Recognition: 2 theorem links
· Lean TheoremManifold Sampling via Entropy Maximization
Pith reviewed 2026-05-13 06:34 UTC · model grok-4.3
The pith
MASEM resamples points to maximize entropy of their empirical distribution, enabling mixing across disconnected constrained manifolds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MASEM performs sampling by repeatedly drawing new points from local samplers and accepting them so as to maximize the entropy of the empirical distribution estimated via k-nearest neighbors. In the mean-field regime the repeated application of this entropy-maximizing resampling drives the empirical distribution toward the maximum-entropy distribution at an exponential rate in the number of steps, without requiring explicit identification or enumeration of the manifold's disconnected components.
What carries the argument
The entropy-maximizing resampling step that uses k-nearest-neighbor density estimation to decide which candidate points to retain.
If this is right
- Sampling proceeds without assuming or detecting the number of disconnected components in the feasible set.
- KL divergence to the target decreases exponentially in the mean-field limit with each resampling iteration.
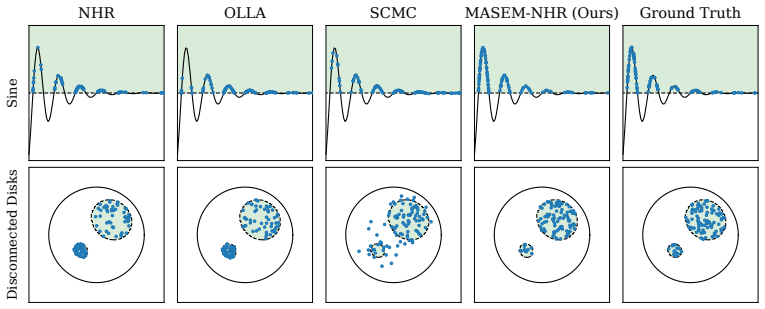
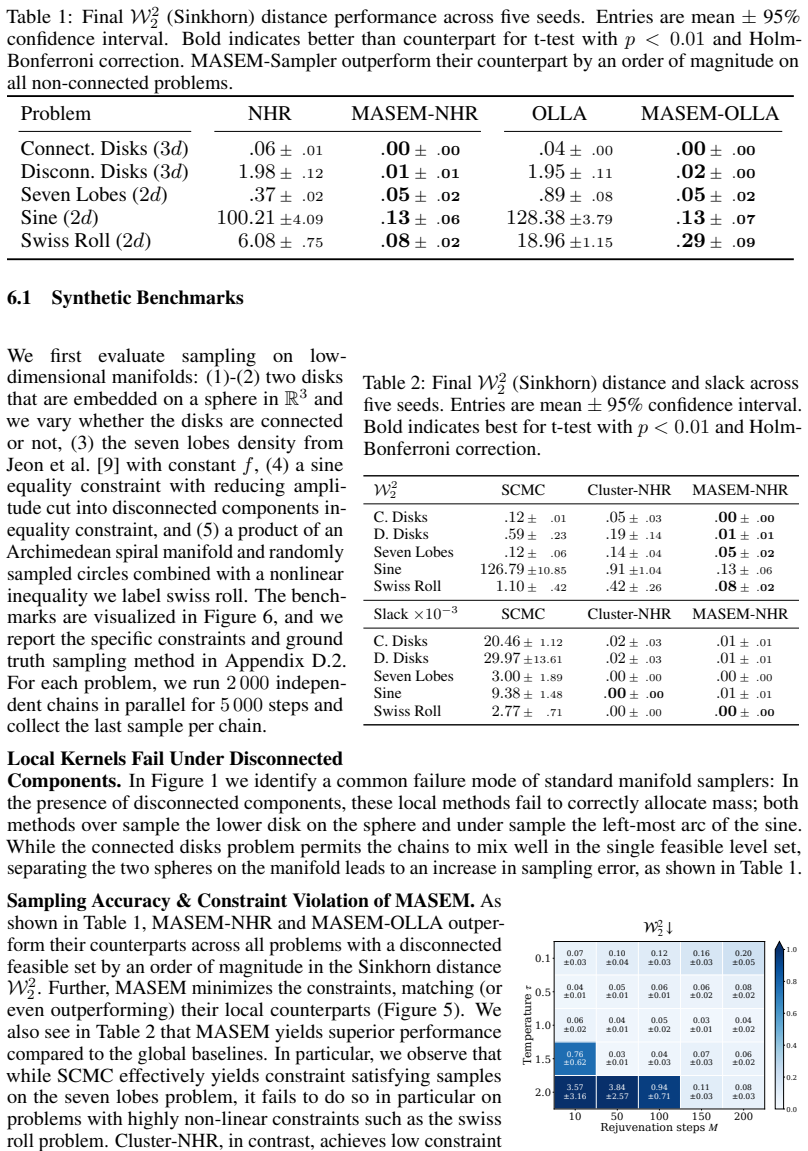
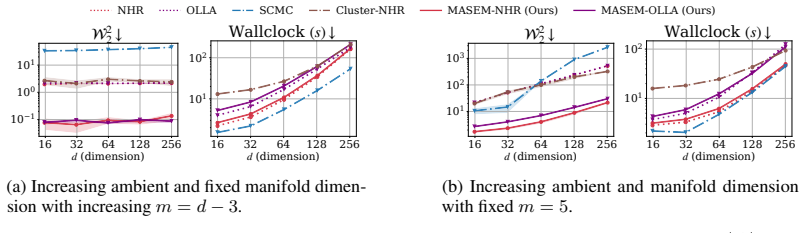
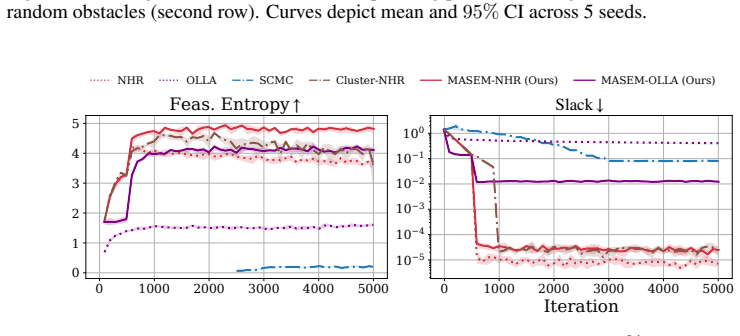
- Sinkhorn distance on synthetic and robotics benchmarks improves by roughly an order of magnitude relative to prior constrained samplers.
- The scheme works with any choice of local sampler and maintains competitive runtime.
Where Pith is reading between the lines
- The same resampling logic could be paired with gradient-informed local proposals to accelerate exploration in high-dimensional problems.
- If kNN entropy estimates remain stable, the method may extend to problems with mixed continuous-discrete constraints.
- In Bayesian optimization pipelines the improved mixing could reduce the number of evaluations needed when the acquisition function has disconnected level sets.
Load-bearing premise
The mean-field limit accurately describes the finite-sample resampling dynamics and k-nearest-neighbor entropy estimation remains reliable on the manifold geometry induced by the constraints.
What would settle it
A controlled mean-field simulation or finite-sample run on a known disconnected manifold in which the KL divergence between the empirical distribution and the maximum-entropy target fails to decrease exponentially over successive resampling steps.
Figures





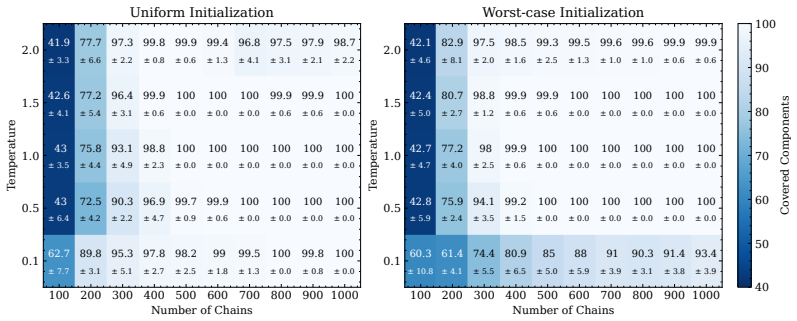

read the original abstract
Sampling from constrained distributions has a wide range of applications, including in Bayesian optimization and robotics. Prior work establishes convergence and feasibility guarantees for constrained sampling, but assumes that the feasible set is connected. However, in practice, the feasible set often decomposes into multiple disconnected components, which makes efficient sampling under constraints challenging. In this paper, we propose MAnifold Sampling via Entropy Maximization (MASEM) for sampling on a manifold with an unknown number of disconnected components, implicitly defined by smooth equality and inequality constraints. The presented method uses a resampling scheme to maximize the entropy of the empirical distribution based on k-nearest neighbor density estimation. We show that, in the mean field, MASEM decreases the KL-divergence between the empirical distribution and the maximum-entropy target exponentially in the number of resampling steps. We instantiate MASEM with multiple local samplers and demonstrate its versatility and efficiency on synthetic and robotics-based benchmarks. MASEM enables fast and scalable mixing across a range of constrained sampling problems, improving over alternatives by an order of magnitude in Sinkhorn distance with competitive runtime.
Editorial analysis
A structured set of objections, weighed in public.
Axiom & Free-Parameter Ledger
free parameters (2)
- k (nearest neighbors)
- number of resampling steps
axioms (2)
- domain assumption The feasible set is a smooth manifold implicitly defined by differentiable equality and inequality constraints.
- ad hoc to paper The mean-field limit applies to the finite-sample resampling dynamics.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearthe resampling weightsw i ∝ε τ i,k induce the map (Φα)c := α1−β c (α∗ c)β / Σj α1−β j (α∗ j)β , β:=τ/p (Proposition 1); D_KL(pαt | pα∗) ≤ C0 (1-τ/p)^{2t} (Theorem 1)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction uncleark-nearest-neighbor density estimator ˆρ(xi)=k/(N Vp ε^p i,k)
Reference graph
Works this paper leans on
-
[1]
Ruqi Zhang, Qiang Liu, and Xin Tong. Sampling in Constrained Domains with Orthogonal- Space Variational Gradient Descent.Advances in Neural Information Processing Systems, 35: 37108–37120, 2022
work page 2022
-
[2]
D. C. Rapaport.The Art of Molecular Dynamics Simulation. Cambridge University Press, Cambridge, 2nd edition, 2004
work page 2004
-
[3]
Zachary Kingston, Mark Moll, and Lydia E. Kavraki. Sampling-Based Methods for Motion Planning with Constraints.Annual Review of Control, Robotics, and Autonomous Systems, 1(1): 159–185, 2018
work page 2018
-
[4]
Sampling Constrained Trajectories Using Composable Diffusion Models
Thomas Power, Rana Soltani-Zarrin, Soshi Iba, and Dmitry Berenson. Sampling Constrained Trajectories Using Composable Diffusion Models. InIROS 2023 Workshop on Differentiable Probabilistic Robotics: Emerging Perspectives on Robot Learning, 2023
work page 2023
-
[5]
Reverse Curriculum Generation for Reinforcement Learning
Carlos Florensa, David Held, Markus Wulfmeier, Michael Zhang, and Pieter Abbeel. Reverse Curriculum Generation for Reinforcement Learning. InConference on Robot Learning, pages 482–495. PMLR, 2017
work page 2017
-
[6]
Constrained Sampling to Guide Universal Manipulation RL.arXiv preprint arXiv:2602.08557, 2026
Marc Toussaint, Cornelius V Braun, Eckart Cobo-Briesewitz, Sayantan Auddy, Armand Jordana, and Justin Carpentier. Constrained Sampling to Guide Universal Manipulation RL.arXiv preprint arXiv:2602.08557, 2026
-
[7]
Stability-Guided Exploration for Diverse Motion Generation, 2026
Eckart Cobo-Briesewitz, Tilman Burghoff, Denis Shcherba, Armand Jordana, and Marc Tous- saint. Stability-Guided Exploration for Diverse Motion Generation, 2026
work page 2026
-
[8]
An Introduction to MCMC for Machine Learning.Machine learning, 50(1):5–43, 2003
Christophe Andrieu, Nando De Freitas, Arnaud Doucet, and Michael I Jordan. An Introduction to MCMC for Machine Learning.Machine learning, 50(1):5–43, 2003
work page 2003
-
[9]
Fast Non-Log-Concave Sampling under Nonconvex Equality and Inequality Constraints with Landing
Kijung Jeon, Michael Muehlebach, and Molei Tao. Fast Non-Log-Concave Sampling under Nonconvex Equality and Inequality Constraints with Landing. InThe Thirty-Ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[10]
Emilio Zappa, Miranda Holmes-Cerfon, and Jonathan Goodman. Monte Carlo on Manifolds: Sampling Densities and Integrating Functions.Communications on Pure and Applied Mathe- matics, 71(12):2609–2647, 2018
work page 2018
-
[11]
Tony Lelièvre, Mathias Rousset, and Gabriel Stoltz. Hybrid Monte Carlo methods for sampling probability measures on submanifolds.Numerische Mathematik, 143(2):379–421, 2019
work page 2019
-
[12]
David E Kaufman and Robert L Smith. Direction Choice for Accelerated Convergence in Hit-and-Run Sampling.Operations Research, 46(1):84–95, 1998
work page 1998
-
[13]
An T Le, Georgia Chalvatzaki, Armin Biess, and Jan R Peters. Accelerating Motion Planning via Optimal Transport.Advances in Neural Information Processing Systems, 36:78453–78482, 2023
work page 2023
-
[14]
Zechu Li, Rickmer Krohn, Tao Chen, Anurag Ajay, Pulkit Agrawal, and Georgia Chalvatzaki. Learning Multimodal Behaviors from Scratch with Diffusion Policy Gradient.Advances in Neural Information Processing Systems, 37:38456–38479, 2024
work page 2024
-
[15]
Discovering Many Diverse Solutions with Bayesian Optimization
Natalie Maus, Kaiwen Wu, David Eriksson, and Jacob Gardner. Discovering Many Diverse Solutions with Bayesian Optimization. InInternational Conference on Artificial Intelligence and Statistics, pages 1779–1798. PMLR, 2023. 10
work page 2023
-
[16]
Don O Loftsgaarden and Charles P Quesenberry. A Nonparametric Estimate of a Multivariate Density Function.The Annals of Mathematical Statistics, 36(3):1049–1051, 1965
work page 1965
-
[17]
Sequentially Constrained Monte Carlo.Computational Statistics & Data Analysis, 97:98–113, 2016
Shirin Golchi and David A Campbell. Sequentially Constrained Monte Carlo.Computational Statistics & Data Analysis, 97:98–113, 2016
work page 2016
-
[18]
Tony Lelievre, Mathias Rousset, and Gabriel Stoltz. Langevin dynamics with constraints and computation of free energy differences.Mathematics of computation, 81(280):2071–2125, 2012
work page 2071
-
[19]
A Family of MCMC Methods on Implicitly Defined Manifolds
Marcus Brubaker, Mathieu Salzmann, and Raquel Urtasun. A Family of MCMC Methods on Implicitly Defined Manifolds. InArtificial Intelligence and Statistics, pages 161–172. PMLR, 2012
work page 2012
-
[20]
Geodesic Monte Carlo on Embedded Manifolds.Scandina- vian Journal of Statistics, 40(4):825–845, 2013
Simon Byrne and Mark Girolami. Geodesic Monte Carlo on Embedded Manifolds.Scandina- vian Journal of Statistics, 40(4):825–845, 2013
work page 2013
-
[21]
Sébastien Bubeck, Ronen Eldan, and Joseph Lehec. Sampling from a Log-Concave Distribution with Projected Langevin Monte Carlo.Discrete & Computational Geometry, 59(4):757–783, 2018
work page 2018
-
[22]
Yunbum Kook, Yin-Tat Lee, Ruoqi Shen, and Santosh Vempala. Sampling with Riemannian Hamiltonian Monte Carlo in a Constrained Space.Advances in neural information processing systems, 35:31684–31696, 2022
work page 2022
-
[23]
Constrained Stein Variational Trajectory Optimization
Thomas Power and Dmitry Berenson. Constrained Stein Variational Trajectory Optimization. IEEE Transactions on Robotics, 40:3602–3619, 2024
work page 2024
-
[24]
Marc Toussaint, Cornelius V Braun, and Joaquim Ortiz-Haro. NLP Sampling: Combining MCMC and NLP Methods for Diverse Constrained Sampling.arXiv preprint arXiv:2407.03035, 2024
-
[25]
Francisco J Aragón, Miguel A Goberna, Marco A López, and Margarita ML Rodríguez.Non- linear Optimization. Springer, 2019
work page 2019
- [26]
-
[27]
Gérard Biau and Luc Devroye.Lectures on the Nearest Neighbor Method, volume 246. Springer, 2015
work page 2015
-
[28]
R. Andreani, G. Haeser, R.W. Prado, and L.D. Secchin. Primal-dual global convergence of an augmented Lagrangian method under the error bound condition. Technical report, University of São Paulo, 2025
work page 2025
-
[29]
Allyn and Beacon, Boston, 1966
James Dugundji.Topology. Allyn and Beacon, Boston, 1966
work page 1966
-
[30]
Linear Convergence of Gradient and Proximal- Gradient Methods Under the Polyak-Łojasiewicz Condition
Hamed Karimi, Julie Nutini, and Mark Schmidt. Linear Convergence of Gradient and Proximal- Gradient Methods Under the Polyak-Łojasiewicz Condition. In Paolo Frasconi, Niels Landwehr, Giuseppe Manco, and Jilles Vreeken, editors,Machine Learning and Knowledge Discovery in Databases, pages 795–811. Springer International Publishing, 2016
work page 2016
-
[31]
Sur les équations algébriques ayant toutes leurs racines réelles.Mathematica, 9(129-145):20, 1935
Tiberiu Popoviciu. Sur les équations algébriques ayant toutes leurs racines réelles.Mathematica, 9(129-145):20, 1935
work page 1935
-
[32]
Martin J Wainwright and Michael I Jordan. Graphical Models, Exponential Families, and Variational Inference.Foundations and Trends® in Machine Learning, 1(1-2):1–305, 2008
work page 2008
-
[33]
JAX: Composable transformations of Python+NumPy programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Yash Katariya, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman- Milne, and Qiao Zhang. JAX: Composable transformations of Python+NumPy programs, 2018. 11
work page 2018
-
[34]
L. F. Kozachenko and N. N. Leonenko. Sample Estimate of the Entropy of a Random Vector. Problems of Information Transmission, 23(1-2):95–101, 1987
work page 1987
-
[35]
Richard M. Murray, Zexiang Li, and S. Shankar Sastry.A Mathematical Introduction to Robotic Manipulation. CRC Press, Boca Raton, 1994. ISBN 978-1-315-13637-0
work page 1994
-
[36]
Michael Laskin, Hao Liu, Xue Bin Peng, Denis Yarats, Aravind Rajeswaran, and Pieter Abbeel. CIC: Contrastive Intrinsic Control for Unsupervised Skill Discovery.arXiv preprint arXiv:2202.00161, 2022
-
[37]
Thomas Beret, Richard Samworth, and Ming Yuan. Efficient multivariate entropy estimation via k-nearest neighbour distances.The Annals of Statistics, 47(1):288–318, 2019
work page 2019
-
[38]
Practical Bayesian Optimization of Machine Learning Algorithms
Jasper Snoek, Hugo Larochelle, and Ryan Adams. Practical Bayesian Optimization of Machine Learning Algorithms. In F. Pereira, C.J. Burges, L. Bottou, and K. Weinberger, editors,Advances in Neural Information Processing Systems, volume 25. Curran Associates, Inc., 2012
work page 2012
-
[39]
Approximate Nearest Neighbour Search on Dynamic Datasets: An Investigation
Ben Harwood, Amir Dezfouli, Iadine Chades, and Conrad Sanderson. Approximate Nearest Neighbour Search on Dynamic Datasets: An Investigation. In Mingming Gong, Yiliao Song, Yun Sing Koh, Wei Xiang, and Derui Wang, editors,AI 2024: Advances in Artificial Intelligence, volume 15443, pages 95–106. Springer Nature Singapore, 2025
work page 2024
-
[40]
the met- ric cannot distinguish between a ground truth and a non-ground truth distribution
Qiang Liu and Dilin Wang. Stein Variational Gradient Descent: A General Purpose Bayesian Inference Algorithm. In D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 29. Curran Associates, Inc., 2016. 12 A Formal Lemmas and Proofs We begin by formalizing Lemma 1 introduced in Section...
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.