Recognition: no theorem link
Uncertainty Quantification for LLM-based Code Generation
Pith reviewed 2026-05-13 03:54 UTC · model grok-4.3
The pith
LLM-based code generation can produce partial programs as prediction sets guaranteed to contain a correct solution with high confidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
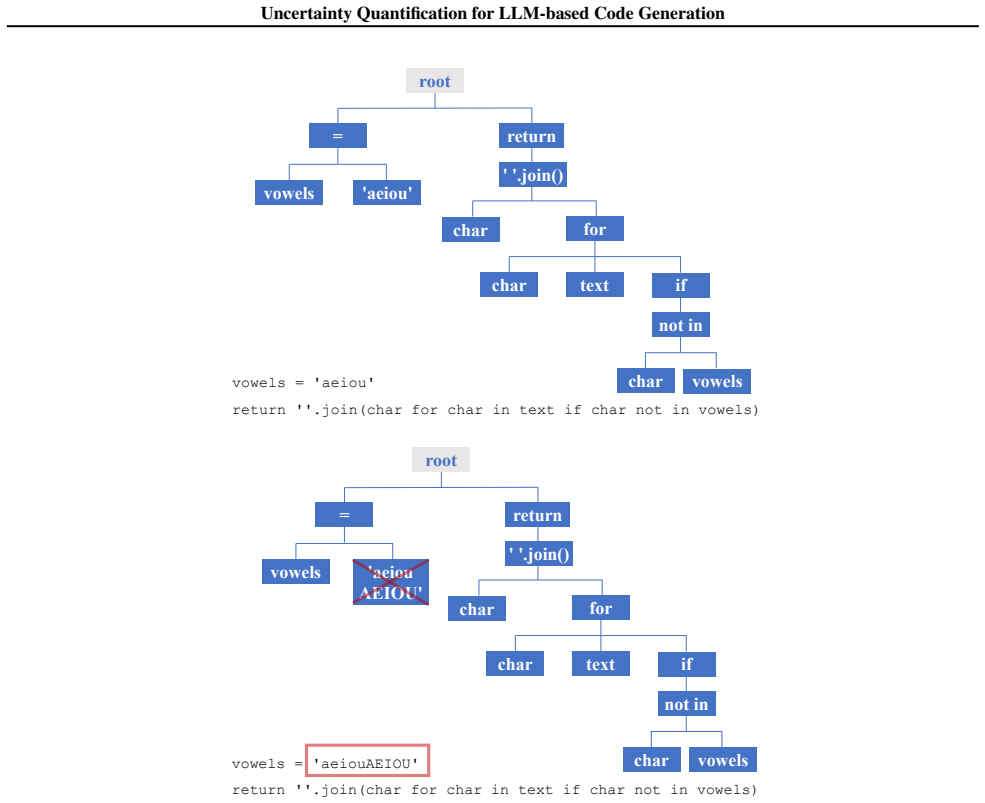
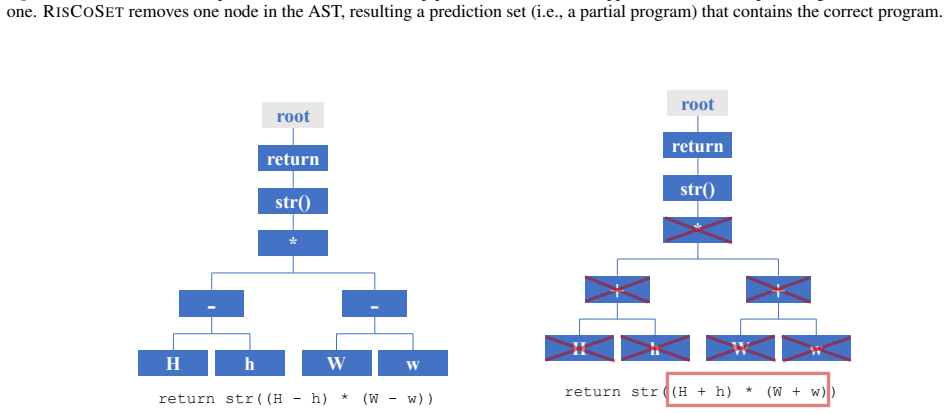
Given a trained code generation model, the method leverages multiple hypothesis testing to construct risk-controlling predictions represented by a partial program that is guaranteed to contain a correct solution with high confidence, addressing the non-monotonic risk and multi-valid-output characteristics of code generation.
What carries the argument
Multiple hypothesis testing applied to construct risk-controlling partial programs as prediction sets for LLM code generation.
If this is right
- The method produces prediction sets without restricting to single outputs or requiring monotonic risk.
- Risk control is achieved for code generation tasks on three different LLMs.
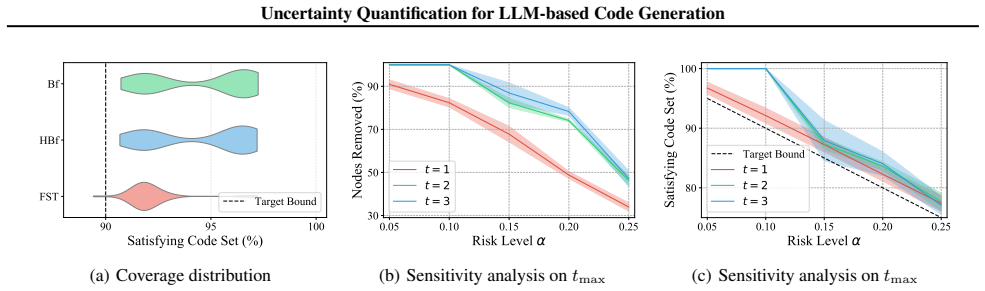
- Compared to state-of-the-art, it reduces code removal by up to 24.5% at the same risk level.
- Prediction sets can be represented compactly as partial programs rather than full candidates.
Where Pith is reading between the lines
- Developers could use the partial programs to focus completion efforts only on the uncertain parts of the code.
- The approach might extend to other structured generation tasks like text or molecule generation if similar risk structures apply.
- Future work could test the method on larger codebases or different risk functions to verify the guarantees hold in practice.
Load-bearing premise
Multiple hypothesis testing can be directly adapted to the non-monotonic risk structure and multi-valid-output nature of code generation without needing extra conditions on the model's output distribution or the risk function.
What would settle it
An evaluation on a held-out set of code generation prompts where the rate at which the produced partial programs exclude all correct solutions exceeds the target risk threshold.
Figures




read the original abstract
Prediction sets provide a theoretically grounded framework for quantifying uncertainty in machine learning models. Adapting them to structured generation tasks, in particular, large language model (LLM) based code generation, remains a challenging problem. An existing attempt proposes PAC prediction sets but is limited by its strong monotonicity assumption on risk and single-label classification framework, which severely limits the space of candidate programs and cannot accommodate the multiple valid outputs inherent to code generation. To address these limitations, we propose an approach RisCoSet that leverages multiple hypothesis testing to construct risk-controlling predictions for LLM-based code generation. Given a trained code generation model, we produce a prediction set represented by a partial program, which is guaranteed to contain a correct solution with high confidence. Extensive experiments on three LLMs demonstrate the effectiveness of the proposed method. For instance, compared with the state-of-the-art, our method can significantly reduce the code removal by up to 24.5%, at the same level of risk.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RisCoSet, which adapts multiple hypothesis testing to construct risk-controlling prediction sets for LLM-based code generation. The sets are represented as partial programs guaranteed to contain at least one correct solution with probability at least 1-α. This relaxes the strong monotonicity assumption and single-valid-output restriction of prior PAC prediction sets. Experiments on three LLMs report up to 24.5% reduction in code removal compared to the state-of-the-art at equivalent risk levels.
Significance. If the coverage guarantee is valid, the work would meaningfully extend conformal-style uncertainty quantification to structured, multi-output generation tasks where monotonicity fails. The empirical reduction in removed code suggests practical value for code-completion tools. However, the absence of a derivation or explicit verification that the risk function satisfies the conditions for valid p-value construction and family-wise error control under dependence and non-monotonicity limits the assessed significance.
major comments (2)
- [Abstract] Abstract: The guarantee that the partial-program prediction set 'is guaranteed to contain a correct solution with high confidence' is asserted via multiple hypothesis testing, yet no derivation, proof sketch, or definition of the risk function (probability that a partial program has no correct completion) is supplied. This is load-bearing for the central claim, as standard multiple-testing theorems require conditions on the risk function and hypothesis dependence that the skeptic note indicates are likely violated by non-monotonic code-generation risk.
- [Experimental Evaluation] Experimental Evaluation: The reported gains (e.g., 24.5% reduction in code removal) are summarized without error bars, full methodology for applying the multiple-testing procedure to code outputs, or details on how p-values are computed from the LLM's output distribution. This prevents assessment of whether the empirical results actually support the claimed risk control.
minor comments (2)
- The abstract refers to 'three LLMs' and 'state-of-the-art' without naming the models, datasets, or baseline methods; adding these in the experiments section would improve reproducibility.
- Notation for the partial-program prediction set and the risk function could be introduced with a small concrete example early in the method description.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. The comments highlight important areas for clarification on the theoretical foundations and experimental reporting. We address each point below and will revise the manuscript accordingly to strengthen the presentation of the risk-control guarantees and empirical methodology.
read point-by-point responses
-
Referee: [Abstract] Abstract: The guarantee that the partial-program prediction set 'is guaranteed to contain a correct solution with high confidence' is asserted via multiple hypothesis testing, yet no derivation, proof sketch, or definition of the risk function (probability that a partial program has no correct completion) is supplied. This is load-bearing for the central claim, as standard multiple-testing theorems require conditions on the risk function and hypothesis dependence that the skeptic note indicates are likely violated by non-monotonic code-generation risk.
Authors: We agree that an explicit definition of the risk function and a derivation of the coverage guarantee are necessary for the central claim. The risk function is defined as the probability that a given partial program admits no correct completion under the data distribution. RisCoSet constructs hypotheses over candidate completions of the partial program and applies a multiple-testing procedure (controlling family-wise error) to ensure that, with probability at least 1-α, the retained partial program has at least one valid completion. While the manuscript states the high-level adaptation, we acknowledge the absence of a self-contained proof sketch addressing dependence and non-monotonicity. In revision we will add a dedicated subsection with the formal definition, the precise hypothesis construction, and a proof outline showing why the standard multiple-testing conditions hold under our partial-program representation (which relaxes monotonicity by design). revision: yes
-
Referee: [Experimental Evaluation] Experimental Evaluation: The reported gains (e.g., 24.5% reduction in code removal) are summarized without error bars, full methodology for applying the multiple-testing procedure to code outputs, or details on how p-values are computed from the LLM's output distribution. This prevents assessment of whether the empirical results actually support the claimed risk control.
Authors: We accept that the experimental section requires additional detail to allow readers to verify the risk-control claims. The 24.5% figure is the maximum observed reduction across the three LLMs and datasets at matched risk levels; however, we did not report variability across random seeds or full implementation steps. In the revision we will: (i) add error bars computed over 5 independent calibration/test splits, (ii) provide a step-by-step description of how the multiple-testing procedure is instantiated on token sequences (including the exact mapping from LLM logits to per-hypothesis p-values), and (iii) include pseudocode for the p-value computation and the partial-program pruning step. These additions will make the empirical support for risk control transparent. revision: yes
Circularity Check
No circularity; derivation adapts established multiple hypothesis testing without self-referential reduction
full rationale
The paper's central construction of RisCoSet uses multiple hypothesis testing to produce risk-controlling partial-program prediction sets. This follows directly from standard theorems on family-wise error control and p-value construction under the stated risk function, without any equation or step reducing the coverage guarantee to a fitted parameter, self-definition, or prior self-citation that itself depends on the target result. No load-bearing ansatz, uniqueness theorem, or renaming of known results is introduced via self-reference. The method is self-contained against external benchmarks in conformal prediction and hypothesis testing literature.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multiple hypothesis testing procedures can control the risk of missing a correct program in structured generation tasks
invented entities (1)
-
RisCoSet
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The Annals of Applied Statistics , volume=
Learn then test: Calibrating predictive algorithms to achieve risk control , author=. The Annals of Applied Statistics , volume=. 2025 , publisher=
work page 2025
-
[2]
International Conference on Machine Learning , pages=
PAC prediction sets for large language models of code , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[3]
Journal of the ACM (JACM) , volume=
Distribution-free, risk-controlling prediction sets , author=. Journal of the ACM (JACM) , volume=. 2021 , publisher=
work page 2021
-
[4]
Journal of the American statistical association , volume=
Probability inequalities for sums of bounded random variables , author=. Journal of the American statistical association , volume=. 1963 , publisher=
work page 1963
-
[5]
On Hoeffding’s inequalities , author=
-
[6]
Statistics in medicine , volume=
Multiple testing in clinical trials , author=. Statistics in medicine , volume=. 1991 , publisher=
work page 1991
-
[7]
Scandinavian journal of statistics , pages=
A simple sequentially rejective multiple test procedure , author=. Scandinavian journal of statistics , pages=. 1979 , publisher=
work page 1979
-
[8]
International Conference on Learning Representations , year=
Pac confidence sets for deep neural networks via calibrated prediction , author=. International Conference on Learning Representations , year=
-
[9]
arXiv preprint arXiv:2506.10908 , year=
Probably Approximately Correct Labels , author=. arXiv preprint arXiv:2506.10908 , year=
-
[10]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Program Synthesis with Large Language Models
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
arXiv preprint arXiv:2207.10397 , year=
Codet: Code generation with generated tests , author=. arXiv preprint arXiv:2207.10397 , year=
-
[13]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
DeepSeek-Coder: When the Large Language Model Meets Programming--The Rise of Code Intelligence , author=. arXiv preprint arXiv:2401.14196 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Qwen2.5-Coder Technical Report
Qwen2. 5-coder technical report , author=. arXiv preprint arXiv:2409.12186 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
arXiv preprint arXiv:2306.08568 , year=
Wizardcoder: Empowering code large language models with evol-instruct , author=. arXiv preprint arXiv:2306.08568 , year=
-
[16]
Proceedings of the American Mathematical Society , volume=
The Lindeberg-Levy theorem for martingales , author=. Proceedings of the American Mathematical Society , volume=
-
[17]
A review of uncertainty quantification in deep learning: Techniques, applications and challenges , author=. Information fusion , volume=. 2021 , publisher=
work page 2021
-
[18]
international conference on machine learning , pages=
Dropout as a bayesian approximation: Representing model uncertainty in deep learning , author=. international conference on machine learning , pages=. 2016 , organization=
work page 2016
-
[19]
International conference on machine learning , pages=
On calibration of modern neural networks , author=. International conference on machine learning , pages=. 2017 , organization=
work page 2017
-
[20]
Advances in neural information processing systems , volume=
Conformalized quantile regression , author=. Advances in neural information processing systems , volume=
-
[21]
Conformal prediction: A gentle introduction , author=. Foundations and Trends. 2023 , publisher=
work page 2023
-
[22]
Journal of the American Statistical Association , volume=
Least ambiguous set-valued classifiers with bounded error levels , author=. Journal of the American Statistical Association , volume=. 2019 , publisher=
work page 2019
-
[23]
The Eleventh International Conference on Learning Representations , year=
Predictive inference with feature conformal prediction , author=. The Eleventh International Conference on Learning Representations , year=
-
[24]
Conformal prediction with large language models for multi-choice question answering
Conformal prediction with large language models for multi-choice question answering , author=. arXiv preprint arXiv:2305.18404 , year=
-
[25]
Calibration of Pre-trained Transformers
Desai, Shrey and Durrett, Greg. Calibration of Pre-trained Transformers. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.21
- [26]
-
[27]
arXiv preprint arXiv:2105.11098 , year=
Prevent the language model from being overconfident in neural machine translation , author=. arXiv preprint arXiv:2105.11098 , year=
-
[28]
arXiv preprint arXiv:2302.07248 , year=
Generation probabilities are not enough: Exploring the effectiveness of uncertainty highlighting in AI-powered code completions , author=. arXiv preprint arXiv:2302.07248 , year=
- [29]
-
[30]
Teaching Models to Express Their Uncertainty in Words , author=. 2022 , eprint=
work page 2022
-
[31]
The 2023 Conference on Empirical Methods in Natural Language Processing , year=
Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback , author=. The 2023 Conference on Empirical Methods in Natural Language Processing , year=
work page 2023
-
[32]
The Twelfth International Conference on Learning Representations , year=
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs , author=. The Twelfth International Conference on Learning Representations , year=
-
[33]
Towards Understanding the Characteristics of Code Generation Errors Made by Large Language Models , author=. 2025 , eprint=
work page 2025
-
[34]
IEEE Transactions on Software Engineering , year=
Look before you leap: An exploratory study of uncertainty analysis for large language models , author=. IEEE Transactions on Software Engineering , year=
-
[35]
A Theoretical Study on Bridging Internal Probability and Self-Consistency for
Zhi Zhou and Yuhao Tan and Zenan Li and Yuan Yao and Lan-Zhe Guo and Yu-Feng Li and Xiaoxing Ma , booktitle=. A Theoretical Study on Bridging Internal Probability and Self-Consistency for. 2025 , url=
work page 2025
-
[36]
Measuring Coding Challenge Competence With APPS
Measuring coding challenge competence with apps , author=. arXiv preprint arXiv:2105.09938 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation , author=. arXiv preprint arXiv:2302.09664 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Relic: Investigating large language model responses using self-consistency , year =
Cheng, Furui and Zouhar, Vil. Relic: Investigating large language model responses using self-consistency , year =. Proceedings of the CHI Conference on Human Factors in Computing Systems , date-added =
-
[39]
Enhancing Self-Consistency and Performance of Pre-Trained Language Models through Natural Language Inference , author=. 2022 , eprint=
work page 2022
-
[40]
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. 2023 , eprint=
work page 2023
- [41]
- [42]
-
[43]
Conformal Prediction with Large Language Models for Multi-Choice Question Answering , author=. 2023 , eprint=
work page 2023
-
[44]
Language Models with Conformal Factuality Guarantees , author=. 2024 , eprint=
work page 2024
-
[45]
Large language model validity via enhanced conformal prediction methods , author=. 2024 , eprint=
work page 2024
-
[46]
Benchmarking LLMs via Uncertainty Quantification , author=. 2024 , eprint=
work page 2024
-
[47]
and Sandler, Corey and Badgett, Tom , biburl =
Myers, Glenford J. and Sandler, Corey and Badgett, Tom , biburl =
-
[48]
Testing and Analysis : Process , Principles , and Techniques , author=. 2000 , url=
work page 2000
-
[49]
Park, Jihyeok and Lee, Hongki and Ryu, Sukyoung , title =. 2021 , issue_date =. doi:10.1145/3464457 , journal =
- [50]
-
[51]
Zhu, Xiaogang and Wen, Sheng and Camtepe, Seyit and Xiang, Yang , title =. 2022 , issue_date =. doi:10.1145/3512345 , journal =
-
[52]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
arXiv preprint arXiv:2404.09785 , year=
Benchmarking llama2, mistral, gemma and gpt for factuality, toxicity, bias and propensity for hallucinations , author=. arXiv preprint arXiv:2404.09785 , year=
-
[56]
arXiv preprint arXiv:2404.00971 , year=
Exploring and evaluating hallucinations in llm-powered code generation , author=. arXiv preprint arXiv:2404.00971 , year=
-
[57]
Journal of Legal Analysis , volume=
Large legal fictions: Profiling legal hallucinations in large language models , author=. Journal of Legal Analysis , volume=. 2024 , publisher=
work page 2024
-
[58]
arXiv preprint arXiv:2208.02814 , year=
Conformal risk control , author=. arXiv preprint arXiv:2208.02814 , year=
-
[59]
Algorithmic learning in a random world , author=. 2005 , publisher=
work page 2005
-
[60]
Advances in Neural Information Processing Systems , volume=
Benchmarking llms via uncertainty quantification , author=. Advances in Neural Information Processing Systems , volume=
-
[61]
Conformal and probabilistic prediction with applications , pages=
A review of nonconformity measures for conformal prediction in regression , author=. Conformal and probabilistic prediction with applications , pages=. 2023 , publisher=
work page 2023
-
[62]
Empirical Software Engineering , volume=
Studying the difference between natural and programming language corpora , author=. Empirical Software Engineering , volume=. 2019 , publisher=
work page 2019
-
[63]
arXiv preprint arXiv:2106.10158 , year=
Learning to complete code with sketches , author=. arXiv preprint arXiv:2106.10158 , year=
-
[64]
Proceedings of the 2018 ACM SIGSAC conference on computer and communications security , pages=
Evaluating fuzz testing , author=. Proceedings of the 2018 ACM SIGSAC conference on computer and communications security , pages=
work page 2018
- [65]
-
[66]
2017 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE) , pages=
Boosting complete-code tool for partial program , author=. 2017 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE) , pages=. 2017 , organization=
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.