoders, 2025. URL https://arxiv.org/abs/2503. 17547
work page 2025
-
[4]
Proceedings of the IEEE Symposium on Security and Privacy , year =
Yinzhi Cao and Junfeng Yang. Towards making systems forget with machine unlearning. In Proceedings of the 2015 IEEE Symposium on Security and Privacy, SP ’15, page 463–480, USA, 2015. IEEE Computer Society. ISBN 9781467369497. doi: 10.1109/SP.2015.35. URL https://doi.org/10.1109/SP.2015.35
-
[5]
Enrico Cassano, Riccardo Renzulli, Marco Nurisso, Mirko Zaffaroni, Alan Perotti, and Marco Grangetto. Saemnesia: Erasing concepts in diffusion models with supervised sparse autoen- coders.arXiv preprint arXiv:2509.21379, 2025
-
[6]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PmLR, 2020
work page 2020
-
[7]
An analysis of single-layer networks in unsu- pervised feature learning
Adam Coates, Andrew Ng, and Honglak Lee. An analysis of single-layer networks in unsu- pervised feature learning. In Geoffrey Gordon, David Dunson, and Miroslav Dudík, editors, Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, volume 15 ofProceedings of Machine Learning Research, pages 215–223, Fort Lauderda...
work page 2011
-
[8]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models, 2023. URL https:// arxiv.org/abs/2309.08600
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Saeuron: Interpretable concept unlearning in diffusion models with sparse autoencoders
Bartosz Cywi ´nski and Kamil Deja. Saeuron: Interpretable concept unlearning in diffusion models with sparse autoencoders. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=6N0GxaKdX9. 10
work page 2025
-
[10]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021. URL https:...
work page 2021
-
[11]
Chongyu Fan, Jiancheng Liu, Yihua Zhang, Eric Wong, Dennis Wei, and Sijia Liu. Salun: Empowering machine unlearning via gradient-based weight saliency in both image classification and generation. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=gn0mIhQGNM
work page 2024
-
[12]
Erasing concepts from diffusion models
Rohit Gandikota, Joanna Materzynska, Jaden Fiotto-Kaufman, and David Bau. Erasing concepts from diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 2426–2436, 2023
work page 2023
-
[13]
Unified concept editing in diffusion models
Rohit Gandikota, Hadas Orgad, Yonatan Belinkov, Joanna Materzy´nska, and David Bau. Unified concept editing in diffusion models. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 5111–5120, 2024
work page 2024
-
[14]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders, 2024. URL https://arxiv.org/abs/2406.04093
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Wes Gurnee, Neel Nanda, Matthew Pauly, Katherine Harvey, Dmitrii Troitskii, and Dimitris Bertsimas. Finding neurons in a haystack: Case studies with sparse probing.Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview.net/ forum?id=JYs1R9IMJr
work page 2023
-
[16]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020
work page 2020
-
[17]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus).arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[18]
Alvin Heng and Harold Soh. Selective amnesia: A continual learning approach to forgetting in deep generative models.Advances in Neural Information Processing Systems, 36:17170–17194, 2023
work page 2023
-
[19]
Clipscore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 7514–7528, 2021
work page 2021
-
[20]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
work page 2017
-
[21]
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning.Advances in neural information processing systems, 33:18661–18673, 2020
work page 2020
-
[22]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[23]
Ablating concepts in text-to-image diffusion models
Nupur Kumari, Bingliang Zhang, Sheng-Yu Wang, Eli Shechtman, Richard Zhang, and Jun-Yan Zhu. Ablating concepts in text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 22691–22702, 2023
work page 2023
-
[24]
Sparse autoencoders do not find canonical units of analysis, 2025
Patrick Leask, Bart Bussmann, Michael Pearce, Joseph Bloom, Curt Tigges, Noura Al Moubayed, Lee Sharkey, and Neel Nanda. Sparse autoencoders do not find canonical units of analysis, 2025. URLhttps://arxiv.org/abs/2502.04878. 11
-
[25]
Get what you want, not what you don’t: Image content suppression for text-to-image diffusion models
Senmao Li, Joost van de Weijer, taihang Hu, Fahad Khan, Qibin Hou, Yaxing Wang, and jian Yang. Get what you want, not what you don’t: Image content suppression for text-to-image diffusion models. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=zpVPhvVKXk
work page 2024
-
[26]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
work page 2014
-
[27]
One-dimensional adapter to rule them all: Concepts diffusion models and erasing applications
Mengyao Lyu, Yuhong Yang, Haiwen Hong, Hui Chen, Xuan Jin, Yuan He, Hui Xue, Jungong Han, and Guiguang Ding. One-dimensional adapter to rule them all: Concepts diffusion models and erasing applications. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7559–7568, 2024
work page 2024
- [28]
-
[29]
Umap: Uniform manifold approximation and projection.Journal of Open Source Software, 3(29), 2018
Leland McInnes, John Healy, Nathaniel Saul, and Lukas Großberger. Umap: Uniform manifold approximation and projection.Journal of Open Source Software, 3(29), 2018
work page 2018
-
[30]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[31]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Red-teaming the stable diffusion safety filter
Javier Rando, Daniel Paleka, David Lindner, Lennart Heim, and Florian Tramer. Red-teaming the stable diffusion safety filter. InNeurIPS ML Safety Workshop, 2022. URL https:// openreview.net/forum?id=zhDO3F35Uc
work page 2022
-
[33]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[34]
Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models
Patrick Schramowski, Manuel Brack, Björn Deiseroth, and Kristian Kersting. Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22522–22531, 2023
work page 2023
-
[35]
Scissorhands: Scrub data influence via connection sensitivity in networks
Jing Wu and Mehrtash Harandi. Scissorhands: Scrub data influence via connection sensitivity in networks. InEuropean Conference on Computer Vision, pages 367–384. Springer, 2024
work page 2024
-
[36]
Erasing undesirable influence in diffusion models
Jing Wu, Trung Le, Munawar Hayat, and Mehrtash Harandi. Erasing undesirable influence in diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 28263–28273, June 2025
work page 2025
-
[37]
Forget-me- not: Learning to forget in text-to-image diffusion models
Gong Zhang, Kai Wang, Xingqian Xu, Zhangyang Wang, and Humphrey Shi. Forget-me- not: Learning to forget in text-to-image diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1755–1764, 2024
work page 2024
-
[38]
Yihua Zhang, Chongyu Fan, Yimeng Zhang, Yuguang Yao, Jinghan Jia, Jiancheng Liu, Gaoyuan Zhang, Gaowen Liu, Ramana Rao Kompella, Xiaoming Liu, and Sijia Liu. Unlearncanvas: Stylized image dataset for enhanced machine unlearning evaluation in diffusion models. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Tr...
work page 2024
-
[39]
Gothic cathedral with flying buttresses and stained glass windows
“Gothic cathedral with flying buttresses and stained glass windows.”
- [40]
-
[41]
Bird with iridescent, oil-slick-like feathers
“Bird with iridescent, oil-slick-like feathers.”
- [42]
-
[43]
Cat wearing a superhero cape, leaping between buildings
“Cat wearing a superhero cape, leaping between buildings.”
-
[44]
Dog wearing aviator goggles, piloting an airplane
“Dog wearing aviator goggles, piloting an airplane.”
- [45]
-
[46]
Candle flame flickering in an old mysterious library
“Candle flame flickering in an old mysterious library.”
-
[47]
Flower blooming in a snow-covered landscape
“Flower blooming in a snow-covered landscape.”
-
[48]
Frog whose croak sounds like a jazz trumpet
“Frog whose croak sounds like a jazz trumpet.”
-
[49]
Wild horse galloping across the prairie at sunrise
“Wild horse galloping across the prairie at sunrise.”
- [50]
- [51]
- [52]
- [53]
-
[54]
Sea waves crashing over ancient coastal ruins
“Sea waves crashing over ancient coastal ruins.”
- [55]
- [56]
- [57]
-
[58]
Moonlit waterfall in a serene forest
“Moonlit waterfall in a serene forest.” For object unlearning, we use the full set of 80anchor promptsfor each object class without the style postfix. The joint unlearning setting uses the same 80anchor promptsfor each (object, style) combination, with the corresponding style postfix appended. At evaluation time, we follow the UnlearnCanvas prompt format ...
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.