Recognition: no theorem link
Mitigating Context-Memory Conflicts in LLMs through Dynamic Cognitive Reconciliation Decoding
Pith reviewed 2026-05-13 05:42 UTC · model grok-4.3
The pith
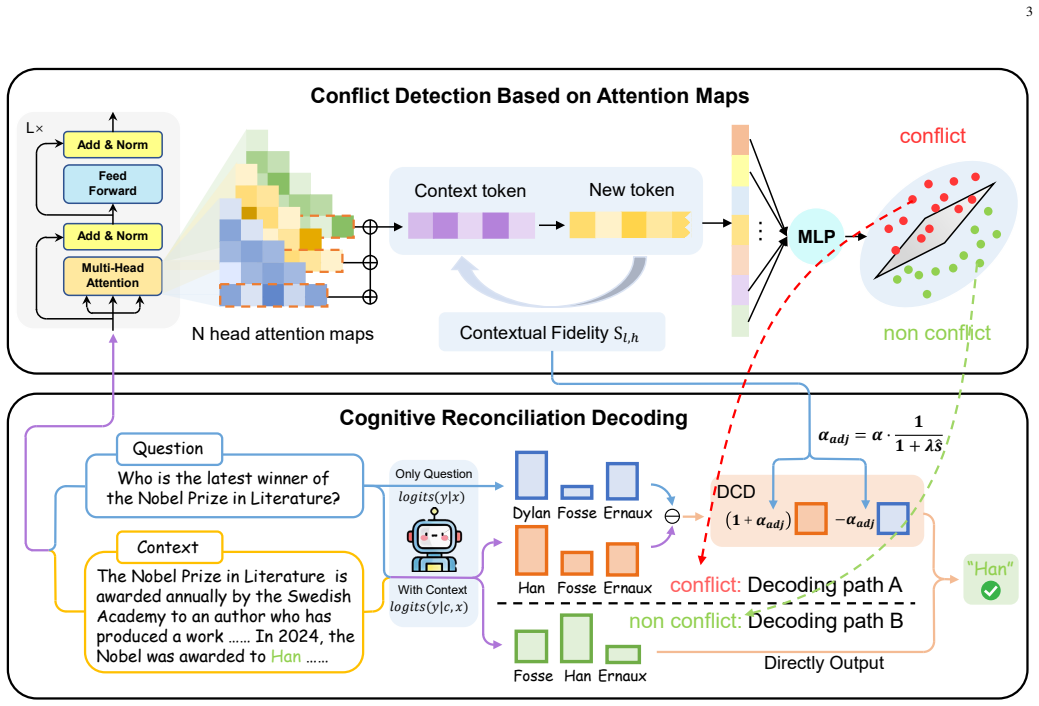
DCRD detects context-memory conflicts in LLMs via attention-map analysis and routes decoding to either greedy or dynamic fidelity paths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central proposal is a two-stage decoding procedure named DCRD. In the first stage the model examines its own attention map to estimate how faithfully it is attending to the supplied context versus its stored parametric knowledge, thereby predicting the likelihood of a conflict. Based on that prediction the input is routed either to ordinary greedy decoding or to a second decoding path that dynamically adjusts outputs according to measured context fidelity.
What carries the argument
Attention-map analysis of context fidelity, used to predict conflict and route the input to either greedy decoding or context-fidelity dynamic decoding.
If this is right
- LLMs can maintain high accuracy on QA tasks even when external knowledge updates contradict pre-trained facts.
- Decoding can adapt dynamically to internal signals rather than applying a single fixed strategy to every input.
- The ConflictKG benchmark enables systematic evaluation of methods under controlled frequent knowledge-update conditions.
- Overall performance improves across multiple model sizes and QA datasets while preserving efficiency in conflict-free cases.
Where Pith is reading between the lines
- If attention-map signals prove stable, the same routing idea could be applied to detect other internal inconsistencies such as hallucination risk.
- The two-path design might transfer to non-QA settings like long-document summarization where context and memory also interact.
- Further experiments could check whether the routing decision itself creates measurable distribution shifts on edge-case inputs.
Load-bearing premise
Attention patterns inside the model can reliably indicate whether a real conflict between context and parametric memory is present and how severe it is.
What would settle it
Measure whether DCRD accuracy drops below strong baselines on test cases where attention maps show high context fidelity yet a genuine knowledge conflict exists, or where maps show low fidelity yet no conflict is present.
Figures


read the original abstract
Large language models accumulate extensive parametric knowledge through pre-training. However, knowledge conflicts occur when outdated or incorrect parametric knowledge conflicts with external knowledge in the context. Existing methods address knowledge conflicts through contrastive decoding, but in conflict-free scenarios, static approaches disrupt output distribution. Other dynamic decoding methods attempt to measure the degree of conflict but still struggle with complex real-world situations. In this paper, we propose a two-stage decoding method called Dynamic Cognitive Reconciliation Decoding (DCRD), to predict and mitigate context-memory conflicts. DCRD first analyzes the attention map to assess context fidelity and predict potential conflicts. Based on this prediction, the input is directed to one of two decoding paths: (1) greedy decoding, or (2) context fidelity-based dynamic decoding. This design enables DCRD to handle conflicts efficiently while maintaining high accuracy and decoding efficiency in conflict-free cases. Additionally, to simulate scenarios with frequent knowledge updates, we constructed ConflictKG, a knowledge conflict QA benchmark. Experiments on four LLMs across six QA datasets show that DCRD outperforms all baselines, achieving state-of-the-art performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Dynamic Cognitive Reconciliation Decoding (DCRD), a two-stage decoding method for LLMs that first analyzes attention maps to assess context fidelity and predict context-memory conflicts, then routes the input to either standard greedy decoding or a context-fidelity dynamic decoding path. It introduces the ConflictKG benchmark to simulate frequent knowledge updates and reports that DCRD achieves state-of-the-art performance over baselines across four LLMs and six QA datasets.
Significance. If the gains are shown to stem specifically from accurate conflict prediction and routing rather than ancillary decoding effects, DCRD could offer a practical, efficient solution for balancing parametric and contextual knowledge in deployed LLMs. The ConflictKG benchmark is a constructive addition that enables targeted evaluation of conflict-handling methods.
major comments (2)
- [§3.2] §3.2 (Attention-based conflict prediction): The central routing decision relies on attention map analysis to predict conflicts, yet the manuscript supplies no validation such as correlation coefficients with ground-truth conflict labels, human annotations, or an ablation that disables the prediction stage while retaining the dynamic decoding path. Without this, it remains possible that reported improvements arise from general decoding adjustments or benchmark artifacts rather than targeted reconciliation.
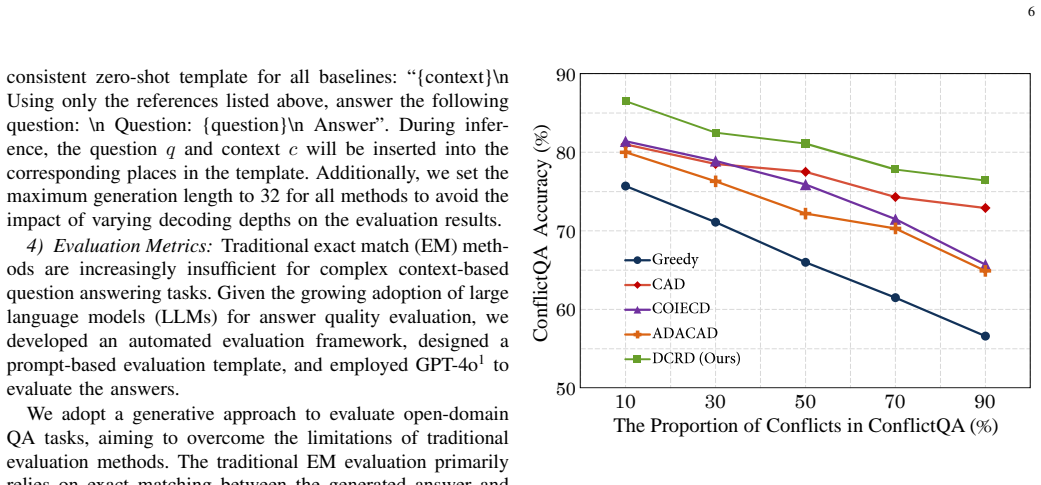
- [§4.3] §4.3 and Table 4 (Experimental results on ConflictKG and QA datasets): The SOTA claim is load-bearing but lacks statistical significance tests (e.g., paired t-tests or bootstrap confidence intervals), details on baseline hyperparameter matching, and an ablation isolating the contribution of the attention-based router. This weakens the ability to attribute gains specifically to conflict mitigation.
minor comments (3)
- [§3.1] The notation for the context fidelity score in §3.1 could be formalized with an explicit equation to improve reproducibility.
- [Figure 2] Figure 2 would benefit from an additional panel or caption clarifying how attention patterns differ between conflict and non-conflict examples.
- [§2] A few citations to recent contrastive decoding variants are absent from the related work section.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major point below and commit to revisions that will strengthen the validation of DCRD's conflict prediction and the statistical rigor of our results.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Attention-based conflict prediction): The central routing decision relies on attention map analysis to predict conflicts, yet the manuscript supplies no validation such as correlation coefficients with ground-truth conflict labels, human annotations, or an ablation that disables the prediction stage while retaining the dynamic decoding path. Without this, it remains possible that reported improvements arise from general decoding adjustments or benchmark artifacts rather than targeted reconciliation.
Authors: We agree that direct validation of the attention-based router is essential to attribute gains specifically to conflict detection. In the revised manuscript we will add (1) Pearson correlation coefficients between the attention-derived conflict score and the explicit ground-truth conflict labels available in ConflictKG, and (2) an ablation that replaces the learned router with either random routing or a fixed always-dynamic-decoding policy while keeping the fidelity-based decoding path intact. These additions will demonstrate that performance improvements are driven by accurate conflict prediction rather than generic decoding changes. revision: yes
-
Referee: [§4.3] §4.3 and Table 4 (Experimental results on ConflictKG and QA datasets): The SOTA claim is load-bearing but lacks statistical significance tests (e.g., paired t-tests or bootstrap confidence intervals), details on baseline hyperparameter matching, and an ablation isolating the contribution of the attention-based router. This weakens the ability to attribute gains specifically to conflict mitigation.
Authors: We acknowledge the importance of statistical validation and fair comparison. The revised version will include paired t-tests and bootstrap 95% confidence intervals on the differences reported in Table 4. We will also document the hyperparameter search ranges and final settings used for all baselines to confirm matching computational budgets. The router ablation described in our response to §3.2 will further isolate the contribution of the attention-based routing decision. These changes will allow readers to attribute the reported gains more confidently to conflict mitigation. revision: yes
Circularity Check
No circularity detected; empirical engineering method without derivations or self-referential reductions
full rationale
The paper describes DCRD as a two-stage heuristic: attention-map analysis to predict conflicts, followed by routing to greedy or context-fidelity decoding. No equations, fitted parameters presented as predictions, or derivation chains appear in the abstract or described method. Performance claims rest on experimental results across LLMs and datasets rather than reducing to inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are referenced. This is a standard empirical contribution with independent evaluation content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Improving language understanding by generative pre-training,
A. Radford and K. Narasimhan, “Improving language understanding by generative pre-training,” 2018
work page 2018
-
[2]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. D. M.-W. C. Kenton and L. K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inProceedings of NAACL-HLT, vol. 1, no. 2. Minneapolis, Minnesota, 2019
work page 2019
-
[3]
Dolma: an open corpus of three trillion tokens for language model pretraining research,
L. Soldaini, R. Kinney, A. Bhagia, D. Schwenk, D. Atkinson, R. Authur, B. Bogin, K. Chandu, J. Dumas, Y . Elazar, V . Hofmann, A. Jha, S. Kumar, L. Lucy, X. Lyu, N. Lambert, I. Magnusson, J. Morri- son, N. Muennighoff, A. Naik, C. Nam, M. Peters, A. Ravichander, K. Richardson, Z. Shen, E. Strubell, N. Subramani, O. Tafjord, E. Walsh, L. Zettlemoyer, N. Sm...
work page 2024
-
[4]
Instruction-tuned language models are better knowledge learners,
Z. Jiang, Z. Sun, W. Shi, P. Rodriguez, C. Zhou, G. Neubig, X. Lin, W.-t. Yih, and S. Iyer, “Instruction-tuned language models are better knowledge learners,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), L.-W. Ku, A. Martins, and V . Srikumar, Eds., 2024
work page 2024
-
[5]
How do large language models capture the ever-changing world knowledge? a review of recent advances,
Z. Zhang, M. Fang, L. Chen, M.-R. Namazi-Rad, and J. Wang, “How do large language models capture the ever-changing world knowledge? a review of recent advances,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), H. Bouamor, J. Pino, and K. Bali, Eds., 2023
work page 2023
-
[6]
Knowledge editing through chain- of-thought,
C. Wang, W. Su, Q. Ai, and Y . Liu, “Knowledge editing through chain- of-thought,”arXiv preprint arXiv:2412.17727, 2024
-
[7]
H.-T. Chen, M. Zhang, and E. Choi, “Rich knowledge sources bring complex knowledge conflicts: Recalibrating models to reflect conflicting evidence,” inProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), Y . Goldberg, Z. Kozareva, and Y . Zhang, Eds., 2022
work page 2022
-
[8]
Resolving knowledge conflicts in large language models,
Y . Wang, S. Feng, H. Wang, W. Shi, V . Balachandran, T. He, and Y . Tsvetkov, “Resolving knowledge conflicts in large language models,” arXiv preprint arXiv:2310.00935, 2023
-
[9]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. S. H. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Küttler, M. Lewis, W. Yih, T. Rocktäschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,” in Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin,...
work page 2020
-
[10]
Redeep: Detecting hallucination in retrieval-augmented generation via mechanistic interpretability,
Z. Sun, X. Zang, K. Zheng, Y . Song, J. Xu, X. Zhang, W. Yu, and H. Li, “Redeep: Detecting hallucination in retrieval-augmented generation via mechanistic interpretability,”arXiv preprint arXiv:2410.11414, 2024
-
[11]
Making retrieval- augmented language models robust to irrelevant context,
O. Yoran, T. Wolfson, O. Ram, and J. Berant, “Making retrieval- augmented language models robust to irrelevant context,” inThe Twelfth International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[12]
Retrieval meets long context large language models,
P. Xu, W. Ping, X. Wu, L. McAfee, C. Zhu, Z. Liu, S. Subramanian, E. Bakhturina, M. Shoeybi, and B. Catanzaro, “Retrieval meets long context large language models,” inThe Twelfth International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[13]
Wikicontradict: A benchmark for evaluating llms on real-world knowledge conflicts from wikipedia,
Y . Hou, A. Pascale, J. Carnerero-Cano, T. Tchrakian, R. Marinescu, E. Daly, I. Padhi, and P. Sattigeri, “Wikicontradict: A benchmark for evaluating llms on real-world knowledge conflicts from wikipedia,” inAdvances in Neural Information Processing Systems (NeurIPS), A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, Eds., 2024
work page 2024
-
[14]
Conflictbank : A benchmark for evaluating the influence of knowledge conflicts in llms,
Z. Su, J. Zhang, X. Qu, T. Zhu, Y . Li, J. Sun, J. Li, M. Zhang, and Y . Cheng, “Conflictbank : A benchmark for evaluating the influence of knowledge conflicts in llms,” inAdvances in Neural Information Processing Systems (NeurIPS), A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, Eds., 2024
work page 2024
-
[15]
Z. Jin, P. Cao, Y . Chen, K. Liu, X. Jiang, J. Xu, L. Qiuxia, and J. Zhao, “Tug-of-war between knowledge: Exploring and resolving knowledge conflicts in retrieval-augmented language models,” inProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), N. Calzo- lari, M.-Y . Ka...
work page 2024
-
[16]
TrueTeacher: Learning factual consistency evaluation with large lan- guage models,
Z. Gekhman, J. Herzig, R. Aharoni, C. Elkind, and I. Szpektor, “TrueTeacher: Learning factual consistency evaluation with large lan- guage models,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), H. Bouamor, J. Pino, and K. Bali, Eds., 2023
work page 2023
-
[17]
E. Neeman, R. Aharoni, O. Honovich, L. Choshen, I. Szpektor, and O. Abend, “DisentQA: Disentangling parametric and contextual knowl- edge with counterfactual question answering,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds., 2023
work page 2023
-
[18]
Trusting your evidence: Hallucinate less with context-aware decoding,
W. Shi, X. Han, M. Lewis, Y . Tsvetkov, L. Zettlemoyer, and W.-t. Yih, “Trusting your evidence: Hallucinate less with context-aware decoding,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), K. Duh, H. Gomez, and S. Bethard, Eds., 2024
work page 2024
-
[19]
E. Harmon-Jones and J. Mills, “Cognitive dissonance,”Progress on a pivotal theory in social psychology. Washington, DC: American Psychological Association, 1999
work page 1999
-
[20]
Self-perception: An alternative interpretation of cognitive dissonance phenomena
D. J. Bem, “Self-perception: An alternative interpretation of cognitive dissonance phenomena.”Psychological review, vol. 74, no. 3, p. 183, 1967
work page 1967
-
[21]
An introduction to cognitive dissonance theory and an overview of current perspectives on the theory
E. Harmon-Jones and J. Mills, “An introduction to cognitive dissonance theory and an overview of current perspectives on the theory.” 2019
work page 2019
-
[22]
Entity-based knowledge conflicts in question answering,
S. Longpre, K. Perisetla, A. Chen, N. Ramesh, C. DuBois, and S. Singh, “Entity-based knowledge conflicts in question answering,” inProceed- ings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), M.-F. Moens, X. Huang, L. Specia, and S. W.-t. Yih, Eds., Online and Punta Cana, Dominican Republic, 2021
work page 2021
-
[23]
Natural questions: A benchmark for question answering research,
T. Kwiatkowski, J. Palomaki, O. Redfield, M. Collins, A. Parikh, C. Alberti, D. Epstein, I. Polosukhin, J. Devlin, K. Lee, K. Toutanova, L. Jones, M. Kelcey, M.-W. Chang, A. M. Dai, J. Uszkoreit, Q. Le, and S. Petrov, “Natural questions: A benchmark for question answering research,”Transactions of the Association for Computational Linguistics, vol. 7, pp....
work page 2019
-
[24]
TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension,
M. Joshi, E. Choi, D. Weld, and L. Zettlemoyer, “TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension,” inProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL), R. Barzilay and M.-Y . Kan, Eds., 2017
work page 2017
-
[25]
SQuAD: 100,000+ questions for machine comprehension of text,
P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang, “SQuAD: 100,000+ questions for machine comprehension of text,” inProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP), J. Su, K. Duh, and X. Carreras, Eds., 2016
work page 2016
-
[26]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosaleet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. d. l. Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnieret al., “Mistral 7b,”arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Knowledge conflicts for LLMs: A survey,
R. Xu, Z. Qi, Z. Guo, C. Wang, H. Wang, Y . Zhang, and W. Xu, “Knowledge conflicts for LLMs: A survey,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (ENMLP), Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds., Nov. 2024
work page 2024
-
[30]
Clasheval: Quantifying the tug-of-war between an llm’s internal prior and external evidence,
K. Wu, E. Wu, and J. Y . Zou, “Clasheval: Quantifying the tug-of-war between an llm’s internal prior and external evidence,” inAdvances in Neural Information Processing Systems (NeurIPS), A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, Eds., 2024
work page 2024
-
[31]
Context-faithful prompting for large language models,
W. Zhou, S. Zhang, H. Poon, and M. Chen, “Context-faithful prompting for large language models,” inFindings of the Association for Compu- tational Linguistics: EMNLP 2023, H. Bouamor, J. Pino, and K. Bali, Eds., 2023
work page 2023
-
[32]
When does in-context learning fall short and why? a study on specification-heavy tasks,
H. Peng, X. Wang, J. Chen, W. Li, Y . Qi, Z. Wang, Z. Wu, K. Zeng, B. Xu, L. Houet al., “When does in-context learning fall short and why? a study on specification-heavy tasks,”arXiv preprint arXiv:2311.08993, 2023
-
[33]
Large language models with controllable working memory,
D. Li, A. S. Rawat, M. Zaheer, X. Wang, M. Lukasik, A. Veit, F. Yu, and S. Kumar, “Large language models with controllable working memory,” inFindings of the Association for Computational Linguistics (ACL), A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds., 2023
work page 2023
-
[34]
B. Xue, W. Wang, H. Wang, F. Mi, R. Wang, Y . Wang, L. Shang, X. Jiang, Q. Liu, and K.-F. Wong, “Improving factual consistency for knowledge-grounded dialogue systems via knowledge enhancement and alignment,” inFindings of the Association for Computational Linguistics: EMNLP 2023, H. Bouamor, J. Pino, and K. Bali, Eds., 2023
work page 2023
-
[35]
Contrastive learning with hard negative samples,
J. D. Robinson, C. Chuang, S. Sra, and S. Jegelka, “Contrastive learning with hard negative samples,” in9th International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[36]
Supervised contrastive learn- ing,
P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y . Tian, P. Isola, A. Maschinot, C. Liu, and D. Krishnan, “Supervised contrastive learn- ing,” inAdvances in Neural Information Processing Systems (NeurIPS), H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., 2020
work page 2020
-
[37]
Contrastive decoding: Open-ended text generation as optimization,
X. L. Li, A. Holtzman, D. Fried, P. Liang, J. Eisner, T. Hashimoto, L. Zettlemoyer, and M. Lewis, “Contrastive decoding: Open-ended text generation as optimization,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds., 2023
work page 2023
-
[38]
Contrastive decoding improves reasoning in large language models,
S. O’Brien and M. Lewis, “Contrastive decoding improves reasoning in large language models,”arXiv preprint arXiv:2309.09117, 2023. 12
-
[39]
X. Yuan, Z. Yang, Y . Wang, S. Liu, J. Zhao, and K. Liu, “Discerning and resolving knowledge conflicts through adaptive decoding with contextual information-entropy constraint,” inFindings of the Association for Com- putational Linguistics (ACL), L.-W. Ku, A. Martins, and V . Srikumar, Eds., 2024
work page 2024
-
[40]
Adacad: Adap- tively decoding to balance conflicts between contextual and parametric knowledge,
H. Wang, A. Prasad, E. Stengel-Eskin, and M. Bansal, “Adacad: Adap- tively decoding to balance conflicts between contextual and parametric knowledge,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL 2025 - Volume 1: Long Papers, Albuquerque, Ne...
work page 2025
-
[41]
Get to the point: Summa- rization with pointer-generator networks,
A. See, P. J. Liu, and C. D. Manning, “Get to the point: Summa- rization with pointer-generator networks,” inProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL), R. Barzilay and M.-Y . Kan, Eds., 2017
work page 2017
-
[42]
S. Narayan, S. B. Cohen, and M. Lapata, “Don‘t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), E. Riloff, D. Chi- ang, J. Hockenmaier, and J. Tsujii, Eds., 2018
work page 2018
-
[43]
Wikidata: a free collaborative knowl- edgebase,
D. Vrande ˇci´c and M. Krötzsch, “Wikidata: a free collaborative knowl- edgebase,”Commun. ACM, vol. 57, no. 10, p. 78–85, 2014
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.