Recognition: no theorem link
Beyond Text Prompts: Visual-to-Visual Generation as A Unified Paradigm
Pith reviewed 2026-05-13 05:56 UTC · model grok-4.3
The pith
Visual specification pages replace text prompts in frozen generators without any retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
V2V-Zero is a training-free framework that conditions existing VLM-based generators by replacing text-only inputs with final-layer hidden states extracted from visual specification pages, exploiting the fact that the frozen VLM already projects both modalities into the generator's conditioning space.
What carries the argument
V2V-Zero framework that substitutes text conditioning with final-layer hidden states from visual pages in VLM-conditioned generators.
If this is right
- Existing commercial and open-weight generators can accept visual conditioning through the same interface without architectural modification.
- Attribute binding succeeds reliably while structural alignment and novel content synthesis remain weak points even in closed models.
- The same conditioning swap extends directly to video generators and yields measurable though lower performance.
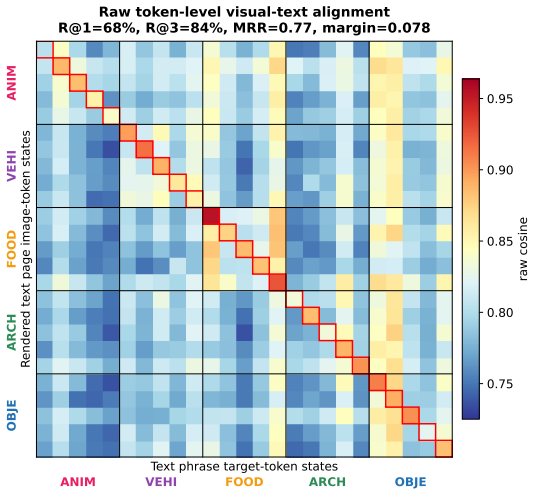
- Conditioning-token attention concentrates 95 percent on the visual-page states, indicating the default reasoning path is visually routed.
Where Pith is reading between the lines
- Users could shift from prompt engineering to creating and editing visual reference documents as the primary creative interface.
- The observed hierarchy of task difficulty points to specific places where future models would need stronger visual-semantic integration.
- If the mapping property holds across more VLMs, visual-to-visual may become the default conditioning mode rather than a special case.
Load-bearing premise
The frozen VLM already maps both text and visual pages into the generator's conditioning space so that the visual hidden states can stand in for text without any fine-tuning.
What would settle it
An experiment that swaps the visual-page hidden states for random vectors while keeping every other model component fixed and measures whether GenEval and Simple-V2V Bench scores collapse toward zero.
Figures










read the original abstract
Humans often specify and create through visual artifacts: typography sheets, sketches, reference images, and annotated scenes. Yet modern visual generators still ask users to serialize this intent into text, a bottleneck that compresses signals like spatial structure, exact appearance, and glyph shape. We propose \textbf{\emph{visual-to-visual} (V2V)} generation, in which the user conditions a generative model with a visual specification page rather than a text prompt. The page is not an edit target, but a visual document that specifies the desired output. We introduce \textbf{V2V-Zero}, a training-free framework that exposes this interface in existing vision-language model (VLM) conditioned generators by replacing text-only conditioning with final-layer hidden states extracted from visual pages, exploiting the fact that the frozen VLM already maps both text and images into the generator's conditioning space. On GenEval, V2V-Zero reaches 0.85 with a frozen Qwen-Image backbone, closely matching its optimized text-to-image performance without fine-tuning. To evaluate the broader V2V space, we introduce \textbf{Simple-V2V Bench}, spanning seven visual-conditioning tasks and seven models, including GPT Image 2, Nano Banana 2, Seedream 5.0 Lite, open-weight baselines, and a video extension. V2V-Zero scores 32.7/100, outperforming evaluated open-weight image baselines and revealing a clear capability hierarchy: attribute binding is strong, content generation is unreliable, and structural control remains hard even for commercial systems. A HunyuanVideo-1.5 extension scores 20.2/100, showing the interface transfers beyond images. Mechanistic analysis shows the default reasoning path is primarily visually routed, with 95.0\% of conditioning-token attention mass on visual-page hidden states.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes visual-to-visual (V2V) generation as an alternative to text prompting, where a visual specification page (sketches, glyphs, annotations) conditions a generative model. It introduces the training-free V2V-Zero framework that extracts final-layer hidden states from a frozen VLM processing the visual page and substitutes them for text conditioning tokens, exploiting the claim that the VLM already maps both modalities into the generator's conditioning space. On GenEval, V2V-Zero achieves 0.85 with a frozen Qwen-Image backbone, matching its text-to-image performance; a new Simple-V2V Bench yields 32.7/100 across seven tasks and models (with a HunyuanVideo extension at 20.2/100), and mechanistic analysis reports 95% attention mass on visual states.
Significance. If the core substitution holds, the work offers a practical route to richer conditioning interfaces that preserve spatial and structural signals lost in text serialization, with the training-free property and video transfer as clear strengths. The competitive GenEval number and attention analysis provide initial support, but the absence of error bars, distribution-shift tests, and detailed ablations limits the strength of the evidence for broad adoption.
major comments (2)
- [Abstract] Abstract: The central claim that final-layer VLM hidden states from visual pages occupy the same conditioning manifold as text tokens (allowing direct substitution without fine-tuning or architectural changes) is load-bearing yet unverified; no direct comparison of state distributions, positional encoding effects, or out-of-distribution visual-page tests is reported to rule out systematic shifts that GenEval may tolerate but other tasks would not.
- [Abstract] GenEval results: The reported 0.85 score is presented as closely matching optimized text-to-image performance, but lacks error bars, variance across runs, or explicit controls for visual-page composition (e.g., sketch vs. annotated scene), making it impossible to assess whether the match is robust or coincidental.
minor comments (1)
- [Abstract] Abstract: The description of Simple-V2V Bench mentions seven tasks and seven models but provides no definition of the scoring scale (out of 100) or task breakdown, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will incorporate revisions to strengthen the empirical support for the core substitution claim and the reported results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that final-layer VLM hidden states from visual pages occupy the same conditioning manifold as text tokens (allowing direct substitution without fine-tuning or architectural changes) is load-bearing yet unverified; no direct comparison of state distributions, positional encoding effects, or out-of-distribution visual-page tests is reported to rule out systematic shifts that GenEval may tolerate but other tasks would not.
Authors: We agree that direct verification of manifold alignment (e.g., via distribution comparisons or positional encoding analysis) is absent from the current manuscript and would strengthen the load-bearing claim. The 95% attention mass and GenEval parity provide indirect support, but we will add a dedicated analysis section in the revision that includes cosine similarity between text and visual hidden states on held-out sets, positional encoding ablation, and out-of-distribution visual-page tests to rule out systematic shifts. revision: yes
-
Referee: [Abstract] GenEval results: The reported 0.85 score is presented as closely matching optimized text-to-image performance, but lacks error bars, variance across runs, or explicit controls for visual-page composition (e.g., sketch vs. annotated scene), making it impossible to assess whether the match is robust or coincidental.
Authors: We concur that error bars, run variance, and explicit controls for visual-page composition are needed to demonstrate robustness. In the revised manuscript we will report standard deviations over multiple random seeds, provide per-composition breakdowns (sketch vs. glyph vs. annotated scene), and detail the exact visual-page generation protocol used for the GenEval evaluation. revision: yes
Circularity Check
No significant circularity: V2V-Zero is training-free and exploits pre-existing frozen VLM properties without reducing results to self-defined fits or citations
full rationale
The paper introduces V2V-Zero as a zero-shot substitution of final-layer VLM hidden states from visual pages for text conditioning tokens, explicitly relying on the pre-trained mapping properties of existing frozen models rather than any derivation, parameter fitting, or self-referential construction. Reported metrics such as 0.85 on GenEval and 32.7/100 on Simple-V2V Bench are obtained through direct empirical evaluation on external benchmarks with no equations or steps that redefine outcomes in terms of the paper's own inputs. No self-citations serve as load-bearing uniqueness theorems, no ansatzes are smuggled, and no predictions reduce by construction to fitted quantities. The approach is self-contained against external model properties and benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The frozen VLM already maps both text and images into the generator's conditioning space so that final-layer hidden states from visual pages can replace text conditioning without any fine-tuning or architectural changes.
Reference graph
Works this paper leans on
-
[1]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report,
-
[3]
URLhttps://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
work page 2023
-
[5]
HunyuanVideo 1.5 Technical Report
Bing Wu, Chang Zou, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Jack Peng, Jianbing Wu, Jiangfeng Xiong, Jie Jiang, et al. Hunyuanvideo 1.5 technical report.arXiv preprint arXiv:2511.18870, 2025
work page internal anchor Pith review arXiv 2025
-
[6]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[7]
High-resolution image synthesis with latent diffusion models, 2021
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models, 2021
work page 2021
-
[8]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in Neural Information Processing Systems, 35:36479–36494, 2022
work page 2022
-
[9]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205, 2023
work page 2023
-
[11]
Yaofang Liu, Yumeng Ren, Xiaodong Cun, Aitor Artola, Yang Liu, Tieyong Zeng, Raymond H Chan, and Jean-michel Morel. Redefining temporal modeling in video diffusion: The vectorized timestep approach.arXiv preprint arXiv:2410.03160, 2024
-
[12]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data.arXiv preprint arXiv:2209.14792, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Yaofang Liu, REN Yumeng, Aitor Artola, Yuxuan Hu, Xiaodong Cun, Xiaotong Zhao, Alan Zhao, Raymond H Chan, Suiyun Zhang, Rui Liu, et al. Pusa v1. 0: Unlocking temporal control in pretrained video diffusion models via vectorized timestep adaptation. InThe Fourteenth International Conference on Learning Representations
-
[15]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Haoxin Chen, Menghan Xia, Yingqing He, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Jinbo Xing, Yaofang Liu, Qifeng Chen, Xintao Wang, et al. Videocrafter1: Open diffusion models for high-quality video generation.arXiv preprint arXiv:2310.19512, 2023. 10
work page internal anchor Pith review arXiv 2023
-
[17]
Evalcrafter: Benchmarking and evaluating large video generation models
Yaofang Liu, Xiaodong Cun, Xuebo Liu, Xintao Wang, Yong Zhang, Haoxin Chen, Yang Liu, Tieyong Zeng, Raymond Chan, and Ying Shan. Evalcrafter: Benchmarking and evaluating large video generation models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22139–22149, 2024
work page 2024
-
[18]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
work page 2020
-
[19]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021
work page 2021
-
[20]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations.arXiv preprint arXiv:2108.01073, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Instructpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18392–18402, 2023
work page 2023
-
[23]
Tokenflow: Con- sistent diffusion features for consistent video editing,
Michal Geyer, Omer Bar-Tal, Shai Bagon, and Tali Dekel. Tokenflow: Consistent diffusion features for consistent video editing.arXiv preprint arXiv:2307.10373, 2023
-
[24]
Max Ku, Cong Wei, Weiming Ren, Harry Yang, and Wenhu Chen. Anyv2v: A tuning-free framework for any video-to-video editing tasks.arXiv preprint arXiv:2403.14468, 2024
-
[25]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3836–3847, 2023
work page 2023
-
[26]
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 4296–4304, 2024
work page 2024
-
[27]
Gligen: Open-set grounded text-to-image generation
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22511–22521, 2023
work page 2023
-
[28]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500–22510, 2023
work page 2023
-
[30]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Xiang Wang, Hangjie Yuan, Shiwei Zhang, Dayou Chen, Jiuniu Wang, Yingya Zhang, Yujun Shen, Deli Zhao, and Jingren Zhou. Videocomposer: Compositional video synthesis with motion controllability.Advances in Neural Information Processing Systems, 36:7594–7611, 2023. 11
work page 2023
-
[32]
Omnigen: Unified image generation
Shitao Xiao, Yueze Wang, Junjie Zhou, Huaying Yuan, Xingrun Xing, Ruiran Yan, Chaofan Li, Shuting Wang, Tiejun Huang, and Zheng Liu. Omnigen: Unified image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13294–13304, 2025
work page 2025
-
[33]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, Ze Liu, Ziyi Xia, Chaofan Li, Haoge Deng, Jiahao Wang, Kun Luo, Bo Zhang, Defu Lian, Xinlong Wang, Zhongyuan Wang, Tiejun Huang, and Zheng Liu. Omnigen2: Towards instruction-aligned multimodal generation, 2026. URL https://arxiv.org/abs...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Vace: All-in- one video creation and editing
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. Vace: All-in- one video creation and editing. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17191–17202, 2025
work page 2025
-
[35]
Character-aware models improve visual text rendering
Rosanne Liu, Dan Garrette, Chitwan Saharia, William Chan, Adam Roberts, Sharan Narang, Irina Blok, RJ Mical, Mohammad Norouzi, and Noah Constant. Character-aware models improve visual text rendering. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16270–16297, 2023
work page 2023
-
[36]
Yukang Yang, Dongnan Gui, Yuhui Yuan, Weicong Liang, Haisong Ding, Han Hu, and Kai Chen. Glyphcontrol: Glyph conditional control for visual text generation.Advances in Neural Information Processing Systems, 36:44050–44066, 2023
work page 2023
-
[37]
Anytext: Multilingual visual text generation and editing.arXiv preprint arXiv:2311.03054, 2023
Yuxiang Tuo, Wangmeng Xiang, Jun-Yan He, Yifeng Geng, and Xuansong Xie. Anytext: Multilingual visual text generation and editing.arXiv preprint arXiv:2311.03054, 2023
-
[38]
Jingye Chen, Yupan Huang, Tengchao Lv, Lei Cui, Qifeng Chen, and Furu Wei. Textdiffuser: Diffusion models as text painters.Advances in Neural Information Processing Systems, 36: 9353–9387, 2023
work page 2023
-
[39]
Improving image generation with better captions
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions. Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, 2(3):8, 2023
work page 2023
-
[40]
Amir Bar, Yossi Gandelsman, Trevor Darrell, Amir Globerson, and Alexei Efros. Visual prompting via image inpainting.Advances in neural information processing systems, 35: 25005–25017, 2022
work page 2022
-
[41]
Zhendong Wang, Yifan Jiang, Yadong Lu, Pengcheng He, Weizhu Chen, Zhangyang Wang, Mingyuan Zhou, et al. In-context learning unlocked for diffusion models.Advances in Neural Information Processing Systems, 36:8542–8562, 2023
work page 2023
-
[42]
Context diffusion: In-context aware image generation
Ivona Najdenkoska, Animesh Sinha, Abhimanyu Dubey, Dhruv Mahajan, Vignesh Ramanathan, and Filip Radenovic. Context diffusion: In-context aware image generation. InEuropean Conference on Computer Vision, pages 375–391. Springer, 2024
work page 2024
-
[43]
Stable diffusion models are secretly good at visual in-context learning
Trevine Oorloff, Vishwanath Sindagi, Wele Gedara Chaminda Bandara, Ali Shafahi, Amin Ghiasi, Charan Prakash, and Reza Ardekani. Stable diffusion models are secretly good at visual in-context learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 23604–23613, 2025
work page 2025
-
[44]
Visualcloze: A universal image generation framework via visual in-context learning
Zhong-Yu Li, Ruoyi Du, Juncheng Yan, Le Zhuo, Zhen Li, Peng Gao, Zhanyu Ma, and Ming- Ming Cheng. Visualcloze: A universal image generation framework via visual in-context learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18969–18979, 2025
work page 2025
-
[45]
Realgeneral: Unifying visual generation via temporal in-context learning with video models
Yijing Lin, Mengqi Huang, Shuhan Zhuang, and Zhendong Mao. Realgeneral: Unifying visual generation via temporal in-context learning with video models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14994–15004, 2025
work page 2025
-
[46]
Unic: Unified in-context video editing.arXiv preprint arXiv:2506.04216, 2025
Zixuan Ye, Xuanhua He, Quande Liu, Qiulin Wang, Xintao Wang, Pengfei Wan, Di Zhang, Kun Gai, Qifeng Chen, and Wenhan Luo. Unic: Unified in-context video editing.arXiv preprint arXiv:2506.04216, 2025. 12
- [47]
-
[48]
Show-o2: Improved Native Unified Multimodal Models
Jinheng Xie, Zhenheng Yang, and Mike Zheng Shou. Show-o2: Improved native unified multimodal models.arXiv preprint arXiv:2506.15564, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation
Zhiheng Liu, Weiming Ren, Xiaoke Huang, Shoufa Chen, Tianhong Li, Mengzhao Chen, Yatai Ji, Sen He, Jonas Schult, Belinda Zeng, et al. Tuna-2: Pixel embeddings beat vision encoders for multimodal understanding and generation.arXiv preprint arXiv:2604.24763, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Dianyi Wang, Ruihang Li, Feng Han, Chaofan Ma, Wei Song, Siyuan Wang, Yibin Wang, Yi Xin, Hongjian Liu, Zhixiong Zhang, et al. Deepgen 1.0: A lightweight unified multimodal model for advancing image generation and editing.arXiv preprint arXiv:2602.12205, 2026
-
[52]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single trans- former to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
PixArt-$\alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, et al. Pixart- α: Fast training of diffusion transformer for photorealistic text-to-image synthesis.arXiv preprint arXiv:2310.00426, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
work page 2024
-
[57]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas Müller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext: Flow matching for in-context image ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Yiyang Ma, Xingchao Liu, Xiaokang Chen, Wen Liu, Chengyue Wu, Zhiyu Wu, Zizheng Pan, Zhenda Xie, Haowei Zhang, Xingkai Yu, et al. Janusflow: Harmonizing autoregression and rectified flow for unified multimodal understanding and generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7739–7751, 2025
work page 2025
-
[59]
Lumina-image 2.0: A unified and efficient image generative framework
Qi Qin, Le Zhuo, Yi Xin, Ruoyi Du, Zhen Li, Bin Fu, Yiting Lu, Xinyue Li, Dongyang Liu, Xiangyang Zhu, et al. Lumina-image 2.0: A unified and efficient image generative framework. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20031– 20042, 2025
work page 2025
-
[60]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Qi Cai, Jingwen Chen, Yang Chen, Yehao Li, Fuchen Long, Yingwei Pan, Zhaofan Qiu, Yiheng Zhang, Fengbin Gao, Peihan Xu, et al. Hidream-i1: A high-efficient image generative foundation model with sparse diffusion transformer.arXiv preprint arXiv:2505.22705, 2025. 13
-
[62]
https://platform.openai.com/docs/ models/gpt-image-1,
Openai model documentation: gpt-image-1. https://platform.openai.com/docs/ models/gpt-image-1, . Accessed: 2025
work page 2025
-
[63]
Yu Gao, Lixue Gong, Qiushan Guo, Xiaoxia Hou, Zhichao Lai, Fanshi Li, Liang Li, Xi- aochen Lian, Chao Liao, Liyang Liu, et al. Seedream 3.0 technical report.arXiv preprint arXiv:2504.11346, 2025
work page internal anchor Pith review arXiv 2025
-
[64]
https://platform.openai.com/docs/ models/gpt-image-2,
Openai model documentation: gpt-image-2. https://platform.openai.com/docs/ models/gpt-image-2, . Accessed: 2026
work page 2026
-
[65]
https://seed.bytedance.com/en/seedream5_ 0_lite
Seedream 5.0 lite model documentation. https://seed.bytedance.com/en/seedream5_ 0_lite. Accessed: 2026
work page 2026
-
[66]
Nano banana 2 model documentation. https://gemini.google/overview/ image-generation/. Accessed: 2026. 14 A Mechanism and Signal Diagnostics The main mechanism claim is empirical: the default FULL-FINALreasoning path is primarily visually routed. In the real attention capture in Section 5, the Qwen-Image DiT assigns 95.0% of measured conditioning-token att...
-
[67]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.