Recognition: no theorem link
Heterogeneous SoC Integrating an Open-Source Recurrent SNN Accelerator for Neuromorphic Edge Computing on FPGA
Pith reviewed 2026-05-13 04:19 UTC · model grok-4.3
The pith
Heterogeneous FPGA SoC integrates open-source recurrent SNN accelerator and matches silicon accuracy for neuromorphic edge computing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
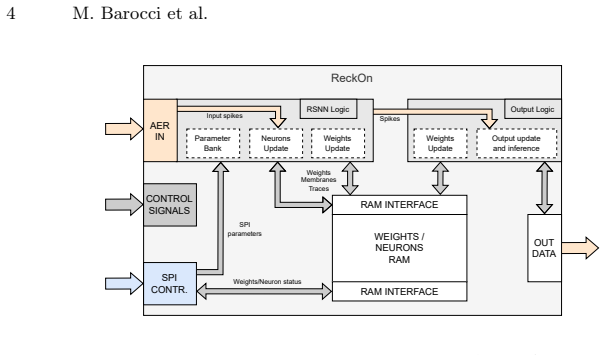
The authors establish that their heterogeneous SoC, which integrates the open-source ReckOn accelerator with the X-HEEP RISC-V microcontroller and Zynq ARM processor, faithfully reproduces the accuracy and characteristics of the original silicon-taped-out ReckOn when implemented on FPGA, while also enabling online learning for neuromorphic tasks like Braille digit recognition.
What carries the argument
The integration of ReckOn accelerator operations managed by traditional processors in a heterogeneous SoC on Zynq Ultrascale FPGA.
If this is right
- The FPGA implementation allows direct comparison of accuracy with the silicon version.
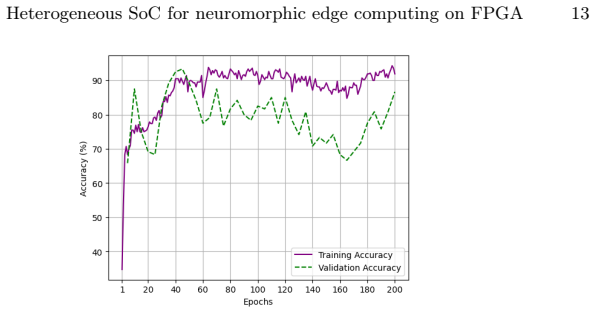
- Online learning capabilities are demonstrated on the Braille digit dataset.
- This setup provides a flexible platform for neuromorphic edge computing without tape-out costs.
- Equivalence in physical characteristics supports reliable prototyping.
Where Pith is reading between the lines
- This validation method could encourage more open-source neuromorphic designs to be tested on FPGAs first.
- The approach might extend to other SNN architectures for broader edge AI applications.
- Potential reduction in development time and cost for neuromorphic systems.
Load-bearing premise
The FPGA implementation of the taped-out ReckOn design accurately mirrors the behavior and metrics of the actual silicon chip without notable discrepancies.
What would settle it
A mismatch in classification accuracy or physical implementation characteristics between the FPGA and silicon versions of ReckOn would disprove the equivalence.
Figures






read the original abstract
The growing popularity of Spiking Neural Networks (SNNs) and their applications has led to a significant fast-paced increase of neuromorphic architectures capable of mimicking the spike-based data processing typical of biological neurons. The efficient power consumption and parallel computing capabilities of the SNNs lead researchers towards the development of digital accelerators, which exploit such features to bring fast and low-power computation on edge devices. The spread of digital neuromorphic hardware however is slowed down by the prohibitive costs that the silicon tape out of circuits brings, that's why targeting Field Programmable Gate Arrays (FPGAs) could represent a viable alternative, offering a flexible and cost-effective platform for implementing digital neuromorphic systems and helping the spread of open-source hardware designs. In this work we present an heterogeneous System-on-Chip (SoC) where the operations of ReckOn, a Recurrent SNN accelerator, are managed through the integration with traditional processors. These include the RISC-V-based, open-source microcontroller X-HEEP and the ARM processor featured in Zynq Ultrascale systems. We validate our design by reproducing the classification results through the implementation on FPGA of the taped-out version of ReckOn in order to check the equivalence of the accuracy and the characteristics in terms of physical implementation. In a second set of experiments, we evaluate the online learning capability of the solution in classifying a subset of the Braille digit dataset recently used to compare neuromorphic frameworks and platforms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a heterogeneous SoC on FPGA integrating the open-source ReckOn recurrent SNN accelerator with the RISC-V X-HEEP microcontroller and the ARM processor on Zynq Ultrascale devices. It claims validation by porting the taped-out ASIC version of ReckOn to FPGA to reproduce classification results and verify equivalence in both accuracy and physical implementation characteristics (power, area, timing). A second experiment demonstrates online learning on a subset of the Braille digit dataset.
Significance. If the core integration and accuracy reproduction hold, the work provides a practical, open-source FPGA platform for recurrent SNN acceleration that lowers barriers to neuromorphic edge computing by avoiding ASIC tape-out costs. The explicit use of standard open-source processors (X-HEEP) and a real-world online-learning task on Braille data adds concrete utility for heterogeneous neuromorphic systems.
major comments (1)
- [Abstract] Abstract: The validation statement asserts that the FPGA port of the taped-out ReckOn 'check[s] the equivalence of the accuracy and the characteristics in terms of physical implementation.' Physical metrics (power, area, critical-path delay) cannot be equivalent between FPGA and ASIC; FPGA LUT/routing overhead systematically inflates dynamic power by 5-20× and alters timing. No scaling models, calibrated post-PAR power estimates, or separate ASIC-vs-FPGA characterization tables are referenced, leaving the physical-equivalence half of the claim unsupported and load-bearing for the stated validation goal.
minor comments (1)
- The abstract and validation description would benefit from explicit numerical metrics (accuracy delta, power numbers, resource utilization) rather than qualitative statements of 'reproducing the classification results.'
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment point-by-point below, agreeing that the abstract wording requires clarification regarding physical implementation metrics.
read point-by-point responses
-
Referee: [Abstract] Abstract: The validation statement asserts that the FPGA port of the taped-out ReckOn 'check[s] the equivalence of the accuracy and the characteristics in terms of physical implementation.' Physical metrics (power, area, critical-path delay) cannot be equivalent between FPGA and ASIC; FPGA LUT/routing overhead systematically inflates dynamic power by 5-20× and alters timing. No scaling models, calibrated post-PAR power estimates, or separate ASIC-vs-FPGA characterization tables are referenced, leaving the physical-equivalence half of the claim unsupported and load-bearing for the stated validation goal.
Authors: We agree with the referee that direct numerical equivalence of physical metrics (power, area, timing) between the FPGA port and the original ASIC is not possible or claimed, due to inherent FPGA overheads in LUTs, routing, and power. The manuscript's intent was to port the taped-out ReckOn design to FPGA to (1) reproduce classification accuracy results as a functional correctness check of the hardware port and (2) report the resulting FPGA-specific physical implementation characteristics (resource utilization, achieved frequency, power on the target device) for the heterogeneous SoC. The abstract wording is imprecise and could be read as implying cross-technology equivalence, which was not our intention and is unsupported. We will revise the abstract to state that we reproduce the accuracy results to validate the port and separately present the FPGA implementation metrics without any equivalence claim to the ASIC. No scaling models or ASIC-FPGA comparison tables exist in the paper because none were performed; the focus remains on the open-source heterogeneous FPGA platform. This change will be incorporated in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical hardware integration and validation only
full rationale
The paper presents a heterogeneous SoC design integrating the existing ReckOn recurrent SNN accelerator with RISC-V and ARM processors on FPGA, followed by empirical validation through FPGA implementation of the taped-out ASIC version to reproduce classification accuracy on datasets like Braille digits. No mathematical derivations, predictions, fitted parameters, ansatzes, or self-citation load-bearing steps are present. The central claim is direct reproduction and measurement, which is self-contained and externally falsifiable via bit-accurate execution and physical metrics on the target platform. No reduction of any result to its own inputs by construction occurs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Barocci, M., Fra, V., Macii, E., Urgese, G.: Review of open neuromorphic archi- tectures and a first integration in the RISC-V PULP platform. In: 2023 IEEE 16th International Symposium on Embedded Multicore/Many-core Systems-on- Chip (MCSoC) (2023)
work page 2023
-
[2]
Na- ture communications13(2022)
Bartolozzi, C., Indiveri, G., Donati, E.: Embodied neuromorphic intelligence. Na- ture communications13(2022)
work page 2022
-
[3]
In: Advances in Neural Information Processing Systems (2018)
Bellec, G., Salaj, D., Subramoney, A., Legenstein, R., Maass, W.: Long short- term memory and learning-to-learn in networks of spiking neurons. In: Advances in Neural Information Processing Systems (2018)
work page 2018
-
[4]
Bellec, G., Scherr, F., Subramoney, A., Hajek, E., Salaj, D., Legenstein, R., Maass, W.: A solution to the learning dilemma for recurrent networks of spiking neu- rons.NatureCommunications11(1), 3625(Jul2020).https://doi.org/10.1038/ s41467-020-17236-y Heterogeneous SoC for neuromorphic edge computing on FPGA 15
-
[5]
In: Embedded Artificial Intelligence
Bos, H., Muir, D.: Sub-mw neuromorphic snn audio processing applications with rockpool and xylo. In: Embedded Artificial Intelligence. River Publishers (2023)
work page 2023
-
[6]
arXiv preprint arXiv:2401.01141 (2024)
Carpegna, A., Savino, A., Carlo, S.D.: Spiker+: a framework for the generation of efficient Spiking Neural Networks FPGA accelerators for inference at the edge. arXiv preprint arXiv:2401.01141 (2024)
-
[7]
Frontiers in Neuro- science9(2016).https://doi.org/10.3389/fnins.2015.00516
Cheung, K., Schultz, S.R., Luk, W.: Neuroflow: A general purpose spiking neural network simulation platform using customizable processors. Frontiers in Neuro- science9(2016).https://doi.org/10.3389/fnins.2015.00516
-
[8]
Clair, J., Eichler, G., Carloni, L.P.: Spikehard: Efficiency-driven neuromorphic hardware for heterogeneous systems-on-chip. ACM Trans. Embed. Comput. Syst. 22(5s) (sep 2023).https://doi.org/10.1145/3609101,https://doi.org/10. 1145/3609101
-
[9]
Davies, M., Srinivasa, N., Lin, T.H., Chinya, G., Cao, Y., Choday, S.H., Dimou, G., Joshi, P., Imam, N., Jain, S., Liao, Y., Lin, C.K., Lines, A., Liu, R., Mathaikutty, D., McCoy, S., Paul, A., Tse, J., Venkataramanan, G., Weng, Y.H., Wild, A., Yang, Y., Wang, H.: Loihi: A Neuromorphic Manycore Processor with On-Chip Learning. IEEE Micro38(2018)
work page 2018
-
[10]
In: 2022 IEEE International Solid-State Circuits Conference (ISSCC)
Frenkel, C., Indiveri, G.: Reckon: A 28nm sub-mm2 task-agnostic spiking recurrent neural network processor enabling on-chip learning over second-long timescales. In: 2022 IEEE International Solid-State Circuits Conference (ISSCC). vol. 65, pp. 1–3 (2022).https://doi.org/10.1109/ISSCC42614.2022.9731734
-
[11]
Frontiers in neuroscience5(2011)
Indiveri, G., Linares-Barranco, B., Hamilton, T.J., Schaik, A.v., Etienne- Cummings, R., Delbruck, T., Liu, S.C., Dudek, P., Häfliger, P., Renaud, S., et al.: Neuromorphic silicon neuron circuits. Frontiers in neuroscience5(2011)
work page 2011
-
[12]
arXiv preprint arXiv:2405.12849 (2024)
Linares-Barranco, A., Prono, L., Lengenstein, R., Indiveri, G., Frenkel, C.: Adap- tive Robotic Arm Control with a Spiking Recurrent Neural Network on a Digital Accelerator. arXiv preprint arXiv:2405.12849 (2024)
-
[13]
Maass, W.: Networks of spiking neurons: The third generation of neural network models. Neural Networks10(1997)
work page 1997
-
[14]
Machetti, S., Schiavone, P.D., Müller, T.C., Peón-Quirós, M., Atienza, D.: X-heep: An open-source, configurable and extendible risc-v microcontroller for the explo- ration of ultra-low-power edge accelerators (2024)
work page 2024
-
[15]
Mack, J., Purdy, R., Rockowitz, K., Inouye, M., Richter, E., Valancius, S., Kumb- hare, N., Hassan, M.S., Fair, K., Mixter, J., Akoglu, A.: Ranc: Reconfigurable ar- chitecture for neuromorphic computing. Trans. Comp.-Aided Des. Integ. Cir. Sys. 40(11), 2265–2278 (nov 2021).https://doi.org/10.1109/TCAD.2020.3038151
-
[16]
Marković, D., Mizrahi, A., Querlioz, D., Grollier, J.: Physics for neuromorphic computing. Nature Reviews Physics2(2020)
work page 2020
-
[17]
arXiv preprint arXiv:1911.02385 (2019)
Mayr, C., Hoeppner, S., Furber, S.: Spinnaker 2: A 10 million core processor system for brain simulation and machine learning. arXiv preprint arXiv:1911.02385 (2019)
-
[18]
Frontiers in Neuroscience16(2022)
Müller-Cleve, S.F., Fra, V., Khacef, L., Pequeño-Zurro, A., Klepatsch, D., Forno, E., Ivanovich, D.G., Rastogi, S., Urgese, G., Zenke, F., Bartolozzi, C.: Braille letter reading: A benchmark for spatio-temporal pattern recognition on neuromorphic hardware. Frontiers in Neuroscience16(2022)
work page 2022
-
[19]
In: IEEE Workshop on Signal Processing Systems (SiPS)
Orchard, G., Frady, E.P., Rubin, D.B.D., Sanborn, S., Shrestha, S.B., Sommer, F.T., Davies, M.: Efficient Neuromorphic Signal Processing with Loihi 2. In: IEEE Workshop on Signal Processing Systems (SiPS). vol. 2021-Octob (2021)
work page 2021
-
[20]
Panchapakesan, S., Fang, Z., Li, J.: Syncnn: Evaluating and accelerating spiking neural networks on fpgas. ACM Trans. Reconfigurable Technol. Syst.15(4) (dec 2022).https://doi.org/10.1145/3514253 16 M. Barocci et al
-
[21]
arXiv preprint arXiv:2311.14641 (2023)
Pedersen, J.E., Abreu, S., Jobst, M., Lenz, G., Fra, V., Bauer, F.C., Muir, D.R., Zhou, P., Vogginger, B., Heckel, K., et al.: Neuromorphic Intermediate Representa- tion: A Unified Instruction Set for Interoperable Brain-Inspired Computing. arXiv preprint arXiv:2311.14641 (2023)
-
[22]
In: 2021 International Conference on Multimedia Analysis and Pattern Recognition (MAPR)
Pham, Q.T., Nguyen, T.Q., Hoang, P.C., Dang, Q.H., Nguyen, D.M., Nguyen, H.H.: A review of snn implementation on fpga. In: 2021 International Conference on Multimedia Analysis and Pattern Recognition (MAPR). pp. 1–6 (2021).https: //doi.org/10.1109/MAPR53640.2021.9585245
-
[23]
Schmidgall, S., Ziaei, R., Achterberg, J., Kirsch, L., Hajiseyedrazi, S., Eshraghian, J.: Brain-inspired learning in artificial neural networks: a review. APL Machine Learning2(2024)
work page 2024
-
[24]
Nature Compu- tational Science2(2022)
Schuman, C.D., Kulkarni, S.R., Parsa, M., Mitchell, J.P., Kay, B., et al.: Oppor- tunities for neuromorphic computing algorithms and applications. Nature Compu- tational Science2(2022)
work page 2022
-
[25]
Siddique, A., Vai, M.I., Pun, S.H.: A low cost neuromorphic learning engine based on a high performance supervised SNN learning algorithm. Scientific Reports13 (2023)
work page 2023
-
[26]
Frontiers in Neuroinformatics16(2022).https://doi.org/10.3389/ fninf.2022.884033
Trensch, G., Morrison, A.: A system-on-chip based hybrid neuromorphic compute node architecture for reproducible hyper-real-time simulations of spiking neural networks. Frontiers in Neuroinformatics16(2022).https://doi.org/10.3389/ fninf.2022.884033
-
[27]
Frontiers in Neuroscience 17, 1197918 (2023)
Urgese, G., Rios-Navarro, A., Linares-Barranco, A., Stewart, T.C., Michmizos, K.: Powering the next-generation iot applications: new tools and emerging technologies for the development of neuromorphic system of systems. Frontiers in Neuroscience 17, 1197918 (2023)
work page 2023
-
[28]
In: 2022 IEEE 4th Interna- tional Conference on Artificial Intelligence Circuits and Systems (AICAS)
Yousefzadeh, A., van Schaik, G.J., Tahghighi, M., Detterer, P., Traferro, S., Hij- dra, M., Stuijt, J., Corradi, F., Sifalakis, M., Konijnenburg, M.: Seneca: Scalable energy-efficient neuromorphic computer architecture. In: 2022 IEEE 4th Interna- tional Conference on Artificial Intelligence Circuits and Systems (AICAS). pp. 371–374 (2022).https://doi.org/...
-
[29]
Zaruba, F., Benini, L.: The cost of application-class processing: Energy and perfor- mance analysis of a linux-ready 1.7-ghz 64-bit risc-v core in 22-nm fdsoi technology. IEEE Transactions on Very Large Scale Integration (VLSI) Systems27(11), 2629– 2640 (Nov 2019).https://doi.org/10.1109/TVLSI.2019.2926114
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.