Recognition: 1 theorem link
· Lean TheoremIterative Audit Convergence in LLM-Managed Multi-Agent Systems: A Case Study in Prompt Engineering Quality Assurance
Pith reviewed 2026-05-13 03:25 UTC · model grok-4.3
The pith
Iterative audits by LLM sub-agents on a 7150-line prompt system found 51 consistency defects and converged to zero after nine rounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
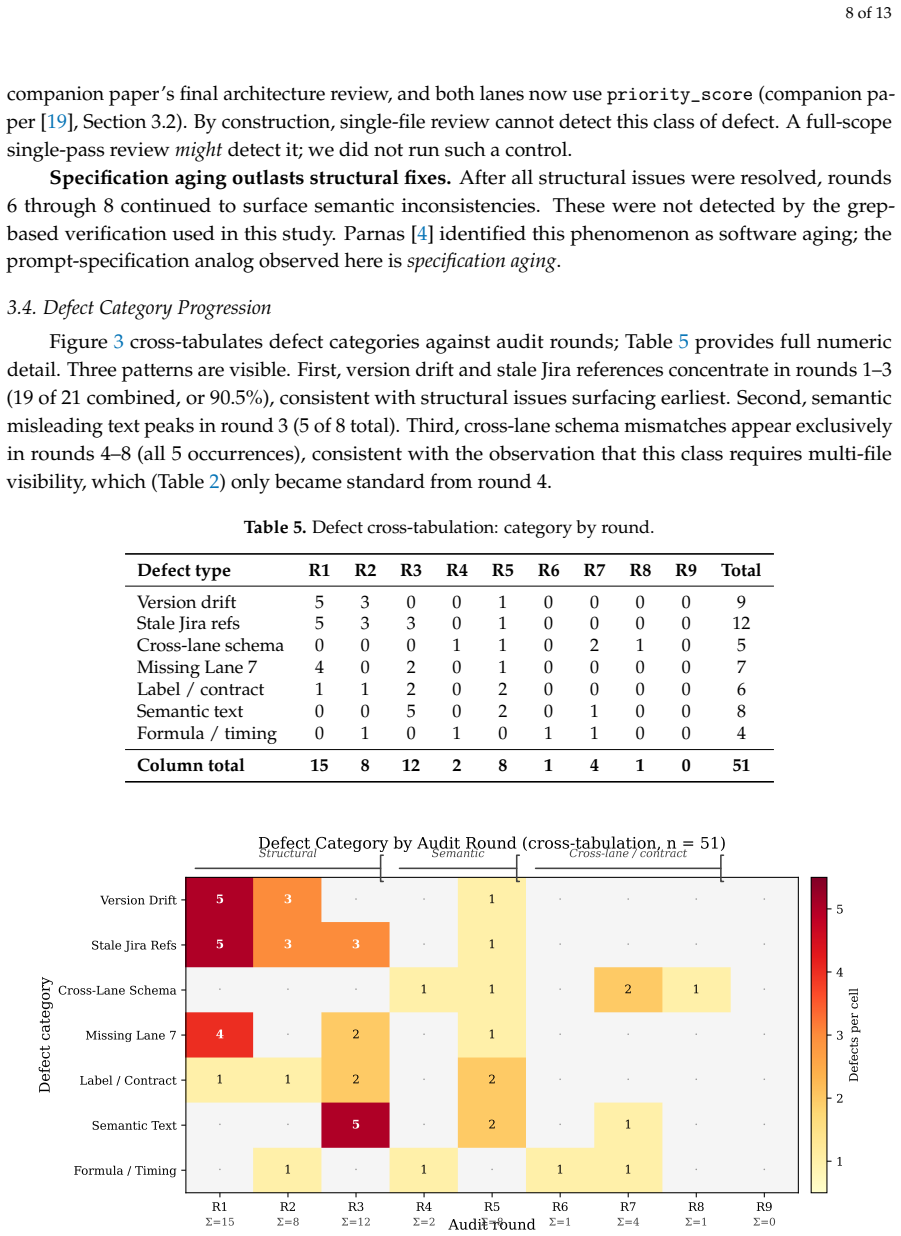
In this 7150-line prompt-specification surface of the AEGIS production pipeline, nine sequential audit rounds executed by Claude sub-agents using a checklist-driven walkthrough adapted from Weinberg and Freedman surfaced 51 prompt-specification consistency defects, with per-round counts of 15, 8, 12, 2, 8, 1, 4, 1, and 0, demonstrating non-monotonic convergence consistent with cascading edits and audit-scope expansion, while single-file review missed defect classes surfaced only by later expanded-scope rounds.
What carries the argument
The checklist-driven walkthrough adapted from Weinberg and Freedman, executed iteratively by Claude sub-agents across multiple prompt files to inspect data contracts and integration logic.
If this is right
- Single-file review is insufficient to catch all consistency defects in multi-file prompt specifications.
- Non-monotonic convergence occurs as fixes in one area and expanded scope expose new issues in others.
- A seven-category defect taxonomy with explicit coding rules classifies prompt-specification issues.
- The distilled audit protocol and locked checklist support application to other similar systems.
Where Pith is reading between the lines
- This method could be integrated into development pipelines to catch prompt integration errors earlier in multi-agent LLM projects.
- Testing the protocol across dissimilar models would clarify whether convergence speed depends on the auditor model.
- The taxonomy might serve as a starting point for automated prompt linting tools in complex orchestration setups.
Load-bearing premise
The observed defects and convergence behavior are attributable to the iterative multi-scope audit process rather than to the specific choice of LLM family for both authoring and auditing, and that the post-hoc taxonomy and protocol will generalize beyond this single system.
What would settle it
Re-running the nine-round audit on the same prompt specifications using a different LLM family or human reviewers and checking whether the same 51 defects appear with similar per-round counts and final convergence.
Figures


read the original abstract
Prompt specifications for multi-agent large language model (LLM) systems carry data contracts and integration logic across many interdependent files but are rarely subjected to structured-inspection rigor. This paper reports a single-system empirical case study of iterative, agent-driven auditing applied to AEGIS (Autonomous Engineering Governance and Intelligence System), a production seven-lane orchestration pipeline whose prompt-specification surface comprises approximately 7150 lines: 6907 across seven lane PROMPT.md files and a 245-line shared Ticket Contract. Nine sequential audit rounds, executed by Claude sub-agents using a checklist-driven walkthrough adapted from Weinberg and Freedman, surfaced 51 prompt-specification consistency defects, distinct from the 51 STRIDE-categorized adversarial code findings reported in the companion preprint. Per-round counts were 15, 8, 12, 2, 8, 1, 4, 1, and 0. We report a seven-category post-hoc defect taxonomy with explicit coding rules, observed non-monotonic convergence consistent with cascading edits and audit-scope expansion, and an audit protocol distilled from the study, with the final locked checklist released as a reproducibility appendix. Single-file review missed defect classes that were surfaced only by later expanded-scope rounds in this system. The same LLM family authored and audited the specifications; replication with dissimilar models and human reviewers is required before generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a single-system empirical case study of iterative audit convergence applied to the ~7150-line prompt specifications of the AEGIS multi-agent orchestration system. Nine sequential rounds of checklist-driven walkthroughs by Claude sub-agents (adapted from Weinberg and Freedman) identified 51 prompt-specification consistency defects with per-round counts of 15, 8, 12, 2, 8, 1, 4, 1, and 0. The authors present a seven-category post-hoc defect taxonomy with explicit coding rules, document non-monotonic convergence attributed to cascading edits and audit-scope expansion, and release a distilled audit protocol plus locked checklist as a reproducibility appendix. They explicitly note that the same LLM family authored and audited the specifications and call for external replication.
Significance. If the 51 defects are independently confirmed as genuine consistency issues and the observed convergence pattern holds beyond this single system and model family, the work supplies a concrete, reproducible protocol for structured quality assurance of interdependent prompt specifications in LLM-managed multi-agent systems. The explicit per-round counts, released checklist, and adaptation of established inspection methods provide a useful empirical baseline for software engineering research on prompt engineering practices.
major comments (3)
- [Results section (per-round defect counts)] Results section (per-round defect counts): The headline finding of 51 defects and the specific sequence 15, 8, 12, 2, 8, 1, 4, 1, 0 rests entirely on the LLM sub-agents' checklist walkthroughs. Because the identical model family both authored the 7150-line specifications and performed all audits, there is no external anchor (human review, inter-rater reliability metric, or dissimilar-model replication) establishing that the reported items are genuine consistency defects rather than model-specific interpretation artifacts.
- [Taxonomy development (seven-category post-hoc taxonomy)] Taxonomy development (seven-category post-hoc taxonomy): The taxonomy and its coding rules are derived entirely from the defects found in this study. Without pre-defined criteria, independent validation against other systems, or inter-rater agreement statistics, the taxonomy cannot yet support the claim that the distilled protocol will generalize or that the observed non-monotonic convergence is attributable to the iterative multi-scope process rather than the specific LLM choice.
- [Methodology (single-system design and scope expansion)] Methodology (single-system design and scope expansion): The claim that single-file review missed defect classes later surfaced by expanded-scope rounds is demonstrated only within this one 7150-line AEGIS system. Absent any comparison arm (human auditors or a dissimilar model family), the attribution of convergence behavior to the iterative, multi-agent audit protocol remains untested and limits the strength of the central empirical contribution.
minor comments (2)
- [Abstract] Abstract: The statement that the 51 defects are 'distinct from the 51 STRIDE-categorized adversarial code findings reported in the companion preprint' lacks a citation or arXiv link, which would help readers locate the related work.
- [Appendix] Appendix: While the locked checklist is released, the manuscript would benefit from including at least one anonymized example of a round-by-round defect report to illustrate how the seven-category coding rules were applied in practice.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review of our case study on iterative audit convergence. We address each major comment below, acknowledging the inherent limitations of a single-system empirical design while clarifying the scope of our contributions and the value of the released protocol and materials.
read point-by-point responses
-
Referee: Results section (per-round defect counts): The headline finding of 51 defects and the specific sequence 15, 8, 12, 2, 8, 1, 4, 1, and 0 rests entirely on the LLM sub-agents' checklist walkthroughs. Because the identical model family both authored the 7150-line specifications and performed all audits, there is no external anchor (human review, inter-rater reliability metric, or dissimilar-model replication) establishing that the reported items are genuine consistency defects rather than model-specific interpretation artifacts.
Authors: We agree that the absence of an external validation anchor is a substantive limitation. The manuscript already states explicitly that the same LLM family authored and audited the specifications and calls for replication with dissimilar models and human reviewers. In revision we will expand the discussion section to include additional analysis of possible model-specific interpretation effects and to emphasize how the released audit protocol and locked checklist are intended to support independent verification. We cannot introduce new external data in this revision. revision: partial
-
Referee: Taxonomy development (seven-category post-hoc taxonomy): The taxonomy and its coding rules are derived entirely from the defects found in this study. Without pre-defined criteria, independent validation against other systems, or inter-rater agreement statistics, the taxonomy cannot yet support the claim that the distilled protocol will generalize or that the observed non-monotonic convergence is attributable to the iterative multi-scope process rather than the specific LLM choice.
Authors: The taxonomy is presented as post-hoc and exploratory, with explicit coding rules supplied precisely to enable future independent validation. We do not claim generalizability; the taxonomy functions as an initial categorization derived from the observed defects. We will revise the manuscript to state this more explicitly in both the results and limitations sections, making clear that the taxonomy and the attribution of convergence behavior require testing on additional systems and models. revision: yes
-
Referee: Methodology (single-system design and scope expansion): The claim that single-file review missed defect classes later surfaced by expanded-scope rounds is demonstrated only within this one 7150-line AEGIS system. Absent any comparison arm (human auditors or a dissimilar model family), the attribution of convergence behavior to the iterative, multi-agent audit protocol remains untested and limits the strength of the central empirical contribution.
Authors: We concur that the demonstration of missed defect classes and the observed convergence pattern is confined to this single system. The work is framed throughout as a case study, and the manuscript already notes the need for replication. In the revised version we will strengthen the limitations and discussion sections to address the implications of the single-system design and the potential role of LLM choice in the non-monotonic pattern. The central empirical contribution remains the detailed per-round reporting and the publicly released protocol and checklist. revision: partial
- Providing external validation through human review, inter-rater reliability metrics, or replication with dissimilar model families, which would require new empirical experiments outside the scope of the present single-system case study.
Circularity Check
No significant circularity: empirical case study reports direct observations
full rationale
The manuscript is a single-system empirical case study reporting raw defect counts (51 total, with per-round breakdowns 15/8/12/2/8/1/4/1/0) obtained from nine checklist-driven audit rounds. No derivations, equations, fitted parameters, or predictions are present that could reduce to inputs by construction. The audit protocol is adapted from external sources (Weinberg and Freedman); the paper itself flags the same-LLM-family limitation and calls for external replication. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing premises. The central claims are falsifiable observations from the described process rather than self-referential constructs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Weinberg and Freedman checklist provides a valid structured walkthrough for prompt-specification consistency defects.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearNine sequential audit rounds... surfaced 51 prompt-specification consistency defects... Per-round counts were 15, 8, 12, 2, 8, 1, 4, 1, and 0.
Reference graph
Works this paper leans on
-
[1]
Discussion 4.1. Three Distinct Notions of Review “Single-pass review” is ambiguous. We use three distinct terms: • Single-file review.The auditor reads one specification file at a time without explicit cross-file comparison. By construction, single-file review cannot detect cross-file schema mismatches. 9 of 13 • Initial full-scope pass.The auditor reads ...
-
[2]
Across nine rounds, 51 prompt-specification defects were surfaced and remediated
Conclusions This paper presented a single-system empirical case study of iterative, agent-driven auditing of prompt specifications in a production seven-lane orchestration pipeline. Across nine rounds, 51 prompt-specification defects were surfaced and remediated. The audit terminated when round 9 returned zero findings under the case-study protocol’s one-...
-
[3]
Fagan, M.E. Design and Code Inspections to Reduce Errors in Program Development.IBM Systems Journal 1976,15, 182–211
work page 1976
-
[4]
Software Defect Reduction Top 10 List.Computer2001,34, 135–137
Boehm, B.; Basili, V .R. Software Defect Reduction Top 10 List.Computer2001,34, 135–137
-
[5]
Reviews, Walkthroughs, and Inspections.IEEE Transactions on Software Engineering1984,SE-10, 68–72
Weinberg, G.M.; Freedman, D.P . Reviews, Walkthroughs, and Inspections.IEEE Transactions on Software Engineering1984,SE-10, 68–72
-
[6]
Parnas, D.L. Software Aging. In Proceedings of the Proceedings of the 16th International Conference on Software Engineering (ICSE), Sorrento, Italy, 1994; pp. 279–287
work page 1994
-
[7]
An Analysis of the Requirements Traceability Problem
Gotel, O.C.Z.; Finkelstein, A.C.W. An Analysis of the Requirements Traceability Problem. In Proceedings of the Proceedings of the 1st International Conference on Requirements Engineering (ICRE), Colorado Springs, CO, USA, 1994; pp. 94–101
work page 1994
-
[8]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Wang, X.; Wei, J.; Schuurmans, D.; Le, Q.; Chi, E.; Zhou, D. Self-Consistency Improves Chain of Thought Reasoning in Language Models. In Proceedings of the Proceedings of the International Conference on Learning Representations (ICLR), Kigali, Rwanda, 2023
work page 2023
-
[9]
Self-Refine: Iterative Refinement with Self-Feedback
Madaan, A.; Tandon, N.; Gupta, P .; Hallinan, S.; Gao, L.; Wiegreffe, S.; Alon, U.; Dziri, N.; Prabhumoye, S.; Yang, Y.; et al. Self-Refine: Iterative Refinement with Self-Feedback. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), New Orleans, LA, USA, 2023
work page 2023
-
[10]
He, J.; Treude, C.; Lo, D. LLM-Based Multi-Agent Systems for Software Engineering: Literature Review, Vision and the Road Ahead, 2024, [arXiv:cs.SE/2404.04834]
-
[11]
Why Do Multi-Agent LLM Systems Fail?
Cemri, M.; Pan, M.Z.; Yang, S.; et al. Why Do Multi-Agent LLM Systems Fail?, 2025, [arXiv:cs.AI/2503.13657]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Leveraging LLMs for the Quality Assurance of Software Requirements, 2024, [arXiv:cs.SE/2408.10886]
Lubos, S.; Felfernig, A.; Tran, T.N.T.; Garber, D.; El Mansi, M.; Polat Erdeniz, S.; Le, V .M. Leveraging LLMs for the Quality Assurance of Software Requirements, 2024, [arXiv:cs.SE/2408.10886]. RE 2024 — Requirements Engineering Next! track
-
[13]
Promptware engineering: Software engineering for prompt-enabled systems,
Chen, Z.; Wang, C.; Sun, W.; Liu, X.; Zhang, J.M.; Liu, Y. Promptware Engineering: Software Engineering for Prompt-Enabled Systems, 2025, [arXiv:cs.SE/2503.02400]. Accepted by ACM Transactions on Software Engineering and Methodology (TOSEM)
-
[14]
A Blueprint for AI-Driven Software Quality: Integrating LLMs with Established Standards
Patil, A. A Blueprint for AI-Driven Software Quality: Integrating LLMs with Established Standards, 2025, [arXiv:cs.SE/2505.13766]. Earlier versions of this preprint circulated as "Advancing Software Quality: A Standards-Focused Review of LLM-Based Assurance Techniques."
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Akshathala, S.; Adnan, B.; Ramesh, M.; Vaidhyanathan, K.; Muhammed, B.; Parthasarathy, K. Beyond Task Completion: An Assessment Framework for Evaluating Agentic AI Systems, 2025, [arXiv:cs.AI/2512.12791]
-
[16]
Li, J.; Su, Y.; Lyu, M.R. From Laboratory to Real-World Applications: Benchmarking Agentic Code Reasoning at the Repository Level, 2026, [arXiv:cs.SE/2601.03731]. Introduces the RepoReason benchmark. Accepted by ACL 2026 (main track)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
Yang, J.; Jimenez, C.E.; Wettig, A.; Lieret, K.; Yao, S.; Narasimhan, K.; Press, O. SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering, 2024, [arXiv:cs.SE/2405.15793]. 13 of 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
AgentBench: Evaluating LLMs as Agents
Liu, X.; Yu, H.; Zhang, H.; Xu, Y.; Lei, X.; Lai, H.; Gu, Y.; Ding, H.; Men, K.; Yang, K.; et al. AgentBench: Evaluating LLMs as Agents. In Proceedings of the Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 2024
work page 2024
-
[19]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Hong, S.; Zhuge, M.; Chen, J.; Zheng, X.; Cheng, Y.; Wang, J.; Zhang, C.; Wang, Z.; Yau, S.K.S.; Lin, Z.; et al. MetaGPT: Meta Programming for a Multi-Agent Collaborative Framework, 2023, [arXiv:cs.AI/2308.00352]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Naqvi, S.; Baqar, M.; Mohammad, N.A. The Rise of Agentic Testing: Multi-Agent Systems for Robust Software Quality Assurance, 2026, [arXiv:cs.SE/2601.02454]
-
[21]
Calboreanu, E. Closed-Loop Autonomous Software Development via Jira-Integrated Backlog Orchestration: A Case Study in Deterministic Control and Safety-Constrained Automation, 2026, [arXiv:cs.SE/2604.05000]. Preprint, Swift North AI Lab, The Swift Group, LLC
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Context Engineering: A Methodology for Structured Human-AI Collaboration, 2026
Calboreanu, E. Context Engineering: A Methodology for Structured Human-AI Collaboration, 2026. Working Paper v2.5, Capitol Technology University. ORCID: https://orcid.org/0009-0008-9194-0589
work page 2026
-
[23]
MANDATE: A Tolerance-Based Framework for Autonomous Agent Task Specification, 2026
Calboreanu, E. MANDATE: A Tolerance-Based Framework for Autonomous Agent Task Specification, 2026. SSRN paper 6170328. Title cited per the SSRN canonical entry. The acronym MANDATE is the project name; an alternative expansion appears in earlier companion artifacts., https://doi.org/10.2139/ssrn.6170328
-
[24]
LATTICE: A Governance-First Architecture for Authorized Autonomous AI Operations, 2026
Calboreanu, E. LATTICE: A Governance-First Architecture for Authorized Autonomous AI Operations, 2026. SSRN paper 6151128. Title cited per the SSRN canonical entry. The acronym LATTICE is the project name; an alternative expansion appears in earlier companion artifacts., https://doi.org/10.2139/ssrn.6151128
-
[25]
Calboreanu, E. TRACE: A Governance-First Execution Framework Providing Architectural Assurance for Autonomous AI Operations, 2026. SSRN paper 6212818. Title cited per the SSRN canonical entry. The acronym TRACE is the project name; an alternative expansion appears in earlier companion artifacts., https://doi.org/10.2139/ssrn.6212818
-
[26]
Model Context Protocol Specification, 2024
Anthropic. Model Context Protocol Specification, 2024. Online documentation; accessed 12 May 2026
work page 2024
-
[27]
Runeson, P .; Höst, M. Guidelines for Conducting and Reporting Case Study Research in Software Engineer- ing.Empirical Software Engineering2009,14, 131–164
-
[28]
Wohlin, C.; Runeson, P .; Höst, M.; Ohlsson, M.C.; Regnell, B.; Wesslén, A.Experimentation in Software Engineering; Springer: Berlin, Germany, 2012
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.