Recognition: 2 theorem links
· Lean TheoremGuidedVLA: Specifying Task-Relevant Factors via Plug-and-Play Action Attention Specialization
Pith reviewed 2026-05-13 03:47 UTC · model grok-4.3
The pith
GuidedVLA improves robot task success by manually guiding individual attention heads in the action decoder to focus on specific task-relevant factors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
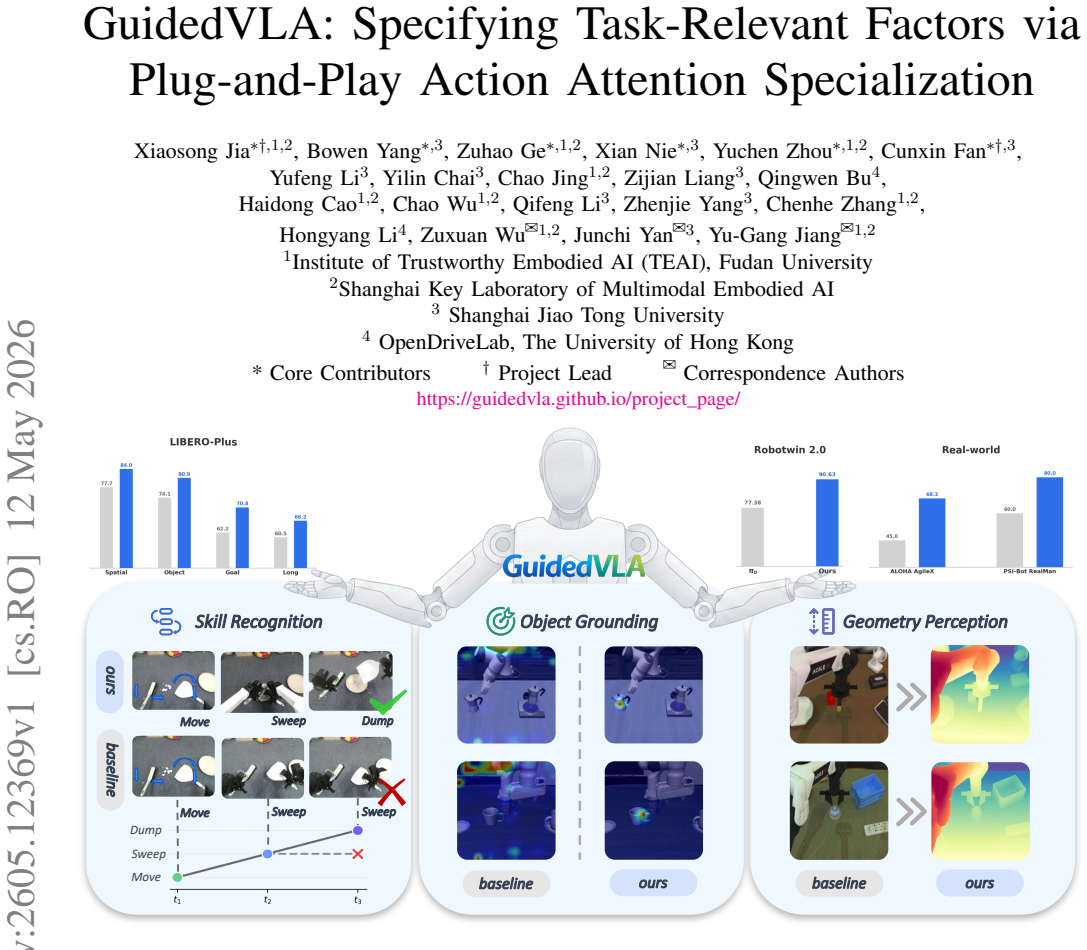
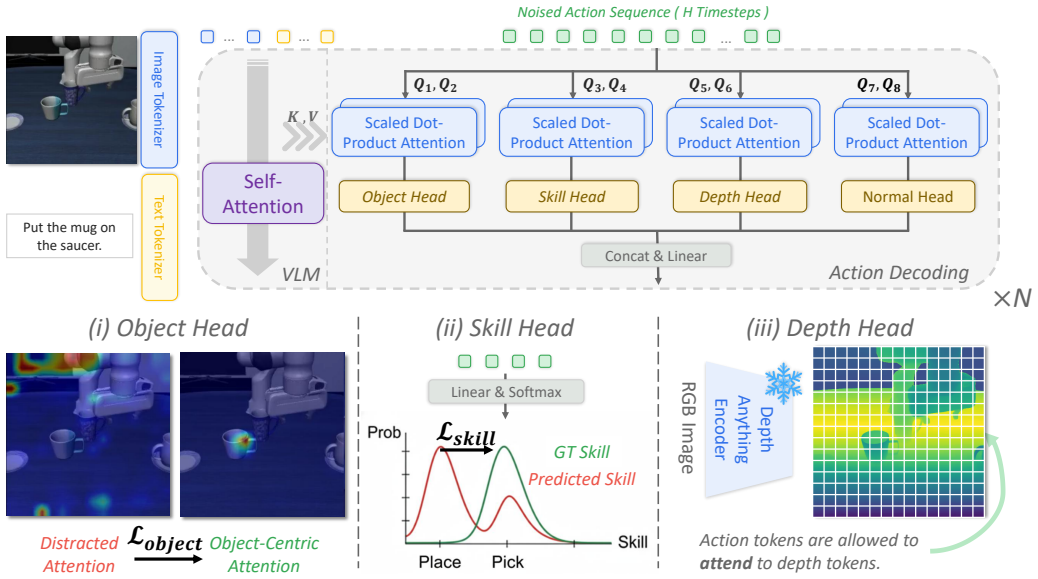
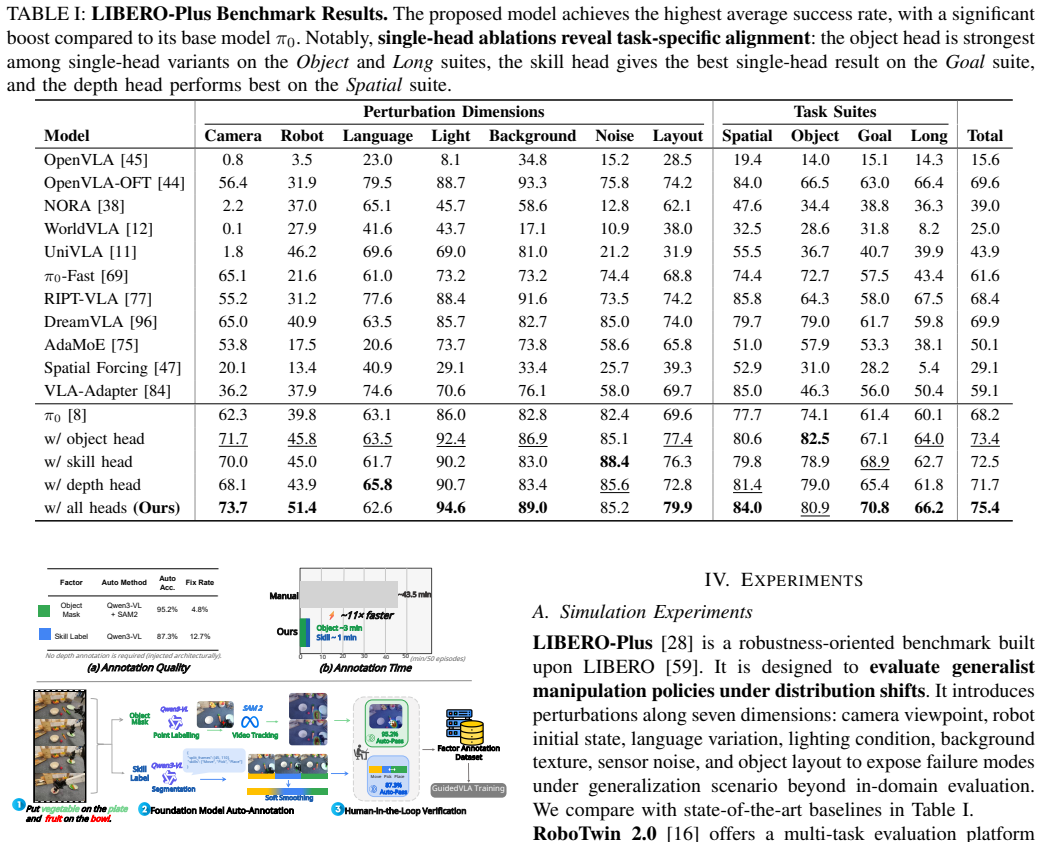
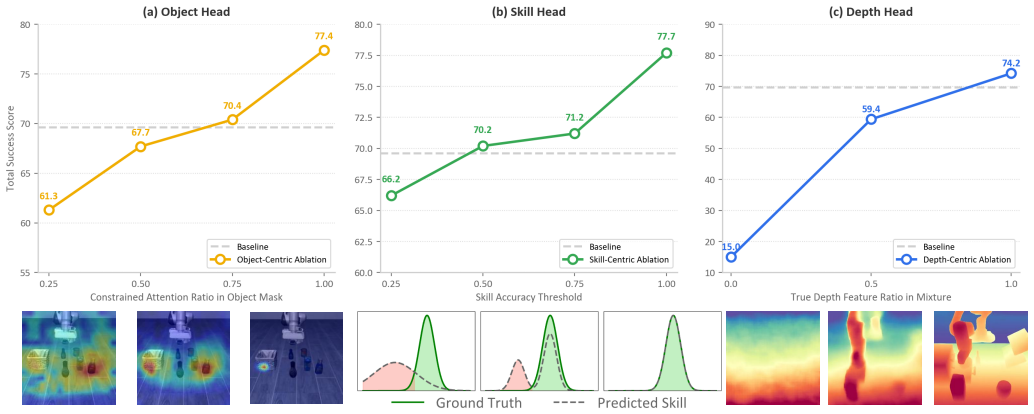
GuidedVLA manually guides the action generation in VLA models by supervising individual attention heads with manually defined auxiliary signals to capture distinct task-relevant factors, including object grounding, spatial geometry, and temporal skill logic. This results in improved success rates across simulation and real-robot experiments in both in-domain and out-of-domain settings, with the specialized factors yielding decoupled, high-quality features that correlate positively with task performance.
What carries the argument
Plug-and-play action attention specialization, where individual attention heads are supervised by auxiliary signals to capture distinct task factors without interfering with the main action objective.
If this is right
- Explicit supervision of attention heads reduces overfitting to environmental noise and visual shortcuts.
- Decoupled features from specialized heads improve generalization to new environments.
- The quality of auxiliary-guided factors directly impacts overall task success.
- Action decoders can be designed as modular assemblies rather than monolithic learners.
Where Pith is reading between the lines
- Similar specialization could be applied to other modalities in multimodal models beyond robotics.
- Automating the definition of auxiliary signals might reduce the manual effort required.
- Testing on more complex tasks could reveal limits of the three-head setup.
- Integration with other VLA improvements might compound the benefits.
Load-bearing premise
That manually defined auxiliary signals can be supplied to individual attention heads to capture distinct factors without the heads interfering with one another or the main action objective.
What would settle it
An experiment where adding the specialized heads with auxiliary signals shows no improvement or decrease in success rates compared to the baseline VLA model.
Figures




























read the original abstract
Vision-Language-Action (VLA) models aim for general robot learning by aligning action as a modality within powerful Vision-Language Models (VLMs). Existing VLAs rely on end-to-end supervision to implicitly enable the action decoding process to learn task-relevant features. However, without explicit guidance, these models often overfit to spurious correlations, such as visual shortcuts or environmental noise, limiting their generalization. In this paper, we introduce GuidedVLA, a framework designed to manually guide the action generation to focus on task-relevant factors. Our core insight is to treat the action decoder not as a monolithic learner, but as an assembly of functional components. Individual attention heads are supervised by manually defined auxiliary signals to capture distinct factors. As an initial study, we instantiate this paradigm with three specialized heads: object grounding, spatial geometry, and temporal skill logic. Across simulation and real-robot experiments, GuidedVLA improves success rates in both in-domain and out-of-domain settings compared to strong VLA baselines. Finally, we show that the quality of these specialized factors correlates positively with task performance and that our mechanism yields decoupled, high-quality features. Our results suggest that explicitly guiding action-decoder learning is a promising direction for building more robust and general VLA models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GuidedVLA, a framework for Vision-Language-Action (VLA) models that treats the action decoder as modular components by supervising individual attention heads with manually defined auxiliary signals to capture distinct task-relevant factors (object grounding, spatial geometry, temporal skill logic). It claims this explicit guidance reduces overfitting to spurious correlations and yields improved success rates over strong VLA baselines in both in-domain and out-of-domain settings across simulation and real-robot experiments, with the quality of specialized factors shown to correlate positively with performance and produce decoupled features.
Significance. If the empirical improvements hold under rigorous validation, the work would be significant for robot learning by offering a practical plug-and-play mechanism to inject task-specific inductive biases into large VLAs without full retraining. The modular attention specialization could enhance interpretability and robustness, addressing a key limitation of end-to-end VLA training. The reported correlation between factor quality and task success provides a useful supporting observation for future extensions.
major comments (2)
- [§3.2] §3.2 (Specialized Attention Heads): The auxiliary signals are described as manually defined external inputs assigned to specific heads, but no formulation of the auxiliary losses, no equations for how they are integrated into the attention computation, and no mechanism (e.g., masking, routing, or weighting) to prevent interference with the primary action objective are provided. This is load-bearing for the central claim that the heads capture decoupled, task-relevant factors without degrading main-task performance.
- [§4] §4 (Experiments): No ablation results isolate the contribution of attention-head specialization from other training changes or from the choice of the three specific factors; the reported success-rate gains cannot be attributed to the proposed mechanism. This undermines the out-of-domain generalization claim.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief equation or diagram illustrating the plug-and-play insertion of auxiliary signals into the attention heads.
- [§3] Notation for the three specialized heads is introduced informally; consistent symbols and a table summarizing their auxiliary targets would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. We appreciate the identification of areas where technical clarity and experimental rigor can be strengthened. We have revised the manuscript to address both major comments by adding the missing formulations and new ablation studies. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Specialized Attention Heads): The auxiliary signals are described as manually defined external inputs assigned to specific heads, but no formulation of the auxiliary losses, no equations for how they are integrated into the attention computation, and no mechanism (e.g., masking, routing, or weighting) to prevent interference with the primary action objective are provided. This is load-bearing for the central claim that the heads capture decoupled, task-relevant factors without degrading main-task performance.
Authors: We agree that the original §3.2 description was insufficiently precise on these points. In the revised manuscript we have expanded this section with: (i) explicit formulations of the three auxiliary losses (cross-entropy for object grounding, L2 regression for spatial geometry, and next-token prediction for temporal skill logic); (ii) the integration equation L_total = L_action + λ ∑ L_aux_i with the chosen λ schedule; and (iii) the head-masking procedure that routes each auxiliary signal exclusively to its assigned attention head during the forward pass while leaving the primary action loss unaffected. These additions directly support the claim of decoupled factors without performance degradation. revision: yes
-
Referee: [§4] §4 (Experiments): No ablation results isolate the contribution of attention-head specialization from other training changes or from the choice of the three specific factors; the reported success-rate gains cannot be attributed to the proposed mechanism. This undermines the out-of-domain generalization claim.
Authors: We acknowledge that the original experiments did not include targeted ablations isolating the specialization mechanism. In the revised version we have added two new ablation suites: (1) variants in which individual specialized heads are disabled one at a time, and (2) comparisons using alternative auxiliary factor sets. The updated results show that removing any specialized head measurably reduces both in-domain and out-of-domain success rates, while the full three-head configuration yields the reported gains. These controls allow the performance improvements to be attributed to the attention specialization rather than other training differences. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external validation
full rationale
The paper presents GuidedVLA as an empirical framework that assigns manually defined auxiliary signals to specific attention heads and reports measured success-rate gains over baselines in simulation and real-robot experiments. No equations, derivations, or first-principles predictions appear that would reduce the reported improvements to quantities defined by the same inputs or by self-citation chains. The auxiliary signals are described as external manual inputs, and performance is assessed via independent test sets, satisfying the criteria for a self-contained, non-circular result.
Axiom & Free-Parameter Ledger
invented entities (1)
-
specialized attention heads for object grounding, spatial geometry, and temporal skill logic
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Individual attention heads are supervised by manually defined auxiliary signals to capture distinct factors... three specialized heads: object grounding, spatial geometry, and temporal skill logic.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ControlNet-style residual adapter... ZeroConv... A_L ← ZeroConv(A_specified_L) + A_main_L
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[2]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Haus- man, et al. Do as i can, not as i say: Ground- ing language in robotic affordances.arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Vineet Bhat, Yu-Hsiang Lan, Prashanth Krishnamurthy, Ramesh Karri, and Farshad Khorrami. 3d cavla: Leveraging depth and 3d context to generalize vision language action models for unseen tasks.arXiv preprint arXiv:2505.05800, 2025
-
[6]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
In9th Annual Conference on Robot Learning, 2025
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y Galliker, et al.π 0.5: A vision-language-action model with open- world generalization. In9th Annual Conference on Robot Learning, 2025
work page 2025
-
[8]
Kevin Black, Noah Brown, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π 0: A vision-language-action flow model for general robot control. InRSS, 2025
work page 2025
-
[9]
Kevin Black, Manuel Y Galliker, and Sergey Levine. Real-time execution of action chunking flow policies. arXiv preprint arXiv:2506.07339, 2025
-
[10]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yev- gen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, Deli Zhao, and Hao Chen. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Alexandre Chapin, Emmanuel Dellandréa, and Liming Chen. Storm: Slot-based task-aware object-centric rep- resentation for robotic manipulation.arXiv preprint arXiv:2601.20381, 2026
-
[14]
Jiayi Chen, Wenxuan Song, Pengxiang Ding, Ziyang Zhou, Han Zhao, Feilong Tang, Donglin Wang, and Haoang Li. Unified diffusion vla: Vision-language- action model via joint discrete denoising diffusion pro- cess.arXiv preprint arXiv:2511.01718, 2025
-
[15]
Ratliff, Jiafei Duan, Dieter Fox, and Ranjay Krishna
Shirui Chen, Cole Harrison, Ying-Chun Lee, Angela Jin Yang, Zhongzheng Ren, Lillian J. Ratliff, Jiafei Duan, Dieter Fox, and Ranjay Krishna. Topreward: Token probabilities as hidden zero-shot rewards for robotics. arXiv preprint arXiv:2602.19313, 2026
-
[16]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, Weiliang Deng, Yubin Guo, Tian Nian, Xuanbing Xie, Qiangyu Chen, Kailun Su, Tianling Xu, Guodong Liu, Mengkang Hu, Huan ang Gao, Kaixuan Wang, Zhixuan Liang, Yusen Qin, Xi- aokang Yang, Ping Luo, and Yao Mu. Robotwin 2.0: A scalable...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Baiye Cheng, Tianhai Liang, Suning Huang, Maanping Shao, Feihong Zhang, Botian Xu, Zhengrong Xue, and Huazhe Xu. Moe-dp: An moe-enhanced diffusion policy for robust long-horizon robotic manipulation with skill decomposition and failure recovery.arXiv preprint arXiv:2511.05007, 2025
-
[18]
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shu- ran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
work page 2025
-
[19]
arXiv preprint arXiv:2508.08113 (2025)
Yinpei Dai, Jayjun Lee, Yichi Zhang, Ziqiao Ma, Jed Yang, Amir Zadeh, Chuan Li, Nima Fazeli, and Joyce Chai. Aimbot: A simple auxiliary visual cue to enhance spatial awareness of visuomotor policies.arXiv preprint arXiv:2508.08113, 2025
-
[20]
Robonet: Large-scale multi-robot learning,
Sudeep Dasari, Frederik Ebert, Stephen Tian, Suraj Nair, Bernadette Bucher, Karl Schmeckpeper, Siddharth Singh, Sergey Levine, and Chelsea Finn. Robonet: Large-scale multi-robot learning.arXiv preprint arXiv:1910.11215, 2019
-
[21]
Causal confusion in imitation learning.Advances in neural information processing systems, 32, 2019
Pim De Haan, Dinesh Jayaraman, and Sergey Levine. Causal confusion in imitation learning.Advances in neural information processing systems, 32, 2019
work page 2019
-
[22]
Shengliang Deng, Mi Yan, Yixin Zheng, Jiayi Su, Wen- hao Zhang, Xiaoguang Zhao, Heming Cui, Zhizheng Zhang, and He Wang. Stereovla: Enhancing vision- language-action models with stereo vision.arXiv preprint arXiv:2512.21970, 2025
-
[23]
Palm-e: An embodied multimodal language model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model. In International Conference on Machine Learning, pages 8469–8488. PMLR, 2023
work page 2023
-
[24]
Bridgedata v2: A dataset for robot learning at scale, 2024
Frederik Ebert et al. Bridgedata v2: A dataset for robot learning at scale.arXiv preprint arXiv:2308.12952, 2023
-
[25]
Interleave-vla: Enhancing robot manipulation with interleaved image- text instructions
Cunxin Fan, Xiaosong Jia, Yihang Sun, Yixiao Wang, Jianglan Wei, Ziyang Gong, Xiangyu Zhao, Masayoshi Tomizuka, Xue Yang, Junchi Yan, et al. Interleave-vla: Enhancing robot manipulation with interleaved image- text instructions. InICLR, 2026
work page 2026
-
[26]
Qingyu Fan, Zhaoxiang Li, Yi Lu, Wang Chen, Qiu Shen, Xiao-xiao Long, Yinghao Cai, Tao Lu, Shuo Wang, and Xun Cao. Peafowl: Perception-enhanced multi-view vision-language-action for bimanual manip- ulation.arXiv preprint arXiv:2601.17885, 2026
-
[27]
Learning skills from action-free videos
Hung-Chieh Fang, Kuo-Han Hung, Chu-Rong Chen, Po-Jung Chou, Chun-Kai Yang, Po-Chen Ko, Yu- Chiang Wang, Yueh-Hua Wu, Min-Hung Chen, and Shao-Hua Sun. Learning skills from action-free videos. arXiv preprint arXiv:2512.20052, 2025
-
[28]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
Senyu Fei, Siyin Wang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, et al. Libero-plus: In-depth robustness anal- ysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Robert Geirhos, Patricia Rubisch, Claudio Michaelis, Matthias Bethge, Felix A Wichmann, and Wieland Brendel. Imagenet-trained cnns are biased towards texture; increasing shape bias improves accuracy and robustness. InInternational conference on learning representations, 2018
work page 2018
-
[30]
Shortcut learning in deep neural networks.Nature Machine Intelligence, 2 (11):665–673, 2020
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. Shortcut learning in deep neural networks.Nature Machine Intelligence, 2 (11):665–673, 2020
work page 2020
-
[31]
Octo: An open- source generalist robot policy
Dibya Ghosh, Homer Rich Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, et al. Octo: An open- source generalist robot policy. InRobotics: Science and Systems, 2024
work page 2024
-
[32]
Siddhant Haldar and Lerrel Pinto. Point policy: Unify- ing observations and actions with key points for robot manipulation.arXiv preprint arXiv:2502.20391, 2025
-
[33]
Spot: Se(3) pose trajectory diffusion for object-centric manipulation
Cheng-Chun Hsu, Bowen Wen, Jie Xu, Yashraj Narang, Xiaolong Wang, Yuke Zhu, Joydeep Biswas, and Stan Birchfield. Spot: Se(3) pose trajectory diffusion for object-centric manipulation. In2025 IEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 4853–4860, 2025. doi: 10.1109/ICRA55743. 2025.11127562. arXiv:2411.00965
-
[34]
Lora: Low-rank adaptation of large lan- guage models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large lan- guage models.ICLR, 1(2):3, 2022
work page 2022
-
[35]
Skill-aware diffusion for generalizable robotic manipulation.arXiv preprint arXiv:2601.11266, 2026
Aoshen Huang, Jiaming Chen, Jiyu Cheng, Ran Song, Wei Pan, and Wei Zhang. Skill-aware diffusion for generalizable robotic manipulation.arXiv preprint arXiv:2601.11266, 2026
-
[36]
Rekep: Spatio-temporal rea- soning of relational keypoint constraints for robotic manipulation
Wenlong Huang, Chen Wang, Yunzhu Li, Ruohan Zhang, and Li Fei-Fei. Rekep: Spatio-temporal rea- soning of relational keypoint constraints for robotic manipulation. InConference on Robot Learning, pages 4573–4602. PMLR, 2025
work page 2025
-
[37]
Wenlong Huang, Yu-Wei Chao, Arsalan Mousavian, Ming-Yu Liu, Dieter Fox, Kaichun Mo, and Li Fei-Fei. Pointworld: Scaling 3d world models for in-the-wild robotic manipulation.arXiv preprint arXiv:2601.03782, 2026
-
[38]
Chia-Yu Hung, Qi Sun, Pengfei Hong, Amir Zadeh, Chuan Li, U Tan, Navonil Majumder, Soujanya Poria, et al. Nora: A small open-sourced generalist vision language action model for embodied tasks.arXiv preprint arXiv:2504.19854, 2025
-
[39]
Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J Davison. Rlbench: The robot learning bench- mark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020
work page 2020
-
[40]
Galaxea open-world dataset and g0 dual-system vla model.arXiv preprint arXiv:2509.00576,
Tao Jiang, Tianyuan Yuan, Yicheng Liu, Chenhao Lu, Jianning Cui, Xiao Liu, Shuiqi Cheng, Jiyang Gao, Huazhe Xu, and Hang Zhao. Galaxea open-world dataset and g0 dual-system vla model.arXiv preprint arXiv:2509.00576, 2025
-
[41]
AsyncVLA: Asynchronous Flow Matching for Vision-Language-Action Models
Yuhua Jiang, Shuang Cheng, Yan Ding, Feifei Gao, and Biqing Qi. Asyncvla: Asynchronous flow match- ing for vision-language-action models.arXiv preprint arXiv:2511.14148, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
VIMA : General robot manipulation with multimodal prompts
Yunfan Jiang, Agrim Gupta, Zichen Zhang, Guanzhi Wang, Yongqiang Dou, Yanjun Chen, Li Fei-Fei, Anima Anandkumar, Yuke Zhu, and Linxi Fan. Vima: General robot manipulation with multimodal prompts.arXiv preprint arXiv:2210.03094, 2(3):6, 2022
-
[43]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ash- win Balakrishna, Sudeep Dasari, Siddharth Karam- cheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset. arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Openvla: An open-source vision-language- action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, et al. Openvla: An open-source vision-language- action model. InConference on Robot Learning, pages 2679–2713. PMLR, 2025
work page 2025
-
[46]
Seungjae Lee, Yoonkyo Jung, Inkook Chun, Yao-Chih Lee, Zikui Cai, Hongjia Huang, Aayush Talreja, Tan Dat Dao, Yongyuan Liang, Jia-Bin Huang, et al. Trace- gen: World modeling in 3d trace space enables learn- ing from cross-embodiment videos.arXiv preprint arXiv:2511.21690, 2025
-
[47]
Spatial forcing: Implicit spatial repre- sentation alignment for vision-language-action model
Fuhao Li, Wenxuan Song, Han Zhao, Jingbo Wang, Pengxiang Ding, Donglin Wang, Long Zeng, and Haoang Li. Spatial forcing: Implicit spatial repre- sentation alignment for vision-language-action model. InInternational Conference on Learning Represen- tations, 2026. URL https://openreview.net/forum?id= euMVC1DO4k
work page 2026
-
[48]
Guangrun Li, Yaoxu Lyu, Zhuoyang Liu, Chengkai Hou, Jieyu Zhang, and Shanghang Zhang. H2r: A human-to-robot data augmentation for robot pre- training from videos.arXiv preprint arXiv:2505.11920, 2025
-
[49]
Language-guided object-centric diffusion policy for generalizable and collision-aware manipulation
Hang Li, Qian Feng, Zhi Zheng, Jianxiang Feng, Zhaopeng Chen, and Alois Knoll. Language-guided object-centric diffusion policy for generalizable and collision-aware manipulation. In2025 IEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 12834–12841. IEEE, 2025
work page 2025
-
[50]
Coa-vla: Improving vision-language-action models via visual-text chain-of- affordance
Jinming Li, Yichen Zhu, Zhibin Tang, Junjie Wen, Minjie Zhu, Xiaoyu Liu, Chengmeng Li, Ran Cheng, Yaxin Peng, Yan Peng, et al. Coa-vla: Improving vision-language-action models via visual-text chain-of- affordance. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 9759– 9769, 2025
work page 2025
-
[51]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International conference on machine learning, pages 19730–19742. PMLR, 2023
work page 2023
-
[52]
Bridgevla: Input-output alignment for efficient 3d manipulation learning with vision-language models
Peiyan Li, Yixiang Chen, Hongtao Wu, Xiao Ma, Xiangnan Wu, Yan Huang, Liang Wang, Tao Kong, and Tieniu Tan. Bridgevla: Input-output alignment for efficient 3d manipulation learning with vision-language models.arXiv preprint arXiv:2506.07961, 2025
-
[53]
Ziwen Li, Xin Wang, Hanlue Zhang, Runnan Chen, Runqi Lin, Xiao He, Han Huang, Yandong Guo, Fakhri Karray, Tongliang Liu, et al. Posa-vla: Enhancing action generation via pose-conditioned anchor attention.arXiv preprint arXiv:2512.03724, 2025
-
[54]
Skilldiffuser: Interpretable skill planning for latent diffusion-based manipulation
Yixing Liang, Anna Xie, Ziyun Feng, Yuke Zhu, Song- Chun Zhu, and Yunzhu Li. Skilldiffuser: Interpretable skill planning for latent diffusion-based manipulation. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 16467–16476, 2024
work page 2024
-
[55]
Zhixuan Liang, Yizhuo Li, Tianshuo Yang, Chengyue Wu, Sitong Mao, Tian Nian, Liuao Pei, Shunbo Zhou, Xiaokang Yang, Jiangmiao Pang, et al. Discrete diffu- sion vla: Bringing discrete diffusion to action decod- ing in vision-language-action policies.arXiv preprint arXiv:2508.20072, 2025
-
[56]
arXiv preprint arXiv:2406.01586 (2024)
Fanqi Lin, Haojie Lu, Haojian Fang, and Ping Luo. Manicm: Real-time 3d diffusion policy via consis- tency model for robotic manipulation.arXiv preprint arXiv:2406.01586, 2024
-
[57]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Constraint-preserving data generation for one- shot visuomotor policy generalization
Kevin Lin, Varun Ragunath, Andrew McAlinden, Aa- ditya Prasad, Jimmy Wu, Yuke Zhu, and Jeannette Bohg. Constraint-preserving data generation for one- shot visuomotor policy generalization. InProceedings of The 9th Conference on Robot Learning, volume 305 ofProceedings of Machine Learning Research, pages 3631–3646. PMLR, 2025. URL https://proceedings.mlr. ...
work page 2025
-
[59]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Ad- vances in Neural Information Processing Systems, 36: 44776–44791, 2023
work page 2023
-
[60]
Rdt-1b: a diffusion foundation model for bimanual manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[61]
Hierarchical diffu- sion policy for kinematics-aware multi-task robotic ma- nipulation
Jing Ma, Zhengyi Jiang, Rifat Hoque, Sangwoo Ahn, Pulkit Agrawal, and Kaiming Lee. Hierarchical diffu- sion policy for kinematics-aware multi-task robotic ma- nipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18081–18090, 2024
work page 2024
-
[62]
arXiv preprint arXiv:2510.26742 (2025)
Yunchao Ma, Yizhuang Zhou, Yunhuan Yang, Tiancai Wang, and Haoqiang Fan. Running vlas at real-time speed.arXiv preprint arXiv:2510.26742, 2025
-
[63]
Roboturk: A crowdsourcing platform for robotic skill learning through imitation
Ajay Mandlekar, Yuke Zhu, Animesh Garg, Jonathan Booher, Max Spero, Albert Tung, Julian Gao, John Emmons, Anchit Gupta, Emre Orbay, et al. Roboturk: A crowdsourcing platform for robotic skill learning through imitation. InConference on Robot Learning, pages 879–893. PMLR, 2018
work page 2018
-
[64]
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. Calvin: A benchmark for language- conditioned policy learning for long-horizon robot ma- nipulation tasks.IEEE Robotics and Automation Let- ters, 7(3):7327–7334, 2022
work page 2022
-
[65]
arXiv preprint arXiv:2203.12601 (2022)
Suraj Nair, Aravind Rajeswaran, Vikash Kumar, Chelsea Finn, and Abhinav Gupta. R3m: A universal visual representation for robot manipulation.arXiv preprint arXiv:2203.12601, 2022
-
[66]
Zehao Ni, Yonghao He, Lingfeng Qian, Jilei Mao, Fa Fu, Wei Sui, Hu Su, Junran Peng, Zhipeng Wang, and Bin He. V o-dp: Semantic-geometric adaptive diffu- sion policy for vision-only robotic manipulation.arXiv preprint arXiv:2510.15530, 2025
-
[67]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collabo- ration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collabo- ration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
work page 2024
-
[68]
Mingjie Pan, Jiyao Zhang, Tianshu Wu, Yinghao Zhao, Wenlong Gao, and Hao Dong. Omnimanip: Towards general robotic manipulation via object-centric interac- tion primitives as spatial constraints. InProceedings of the Computer Vision and Pattern Recognition Confer- ence, pages 17359–17369, 2025
work page 2025
-
[69]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokeniza- tion for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
GeoPredict: Leveraging Predictive Kinematics and 3D Gaussian Geometry for Precise VLA Manipulation
Jingjing Qian, Boyao Han, Chen Shi, Lei Xiao, Long Yang, Shaoshuai Shi, and Li Jiang. Geopredict: Lever- aging predictive kinematics and 3d gaussian geom- etry for precise vla manipulation.arXiv preprint arXiv:2512.16811, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
Spatialvla: Exploring spatial representations for visual-language-action model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model. In Robotics: Science and Systems, 2025
work page 2025
-
[72]
SAM 2: Segment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Rong- hang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollar, and Christoph Feichtenhofer. SAM 2: Segment anything in images and videos. InThe Thirteenth Internati...
work page 2025
-
[73]
Grounded sam: Assembling open-world models for di- verse visual tasks, 2024
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kun- chang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, Zhaoyang Zeng, Hao Zhang, Feng Li, Jie Yang, Hongyang Li, Qing Jiang, and Lei Zhang. Grounded sam: Assembling open-world models for di- verse visual tasks, 2024
work page 2024
-
[74]
Ralf Römer, Yi Zhang, and Angela P Schoellig. Clare: Continual learning for vision-language-action models via autonomous adapter routing and expansion.arXiv preprint arXiv:2601.09512, 2026
-
[75]
Weijie Shen, Yitian Liu, Yuhao Wu, Zhixuan Liang, Sijia Gu, Dehui Wang, Tian Nian, Lei Xu, Yusen Qin, Jiangmiao Pang, et al. Expertise need not monopolize: Action-specialized mixture of experts for vision-language-action learning.arXiv preprint arXiv:2510.14300, 2025
-
[76]
Geovla: Em- powering 3d representations in vision-language-action models,
Lin Sun, Bin Xie, Yingfei Liu, Hao Shi, Tiancai Wang, and Jiale Cao. Geovla: Empowering 3d representa- tions in vision-language-action models.arXiv preprint arXiv:2508.09071, 2025
-
[77]
Interactive post-training for vision-language- action models, 2025
Shuhan Tan, Kairan Dou, Yue Zhao, and Philipp Krähenbühl. Interactive post-training for vision-language-action models.arXiv preprint arXiv:2505.17016, 2025
-
[78]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gonzalez Arenas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[79]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[80]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, 2017
work page 2017
-
[81]
Bridgedata v2: A dataset for robot learning at scale
Homer Rich Walke, Kevin Black, Tony Z Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen-Estruch, An- dre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning, pages 1723–
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.