Recognition: 2 theorem links
· Lean TheoremCombining On-Policy Optimization and Distillation for Long-Context Reasoning in Large Language Models
Pith reviewed 2026-05-13 05:21 UTC · model grok-4.3
The pith
Combining on-policy optimization with distillation stabilizes long-context reasoning in large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
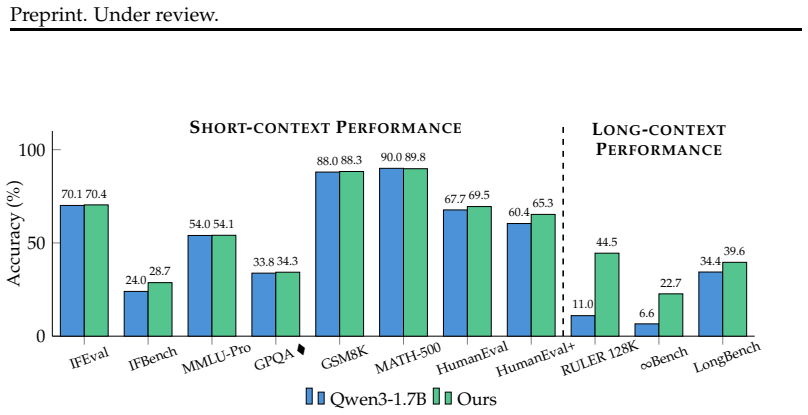
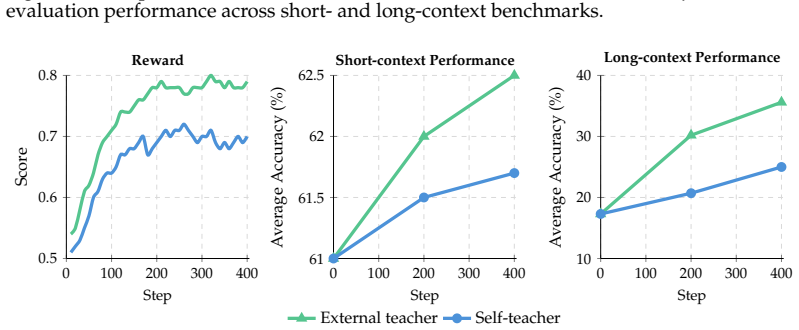
Distilled Group Relative Policy Optimization (dGRPO) augments the GRPO objective with on-policy distillation from a stronger teacher, supplying dense token-level guidance while still optimizing for outcome-based rewards. This single-objective combination leads to more stable training for long-context reasoning tasks compared to off-policy methods or sparse-reward GRPO alone, as shown in ablations on synthetic data covering multi-hop reasoning, contextual grounding, and long-form generation.
What carries the argument
dGRPO, which merges the sparse reward signal of Group Relative Policy Optimization with dense on-policy distillation to correct errors in model-generated states over long sequences.
If this is right
- Training becomes more stable and sample-efficient than standard GRPO because dense signals reduce variance.
- Models maintain short-context performance since the on-policy aspect avoids exposure bias.
- Long-context capabilities improve in areas like multi-hop reasoning and long-form generation.
- The method works with arbitrary reward signals beyond simple outcomes.
Where Pith is reading between the lines
- This approach might allow using smaller teachers if on-policy alignment is efficient.
- It could extend to other domains with long sequences like code generation or dialogue.
- Future work could test if it scales to contexts beyond those in LongBlocks without additional tuning.
- Combining methods this way might generalize to other RL setups plagued by sparse rewards.
Load-bearing premise
That the dense guidance from the teacher will align well with the sparse outcome rewards without introducing new biases or instabilities that undermine the benefits.
What would settle it
Running the same experiments but finding that dGRPO models show higher error rates or lower coherence on long sequences than GRPO-only models, or suffer drops in short-context benchmarks, would falsify the claim of a more stable and effective path.
Figures




read the original abstract
Adapting large language models (LLMs) to long-context tasks requires post-training methods that remain accurate and coherent over thousands of tokens. Existing approaches are limited in several ways: 1) off-policy methods such as supervised fine-tuning (SFT) and knowledge distillation (KD) suffer from exposure bias and limited recovery from model-generated errors over long horizons; 2) on-policy reinforcement learning methods such as Group Relative Policy Optimization (GRPO) better align training with model-generated states, but are unstable and sample-inefficient due to sparse rewards; 3) on-policy distillation (OPD) provides dense token-level guidance, but does not directly optimize arbitrary reward signals. In this paper, we propose Distilled Group Relative Policy Optimization (dGRPO), a method for long-context reasoning that augments GRPO with dense guidance from a stronger teacher via OPD. We also introduce LongBlocks, a synthetic long-context dataset spanning multi-hop reasoning, contextual grounding, and long-form generation. We conduct extensive experiments and ablations comparing off-policy training, sparse-reward GRPO, and our combined approach, leading to an improved recipe for long-context alignment. Overall, our results show that combining outcome-based policy optimization with knowledge distillation in a single objective provides a more stable and effective path to long-context reasoning, while preserving short-context capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Distilled Group Relative Policy Optimization (dGRPO), which augments Group Relative Policy Optimization (GRPO) with on-policy distillation (OPD) from a stronger teacher to create a combined objective for long-context reasoning in LLMs. It introduces the synthetic LongBlocks dataset covering multi-hop reasoning, contextual grounding, and long-form generation tasks, and claims via experiments and ablations that the hybrid approach yields more stable and effective long-context performance than pure GRPO or off-policy KD while preserving short-context capabilities.
Significance. If the results hold under broader validation, the work could supply a practical hybrid recipe for post-training LLMs on long-horizon tasks, addressing exposure bias in off-policy methods and reward sparsity in on-policy RL through dense token-level guidance.
major comments (2)
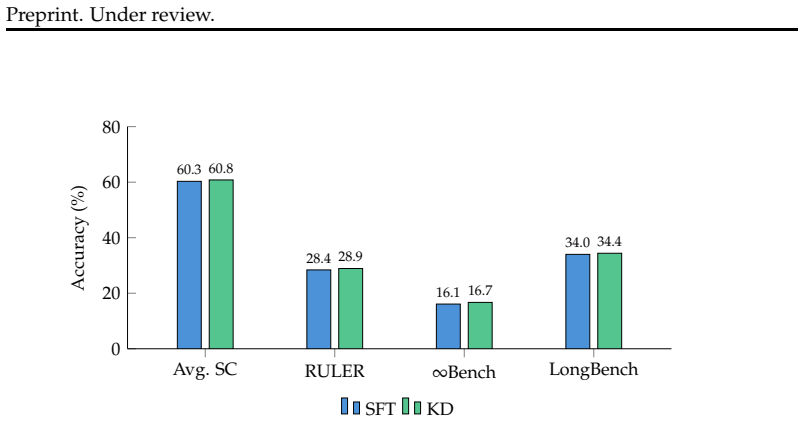
- [Experiments] Experiments section: The central claim that dGRPO provides a more stable and effective path rests on results and ablations using only the synthetic LongBlocks dataset. No evidence is provided that gains transfer to established long-context benchmarks (e.g., LongBench, Needle-in-Haystack, or retrieval-augmented QA), leaving open the possibility that observed improvements are artifacts of the synthetic regime that reward dense teacher signals or group-relative scoring.
- [Method] Method section (dGRPO objective): The approach introduces a balancing hyperparameter between the GRPO and OPD terms. This free parameter must be tuned and is not shown to be robust; the paper does not demonstrate that performance remains stable across reasonable weight values or provide a selection procedure, which undercuts the claim of a reliable combined objective.
minor comments (1)
- [Abstract] Abstract: The description of experiments and the stability claim would be strengthened by including at least one quantitative result (e.g., accuracy delta or stability metric) rather than qualitative statements alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and note the corresponding revisions.
read point-by-point responses
-
Referee: Experiments section: The central claim that dGRPO provides a more stable and effective path rests on results and ablations using only the synthetic LongBlocks dataset. No evidence is provided that gains transfer to established long-context benchmarks (e.g., LongBench, Needle-in-Haystack, or retrieval-augmented QA), leaving open the possibility that observed improvements are artifacts of the synthetic regime that reward dense teacher signals or group-relative scoring.
Authors: We agree that transfer to established benchmarks would strengthen the claims. LongBlocks was introduced to enable controlled evaluation of multi-hop reasoning, contextual grounding, and long-form generation, facilitating precise measurement of stability and error recovery that is challenging on heterogeneous benchmarks. Our ablations isolate the contribution of the hybrid objective in this regime. To address the point, we will add a limitations discussion on generalizability in the revised manuscript and include results on at least one standard benchmark (e.g., a subset of LongBench) where computationally feasible. This is a partial revision. revision: partial
-
Referee: Method section (dGRPO objective): The approach introduces a balancing hyperparameter between the GRPO and OPD terms. This free parameter must be tuned and is not shown to be robust; the paper does not demonstrate that performance remains stable across reasonable weight values or provide a selection procedure, which undercuts the claim of a reliable combined objective.
Authors: We appreciate this observation. In the revised manuscript we will add an ablation varying the balancing hyperparameter over a range of values and demonstrate performance stability. We will also specify a selection procedure based on held-out validation performance. This directly supports the reliability of the combined objective. revision: yes
Circularity Check
No circularity detected in empirical combination of GRPO and OPD
full rationale
The paper proposes dGRPO as an augmentation of existing on-policy RL (GRPO) with on-policy distillation (OPD) and validates the combined objective through experiments and ablations on the introduced LongBlocks synthetic dataset. No load-bearing derivation, equation, or claim reduces by construction to a fitted parameter, self-definition, or self-citation chain. The central result is an empirical finding about stability and effectiveness, externally measured against baselines rather than tautological. The method is presented as a practical recipe without mathematical self-reference.
Axiom & Free-Parameter Ledger
free parameters (1)
- balancing weight between GRPO and OPD terms
invented entities (2)
-
dGRPO objective
no independent evidence
-
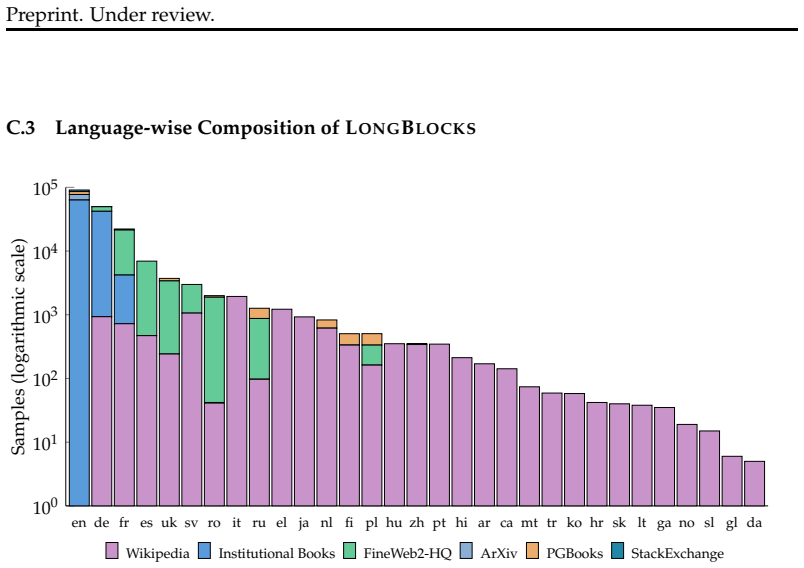
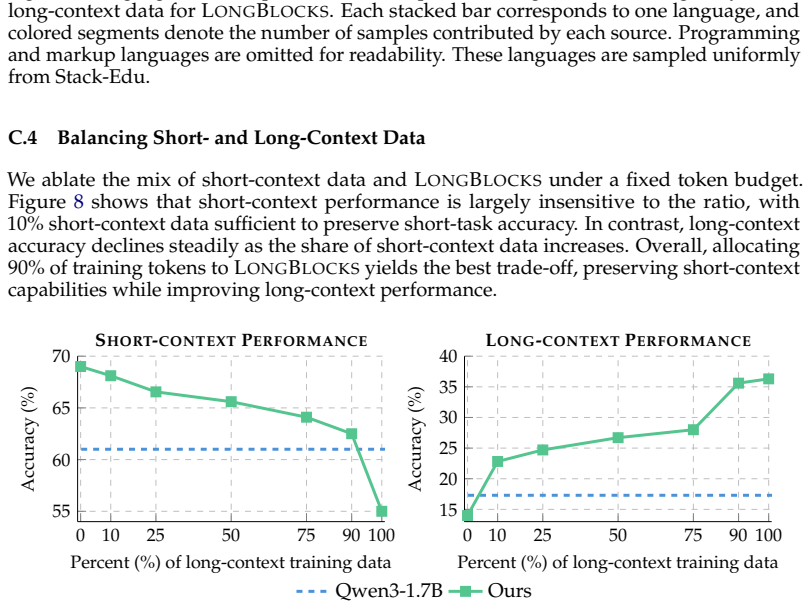
LongBlocks dataset
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe propose Distilled Group Relative Policy Optimization (dGRPO) ... combining outcome-based policy optimization with knowledge distillation in a single objective
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearJdGRPO(θ) = ... min(ρ Â, ρ̄ Â) − β DKL(πθ ∥ πteacher)
Reference graph
Works this paper leans on
-
[1]
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy , year = 2016, month = nov, booktitle =. doi:10.18653/v1/D16-1264 , url =
-
[2]
Joshi, Mandar and Choi, Eunsol and Weld, Daniel and Zettlemoyer, Luke , year = 2017, month = jul, booktitle =. doi:10.18653/v1/P17-1147 , url =
-
[3]
Benchmarking Large Language Models for News Summarization
Benchmarking Large Language Models for News Summarization , author =. Transactions of the Association for Computational Linguistics , publisher =. doi:10.1162/tacl_a_00632 , url =
-
[4]
News summarization and evaluation in the era of gpt-3, 2022
News Summarization and Evaluation in the Era of GPT-3 , author =. 2209.12356 , archiveprefix =
-
[5]
Revisiting the Gold Standard: Grounding Summarization Evaluation with Robust Human Evaluation , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , publisher =. doi:10.18653/v1/2023.acl-long.228 , url =
-
[6]
LaMDA: Language Models for Dialog Applications
LaMDA: Language Models for Dialog Applications , author =. 2201.08239 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
A Complete Survey on LLM-based AI Chatbots , author =. 2406.16937 , archiveprefix =
-
[8]
Recipes for building an open-domain chatbot
Recipes for Building an Open-Domain Chatbot , author =. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , publisher =. doi:10.18653/v1/2021.eacl-main.24 , url =
-
[9]
Qwen2.5-Coder Technical Report
Qwen2.5-Coder Technical Report , author =. 2409.12186 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
doi:10.18653/v1/2025.acl-long.1591 , isbn =
Huang, Siming and Cheng, Tianhao and Liu, Jason Klein and Xu, Weidi and Hao, Jiaran and Song, Liuyihan and Xu, Yang and Yang, Jian and Liu, Jiaheng and Zhang, Chenchen and Chai, Linzheng and Yuan, Ruifeng and Luo, Xianzhen and Wang, Qiufeng and Fan, YuanTao and Zhu, Qingfu and Zhang, Zhaoxiang and Gao, Yang and Fu, Jie and Liu, Qian and Li, Houyi and Zhan...
-
[11]
A Survey of Context Engineering for Large Language Models
A Survey of Context Engineering for Large Language Models , author =. 2507.13334 , archiveprefix =
work page internal anchor Pith review arXiv
-
[12]
Qwen3 Technical Report , author =. 2505.09388 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author =. 2507.06261 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
doi:10.18653/v1/2024.findings-emnlp.74 , url =
Bai, Yushi and Lv, Xin and Zhang, Jiajie and He, Yuze and Qi, Ji and Hou, Lei and Tang, Jie and Dong, Yuxiao and Li, Juanzi , year = 2024, month = nov, booktitle =. doi:10.18653/v1/2024.findings-emnlp.74 , url =
-
[15]
Longlora: Efficient fine-tuning of long-context large language models,
LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models , author =. 2309.12307 , archiveprefix =
-
[16]
doi:10.18653/v1/2025.acl-long.187 , isbn =
Zhang, Jiajie and Hou, Zhongni and Lv, Xin and Cao, Shulin and Hou, Zhenyu and Niu, Yilin and Hou, Lei and Dong, Yuxiao and Feng, Ling and Li, Juanzi , year = 2025, month = jul, booktitle =. doi:10.18653/v1/2025.acl-long.187 , isbn =
-
[17]
Qwenlong-l1: Towards long-context large reasoning models with reinforcement learning, 2025
QwenLong-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning , author =. 2505.17667 , archiveprefix =
-
[18]
LongWriter: Unleashing 10,000+ Word Generation from Long Context LLMs , author =. 2408.07055 , archiveprefix =
-
[19]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author =. 2402.03300 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author =. Thirty-seventh Conference on Neural Information Processing Systems , url =. 2305.18290 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Tulu 3: Pushing Frontiers in Open Language Model Post-Training , author =. 2411.15124 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Hermes 3 Technical Report , author =. 2408.11857 , archiveprefix =
-
[23]
EuroLLM: Multilingual Language Models for Europe , author =. 2409.16235 , archiveprefix =
-
[24]
arXiv preprint arXiv:2508.14444 (2025)
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model , author =. 2508.14444 , archiveprefix =
-
[25]
AIME Problem Set 2024 , author =
work page 2024
-
[26]
AIME Problem Set 2025 , author =
work page 2025
-
[27]
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them , author =
-
[28]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author =. 2110.14168 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Measuring Mathematical Problem Solving With the MATH Dataset , author =
-
[30]
arXiv preprint arXiv:2210.03057 , year=
Language Models are Multilingual Chain-of-Thought Reasoners , author =. The Eleventh International Conference on Learning Representations , url =. 2210.03057 , archiveprefix =
-
[31]
Instruction-Following Evaluation for Large Language Models
Instruction-Following Evaluation for Large Language Models , author =. 2311.07911 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Generalizing verifiable instruction following.arXiv preprint arXiv:2507.02833,
Generalizing Verifiable Instruction Following , author =. 2507.02833 , archiveprefix =
-
[33]
doi:10.48550/arXiv.2502.12404 , keywords =
arXiv e-prints , pages =. doi:10.48550/arXiv.2502.12404 , keywords =
-
[34]
Measuring Massive Multitask Language Understanding
Measuring Massive Multitask Language Understanding , author =. International Conference on Learning Representations , url =. 2009.03300 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[35]
Advances in Neural Information Processing Systems , publisher =
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark , author =. Advances in Neural Information Processing Systems , publisher =
-
[36]
Multilingual Massive Multitask Language Understanding (MMMLU) , author =
-
[37]
Bowman , year = 2024, booktitle =
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , year = 2024, booktitle =
work page 2024
-
[38]
Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code , author =. 2107.03374 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Is Your Code Generated by Chat
Liu, Jiawei and Xia, Chunqiu Steven and Wang, Yuyao and Zhang, Lingming , year = 2023, booktitle =. Is Your Code Generated by Chat
work page 2023
-
[40]
Aya Expanse: Combining Research Breakthroughs for a New Multilingual Frontier , author =. 2412.04261 , archiveprefix =
-
[41]
and Rei, Ricardo and Stigt, Daan van and Coheur, Luisa and Colombo, Pierre and Martins, Andr
Guerreiro, Nuno M. and Rei, Ricardo and Stigt, Daan van and Coheur, Luisa and Colombo, Pierre and Martins, Andr. x. Transactions of the Association for Computational Linguistics , publisher =. doi:10.1162/tacl_a_00683 , url =
-
[42]
The Twelfth International Conference on Learning Representations , url =
Let's Verify Step by Step , author =. The Twelfth International Conference on Learning Representations , url =
-
[43]
Thinking Machines Lab: Connectionism , url =
On-Policy Distillation , author =. Thinking Machines Lab: Connectionism , url =
-
[44]
The Twelfth International Conference on Learning Representations , url =
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes , author =. The Twelfth International Conference on Learning Representations , url =
-
[45]
Neurocomputing , volume = 568, pages = 127063, doi =
RoFormer: Enhanced transformer with Rotary Position Embedding , author =. Neurocomputing , volume = 568, pages = 127063, doi =
-
[46]
Extending Context Window of Large Language Models via Positional Interpolation
Extending Context Window of Large Language Models via Positional Interpolation , author =. 2306.15595 , archiveprefix =
work page internal anchor Pith review arXiv
-
[47]
Bowen Peng and Jeffrey Quesnelle and Honglu Fan and Enrico Shippole , year = 2024, booktitle =. Ya
work page 2024
-
[48]
How to Train Long-Context Language Models (Effectively) , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , publisher =. doi:10.18653/v1/2025.acl-long.366 , isbn =
-
[49]
The Llama 3 Herd of Models , author =. 2407.21783 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
The Thirteenth International Conference on Learning Representations , url =
Jamba: Hybrid Transformer-Mamba Language Models , author =. The Thirteenth International Conference on Learning Representations , url =
-
[51]
KTO: Model Alignment as Prospect Theoretic Optimization
KTO: Model Alignment as Prospect Theoretic Optimization , author =. 2402.01306 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Kingma and Jimmy Ba , year = 2015, booktitle =
Diederik P. Kingma and Jimmy Ba , year = 2015, booktitle =. Adam:
work page 2015
-
[53]
Advances in Neural Information Processing Systems , publisher =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems , publisher =
-
[54]
Journal of Machine Learning Research , volume = 21, number = 140, pages =
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer , author =. Journal of Machine Learning Research , volume = 21, number = 140, pages =
-
[55]
Proximal Policy Optimization Algorithms
Proximal Policy Optimization Algorithms , author =. 1707.06347 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Second Conference on Language Modeling , url =
Understanding R1-Zero-Like Training: A Critical Perspective , author =. Second Conference on Language Modeling , url =
-
[57]
Distilling the Knowledge in a Neural Network
Distilling the Knowledge in a Neural Network , author =. 1503.02531 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Equivalence between policy gradients and soft Q-learning
Equivalence Between Policy Gradients and Soft Q-Learning , author =. 1704.06440 , archiveprefix =
-
[59]
Qiying Yu and Zheng Zhang and Ruofei Zhu and Yufeng Yuan and Xiaochen Zuo and YuYue and Weinan Dai and Tiantian Fan and Gaohong Liu and Juncai Liu and LingJun Liu and Xin Liu and Haibin Lin and Zhiqi Lin and Bole Ma and Guangming Sheng and Yuxuan Tong and Chi Zhang and Mofan Zhang and Ru Zhang and Wang Zhang and Hang Zhu and Jinhua Zhu and Jiaze Chen and ...
work page 2025
-
[60]
Cheng-Ping Hsieh and Simeng Sun and Samuel Kriman and Shantanu Acharya and Dima Rekesh and Fei Jia and Boris Ginsburg , year = 2024, booktitle =
work page 2024
-
[61]
Bai, Yushi and Lv, Xin and Zhang, Jiajie and Lyu, Hongchang and Tang, Jiankai and Huang, Zhidian and Du, Zhengxiao and Liu, Xiao and Zeng, Aohan and Hou, Lei and Dong, Yuxiao and Tang, Jie and Li, Juanzi , year = 2024, month = aug, booktitle =. doi:10.18653/v1/2024.acl-long.172 , url =
-
[62]
Gregory Kamradt , year = 2023, journal =
work page 2023
-
[63]
On the Use of ArXiv as a Dataset , author =. 1905.00075 , archiveprefix =
-
[64]
Wikimedia Downloads , author =
-
[65]
Project Gutenberg , author =
-
[66]
Nikhil Kandpal and Brian Lester and Colin Raffel and Sebastian Majstorovic and Stella Biderman and Baber Abbasi and Luca Soldaini and Enrico Shippole and A. Feder Cooper and Aviya Skowron and Shayne Longpre and Lintang Sutawika and Alon Albalak and Zhenlin Xu and Guilherme Penedo and Loubna Ben allal and Elie Bakouch and John David Pressman and Honglu Fan...
work page 2025
-
[67]
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model , author =. 2502.02737 , archiveprefix =
work page internal anchor Pith review arXiv
-
[68]
Enhancing Multilingual LLM Pretraining with Model-Based Data Selection , author =. arXiv , url =
-
[69]
Institutional Books 1.0: A 242B token dataset from Harvard Library's collections, refined for accuracy and usability , author =. 2506.08300 , archiveprefix =
-
[70]
Advances in Neural Information Processing Systems , publisher =
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author =. Advances in Neural Information Processing Systems , publisher =
-
[71]
Multi-hop Reading Comprehension through Question Decomposition and Rescoring , author =. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , publisher =. doi:10.18653/v1/P19-1613 , url =
-
[72]
Chen, Danqi and Fisch, Adam and Weston, Jason and Bordes, Antoine , year = 2017, month = jul, booktitle =. Reading. doi:10.18653/v1/P17-1171 , url =
-
[73]
Second Conference on Language Modeling , url =
One ruler to measure them all: Benchmarking multilingual long-context language models , author =. Second Conference on Language Modeling , url =. 2503.01996 , archiveprefix =
-
[74]
Wang, Longyue and Tu, Zhaopeng and Gu, Yan and Liu, Siyou and Yu, Dian and Ma, Qingsong and Lyu, Chenyang and Zhou, Liting and Liu, Chao-Hong and Ma, Yufeng and Chen, Weiyu and Graham, Yvette and Webber, Bonnie and Koehn, Philipp and Way, Andy and Yuan, Yulin and Shi, Shuming , year = 2023, month = dec, booktitle =. Findings of the. doi:10.18653/v1/2023.w...
-
[75]
Rei, Ricardo and C. de Souza, Jos. Proceedings of the Seventh Conference on Machine Translation (WMT) , publisher =
-
[76]
Embarrassingly Easy Document-Level
Vernikos, Giorgos and Thompson, Brian and Mathur, Prashant and Federico, Marcello , year = 2022, month = dec, booktitle =. Embarrassingly Easy Document-Level
work page 2022
-
[77]
doi:10.18653/v1/2024.naacl-short.18 , url =
Raunak, Vikas and Kocmi, Tom and Post, Matt , year = 2024, month = jun, booktitle =. doi:10.18653/v1/2024.naacl-short.18 , url =
-
[78]
Kocmi, Tom and Artemova, Ekaterina and Avramidis, Eleftherios and Bawden, Rachel and Bojar, Ond. Findings of the. Proceedings of the Tenth Conference on Machine Translation , publisher =. doi:10.18653/v1/2025.wmt-1.22 , isbn =
-
[79]
Olmo 3 , author =. 2512.13961 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
K2-V2: A 360-Open, Reasoning-Enhanced LLM , author =. 2512.06201 , archiveprefix =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.