Recognition: 2 theorem links
· Lean TheoremMissingness-MDPs: Bridging the Theory of Missing Data and POMDPs
Pith reviewed 2026-05-13 04:53 UTC · model grok-4.3
The pith
PAC learning of missingness functions yields epsilon-optimal policies for miss-MDPs with high probability
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A miss-MDP is a POMDP whose observation function encodes the probability that individual state features are unobserved at each time step. For each of the three standard missingness types the paper derives PAC learners that recover an approximate miss-MDP from trajectory data. Solving the recovered model with existing planners produces policies that, with high probability, achieve epsilon-optimality in the original environment.
What carries the argument
The miss-MDP, defined as a POMDP whose observation function is a missingness mechanism, together with the PAC learners that exploit the structural properties of MCAR, MAR, and MNAR to recover its parameters from trajectories.
If this is right
- Existing POMDP planners can be used without modification once the missingness function has been recovered.
- The optimality guarantee holds separately for each of the three missingness types by exploiting their distinct identifiability properties.
- The approach converts an otherwise intractable POMDP planning problem into a standard MDP planning problem after learning.
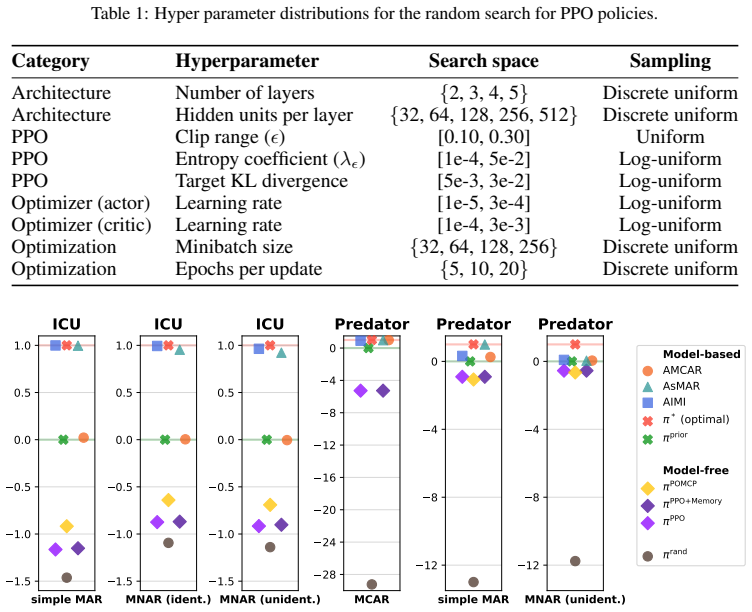
- Empirical results confirm that the method outperforms model-free POMDP baselines on the tested domains.
Where Pith is reading between the lines
- The framework suggests that many real-world POMDP tasks with systematic missing observations, such as sensor data or medical records, could admit similar PAC guarantees once the missingness type is identified.
- Online variants could interleave missingness learning with planning rather than relying on a fixed offline dataset.
- The separation into three canonical types invites further work on hybrid or context-dependent missingness mechanisms.
Load-bearing premise
The true missingness function is one of the three canonical types and the given trajectories suffice to estimate its parameters to the accuracy needed for the PAC bounds to transfer.
What would settle it
A controlled simulation in which the policy obtained from the learned miss-MDP fails to achieve the stated epsilon-optimality gap in the true environment would falsify the transfer of optimality.
Figures






read the original abstract
We introduce missingness-MDPs (miss-MDPs), a novel subclass of partially observable Markov decision processes (POMDPs) that incorporates the theory of missing data. A miss-MDP is a POMDP whose observation function is a missingness function, specifying the probability that individual state features are missing (i.e., unobserved) at a time step. The literature distinguishes three canonical missingness types: missing (1) completely at random (MCAR), (2) at random (MAR), and (3) not at random (MNAR). Our planning problem is to compute near-optimal policies for a miss-MDP with an unknown missingness function, given a dataset of action-observation trajectories. Achieving such optimality guarantees for policies requires learning the missingness function from data, which is infeasible for general POMDPs. To overcome this challenge, we exploit the structural properties of different missingness types to derive probably approximately correct (PAC) algorithms for learning the missingness function. These algorithms yield an approximate but fully specified miss-MDP that we solve using off-the-shelf planning methods. We prove that, with high probability, the resulting policies are epsilon-optimal in the true miss-MDP. Empirical results confirm the theory and demonstrate superior performance of our approach over two model-free POMDP methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces missingness-MDPs (miss-MDPs), a subclass of POMDPs whose observation function is a missingness mechanism over state features. It distinguishes the three canonical missingness types (MCAR, MAR, MNAR), derives PAC algorithms that exploit type-specific structure to learn the missingness function from action-observation trajectories, constructs an approximate but fully specified miss-MDP, solves it with off-the-shelf POMDP planners, and proves that the resulting policies are epsilon-optimal in the true miss-MDP with high probability. Empirical results are reported to confirm the theory and outperform two model-free POMDP baselines.
Significance. If the PAC-to-optimality transfer holds, the work supplies a concrete bridge between missing-data theory and POMDP planning that is unavailable for general POMDPs. The exploitation of MCAR/MAR/MNAR structure to obtain PAC learnability, followed by reuse of existing planners, is a clear methodological strength. No machine-checked proofs or open-source code are mentioned, but the falsifiable claim of epsilon-optimality under explicit missingness types is a positive feature.
major comments (2)
- [Proof of epsilon-optimality (likely §4 or Theorem on PAC transfer)] The central claim requires that a PAC approximation of the missingness function (error delta) induces a value-function difference bounded by epsilon in the true miss-MDP. No explicit Lipschitz constant, contraction modulus of the Bellman operator, or sensitivity analysis with respect to the observation probabilities is visible that would guarantee uniform transfer of delta to policy value, particularly under MNAR where missingness depends on latent state features.
- [MNAR learning algorithm and sample-complexity derivation] For MNAR, the trajectories are generated by policies that act on partial observations; this induces a distribution over missingness patterns that may violate the i.i.d. assumptions underlying standard missing-data PAC bounds. The paper must show that its structural exploitation still yields sample complexity that controls the induced dependence between actions and missingness.
minor comments (2)
- [Abstract] The abstract states 'superior performance' without naming the two model-free baselines or the evaluation metrics (e.g., cumulative reward, success rate).
- [Model definition and notation] Notation for the true miss-MDP versus the learned approximate miss-MDP should be introduced once and used consistently when stating the epsilon-optimality guarantee.
Simulated Author's Rebuttal
We thank the referee for the insightful and constructive comments. We address each major point below, providing clarifications on the theoretical arguments and indicating where we will revise the manuscript for greater explicitness.
read point-by-point responses
-
Referee: [Proof of epsilon-optimality (likely §4 or Theorem on PAC transfer)] The central claim requires that a PAC approximation of the missingness function (error delta) induces a value-function difference bounded by epsilon in the true miss-MDP. No explicit Lipschitz constant, contraction modulus of the Bellman operator, or sensitivity analysis with respect to the observation probabilities is visible that would guarantee uniform transfer of delta to policy value, particularly under MNAR where missingness depends on latent state features.
Authors: We agree that the transfer argument would benefit from a more explicit sensitivity analysis. The proof of Theorem 4.2 composes the PAC guarantee on the missingness function with a bound on the induced difference in value functions. This bound follows from the contraction property of the POMDP Bellman operator (modulus equal to the discount factor gamma) and the fact that the value function is Lipschitz continuous in the total-variation distance between observation distributions, with the Lipschitz constant depending only on the reward range and gamma. For the MNAR case the analysis further uses the deterministic dependence of missingness on the latent state to control the distribution shift. While these steps are present, the Lipschitz constant is not isolated as a standalone lemma. We will add Lemma 4.1 stating the explicit constant and the full sensitivity derivation in the revised manuscript. revision: partial
-
Referee: [MNAR learning algorithm and sample-complexity derivation] For MNAR, the trajectories are generated by policies that act on partial observations; this induces a distribution over missingness patterns that may violate the i.i.d. assumptions underlying standard missing-data PAC bounds. The paper must show that its structural exploitation still yields sample complexity that controls the induced dependence between actions and missingness.
Authors: We appreciate the referee drawing attention to the dependence issue in the MNAR setting. Section 3.3 derives the sample complexity for MNAR by exploiting the structural assumption that missingness is a deterministic function of the full state. The algorithm collects trajectories under the current policy and uses a covering argument over possible missingness patterns; the resulting bound replaces standard Hoeffding inequalities with martingale concentration to account for the policy-induced dependence between actions and missingness indicators. The multiplicative factor that appears in the sample complexity is polynomial in the number of actions and the horizon length. We will revise the exposition to include an explicit remark (Remark 3.4) that isolates this dependence control and confirms that the PAC guarantee remains valid. revision: partial
Circularity Check
No circularity: derivation chains PAC learning of missingness to standard POMDP planning bounds without reduction to fitted inputs or self-citations
full rationale
The paper defines miss-MDPs as POMDPs with an explicit missingness observation function, then uses established MCAR/MAR/MNAR structural assumptions to derive PAC learners for that function from trajectories. The resulting approximate miss-MDP is solved with off-the-shelf planners, and epsilon-optimality in the true model is claimed via high-probability transfer bounds. These steps rely on external missing-data taxonomy and generic POMDP approximation results rather than any self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation. The central guarantee is a composite error bound (learning error + planning error) that does not collapse to the input data by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Observation missingness follows one of the three canonical types MCAR, MAR, or MNAR
invented entities (1)
-
miss-MDP
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearWe introduce missingness-MDPs (miss-MDPs), a novel subclass of partially observable Markov decision processes (POMDPs) that incorporates the theory of missing data... PAC algorithms for learning the missingness function... policies are ε-optimal in the true miss-MDP.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe prove that state beliefs do not always depend on the missingness function’s probabilities (Remark 1), similar to ignorability of missing data.
Reference graph
Works this paper leans on
-
[1]
Zeyu Liu, Anahita Khojandi, Xueping Li, Akram Mohammed, Robert L Davis, and Rishikesan Kamaleswaran. A Machine Learning–Enabled Partially Observable Markov Decision Process Framework for Early Sepsis Prediction.INFORMS Journal on Computing, 34(4):2039–2057, July
work page 2039
-
[2]
Solving robust markov decision processes: Generic, reliable, efficient.CoRR, abs/2412.10185,
Tobias Meggendorfer, Maximilian Weininger, and Patrick Wienh¨oft. Solving robust markov decision processes: Generic, reliable, efficient.CoRR, abs/2412.10185,
-
[3]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms.CoRR, abs/1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Yuhui Wang, Hao He, and Xiaoyang Tan. Robust reinforce- ment learning in POMDPs with incomplete and noisy ob- servations.CoRR, abs/1902.05795,
-
[5]
= 1z⪯s′ P s∈S T(s ′ |s, a)b(s)P s′′∈S 1z⪯s′′ P s∈S T(s ′′ |s, a)b(s) . (pcancels out) Therefore, the probabilities of M do not affect the resulting probabilities of the belief update. In particular, this means that maintaining a belief while executing a miss-MDP does not require knowledge ofM. Still, we stress again that one needs M to compute an opti- ma...
work page 2022
-
[6]
Moreover, we denote by ˆp= k n the empirical success probability. Okamoto’s seminal work proves the following property of estimating p through observing a Bernoulli process: Theorem 4(Okamoto’s inequality (Okamoto, 1959, Theorem 1)).For a Bernoulli process with n repetitions and k successes and a given precisionε, we have Pr(ˆp−p≥ε)≤e −2·n·ε2 andPr(p−ˆp≥ε...
work page 1959
-
[7]
for a discussion. However, as our goal is only to prove the existence of a bound, we choose the conservative Okamoto bound for its easier accessibility. C.2 PAC guarantees for AsMAR Theorem 1(PAC guarantee for AsMAR).Let P be a missingness-MDP with a simple MAR missingness function. For every precision ε and confidence threshold δ, there exists a number n...
work page 2005
-
[8]
Proof. (a) If we know from an m-graph that a particular fea- ture i is not influenced by feature j, for all valuations of j the Bernoulli process has the same success probability. Thus, we can merge these Bernoulli processes and ignore featurej. (b) If we know the missingness function is simple MAR and feature j goes missing, we know that it cannot influe...
work page 2021
-
[9]
Hence, given the dataset described in the pre- vious paragraph, we can approximate cM in a way such that with probability δ, it is εM -precise. Note that here we do not employ the full allowed imprecision ε, but rather a smaller εM < ε, since there will be other sources of error. M andcM qualitatively agree.For our technical reasoning, we require that M(z...
work page 2017
-
[10]
For every closed constant-support RMDP
exist. Using Lemma 2, we obtain the following inequality: |VP(π∗)−V bP(π∗)| ≤f(ε M).(6) Implications of the inequalities.Since we reason about absolute differences, we need to make case distinctions on whether supπ VP(π)−sup π V bP(π)≥0 or not when apply- ing Equation (4). If supπ VP(π)−sup π V bP(π)≥0 , then supπ VP(π)−sup π V bP(π)≤f(ε M), and by reorde...
work page 2022
-
[11]
applies to all policies. An environment policy is the policy that chooses the instantiation of the transition function, i.e. the exact missingness probabilities from the set of all that differ by at mostε M in our setting. • “Total-reward objectives:” (Meggendorferet al., 2024, Lemma
work page 2024
-
[12]
The value function is continuous w.r.t. the environment policy
concernsundiscountedtotal-reward or mean payoff objectives. Undiscounted total-reward generalizes discounted expected reward, using the standard construc- tion which adds an edge transitioning with probability γ to a dedicated sink state to every transition. Thus, the lemma is applicable to the objective in our setting. • “The value function is continuous...
work page 2024
-
[13]
Predator.This environment is a variant of theTagbench- mark from Pineauet al.(2003), where an agent (in our case, a predator) is tasked with chasing a partially hidden target (a prey) in a 2D grid environment. The prey senses the predator and usually moves away from it; in case multiple directions lead away from the predator, the prey chooses uniformly at...
work page 2003
-
[14]
Training and Evaluation.All PPO policies were trained for nsteps = 106 steps with individual seeds using the Adam optimizer. The policies were evaluated using cumulative dis- counted return, identical to the evaluation of the other bench- marks. During evaluation actions were sampled from PPO’s action distribution. The mean performance was computed over n...
work page 2000
-
[15]
were computed using the BasicPOMCP.jl framework (Version 0.3.12) in Julia (Version 1.11.5), which implements the PO-UCT online tree search algorithm together with particle filters (resulting in POMCP) for POMDPs. Planning Setup.POMCP was used as an online, planning baseline with access to the transition and reward functions of the underlying miss-MDP. Bel...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.