Recognition: 2 theorem links
· Lean TheoremMorphologically Equivariant Flow Matching for Bimanual Mobile Manipulation
Pith reviewed 2026-05-13 04:24 UTC · model grok-4.3
The pith
Bimanual robot policies that respect left-right morphological symmetry learn faster and generalize to mirrored tasks without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
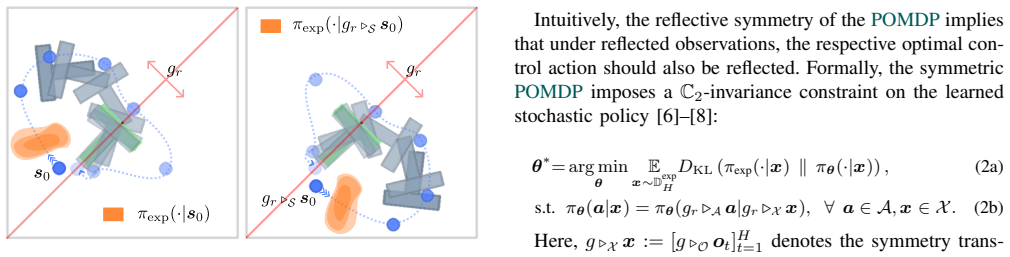
We formalize that morphological symmetry forces optimal bimanual policies to be ambidextrous and equivariant under reflections across the sagittal plane. We introduce a reflection-equivariant flow matching policy that enforces this symmetry either through a regularized training loss or an equivariant velocity network. The symmetry-aware policies achieve higher sample efficiency and zero-shot generalization to mirrored task configurations that are absent from the training distribution, with validation on both simulation benchmarks and a real robot.
What carries the argument
The reflection-equivariant flow matching policy, which enforces left-right symmetry in the generated actions either by penalizing asymmetry during training or by making the velocity network itself respect the reflection.
If this is right
- Symmetry-informed policies require fewer demonstrations to reach competent performance on planar and 6-DoF mobile manipulation tasks.
- The learned policies succeed on mirrored task versions that were never shown in training, without any additional data or fine-tuning.
- The same symmetry prior works for both simulation environments and transfer to a physical bimanual mobile robot.
- Enforcing the symmetry can be done flexibly either by a training-time penalty or by an architectural change to the velocity network.
Where Pith is reading between the lines
- The same morphological prior could be combined with other robot-specific constraints such as joint limits or contact geometry to further reduce data requirements.
- When a task truly demands asymmetric behavior, the regularization version of the method allows the policy to relax the symmetry constraint during training.
- The zero-shot mirror generalization suggests that data collection for bimanual robots can focus on one side of the workspace and still cover the full task space.
Load-bearing premise
That the optimal policy for a bimanual task is always symmetric, so that the behavior on one side fully determines the correct behavior on the mirror-image side.
What would settle it
A task where an unconstrained policy outperforms the symmetry-enforced version because the required left and right arm actions cannot be mirrors of each other.
Figures



read the original abstract
Mobile manipulation requires coordinated control of high-dimensional, bimanual robots. Imitation learning methods have been broadly used to solve these robotic tasks, yet typically ignore the bilateral morphological symmetry inherent in such systems. We argue that morphological symmetry is an underexplored but crucial inductive bias for learning in bimanual mobile manipulation: knowing how to solve a task in one configuration directly determines how to solve its mirrored counterpart. In this paper, we formalize this symmetry prior and show that it constrains optimal bimanual policies to be ambidextrous and equivariant under reflections across the robot's sagittal plane. We introduce a $\mathbb{C}_2$-equivariant flow matching policy that enforces reflective symmetry either via a regularized training loss or an equivariant velocity network. Across planar and 6-DoF mobile manipulation tasks, symmetry-informed policies consistently improve sample efficiency and achieve zero-shot generalization to mirrored configurations absent from the training distribution. We further validate this zero-shot generalization capability on a real-world manipulation task with a TIAGo++ robot. Together, our findings establish morphological symmetry as an effective, generalizable, and scalable inductive bias for ambidextrous generative policy learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that morphological bilateral symmetry is a key inductive bias for bimanual mobile manipulation. It formalizes that optimal policies must be ambidextrous and C2-equivariant under sagittal-plane reflection, then introduces a flow-matching policy that enforces this symmetry either via a regularized loss or an explicitly equivariant velocity network. Experiments on planar and 6-DoF simulated tasks report improved sample efficiency and zero-shot generalization to mirrored configurations; the approach is further validated on a real TIAGo++ robot.
Significance. If the empirical claims hold, the work supplies a principled, morphology-derived prior that reduces data needs and enables mirror generalization without additional training. The explicit construction from first principles of robot symmetry (rather than learned or post-hoc) is a clear strength, as is the real-robot demonstration. The result could influence policy architectures for any bilaterally symmetric platform, provided the symmetry assumption is respected by the task.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the central claim that symmetry-informed policies 'consistently improve sample efficiency' and achieve zero-shot mirror generalization rests on the assumption that optimal policies are always C2-equivariant. No experiments or ablations are reported on tasks containing asymmetric elements (one-sided goals, obstacles, or base asymmetries), where the enforced equivariance could shrink the representable policy class and degrade performance on the original distribution. This assumption is load-bearing for the 'consistent improvement' statement.
- [Abstract] Abstract: reports 'consistent improvements' and 'real-robot validation' yet supplies no quantitative metrics, baseline comparisons, statistical significance tests, or implementation details (network sizes, training budgets, number of trials). Without these, the strength of support for the sample-efficiency and generalization claims cannot be assessed and remains only moderately established.
minor comments (1)
- [Method] The notation for the C2 group action and the precise definition of the sagittal reflection operator should be stated explicitly in the method section with a diagram for readers unfamiliar with group-equivariant learning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications on the scope of our claims and proposed revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central claim that symmetry-informed policies 'consistently improve sample efficiency' and achieve zero-shot mirror generalization rests on the assumption that optimal policies are always C2-equivariant. No experiments or ablations are reported on tasks containing asymmetric elements (one-sided goals, obstacles, or base asymmetries), where the enforced equivariance could shrink the representable policy class and degrade performance on the original distribution. This assumption is load-bearing for the 'consistent improvement' statement.
Authors: Our formalization in Section 3 derives C2-equivariance specifically for tasks respecting bilateral morphological symmetry, which is the setting of bimanual mobile manipulation addressed in the paper. All reported experiments use planar and 6-DoF tasks with symmetric configurations, where the inductive bias yields the observed gains in sample efficiency and zero-shot mirror generalization. We agree that the current experiments do not cover asymmetric cases and that enforcing equivariance could be detrimental there; the regularized-loss variant of our method already permits relaxing the constraint. In revision we will add an explicit discussion of the symmetry assumption's scope and an ablation on a task variant with asymmetric elements to demonstrate the trade-off. revision: yes
-
Referee: [Abstract] Abstract: reports 'consistent improvements' and 'real-robot validation' yet supplies no quantitative metrics, baseline comparisons, statistical significance tests, or implementation details (network sizes, training budgets, number of trials). Without these, the strength of support for the sample-efficiency and generalization claims cannot be assessed and remains only moderately established.
Authors: The abstract is written as a high-level summary; all quantitative metrics, baseline comparisons, statistical tests, network architectures, training budgets, and trial counts appear in the Experiments section and associated tables. To improve accessibility, we will revise the abstract to include concise quantitative highlights (e.g., sample-efficiency gains and zero-shot success rates) while retaining its brevity. revision: yes
Circularity Check
No significant circularity; symmetry prior derived from morphology and enforced explicitly
full rationale
The paper starts from the observable bilateral symmetry of bimanual robots and formalizes a C2-equivariance constraint on optimal policies under sagittal reflection. It then implements this constraint either through a regularized training loss or by constructing an equivariant velocity network inside the flow-matching model. Neither step reduces to a fitted parameter renamed as a prediction, nor to a self-citation chain; the equivariance is an externally motivated inductive bias that is applied to the policy class and validated empirically on both simulated and real tasks. The derivation chain therefore remains self-contained against external benchmarks and does not collapse by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Optimal bimanual policies are ambidextrous and equivariant under reflections across the robot's sagittal plane.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a C2-equivariant flow matching policy that enforces reflective symmetry either via a regularized training loss or an equivariant velocity network.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
symmetry-informed policies consistently improve sample efficiency and achieve zero-shot generalization to mirrored configurations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” in Proceedings of Robotics: Science and Systems (RSS), 2023
work page 2023
-
[2]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,”arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsuet al., “Rt-1: Robotics transformer for real-world control at scale,”arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichteret al., “π 0: A vision- language-action flow model for general robot control,”arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Morphological symmetries in robotics,
D. Ordo ˜nez-Apraez, G. Turrisi, V . Kostic, M. Martin, A. Agudo, F. Moreno-Noguer, M. Pontil, C. Semini, and C. Mastalli, “Morphological symmetries in robotics,”The International Journal of Robotics Research, vol. 44, no. 10-11, p. 02783649241282422, 2025. [Online]. Available: https://doi.org/10.1177/02783649241282422
-
[6]
Morphologically symmetric reinforcement learning for ambidextrous bimanual manipulation,
Z. Li, Y . Jin, D. O. Apraez, C. Semini, P. Liu, and G. Chalvatzaki, “Morphologically symmetric reinforcement learning for ambidextrous bimanual manipulation,”arXiv preprint arXiv:2505.05287, 2025
-
[7]
M. Zinkevich and T. R. Balch, “Symmetry in markov decision pro- cesses and its implications for single agent and multiagent learning,” inProceedings of the Eighteenth International Conference on Machine Learning, ser. ICML ’01. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 2001, p. 632
work page 2001
-
[8]
Edgi: Equivariant diffusion for planning with embodied agents,
J. Brehmer, J. Bose, P. De Haan, and T. S. Cohen, “Edgi: Equivariant diffusion for planning with embodied agents,”Advances in Neural Information Processing Systems, vol. 36, pp. 63 818–63 834, 2023
work page 2023
-
[9]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Equivariant flows: exact likelihood generative learning for symmetric densities,
J. K ¨ohler, L. Klein, and F. No ´e, “Equivariant flows: exact likelihood generative learning for symmetric densities,” inInternational confer- ence on machine learning. PMLR, 2020, pp. 5361–5370
work page 2020
-
[11]
L. Klein, A. Kr ¨amer, and F. No ´e, “Equivariant flow matching,” Advances in Neural Information Processing Systems, vol. 36, pp. 59 886–59 910, 2023
work page 2023
-
[12]
On flow matching kl divergence,
M. Su, J. Y .-C. Hu, S. Pi, and H. Liu, “On flow matching kl divergence,”arXiv preprint arXiv:2511.05480, 2025
-
[13]
Symmetry-based represen- tations for artificial and biological general intelligence,
I. Higgins, S. Racani `ere, and D. Rezende, “Symmetry-based represen- tations for artificial and biological general intelligence,”Frontiers in Computational Neuroscience, vol. 16, p. 836498, 2022
work page 2022
-
[14]
Equibim: Learning symmetry-equivariant policy for bimanual ma- nipulation,
Z. Zhang, A. Mohan, S. Han, W. Shou, D. Wang, and Y . She, “Equibim: Learning symmetry-equivariant policy for bimanual ma- nipulation,”arXiv preprint arXiv:2603.08541, 2026
-
[15]
Mink: Python inverse kinematics based on MuJoCo,
K. Zakka, “Mink: Python inverse kinematics based on MuJoCo,” May 2025. [Online]. Available: https://github.com/kevinzakka/mink
work page 2025
-
[16]
Implementing torque control with high-ratio gear boxes and without joint-torque sensors,
A. Del Prete, N. Mansard, O. E. Ramos, O. Stasse, and F. Nori, “Implementing torque control with high-ratio gear boxes and without joint-torque sensors,” inInt. Journal of Humanoid Robotics, 2016, p. 1550044. [Online]. Available: https://hal.archives-ouvertes. fr/hal-01136936/document
work page 2016
-
[17]
Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation,
Z. Fu, T. Z. Zhao, and C. Finn, “Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation,” in Conference on Robot Learning (CoRL), 2024
work page 2024
-
[18]
Mobi-π: Mobilizing your robot learning policy,
J. Yang, I. Huang, B. Vu, M. Bajracharya, R. Antonova, and J. Bohg, “Mobi-π: Mobilizing your robot learning policy,”arXiv preprint arXiv:2505.23692, 2025
-
[19]
N. M. M. Shafiullah, A. Rai, H. Etukuru, Y . Liu, I. Misra, S. Chin- tala, and L. Pinto, “On bringing robots home,”arXiv preprint arXiv:2311.16098, 2023
-
[20]
Homer: Learn- ing in-the-wild mobile manipulation via hybrid imitation and whole- body control,
P. Sundaresan, R. Malhotra, P. Miao, J. Yang, J. Wu, H. Hu, R. Antonova, F. Engelmann, D. Sadigh, and J. Bohg, “Homer: Learn- ing in-the-wild mobile manipulation via hybrid imitation and whole- body control,”arXiv preprint arXiv:2506.01185, 2025
-
[21]
Safemimic: Towards safe and autonomous human-to-robot imitation for mobile manipulation,
A. Bahety, A. Balaji, B. Abbatematteo, and R. Mart ´ın-Mart´ın, “Safemimic: Towards safe and autonomous human-to-robot imitation for mobile manipulation,”arXiv preprint arXiv:2506.15847, 2025
-
[22]
D. Wang, S. Hart, D. Surovik, T. Kelestemur, H. Huang, H. Zhao, M. Yeatman, J. Wang, R. Walters, and R. Platt, “Equivariant diffusion policy,” in8th Annual Conference on Robot Learning, 2024. [Online]. Available: https://openreview.net/forum?id=wD2kUVLT1g
work page 2024
-
[23]
A practical guide for incorporating symmetry in diffusion policy,
D. Wang, B. Hu, S. Song, R. Walters, and R. Platt, “A practical guide for incorporating symmetry in diffusion policy,”arXiv preprint arXiv:2505.13431, 2025
-
[24]
Et-seed: Efficient trajectory-level se(3) equivariant diffusion policy,
C. Tie, Y . Chen, R. Wu, B. Dong, Z. Li, C. Gao, and H. Dong, “Et-seed: Efficient trajectory-level se(3) equivariant diffusion policy,”
-
[25]
Available: https://arxiv.org/abs/2411.03990
[Online]. Available: https://arxiv.org/abs/2411.03990
-
[26]
Equibot: Sim(3)-equivariant diffusion policy for generalizable and data efficient learning,
J. Yang, Z.-a. Cao, C. Deng, R. Antonova, S. Song, and J. Bohg, “Equibot: Sim(3)-equivariant diffusion policy for generalizable and data efficient learning,” in8th Annual Conference on Robot Learning, 2024
work page 2024
-
[27]
Equivact: Sim(3)-equivariant visuomotor policies beyond rigid object manipulation,
J. Yang, C. Deng, J. Wu, R. Antonova, L. Guibas, and J. Bohg, “Equivact: Sim(3)-equivariant visuomotor policies beyond rigid object manipulation,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 9249–9255
work page 2024
-
[28]
Guaranteed se(3)-equivariant control via hand-centric behavior cloning,
J. Jankowski, P. Klink, I. Posner, E. Gundogdu, K. Park, and C. Erdogan, “Guaranteed se(3)-equivariant control via hand-centric behavior cloning,” 2025. [Online]. Available: https://corl25-genpriors. github.io/Papers/15 Guaranteed SE 3 Equivariant.pdf
work page 2025
-
[29]
Seil: Simulation-augmented equivariant imitation learning,
M. Jia, D. Wang, G. Su, D. Klee, X. Zhu, R. Walters, and R. Platt, “Seil: Simulation-augmented equivariant imitation learning,”arXiv preprint arXiv:2211.00194, 2022
-
[30]
Actionflow: Equivariant, accurate, and efficient policies with spatially symmetric flow matching,
N. Funk, J. Urain, J. Carvalho, V . Prasad, G. Chalvatzaki, and J. Peters, “Actionflow: Equivariant, accurate, and efficient policies with spatially symmetric flow matching,”arXiv preprint arXiv:2409.04576, 2024
-
[31]
Efficientflow: Efficient equiv- ariant flow policy learning for embodied ai,
J. Chang, R. Mei, W. Ke, and X. Xu, “Efficientflow: Efficient equiv- ariant flow policy learning for embodied ai,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 24, 2026, pp. 19 496–19 504
work page 2026
-
[32]
Symme- try considerations for learning task symmetric robot policies,
M. Mittal, N. Rudin, V . Klemm, A. Allshire, and M. Hutter, “Symme- try considerations for learning task symmetric robot policies,”arXiv preprint arXiv:2403.04359, 2024
-
[33]
On learning symmetric locomotion,
F. Abdolhosseini, H. Y . Ling, Z. Xie, X. B. Peng, and M. van de Panne, “On learning symmetric locomotion,” inMotion, Interaction and Games, ser. MIG ’19. New York, NY , USA: Association for Computing Machinery, 2019. [Online]. Available: https://doi.org/10. 1145/3359566.3360070
-
[34]
Leveraging symmetry in rl- based legged locomotion control,
Z. Su, X. Huang, D. Ordo ˜nez-Apraez, Y . Li, Z. Li, Q. Liao, G. Turrisi, M. Pontil, C. Semini, Y . Wuet al., “Leveraging symmetry in rl- based legged locomotion control,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 6899–6906
work page 2024
-
[35]
Ms- ppo: Morphological-symmetry-equivariant policy for legged robot locomotion,
S. Wei, X. Chen, F. Xie, G. E. Katz, Z. Gan, and L. Gan, “Ms- ppo: Morphological-symmetry-equivariant policy for legged robot locomotion,”arXiv preprint arXiv:2512.00727, 2025
-
[36]
F. Xie, S. Wei, Y . Song, Y . Yue, and L. Gan, “Morphological- symmetry-equivariant heterogeneous graph neural network for robotic dynamics learning,”arXiv preprint arXiv:2412.01297, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.