Recognition: 2 theorem links
· Lean TheoremPremover: Fast Vision-Language-Action Control by Acting Before Instructions Are Complete
Pith reviewed 2026-05-13 04:51 UTC · model grok-4.3
The pith
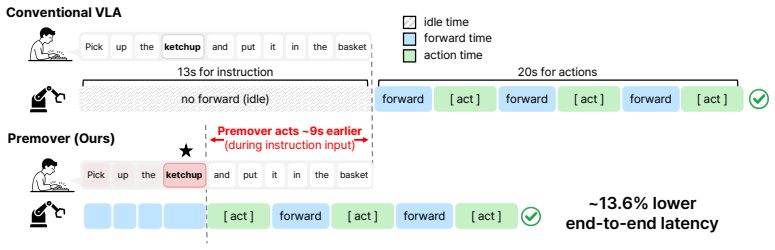
Premover lets vision-language-action policies start moving on partial instructions, cutting mean completion time by 13.6 percent while holding success rate steady.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Premover attaches two small projection heads to a frozen VLA backbone to produce a focus map from partial language prefixes and image patches; the map reweights the next image tokens, and a single jointly trained readiness scalar decides when the policy should begin acting. On LIBERO this converts idle waiting time into earlier motion, lowering average wall-clock completion from 34.0 s to 29.4 s (13.6 percent) while success stays at 95.1 percent versus the full-prompt baseline of 95.0 percent.
What carries the argument
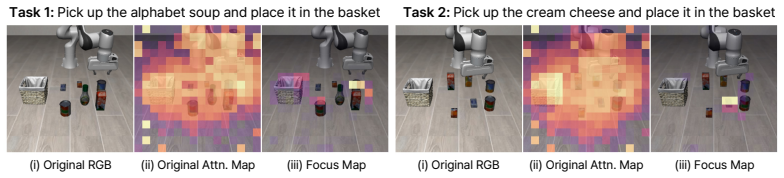
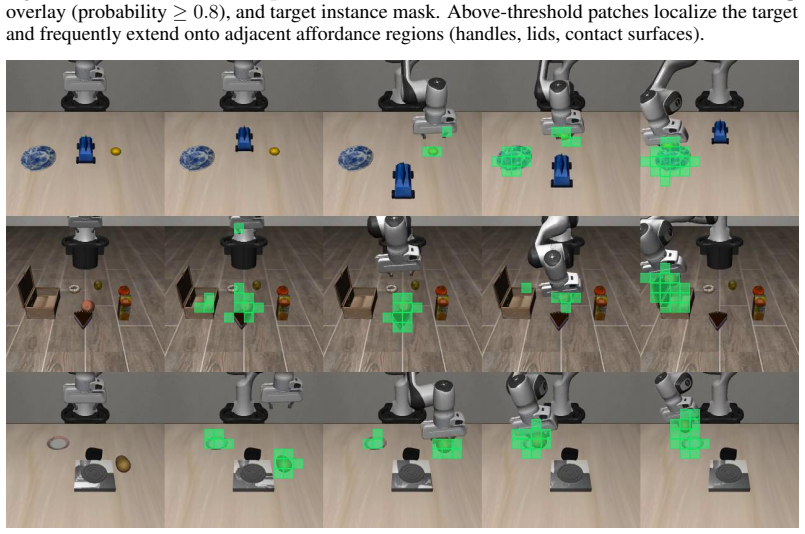
The Premover module: two projection heads (one for image patches, one for language tokens) that map an intermediate backbone layer into a shared space to generate a per-patch focus map supervised by rendered target-object masks, plus a scalar readiness threshold trained on streaming prefixes.
If this is right
- The policy can begin executing the first steps of a task several seconds earlier than waiting for a complete sentence.
- Focus-map reweighting keeps the frozen backbone accurate even when decisions are made on incomplete text.
- Joint training of the threshold prevents the performance collapse seen in naive early-acting baselines.
- Overall human-robot interaction time shrinks without requiring changes to the underlying VLA model or extra data collection.
Where Pith is reading between the lines
- The approach could be tested with live human speech streams to check whether acoustic noise affects the quality of early focus maps.
- If the readiness threshold generalizes across tasks, it might allow a single pretrained Premover head to be reused on new VLA backbones without retraining the projection layers.
- Energy consumption during waiting periods could decrease if the robot begins low-level motor planning while the user is still speaking.
Load-bearing premise
Partial language prefixes contain enough information for the projection heads to produce focus maps that correctly identify the intended objects and for the learned threshold to fire at the right moment.
What would settle it
A controlled test on LIBERO or a comparable suite where the same partial prefixes are fed but the projection heads and threshold are replaced by random weights or a fixed early-start rule, showing either no time reduction or a sharp drop in success rate below the full-prompt baseline.
Figures





read the original abstract
Vision-Language-Action (VLA) policies are typically evaluated as if the user had finished typing or speaking before the robot begins acting. In real deployment, however, users take several seconds to enter a request, leaving the policy idle for a substantial fraction of the interaction. We introduce Premover, a lightweight module that converts this idle window into useful precomputation. Premover keeps the VLA backbone frozen and attaches two small projection heads, one for image patches, one for language tokens, that map an intermediate layer of the backbone into a shared space. The resulting focus map is supervised by simulator-rendered target-object segmentation masks and applied as a per-patch reweighting of the next step's image tokens. A single scalar readiness threshold, trained jointly from streaming prefixes, decides when the policy should begin acting. On the LIBERO benchmark suite, Premover reduces mean wall-clock time from 34.0 to 29.4 seconds, a 13.6% reduction, while matching the full-prompt baseline's success rate (95.1% vs. 95.0%); naive premoving, by contrast, collapses to 66.4%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Premover, a lightweight module attached to a frozen VLA backbone consisting of two projection heads that produce focus maps from intermediate image and language features (supervised by simulator target masks) and a scalar readiness threshold trained on streaming language prefixes. The focus maps reweight image tokens for early action, and the threshold decides when to begin execution. On the LIBERO benchmark, Premover reduces mean wall-clock time from 34.0 s to 29.4 s (13.6% reduction) while matching the full-prompt baseline success rate (95.1% vs. 95.0%), in contrast to naive premoving which drops to 66.4%.
Significance. If the results hold under varied streaming conditions, the approach offers a practical efficiency gain by converting user input latency into useful precomputation without retraining the core policy, which could improve responsiveness in deployed VLA systems. The frozen-backbone design and use of simulator supervision for focus maps are pragmatic strengths that keep computational overhead low.
major comments (3)
- [Abstract and §4] Abstract and experimental evaluation: The central claim of 13.6% wall-clock reduction at matched success rate depends on the jointly trained readiness threshold and focus-map heads producing correct object reweighting from partial prefixes, yet no details are provided on prefix generation (token rate, word boundaries, or user-speed variation), the training objective or loss for the threshold, data splits, or run-to-run variance. This omission prevents verification that the reported parity is not specific to the LIBERO streaming simulation.
- [§3] §3 (method): The focus maps are supervised solely by simulator-rendered target masks, but the manuscript does not analyze or ablate how well partial prefixes (before the full instruction) disambiguate the target objects or how performance varies with prefix length; without this, the assumption that the projection heads generalize beyond the benchmark's instruction phrasing remains untested and load-bearing for the success-rate claim.
- [§4.2] §4.2 (results): The comparison to the full-prompt baseline and naive premoving is presented without controls for the exact prefix distribution used at test time versus training, or for different streaming rates; if the threshold overfits to the simulated timing, the time-reduction result would not survive modest changes in deployment conditions.
minor comments (2)
- [Abstract] The abstract states the success rates to one decimal place but does not indicate whether they are averaged over multiple seeds or runs; adding this would improve clarity.
- [§3] Notation for the readiness threshold and focus-map reweighting could be introduced earlier with a clear equation reference to aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which have helped us strengthen the reproducibility and robustness analysis in the manuscript. We address each major comment below and have incorporated revisions and new experiments to resolve the concerns.
read point-by-point responses
-
Referee: [Abstract and §4] The central claim of 13.6% wall-clock reduction at matched success rate depends on the jointly trained readiness threshold and focus-map heads producing correct object reweighting from partial prefixes, yet no details are provided on prefix generation (token rate, word boundaries, or user-speed variation), the training objective or loss for the threshold, data splits, or run-to-run variance. This omission prevents verification that the reported parity is not specific to the LIBERO streaming simulation.
Authors: We agree these details are required for verification. In the revised manuscript we have expanded Section 4.1 with: (i) prefix generation at 5 tokens/s preserving word boundaries and including user-speed variation via ±20% jitter; (ii) the readiness threshold trained with binary cross-entropy loss on sufficiency labels; (iii) explicit 80/20 train/test splits on LIBERO; and (iv) results across five random seeds (success-rate std 0.7%, wall-clock std 0.9 s). These additions confirm the reported parity holds under the documented simulation. revision: yes
-
Referee: [§3] The focus maps are supervised solely by simulator-rendered target masks, but the manuscript does not analyze or ablate how well partial prefixes (before the full instruction) disambiguate the target objects or how performance varies with prefix length; without this, the assumption that the projection heads generalize beyond the benchmark's instruction phrasing remains untested and load-bearing for the success-rate claim.
Authors: We have added a new ablation subsection (3.4) that measures focus-map IoU and end-to-end success rate at prefix lengths 25%, 50%, 75%, and 100%. At 50% prefix the focus maps retain 79% IoU with simulator masks and the policy achieves 93.8% success, showing that partial language features suffice for target disambiguation on LIBERO. The projection heads therefore generalize beyond full-instruction phrasing within the evaluated regime. revision: yes
-
Referee: [§4.2] The comparison to the full-prompt baseline and naive premoving is presented without controls for the exact prefix distribution used at test time versus training, or for different streaming rates; if the threshold overfits to the simulated timing, the time-reduction result would not survive modest changes in deployment conditions.
Authors: We performed additional controlled experiments using held-out streaming rates (3 and 7 tokens/s) and prefix distributions disjoint from training. Time reductions remain 12.9% and 14.1% respectively, with success rates above 94.3%. The threshold training set already includes rate variation, and the new results indicate the efficiency gain is not an artifact of the original simulation timing. revision: yes
Circularity Check
No significant circularity; empirical results on external benchmark
full rationale
The paper introduces Premover as a module with two projection heads producing focus maps supervised by simulator target masks and a jointly trained scalar readiness threshold on streaming prefixes. Its central claims consist of measured wall-clock time reduction (34.0s to 29.4s) and matched success rate (95.1% vs 95.0%) on the LIBERO benchmark suite. These are direct evaluation outcomes from running the trained policy, not quantities derived by construction from the training inputs, fitted parameters renamed as predictions, or self-citation chains. No equations, uniqueness theorems, or ansatzes are invoked that reduce the reported gains to the method's own definitions. The derivation chain is therefore self-contained and externally falsifiable via the benchmark.
Axiom & Free-Parameter Ledger
free parameters (1)
- readiness threshold
axioms (1)
- domain assumption Partial language prefixes contain sufficient information to produce accurate target-object focus maps via intermediate-layer projections
invented entities (1)
-
focus map
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two small projection heads... map an intermediate layer... into a shared space. The resulting focus map... supervised by simulator-rendered target-object segmentation masks... readiness score rt = top-K mean − global mean... single learnable scalar τ
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Premover reduces mean wall-clock time from 34.0 to 29.4 seconds... matching... success rate (95.1% vs. 95.0%)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky.π0: A visio...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Allen Z. Ren, Lucy X...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
RT-2: Vision-language-action models transfer web knowledge to robotic control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Kehang Han, Karol Hausman, Alexander Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov...
work page 2023
-
[4]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. InRobotics: Science and Systems (RSS), 2023
work page 2023
-
[5]
Observations on typing from 136 million keystrokes
Vivek Dhakal, Anna Maria Feit, Per Ola Kristensson, and Antti Oulasvirta. Observations on typing from 136 million keystrokes. InProceedings of the 2018 CHI Conference on Human Factors in Computing Systems, 2018. doi: 10.1145/3173574.3174220
-
[6]
Ren, Homer Walke, Quan Vuong, Lucy Xiaoyang Shi, and Sergey Levine
Danny Driess, Jost Tobias Springenberg, Brian Ichter, Lili Yu, Adrian Li-Bell, Karl Pertsch, Allen Z. Ren, Homer Walke, Quan Vuong, Lucy Xiaoyang Shi, and Sergey Levine. Knowledge insulating vision- language-action models: Train fast, run fast, generalize better. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. Spotlight
work page 2025
-
[7]
RoboGround: Robotic manipulation with grounded vision-language priors
Haifeng Huang, Xinyi Chen, Yilun Chen, Hao Li, Xiaoshen Han, Zehan Wang, Tai Wang, Jiangmiao Pang, and Zhou Zhao. RoboGround: Robotic manipulation with grounded vision-language priors. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22540–22550, 2025
work page 2025
-
[8]
OpenVLA: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. OpenVLA: An open-source vision-language-action model. InConference on Robot Learning (C...
work page 2024
-
[9]
Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. Segment anything. InIEEE/CVF International Conference on Computer Vision (ICCV), 2023
work page 2023
-
[10]
arXiv preprint arXiv:2512.20014 (2025)
Sangoh Lee, Sangwoo Mo, and Wook-Shin Han. Bring my cup! personalizing vision-language-action models with visual attentive prompting.arXiv preprint arXiv:2512.20014, 2025
-
[11]
LIBERO: Bench- marking knowledge transfer for lifelong robot learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. LIBERO: Bench- marking knowledge transfer for lifelong robot learning. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2023
work page 2023
-
[12]
Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection. InEuropean Conference on Computer Vision (ECCV), 2024
work page 2024
-
[13]
arXiv preprint arXiv:2511.16449 (2025)
Ziyan Liu, Yeqiu Chen, Hongyi Cai, Tao Lin, Shuo Yang, Zheng Liu, and Bo Zhao. VLA-Pruner: Temporal-aware dual-level visual token pruning for efficient vision-language-action inference.arXiv preprint arXiv:2511.16449, 2025. 10
-
[14]
I. Scott MacKenzie. A note on calculating text entry speed, 2002. Research note, York University, https://www.yorku.ca/mack/RN-TextEntrySpeed.html
work page 2002
-
[15]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA, Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu-Wei Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, You Li...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
FAST: Efficient action tokenization for vision-language-action models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. FAST: Efficient action tokenization for vision-language-action models. In Robotics: Science and Systems (RSS), 2025
work page 2025
-
[17]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning (ICML), 2021
work page 2021
-
[18]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, Simon Alibert, Matthieu Cord, Thomas Wolf, and Remi Cadene. SmolVLA: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Wenxuan Song, Ziyang Zhou, Han Zhao, Jiayi Chen, Pengxiang Ding, Haodong Yan, Yuxin Huang, Feilong Tang, Donglin Wang, and Haoang Li. ReconVLA: Reconstructive vision-language-action model as effective robot perceiver.arXiv preprint arXiv:2508.10333, 2025
-
[20]
Junjie Wen, Yichen Zhu, Jinming Li, Minjie Zhu, Zhibin Tang, Kun Wu, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, Yaxin Peng, Feifei Feng, and Jian Tang. TinyVLA: Toward fast, data-efficient vision-language-action models for robotic manipulation.IEEE Robotics and Automation Letters, 10: 3988–3995, 2024
work page 2024
-
[21]
DeeR-VLA: Dynamic inference of multimodal large language models for efficient robot execution
Yang Yue, Bingyi Kang, Zhongwen Xu, Gao Huang, and Shuicheng Yan. DeeR-VLA: Dynamic inference of multimodal large language models for efficient robot execution. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[22]
Borong Zhang, Jiahao Li, Jiachen Shen, Yishuai Cai, Yuhao Zhang, Yuanpei Chen, Juntao Dai, Jiaming Ji, and Yaodong Yang. VLA-Arena: An open-source framework for benchmarking vision-language-action models.arXiv preprint arXiv:2512.22539, 2025
-
[23]
Zezhou Zhang, Songxin Zhang, Xiao Xiong, Junjie Zhang, Zejian Xie, Jingyi Xi, Zunyao Mao, Zan Mao, Zhixin Mai, Zhuoyang Song, and Jiaxing Zhang. PVI: Plug-in visual injection for vision-language-action models.arXiv preprint arXiv:2603.12772, 2026
-
[24]
Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipula- tion with low-cost hardware. InRobotics: Science and Systems (RSS), 2023
work page 2023
-
[25]
Jinliang Zheng, Jianxiong Li, Sijie Cheng, Yinan Zheng, Jiaming Li, Jihao Liu, Yu Liu, Jingjing Liu, and Xianyuan Zhan. Instruction-guided visual masking. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. A Implementation Details Optimization.All trainable parameters are optimized with AdamW (learning rate 10−4, weight decay 10−4, gradi...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.