Recognition: 2 theorem links
· Lean TheoremPRISM: Pareto-Efficient Retrieval over Intent-Aware Structured Memory for Long-Horizon Agents
Pith reviewed 2026-05-13 05:04 UTC · model grok-4.3
The pith
PRISM retrieves evidence from graph-structured memory via intent-aware min-cost path selection and compression, achieving higher accuracy than baselines at an order-of-magnitude smaller context budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
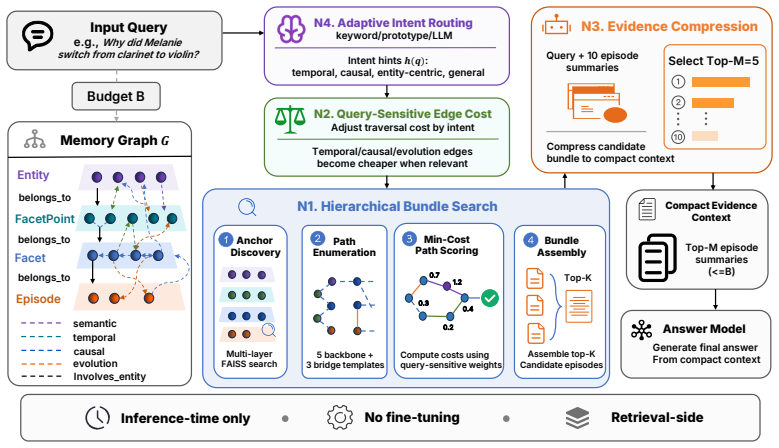
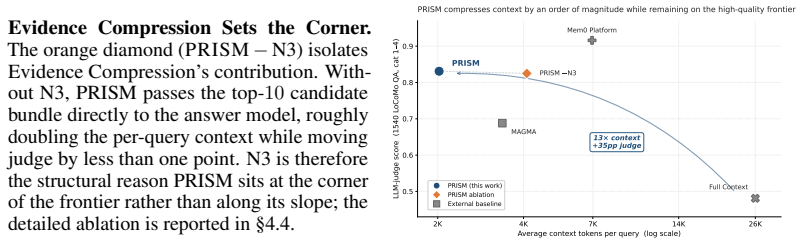
The paper claims that formulating retrieval as min-cost selection over typed path templates, combined with hierarchical bundle search, query-sensitive edge costing, evidence compression, and adaptive intent routing, surfaces the right evidence under a strict context budget and produces substantially higher LLM-judge accuracy on the LoCoMo benchmark than every same-protocol baseline while using an order-of-magnitude smaller context.
What carries the argument
Min-cost selection over typed relation path templates paired with query-sensitive edge costing in a graph-structured memory.
If this is right
- Long-horizon agents can sustain extended interactions at lower per-query token cost while preserving or improving answer quality.
- Most queries can be routed through zero-LLM tiers, reducing overall LLM calls during memory access.
- Evidence can be compressed after retrieval without loss of answer-critical information under the same budget.
- Retrieval accuracy improves by aligning graph traversal costs directly to the detected intent of the current query.
Where Pith is reading between the lines
- The same min-cost path formulation could be applied to other structured memories such as knowledge graphs or episode logs in robotic agents.
- If intent detection remains reliable across domains, the framework reduces the incentive to fine-tune retrieval modules for each new agent deployment.
- Compression after selection suggests a general separation between retrieval precision and context packing that other memory systems might adopt.
- Adaptive routing implies that the fraction of queries needing full LLM involvement can be measured and optimized independently of the core search logic.
Load-bearing premise
The upstream ingestion pipeline supplies a clean graph with typed relations and query intent can be detected reliably enough to guide edge costing without training or fine-tuning.
What would settle it
On the LoCoMo benchmark, PRISM fails to exceed the LLM-judge accuracy of same-protocol baselines when restricted to one-tenth the context budget used by those baselines, or intent detection produces edge costs that do not improve retrieval precision.
Figures


read the original abstract
Long-horizon language agents accumulate conversation history far faster than any fixed context window can hold, making memory management critical to both answer accuracy and serving cost. Existing approaches either expand the context window without addressing what is retrieved, perform heavy ingestion-time fact extraction at substantial token cost, or rely on heuristic graph traversal that leaves both accuracy and efficiency on the table. We present PRISM, a training-free retrieval-side framework that treats long-horizon memory as a joint retrieval-and-compression problem over a graph-structured memory. PRISM combines four orthogonal inference-time components: Hierarchical Bundle Search over typed relation paths, Query-Sensitive Edge Costing that aligns traversal with detected query intent, Evidence Compression that compresses the candidate bundle into a compact answer-side context, and Adaptive Intent Routing that routes most queries through zero-LLM tiers. By formulating retrieval as min-cost selection over typed path templates and pairing it with an LLM-side compression step, PRISM surfaces the right evidence under a strict context budget without any fine-tuning or modification to the upstream ingestion pipeline. Experiments on the LoCoMo benchmark show that PRISM delivers substantially higher LLM-judge accuracy than every same-protocol baseline at an order-of-magnitude smaller context budget, occupying a previously empty corner of the accuracy-context-cost frontier and demonstrating a superior balance between answer quality and retrieval efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PRISM, a training-free, inference-time framework for retrieval and compression over graph-structured memory in long-horizon language agents. It combines four components—Hierarchical Bundle Search over typed relation paths, Query-Sensitive Edge Costing that uses detected query intent to guide traversal, Evidence Compression to fit candidate bundles into a strict context budget, and Adaptive Intent Routing that bypasses the LLM for many queries—and claims this yields substantially higher LLM-judge accuracy than same-protocol baselines on the LoCoMo benchmark while using an order-of-magnitude smaller context budget.
Significance. If the reported gains are reproducible and the intent-detection component is shown to be reliable, PRISM would occupy a useful point on the accuracy–context–cost frontier for agent memory management. The training-free nature and lack of upstream pipeline changes are practical strengths that could influence retrieval design for long-context agents.
major comments (3)
- Abstract and Experiments section: the headline claim of substantially higher LLM-judge accuracy at 10× smaller context is presented without any reported baseline definitions, statistical tests, error bars, or number of LoCoMo queries evaluated. This makes it impossible to judge whether the data support the Pareto-frontier assertion.
- Query-Sensitive Edge Costing component (described in the methods): the performance gains are attributed to intent-aware edge costing that operates without training or fine-tuning, yet no intent-classification accuracy, confusion matrix, or ablation that replaces the intent signal with uniform/random costs is provided. If intent detection is only marginally better than chance, the claimed improvement reduces to that of the non-intent-aware graph baseline.
- §4 (Experiments): the manuscript states that the upstream graph is used “as-is,” but supplies no verification that the typed relations and entity linking are sufficiently clean for the Hierarchical Bundle Search and edge-costing steps to function as described; any fragility here would be load-bearing for the reported accuracy numbers.
minor comments (2)
- Notation for path templates and edge costs is introduced without a compact mathematical definition or pseudocode; a small table or equation block would improve clarity.
- The four components are described as orthogonal, but no explicit statement or experiment quantifies the degree of independence (e.g., incremental ablations).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and commit to revisions that improve transparency and rigor without altering the core claims.
read point-by-point responses
-
Referee: Abstract and Experiments section: the headline claim of substantially higher LLM-judge accuracy at 10× smaller context is presented without any reported baseline definitions, statistical tests, error bars, or number of LoCoMo queries evaluated. This makes it impossible to judge whether the data support the Pareto-frontier assertion.
Authors: We agree that greater transparency is needed. In the revised manuscript we will explicitly define every baseline (including exact retrieval protocol and context budget), state the number of LoCoMo queries evaluated (the complete test set), report error bars from repeated LLM-judge runs, and add statistical significance tests (e.g., McNemar’s test) for accuracy differences. These additions will allow direct evaluation of the Pareto claims. revision: yes
-
Referee: Query-Sensitive Edge Costing component (described in the methods): the performance gains are attributed to intent-aware edge costing that operates without training or fine-tuning, yet no intent-classification accuracy, confusion matrix, or ablation that replaces the intent signal with uniform/random costs is provided. If intent detection is only marginally better than chance, the claimed improvement reduces to that of the non-intent-aware graph baseline.
Authors: Intent detection in PRISM uses a deterministic, training-free keyword-and-type heuristic rather than a learned classifier, which is why standalone accuracy metrics were omitted. To address the concern directly, the revision will add an ablation that replaces the intent signal with uniform-cost and random-cost variants. This will quantify the marginal contribution of intent awareness while showing that hierarchical bundle search and compression supply orthogonal gains. revision: yes
-
Referee: §4 (Experiments): the manuscript states that the upstream graph is used “as-is,” but supplies no verification that the typed relations and entity linking are sufficiently clean for the Hierarchical Bundle Search and edge-costing steps to function as described; any fragility here would be load-bearing for the reported accuracy numbers.
Authors: The LoCoMo benchmark supplies the graph as part of the released dataset. In the revision we will add a short verification subsection (or appendix) reporting the fraction of evaluated queries that possess usable typed relation paths and providing qualitative examples of successful bundle retrieval. This will confirm that the methods operate on adequately structured input. The framework includes graceful degradation to broader retrieval when paths are missing, but the requested verification will be supplied. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents PRISM as a training-free framework of four orthogonal inference-time components (Hierarchical Bundle Search, Query-Sensitive Edge Costing, Evidence Compression, Adaptive Intent Routing) whose performance is measured empirically on LoCoMo. No equations, fitted parameters, self-citations, or derivations are described that reduce any claimed result to its own inputs by construction. The central accuracy-context claims rest on experimental outcomes rather than self-referential definitions or renamings.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Cost(π) = d(a) + Σ (c_edge(ei) + c_hop) ... α(τ(ei), h(q)) discounts for TEMPORAL/CAUSAL intents
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PRISM is a training-free retrieval-side framework ... min-cost selection over typed path templates
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
The claude 3 model family: Opus, sonnet, haiku.Claude-3 Model Card, 1(1):4, 2024
AI Anthropic. The claude 3 model family: Opus, sonnet, haiku.Claude-3 Model Card, 1(1):4, 2024
work page 2024
-
[3]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Jizhan Fang, Xinle Deng, Haoming Xu, Ziyan Jiang, Yuqi Tang, Ziwen Xu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, et al. Lightmem: Lightweight and efficient memory- augmented generation.arXiv preprint arXiv:2510.18866, 2025
-
[6]
FlowElement-ai. M-flow. https://github.com/FlowElement-ai/m_flow, 2026. GitHub repository. Accessed: 2026-05-06
work page 2026
-
[7]
MAGMA: A Multi-Graph based Agentic Memory Architecture for AI Agents
Dongming Jiang, Yi Li, Guanpeng Li, and Bingzhe Li. Magma: A multi-graph based agentic memory architecture for ai agents.arXiv preprint arXiv:2601.03236, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Llmlingua: Compress- ing prompts for accelerated inference of large language models
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Llmlingua: Compress- ing prompts for accelerated inference of large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 13358–13376, 2023
work page 2023
-
[9]
Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai. Memory os of ai agent. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25972– 25981, 2025
work page 2025
-
[10]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InEMNLP (1), pages 6769–6781, 2020
work page 2020
-
[11]
Colbert: Efficient and effective passage search via contextual- ized late interaction over bert
Omar Khattab and Matei Zaharia. Colbert: Efficient and effective passage search via contextual- ized late interaction over bert. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, pages 39–48, 2020
work page 2020
-
[12]
arXiv preprint arXiv:2601.02553 , year=
Jiaqi Liu, Yaofeng Su, Peng Xia, Siwei Han, Zeyu Zheng, Cihang Xie, Mingyu Ding, and Huaxiu Yao. Simplemem: Efficient lifelong memory for llm agents.arXiv preprint arXiv:2601.02553, 2026
-
[13]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
work page 2024
-
[14]
Evaluating very long-term conversational memory of llm agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851–13870, 2024
work page 2024
-
[15]
Rodrigo Nogueira and Kyunghyun Cho. Passage re-ranking with bert.arXiv preprint arXiv:1901.04085, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[16]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonza- lez. Memgpt: towards llms as operating systems.arXiv preprint arXiv:2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: a temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Stephen Robertson and Hugo Zaragoza.The probabilistic relevance framework: BM25 and beyond, volume 4. Now Publishers Inc, 2009
work page 2009
-
[19]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
work page 2022
-
[21]
Meda: Dynamic kv cache allocation for efficient multimodal long-context inference
Zhongwei Wan, Hui Shen, Xin Wang, Che Liu, Zheda Mai, and Mi Zhang. Meda: Dynamic kv cache allocation for efficient multimodal long-context inference. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 2485–2497, 2025
work page 2025
-
[22]
Zhongwei Wan, Xinjian Wu, Yu Zhang, Yi Xin, Chaofan Tao, Zhihong Zhu, Xin Wang, Siqi Luo, Jing Xiong, Longyue Wang, et al. D2o: Dynamic discriminative operations for efficient long-context inference of large language models.arXiv preprint arXiv:2406.13035, 2024
-
[23]
Look-m: Look-once optimization in kv cache for efficient multimodal long-context inference
Zhongwei Wan, Ziang Wu, Che Liu, Jinfa Huang, Zhihong Zhu, Peng Jin, Longyue Wang, and Li Yuan. Look-m: Look-once optimization in kv cache for efficient multimodal long-context inference. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 4065–4078, 2024
work page 2024
-
[24]
Xixi Wu, Kuan Li, Yida Zhao, Liwen Zhang, Litu Ou, Huifeng Yin, Zhongwang Zhang, Xinmiao Yu, Dingchu Zhang, Yong Jiang, et al. Resum: Unlocking long-horizon search intelligence via context summarization.arXiv preprint arXiv:2509.13313, 2025
-
[25]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380, 2018
work page 2018
-
[27]
Yi Yu, Liuyi Yao, Yuexiang Xie, Qingquan Tan, Jiaqi Feng, Yaliang Li, and Libing Wu. Agentic memory: Learning unified long-term and short-term memory management for large language model agents.arXiv preprint arXiv:2601.01885, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Memorybank: Enhancing large language models with long-term memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory. InProceedings of the AAAI conference on artificial intelligence, pages 19724–19731, 2024. 11 A Limitations and Broader Impacts Limitations.PRISM currently focuses on retrieval-side compression for LLM-based long-horizon convers...
work page 2024
-
[29]
Include specific details like names, dates, places, objects, and quantities
episode_summary - A concise but comprehensive summary of ALL events and facts mentioned in the chunk. Include specific details like names, dates, places, objects, and quantities
-
[30]
entities - Each item must be: {"name": string, "entity_type": string} - entity_type should be one of: "person", "organization", "place", "concept", "event", "other". - Keep names as they appear in the text whenever possible. - Include specific items mentioned (books, foods, activities, pets, places visited, etc.) as entities with type "concept" or "other"
-
[31]
facet_points - Each item must be: {"content": string, "related_entity_name": string or null, "timestamp_text": string or null} - content should be atomic and factual. - IMPORTANT: Be specific. Include concrete details like exact names, quantities, colors, and descriptions. Good: "Melanie made a cup in her pottery class" Bad : "Melanie does pottery" Good: ...
-
[32]
facets - Each item must be: {"theme": string, "facet_point_indices": array of integers} - facet_point_indices refers to zero-based indices in the facet_points array
-
[33]
temporal_info - Each item must be: {"subject": string, "time_expression": string, "normalized_time": string or null, "relation": string} - relation examples: "before", "after", "during", "at". - normalized_time should use ISO-8601 when explicit enough, otherwise null. - For relative time references (e.g., "yesterday", "last week"), use the conversation ti...
-
[34]
Be specific and cite concrete details from the context
Answer the question using the provided context. Be specific and cite concrete details from the context
-
[35]
For time-related questions, follow these steps: Step 1: Find the conversation date from the header (e.g., [1:56 pm on 8 May, 2023] means the conversation date is 8 May 2023). Step 2: Identify the relative time expression (e.g., "yesterday", "last week", "last Saturday"). Step 3: Calculate the actual date. "yesterday" = conversation date minus 1 day. "last...
work page 2023
-
[36]
When multiple events of the same type exist (e.g., multiple 18 camping trips, multiple beach visits), distinguish between them using their dates
-
[37]
Prefer quoting specific details (names, dates, objects, places) from the context over paraphrasing
-
[38]
If the context contains partial but relevant information, provide the best answer you can
-
[39]
Only say you cannot answer if the context truly contains NO relevant information at all. Answer: LLM-as-a-Judge Prompt. You are an evaluation judge. Compare the generated answer with the gold answer and determine if the generated answer is correct. Be lenient with format differences. For example: - "May 7th" and "7 May" are the same date -> CORRECT - "Cae...
-
[40]
temporal -- The query asks about WHEN something happened, time ordering, duration, or sequence of events. Signals: "when", "before", "after", "during", "how long", "what year", explicit dates, or asking about the timing of events relative to each other
-
[41]
causal -- The query asks WHY something happened, what caused it, or what led to an outcome. Signals: "why", "because", "what caused", "what led to", "as a result of", or asking about reasons, motivations, or consequences
-
[42]
multi_hop -- The query requires combining facts from multiple separate events, interactions, or contexts to answer. A single-fact lookup is NOT multi_hop. Signals: "based on X and Y", "how does X relate to Y", "given that ... what ...", "combining these conversations", "across multiple sessions", asking about trends/patterns/shifts across time, or asking ...
-
[43]
entity_centric -- The query asks about a specific attribute, description, or property of a person, place, or thing that can be looked up as a stored fact. Signals: "who is", "what does X look like", "where does X live", "what is X’s job", or asking to retrieve a single concrete fact about a named entity. NOTE: if answering requires inference or reasoning ...
-
[44]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.