Recognition: no theorem link
STRUM: A Spectral Transcription and Rhythm Understanding Model for End-to-End Generation of Playable Rhythm-Game Charts
Pith reviewed 2026-05-13 04:42 UTC · model grok-4.3
The pith
STRUM converts raw audio into playable Clone Hero charts for five instruments using a hybrid neural pipeline without metadata.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
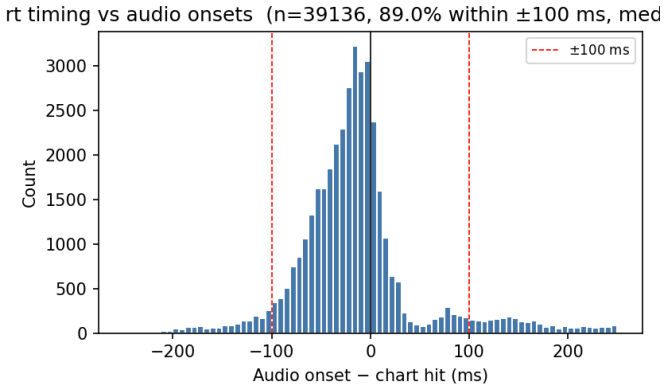
STRUM is a multi-stage hybrid pipeline that maps raw audio to playable rhythm-game charts for drums, guitar, bass, vocals, and keys without oracle metadata. It employs a two-stage CRNN onset detector plus six-model ensemble for drums, neural onsets with monophonic pitch tracking for guitar and bass, word-aligned ASR for vocals, and spectral keyboard detection for keys. On the 30-song benchmark filtered by high median 1-second drum-stem RMS after source separation, it attains the stated F1 scores at +/- 100 ms tolerance with per-song global offset search, supported by an ablation of seven drum components, timing distribution analysis, and drum-classifier confusion matrices.
What carries the argument
The multi-stage hybrid pipeline that routes audio through instrument-specific neural onset detectors, pitch trackers, classifiers, and spectral analyzers to produce timed note events for game charts.
If this is right
- Charts become available for any song whose audio meets basic clarity thresholds rather than only those already transcribed by volunteers.
- Ablation results identify which drum-pipeline stages contribute measurable accuracy gains and which can be simplified.
- Per-song offset search corrects global timing mismatches between audio and generated charts.
- The released benchmark and timing-distribution analysis supply a standardized testbed and reference for future chart-generation work.
- Instrument-specific modules can be swapped or retrained independently while keeping the rest of the pipeline intact.
Where Pith is reading between the lines
- The same pipeline structure could be adapted to generate charts for other rhythm-game engines or mobile titles that use similar note layouts.
- Performance on vocals points to a clear next target: replacing the current ASR step with models trained on singing rather than speech.
- Combining STRUM with existing source-separation models would allow chart generation directly from mixed stereo tracks without separate stems.
- If the drum-onset detector generalizes, the system could support real-time chart previews during live performances or DJ sets.
Load-bearing premise
The 30 songs chosen for strong drum-stem energy after source separation represent the audio conditions and genres users will actually want to convert into charts.
What would settle it
Running the released STRUM models on a larger, unscreened collection of songs spanning lower audio quality, different genres, or live recordings would produce F1 scores that stay within 10 percent of the reported values or drop sharply.
Figures


read the original abstract
We present STRUM (Spectral Transcription and Rhythm Understanding Model), an audio-to-chart pipeline that converts raw recordings into playable Clone Hero / YARG charts for drums, guitar, bass, vocals, and keys without any oracle metadata. STRUM is a multi-stage hybrid: a two-stage CRNN onset detector and a six-model ensemble classifier for drums; neural onset detectors with monophonic pitch tracking for guitar and bass; word-aligned ASR for vocals; and spectral keyboard detection for keys. We evaluate on a 30-song in-envelope benchmark constructed by screening candidate songs on a single audio-quality criterion -- the median 1-second drum-stem RMS after htdemucs_6s source separation. On this benchmark STRUM achieves drums onset F1 = 0.838, bass F1 = 0.694, guitar F1 = 0.651, and vocals F1 = 0.539 at a +/- 100 ms tolerance with per-song global offset search. We report a complete ablation of seven drum-pipeline components with paired per-song Wilcoxon tests, an analysis of ground-truth-to-audio timing distributions in community Clone Hero charts, and a per-class confusion matrix for the drum classifier. Code, model weights, and the full benchmark manifest are released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces STRUM, a hybrid audio-to-chart pipeline for generating playable rhythm game charts from raw audio recordings for drums, guitar, bass, vocals, and keys. It uses a two-stage CRNN for drum onsets and ensemble classifier, neural methods for guitar/bass, ASR for vocals, and spectral detection for keys. Evaluation is performed on a 30-song benchmark selected based on high median 1-second drum-stem RMS after htdemucs source separation, achieving F1 scores of 0.838 for drums, 0.694 for bass, 0.651 for guitar, and 0.539 for vocals at ±100 ms tolerance with per-song global offset search. The authors provide ablations with statistical tests, timing analysis, confusion matrices, and release all code, weights, and the benchmark manifest.
Significance. Should the reported performance prove robust on more diverse and unfiltered audio corpora, this work would represent a meaningful advance in end-to-end chart generation for rhythm games, potentially reducing manual effort in community chart creation. The public release of code, model weights, and the complete benchmark manifest is a notable strength that supports reproducibility and allows independent verification of the results and ablations.
major comments (3)
- §4 (Benchmark Construction): The 30-song benchmark is constructed by screening solely on high median 1-second drum-stem RMS after htdemucs_6s source separation. This criterion selects for tracks with loud, clean drums, which simplifies onset detection and may inflate the headline F1 scores (drums F1 = 0.838). No performance results are reported on unfiltered or standard corpora, undermining claims of general applicability.
- Evaluation Protocol: The per-song global offset search is applied during evaluation to align predictions with ground truth. This step is not available in a blind, real-world deployment scenario for chart generation and should be distinguished from the core model's performance.
- Pipeline Description: The htdemucs_6s model is used both to construct the benchmark (via drum-stem RMS screening) and as a pre-trained component in the STRUM pipeline for source separation. This overlap creates a potential closed loop that could mask domain shift or overfitting to the screened songs.
minor comments (1)
- Abstract: The term 'in-envelope benchmark' is used without a clear definition or reference to its meaning in the context of the screening process.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each major comment below, indicating where revisions have been made to improve clarity and acknowledge limitations.
read point-by-point responses
-
Referee: §4 (Benchmark Construction): The 30-song benchmark is constructed by screening solely on high median 1-second drum-stem RMS after htdemucs_6s source separation. This criterion selects for tracks with loud, clean drums, which simplifies onset detection and may inflate the headline F1 scores (drums F1 = 0.838). No performance results are reported on unfiltered or standard corpora, undermining claims of general applicability.
Authors: We appreciate the referee pointing out this selection bias. The benchmark was deliberately constructed around songs yielding high-quality drum stems after source separation to ensure reliable ground-truth timing for evaluation; this is explicitly described as an 'in-envelope' benchmark in the manuscript. We agree that the criterion favors tracks with prominent drums and that headline scores may not generalize to noisier or less-separated audio. In the revised manuscript we have expanded the limitations paragraph in Section 4 to state this bias explicitly and to avoid any implication of broad applicability. We have not added results on unfiltered corpora, as constructing and annotating such a set would require substantial new effort outside the current revision scope. revision: partial
-
Referee: Evaluation Protocol: The per-song global offset search is applied during evaluation to align predictions with ground truth. This step is not available in a blind, real-world deployment scenario for chart generation and should be distinguished from the core model's performance.
Authors: We concur that the per-song global offset search is an evaluation-only alignment step and is unavailable in blind deployment. The manuscript already notes its use, but we have revised the evaluation section to more clearly separate the core model output from the offset-aligned results. A new table now reports F1 scores computed without the global offset search, allowing readers to assess standalone performance directly. revision: yes
-
Referee: Pipeline Description: The htdemucs_6s model is used both to construct the benchmark (via drum-stem RMS screening) and as a pre-trained component in the STRUM pipeline for source separation. This overlap creates a potential closed loop that could mask domain shift or overfitting to the screened songs.
Authors: htdemucs_6s is used strictly as a fixed, pre-trained, off-the-shelf model; none of its parameters were updated using the benchmark. The screening step merely filters candidate tracks on drum-stem energy, while the pipeline applies the same frozen model to separate test audio. This does not constitute a training loop or permit overfitting to the screened songs. We have nevertheless added explicit wording in the pipeline overview to emphasize that htdemucs_6s remains an unmodified external component and to note the possibility of domain effects when the same separator is used for both selection and inference. revision: partial
Circularity Check
No circularity; evaluation is direct measurement against external ground truth
full rationale
The paper describes a hybrid multi-stage pipeline (CRNN onset detectors, ensemble classifiers, pitch tracking, ASR, spectral detection) and reports F1 scores computed directly from model outputs versus independent community Clone Hero ground-truth charts on a transparently filtered 30-song set. The benchmark construction criterion (median 1-second drum-stem RMS after htdemucs_6s separation) is an explicit selection step that affects difficulty but does not redefine any fitted parameter, model output, or prediction as its own input. No equations reduce by construction, no self-citations supply load-bearing uniqueness theorems, and no ansatz or renaming of known results occurs. The derivation from raw audio to playable charts remains externally falsifiable via the released benchmark manifest and annotations.
Axiom & Free-Parameter Ledger
free parameters (2)
- onset detection thresholds
- ensemble classifier decision rules
axioms (1)
- domain assumption htdemucs_6s source separation produces reliable drum-stem RMS values for audio-quality screening.
Reference graph
Works this paper leans on
-
[1]
Yu-Te Wu, Yin-Jyun Luo, Tsung-Ping Chen, I-Chieh Wei, Jui-Yang Hsu, Yi-Chin Chuang, and Li Su. Omnizart: A general toolbox for automatic music transcription.Journal of Open Source Software, 6(68):3391, 2021.https://doi.org/10.21105/joss.03391
-
[2]
MT3: Multi-task multitrack music transcription,
Josh Gardner, Ian Simon, Ethan Manilow, Curtis Hawthorne, and Jesse Engel. MT3: Multi-task multitrack music transcription.International Conference on Learning Representations (ICLR), 2022.https://arxiv.org/abs/2111.03017
-
[3]
Automatic drum transcription using bi- directional recurrent neural networks.Proc
Carl Southall, Ryan Stables, and Jason Hockman. Automatic drum transcription using bi- directional recurrent neural networks.Proc. International Society for Music Information Retrieval Conference (ISMIR), pages 591–597, 2016
work page 2016
-
[4]
CloneCharter: A Clone Hero chart generator
thejorseman. CloneCharter: A Clone Hero chart generator. Hugging Face Model Repository, 2026.https://huggingface.co/thejorseman/CloneCharter
work page 2026
-
[5]
Simon Rouard, Francisco Massa, and Alexandre D´ efossez. Hybrid Transformers for music source separation.IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.https://arxiv.org/abs/2211.08553
-
[6]
Robust Speech Recognition via Large-Scale Weak Supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision.International Conference on Machine Learning (ICML), 2023.https://arxiv.org/abs/2212.04356
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Matthias Mauch and Simon Dixon. pYIN: A fundamental frequency estimator using proba- bilistic threshold distributions.IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 659–663, 2014
work page 2014
-
[8]
Brian McFee, Colin Raffel, Dawen Liang, Daniel P. W. Ellis, Matt McVicar, Eric Battenberg, and Oriol Nieto. librosa: Audio and music signal analysis in Python.Proc. of the 14th Python in Science Conference (SciPy), pages 18–25, 2015. 9
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.