Recognition: 1 theorem link
· Lean TheoremLatent Causal Void: Explicit Missing-Context Reconstruction for Misinformation Detection
Pith reviewed 2026-05-13 05:53 UTC · model grok-4.3
The pith
Explicitly reconstructing omitted facts helps detect omission-based misinformation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
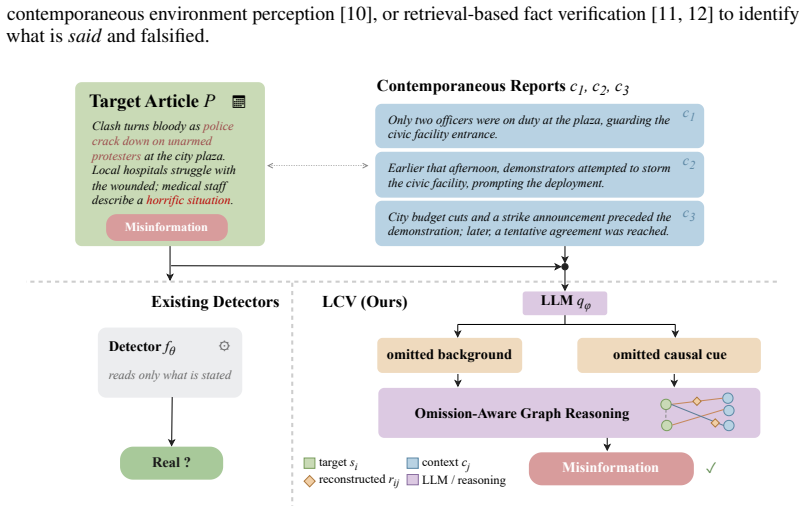
Latent Causal Void (LCV) retrieves temporally aligned articles, prompts a frozen LLM to generate short missing-context descriptions for each sentence-article pair, and incorporates these descriptions as textual relations within a heterograph to improve omission-aware misinformation detection, achieving 2.56 and 2.84 macro-F1 improvements on English and Chinese splits.
What carries the argument
The Latent Causal Void (LCV) method, which generates and uses explicit missing-context descriptions as cross-source textual relations in a heterograph.
If this is right
- Improved detection performance when misinformation relies on omissions rather than explicit falsehoods.
- Integration of LLM-generated relations into graph-based reasoning for fact-checking tasks.
- Applicability to both English and Chinese language settings in the evaluated benchmark.
- Shift from implicit omission signals to explicit fact modeling in detection systems.
Where Pith is reading between the lines
- Similar reconstruction techniques could enhance other areas like claim verification or summarization where context gaps matter.
- Testing with different LLMs or retrieval methods might further optimize the missing-context generation.
- Real-world deployment could involve updating the graph dynamically with new context articles.
Load-bearing premise
A frozen instruction-tuned LLM can reliably generate accurate and relevant short descriptions of the missing context for each target sentence.
What would settle it
An experiment showing no performance gain or even degradation when using the generated missing-context descriptions compared to baselines without them.
Figures




read the original abstract
Automatic misinformation detection performs well when deception is visible in what an article explicitly states. However, some misinformation articles remain locally coherent and only become misleading once compared with contemporaneous reports that supply background facts the article omits. We study this omission-relevant setting and observe that current omission-aware approaches typically either attach retrieved context as auxiliary evidence or infer a categorical omission signal, leaving the specific missing fact implicit. We propose \emph{Latent Causal Void} (LCV), a retrieval-guided detector that explicitly reconstructs the missing fact for each target sentence and uses it as a textual cross-source relation in graph reasoning. Concretely, LCV retrieves temporally aligned context articles, asks a frozen instruction-tuned large language model to generate a short missing-context description for each sentence--article pair, and feeds the resulting relation text into a heterograph over target sentences and context articles. On the bilingual benchmark of Sheng et al., LCV improves over the strongest omission-aware baseline by $2.56$ and $2.84$ macro-F1 points on the English and Chinese splits, respectively. The results indicate that modeling the missing cross-source fact itself, rather than only attaching retrieved evidence or predicting an omission signal, is a useful representation for omission-aware misinformation detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Latent Causal Void (LCV), a retrieval-guided detector for omission-aware misinformation detection. It retrieves temporally aligned context articles, prompts a frozen instruction-tuned LLM to generate short missing-context descriptions for each target sentence paired with retrieved articles, and feeds the resulting relation text as textual edges into a heterograph over target sentences and context articles. On the bilingual benchmark of Sheng et al., LCV reports macro-F1 gains of 2.56 (English) and 2.84 (Chinese) over the strongest omission-aware baseline, arguing that explicitly reconstructing the missing cross-source fact is a useful representation compared to attaching evidence or predicting an omission signal.
Significance. If the results hold after proper verification, the work would demonstrate that making the latent missing fact explicit as a textual relation in graph reasoning improves detection in omission-heavy misinformation settings. This distinguishes the approach from prior methods and provides a concrete mechanism for handling cross-source coherence failures. The bilingual evaluation and focus on explicit reconstruction are strengths, but the absence of supporting experimental details currently renders the claim preliminary.
major comments (2)
- [Experiments / §4] The abstract and method description claim specific macro-F1 improvements, but no experimental section details are provided on setup, retrieval implementation, LLM prompting, heterograph construction, chosen baselines, ablations, statistical tests, or error analysis. This leaves the reported gains unverified and the central claim unsupported from the text.
- [Method / §3.2 (LLM generation step)] The method relies on the frozen LLM producing faithful, relevant missing-context descriptions that function as useful textual relations. No human validation, automatic quality metrics, or error analysis of these generations is reported, nor is there an ablation isolating their contribution from retrieval or the graph architecture alone. If generations are frequently hallucinated or vague, the gains could be explained by other components.
minor comments (1)
- [Abstract] The benchmark is cited only as 'the bilingual benchmark of Sheng et al.' without a full reference or dataset name; adding the precise citation would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to provide the requested experimental details and validation.
read point-by-point responses
-
Referee: [Experiments / §4] The abstract and method description claim specific macro-F1 improvements, but no experimental section details are provided on setup, retrieval implementation, LLM prompting, heterograph construction, chosen baselines, ablations, statistical tests, or error analysis. This leaves the reported gains unverified and the central claim unsupported from the text.
Authors: We acknowledge that the initial submission provided insufficient detail in §4 to allow full verification of the reported macro-F1 gains. In the revised manuscript we will expand the experimental section with complete descriptions of the temporal retrieval implementation, exact LLM prompting templates and hyperparameters, heterograph construction (including node/edge features and message-passing details), baseline configurations, ablation variants, statistical significance testing (paired t-tests with p-values), and error analysis. These additions will substantiate the 2.56 and 2.84 point improvements on the English and Chinese splits of the Sheng et al. benchmark. revision: yes
-
Referee: [Method / §3.2 (LLM generation step)] The method relies on the frozen LLM producing faithful, relevant missing-context descriptions that function as useful textual relations. No human validation, automatic quality metrics, or error analysis of these generations is reported, nor is there an ablation isolating their contribution from retrieval or the graph architecture alone. If generations are frequently hallucinated or vague, the gains could be explained by other components.
Authors: We agree that explicit validation of the generated missing-context descriptions is necessary to support the central claim. The revised version will include both automatic quality metrics (e.g., embedding-based relevance to retrieved context) and a human evaluation on a random sample of generations assessing faithfulness and utility as cross-source relations. We will also add ablations that replace the explicit relation text with raw retrieved sentences or a simple omission flag, thereby isolating the contribution of the reconstructed fact from retrieval and graph structure alone. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's derivation chain is a procedural definition: retrieve temporally aligned articles, prompt a frozen instruction-tuned LLM to produce short missing-context descriptions for each sentence-article pair, and insert the resulting text as relation labels in a heterograph. These steps are externally specified (retrieval + LLM generation) rather than tautological. Performance gains are reported as empirical macro-F1 improvements on the external Sheng et al. bilingual benchmark; no equation reduces a claimed prediction to a fitted parameter by construction, and no self-citation supplies a load-bearing uniqueness theorem or ansatz. The central representation is generated outside the detection model itself, making the method self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fake news detection on social media: A data mining perspective,
Kai Shu, Amy Sliva, Suhang Wang, Jiliang Tang, and Huan Liu, “Fake news detection on social media: A data mining perspective,”SIGKDD Explorations, vol. 19, no. 1, pp. 22–36, 2017
work page 2017
-
[2]
A survey of fake news: Fundamental theories, detection methods, and opportunities,
Xinyi Zhou and Reza Zafarani, “A survey of fake news: Fundamental theories, detection methods, and opportunities,”ACM Computing Surveys, vol. 53, no. 5, pp. 1–40, 2020
work page 2020
-
[3]
Rainer Greifeneder, Mariela Jaffe, Eryn Newman, and Norbert Schwarz,The Psychology of Fake News: Accepting, Sharing, and Correcting Misinformation. Routledge, 2020
work page 2020
-
[4]
Carson,Lying and Deception: Theory and Practice
Thomas L. Carson,Lying and Deception: Theory and Practice. Oxford University Press, 2010
work page 2010
-
[5]
MSynFD: Multi-hop syntax aware fake news detection,
Liang Xiao, Qi Zhang, Chongyang Shi, Shoujin Wang, Usman Naseem, and Liang Hu, “MSynFD: Multi-hop syntax aware fake news detection,” inProceedings of the ACM Web Conference 2024, pp. 4128–4137, 2024
work page 2024
-
[6]
FKA-Owl: Advancing multimodal fake news detection through knowledge-augmented LVLMs,
Xuannan Liu, Peipei Li, Huaibo Huang, Zekun Li, Xing Cui, Jiahao Liang, Lixiong Qin, Wei- hong Deng, and Zhaofeng He, “FKA-Owl: Advancing multimodal fake news detection through knowledge-augmented LVLMs,” inProceedings of the 32nd ACM International Conference on Multimedia, pp. 10154–10163, 2024. 9
work page 2024
-
[7]
Latent-causal graph analysis: evidence integration and prediction shift
-
[8]
Retrieved supporting reports: latent-causal context recovery Key Fact 1:
-
[9]
Missing-context recovery map: explicit links Key Fact 5:
-
[10]
Critics call for mayor's immediate b) Snippet 2:
Target article evidence: presented-only view Key Fact 3: Headline: City Faces Looming Budget Crisis and Union Negotiations Key Fact 6: Source: Key Fact 2: Source: Source: c) Snippet 3: "Critics call for mayor's immediate b) Snippet 2: "Hundreds of residents took to the Headline: Strike Ends as Tentative Agreement Reached Headline: Union Negotiations Stall...
work page 2023
-
[11]
Harmfully manipulated images matter in multimodal misinformation detection,
Bing Wang, Shengsheng Wang, Changchun Li, Renchu Guan, and Ximing Li, “Harmfully manipulated images matter in multimodal misinformation detection,” inProceedings of the 32nd ACM International Conference on Multimedia, pp. 2262–2271, 2024
work page 2024
-
[12]
Multimodal fake news detection: MFND dataset and shallow-deep multitask learning,
Ye Zhu, Yunan Wang, and Zitong Yu, “Multimodal fake news detection: MFND dataset and shallow-deep multitask learning,” inProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, pp. 8012–8020, 2025
work page 2025
-
[13]
PCoT: Persuasion-augmented chain of thought for detecting fake news and social media disinformation,
Arkadiusz Modzelewski, Witold Sosnowski, Tiziano Labruna, Adam Wierzbicki, and Giovanni Da San Martino, “PCoT: Persuasion-augmented chain of thought for detecting fake news and social media disinformation,” inProceedings of ACL, 2025
work page 2025
-
[14]
Zoom out and observe: News environment perception for fake news detection,
Qiang Sheng, Juan Cao, Xueyao Zhang, Rundong Li, Danding Wang, and Yongchun Zhu, “Zoom out and observe: News environment perception for fake news detection,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 4543–4556, 2022
work page 2022
-
[15]
Retrieval augmented fact verification by synthesizing contrastive arguments,
Zhenrui Yue, Huimin Zeng, Lanyu Shang, Yifan Liu, Yang Zhang, and Dong Wang, “Retrieval augmented fact verification by synthesizing contrastive arguments,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 10331–10343, 2024
work page 2024
-
[16]
Robust misinformation detection by visiting potential commonsense conflict,
Bing Wang, Ximing Li, Changchun Li, Bingrui Zhao, Bo Fu, Renchu Guan, and Sheng- sheng Wang, “Robust misinformation detection by visiting potential commonsense conflict,” inProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, pp. 7760–7768, 2025. 10
work page 2025
-
[17]
Reasoning about the unsaid: Misinformation detection with omission-aware graph inference,
Zhengjia Wang, Danding Wang, Qiang Sheng, Jiaying Wu, and Juan Cao, “Reasoning about the unsaid: Misinformation detection with omission-aware graph inference,” inProceedings of AAAI, pp. 1249–1257, 2026
work page 2026
-
[18]
The stepwise deception: Simulating the evolution from true news to fake news with LLM agents,
Yuhan Liu, Zirui Song, Juntian Zhang, Xiaoqing Zhang, Xiuying Chen, and Rui Yan, “The stepwise deception: Simulating the evolution from true news to fake news with LLM agents,” in Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 26176–26192, 2025
work page 2025
-
[19]
Recon, answer, verify: Agents in search of truth,
Satyam Shukla, Himanshu Dutta, and Pushpak Bhattacharyya, “Recon, answer, verify: Agents in search of truth,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track, pp. 2429–2448, 2025
work page 2025
-
[20]
Evaluating evidence attribution in generated fact checking explanations,
Rui Xing, Timothy Baldwin, and Jey Han Lau, “Evaluating evidence attribution in generated fact checking explanations,” inProceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 5475–5496, 2025
work page 2025
-
[21]
Mining dual emotion for fake news detection,
Xueyao Zhang, Juan Cao, Xirong Li, Qiang Sheng, Lei Zhong, and Kai Shu, “Mining dual emotion for fake news detection,” inProceedings of the Web Conference 2021, pp. 3465–3476, 2021
work page 2021
-
[22]
Tianlin Zhang, En Yu, Yi Shao, and Jiande Sun, “Multimodal inverse attention network with intrinsic discriminant feature exploitation for fake news detection,” inProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, pp. 7940–7948, 2025
work page 2025
-
[23]
Disconfounding fake news video explanation with causal inference,
Lizhi Chen, Zhong Qian, Peifeng Li, and Qiaoming Zhu, “Disconfounding fake news video explanation with causal inference,” inProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, pp. 4842–4850, 2025
work page 2025
-
[24]
Hui Li, Ante Wang, Kunquan Li, Zhihao Wang, Liang Zhang, Delai Qiu, Qingsong Liu, and Jinsong Su, “A multi-agent framework with automated decision rule optimization for cross-domain misinformation detection,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 5709–5725, 2025
work page 2025
-
[25]
TRUST-VL: An explainable news assis- tant for general multimodal misinformation detection,
Zehong Yan, Peng Qi, Wynne Hsu, and Mong-Li Lee, “TRUST-VL: An explainable news assis- tant for general multimodal misinformation detection,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 5588–5604, 2025
work page 2025
-
[26]
SSA: Semantic contamina- tion of LLM-driven fake news detection,
Cheng Xu, Nan Yan, Shuhao Guan, Yuke Mei, and Tahar Kechadi, “SSA: Semantic contamina- tion of LLM-driven fake news detection,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 14737–14751, 2025
work page 2025
-
[27]
TripleFact: Defending data contamination in the evaluation of LLM- driven fake news detection,
Cheng Xu and Nan Yan, “TripleFact: Defending data contamination in the evaluation of LLM- driven fake news detection,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 8808–8823, 2025
work page 2025
-
[28]
Birds of a feather: Enhancing multimodal fake news detection via multi-element retrieval,
Xueqin Chen, Xiaoyu Huang, Qiang Gao, Li Huang, Jiajing Yu, and Guisong Liu, “Birds of a feather: Enhancing multimodal fake news detection via multi-element retrieval,” inProceedings of ICDE, pp. 1–14, 2025
work page 2025
-
[29]
Vítor Lourenço, Aline Paes, Tillman Weyde, Audrey Depeige, and Mohnish Dubey, “KG- CRAFT: Knowledge graph-based contrastive reasoning with LLMs for enhancing automated fact-checking,” inProceedings of the 19th Conference of the European Chapter of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pp. 6419–6439, 2026
work page 2026
-
[30]
ChronoFact: Timeline-based tempo- ral fact verification,
Anab Maulana Barik, Wynne Hsu, and Mong Li Lee, “ChronoFact: Timeline-based tempo- ral fact verification,” inProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, pp. 8031–8039, 2025
work page 2025
-
[31]
Investigating language and retrieval bias in multilingual previously fact-checked claim detection,
Ivan Vykopal, Antonia Karamolegkou, Jaroslav Kopˇcan, Qiwei Peng, Tomáš Jav˚ urek, Michal Gregor, and Marian Simko, “Investigating language and retrieval bias in multilingual previously fact-checked claim detection,” inProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 5...
work page 2026
-
[32]
Attacks by content: Automated fact-checking is an AI security issue,
Michael Sejr Schlichtkrull, “Attacks by content: Automated fact-checking is an AI security issue,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 8550–8565, 2025
work page 2025
-
[33]
Zhiwei Liu, Kailai Yang, Qianqian Xie, Christine de Kock, Sophia Ananiadou, and Eduard Hovy, “RAEmoLLM: Retrieval augmented LLMs for cross-domain misinformation detection using in-context learning based on emotional information,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 16508–16...
work page 2025
-
[34]
BERT: Pre-training of deep bidirectional transformers for language understanding,
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” inProceedings of NAACL-HLT, pp. 4171–4186, 2019
work page 2019
-
[35]
Abhimanyu Dubey et al., “The Llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024. 12 NeurIPS Paper Checklist 1.Claims Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? Answer: [Yes] Justification: The abstract and Introduction summarize the representational claim, the metho...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.